Benchmarking AI Code Review at Scale
Measuring AI code review performance
Qodo’s code review benchmark is a public, large-scale benchmark designed to measure how well AI systems perform real code review. It evaluates performance across both functional bugs and best practice violations, reflecting the range of problems found in real code review.
Results are based on precision, recall, and F1 score, capturing issue coverage, noise, and overall balance across many concurrent issues in production-grade pull requests.
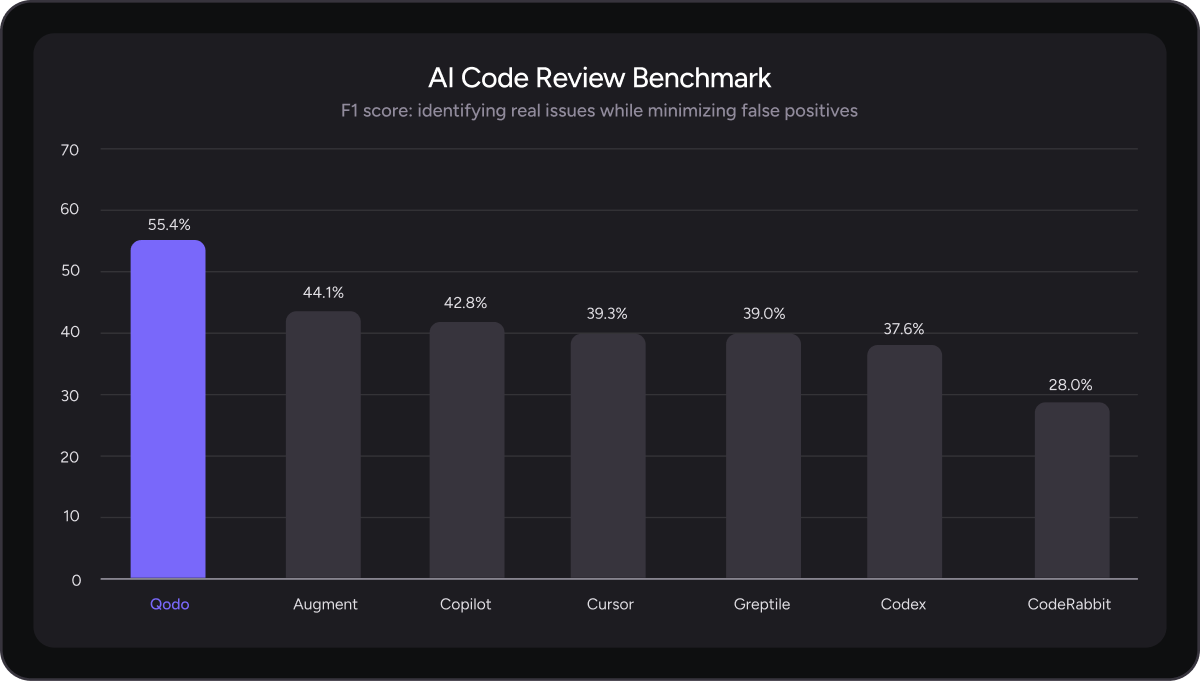
Based on these results, Qodo demonstrates the strongest overall performance among evaluated AI code review tools.
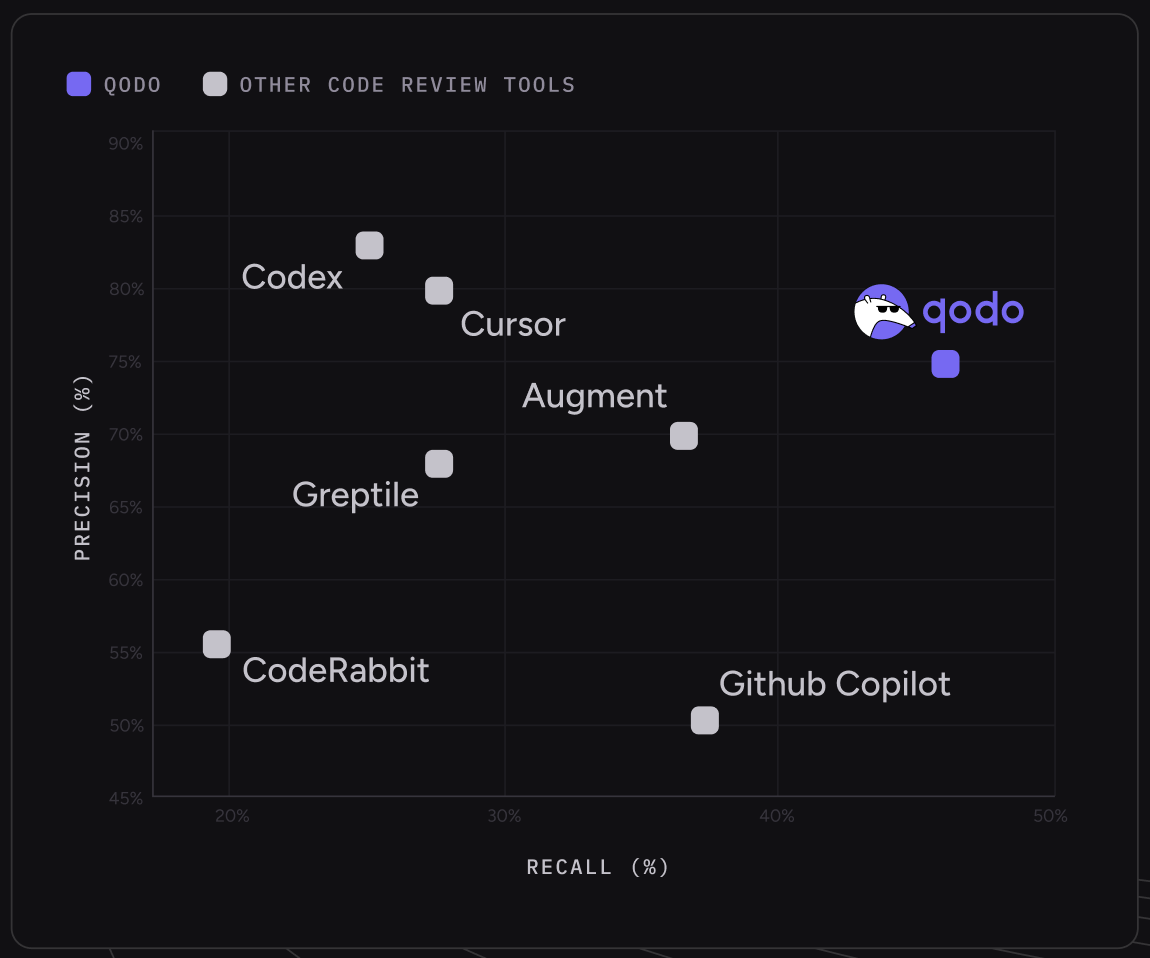
Qodo: A balance of precision and recall
Most tools cluster toward high precision and low recall. This means they comment only on the most obvious issues and miss a large portion of problems in a pull request. The result is quiet reviews with limited coverage.
