Already Fixed, Too Late: What 90 Open-Source Repos Tell Us About Code Review Blind Spots


A pull request merges into a widely used open-source project. It introduces a subtle bug: a sort comparator function that returns a distance value instead of the negative/zero/positive contract that Array.sort() expects. Elements end up in a nondeterministic order. The code review approves it. The CI pipeline is green. The bug ships to every user who updates.
255 days later, a different developer submits a one-line fix for that exact issue. The fix matched, almost word for word, what Qodo would have flagged, had it been running when that PR merged.
I wanted to know how often that pattern repeats: a bug ships through review, and a later fix matches exactly what automated analysis would have caught. Not in theory, not as a thought experiment, but measured across real codebases with real commit histories. So I ran Qodo’s code review on 90 major open-source repositories and analyzed merged pull request pairs: one that introduced a problem, and one that later fixed it.
This pattern repeated 1,258 times across the 90 repositories I studied. The repository’s own history confirms each one. A developer wrote a fix, which means the bug was real.
The study
I selected 90 widely-used repositories across 11 programming languages, prioritizing projects with active development and a meaningful volume of merged pull requests over the past year. The languages span Python, TypeScript, JavaScript, Go, Rust, Java, Ruby, PHP, C/C++, and Swift.
The repositories include Django, Angular, VS Code, Terraform, Selenium, Webpack, Supabase, Homebrew, Deno, OpenCV, Prometheus, Mastodon, Ghost, Discourse, Excalidraw, Storybook, n8n, NestJS, Puppeteer, and dozens more. These are not obscure or under-maintained projects. They are some of the most reviewed, most tested, and most relied-upon open-source software in use today.
For each repository, I analyzed pairs of merged pull requests: one that introduced a defect and one that later addressed it. A finding is only counted as proven if a subsequent PR in the same repository fixes the exact issue that was flagged. Each proven finding is validated against the repository’s own commit history. The fix PR, written by a human developer, confirms the bug was real.
The analysis was performed using Qodo’s code review platform.
The pattern is not specific to any language, framework, or team size. It appeared consistently across the entire dataset.
Several of the repositories in this study already use AI-powered code review tools. The bugs I found were present in pull requests that had been reviewed by both human reviewers and automated tools. The blind spot is not unique to human review or to any particular tool. It is a property of reviewing changes in isolation, without full codebase context.
The time gap
Of the 1,258 bugs that were eventually fixed, I measured the time between the pull request that introduced each bug and the pull request that fixed it.
The median gap was 16 days. The mean, pulled higher by bugs that survived for months, was 46 days.
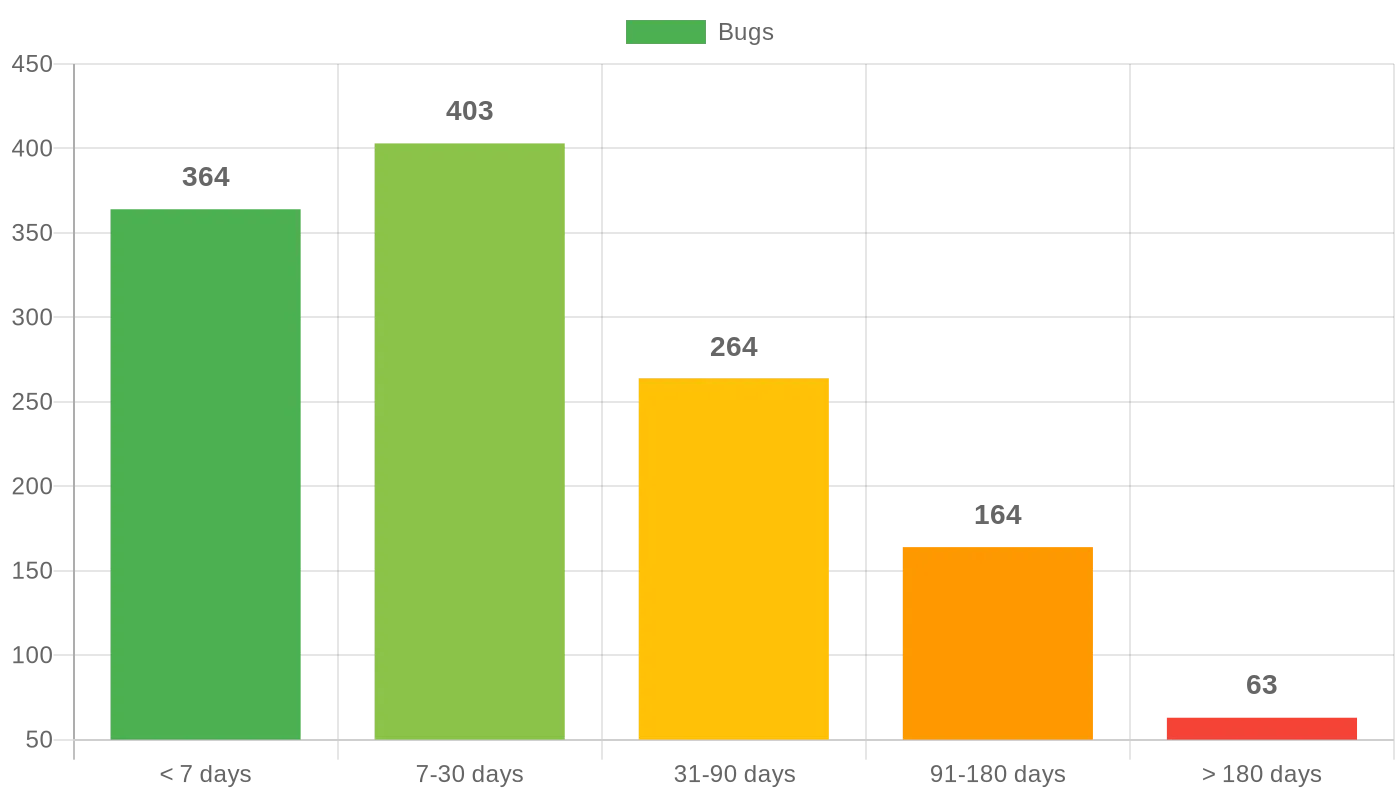
The distribution tells a more nuanced story:
- 29% were fixed within a week
- 32% took one to four weeks
- 21% took one to three months
- 13% took three to six months
- 5% took over six months