When precision and recall are considered together, this balance translates into the strongest overall F1 score among evaluated tools.
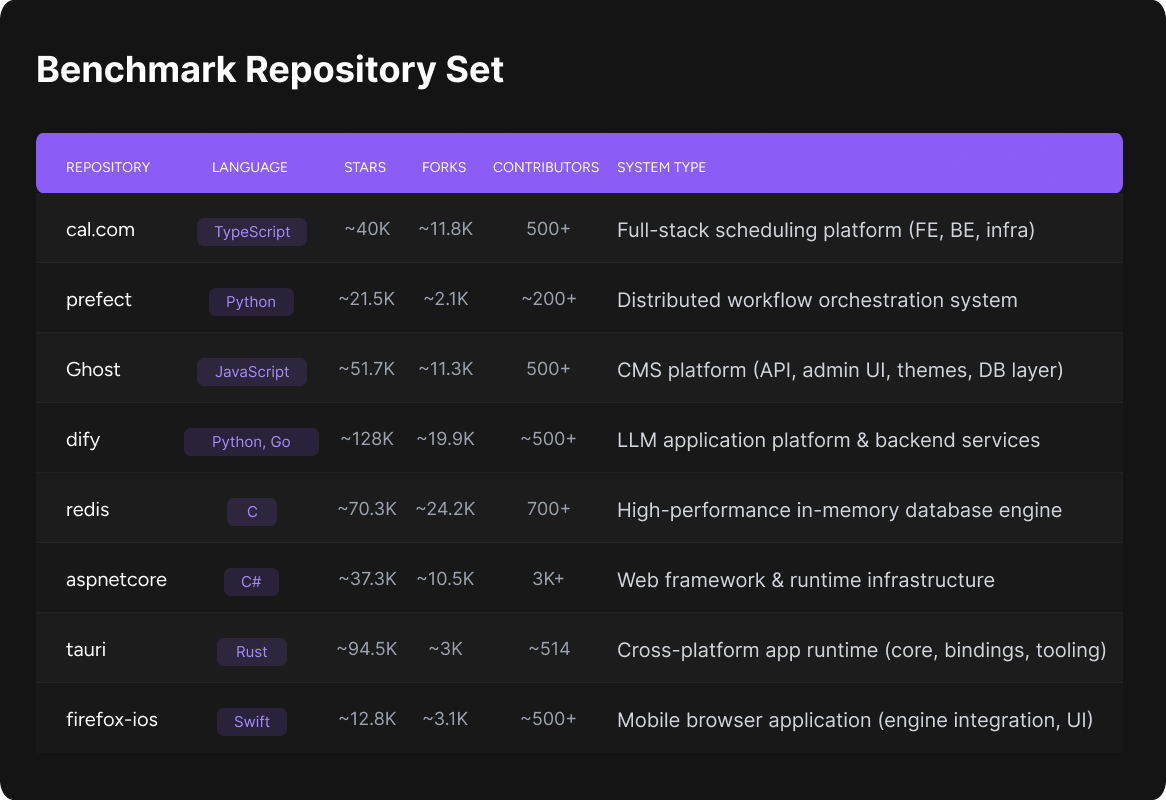
Representative of real-world codebases
The selected repositories span a broad and representative distribution of programming languages and system disciplines.
About the benchmark methodology
The benchmark is built on real, merged pull requests from active, production-grade open-source repositories.
It was built by injecting verified bugs and best practice violations into real, merged pull requests from production-grade open-source repositories. This approach evaluates both code correctness and code quality in full pull request contexts, going beyond benchmarks that focus on isolated bug types.