Consider what each of these fixes actually costs. A developer writes code, submits it for review, gets approval, and merges. Days or weeks pass. Then someone, often a different developer entirely, discovers the bug. That second developer now has to understand code they did not write, reproduce the problem, trace it to its root cause, and submit a fix. Meanwhile, the original author has moved on to other work and other contexts.
Every one of these 1,258 fixes represents a developer stopping what they were doing to go back and repair something that could have been caught before it merged.
The bugs fixed within a week were often the most frustrating: a wrong default value, a missing null check, an off-by-one in a loop bound. The kind of thing that takes seconds to fix during a code review but hours to diagnose after it reaches production. The bugs that survived for months were different in character: race conditions, incorrect state management, silent error swallowing, edge cases in configuration parsing. These are the bugs that only surface under specific conditions. They accumulate user reports and confused debugging sessions before someone finally connects the symptoms to the cause.
In one case, a project shipped a bug where opening a reply form triggered a sequential API loop that fetched all comments one page at a time, blocking the UI. It took 259 days for someone to notice and fix the performance regression. In another, a database connection was used before being initialized, but only on fresh connections after an idle timeout. That one survived 229 days.
The ones still there
Not all the bugs I found have been fixed.
Hundreds of confirmed issues remain in production code across these repositories today. These are not theoretical risks surfaced by a static analysis scanner. They are logic errors, race conditions, and incorrect error handling in code that is running right now.
The proven-and-fixed bugs and the confirmed-in-production bugs represent only the findings I fully validated. Due to the scale of the study, validation was limited to a representative subset per repository. The actual number of bugs across these 90 codebases is very likely higher than what I report here.
71% of these repositories scored a D or F when measured by finding severity and density per pull request. The full scoring breakdown is in the report.
What this tells us
Code review is effective. It catches style issues, enforces conventions, verifies naming, and flags obvious logic errors. Teams that practice code review ship better software than teams that do not.
But the data from this study points to a consistent blind spot. Code review struggles with context: how a change interacts with the broader codebase, edge cases that emerge from specific state combinations, regressions that appear perfectly correct when viewed as an isolated diff.
This is not about blaming reviewers. The developers who reviewed these 1,258 pull requests were doing their jobs, often on large and complex codebases, under real deadlines and competing priorities. Many of these repositories have rigorous review cultures with multiple required approvers. The bugs still got through.
The gap is structural. A human reviewer looking at a diff sees the lines that changed. What they cannot easily see is the full set of assumptions those lines depend on, the state that flows through them at runtime, or the interactions with code in other files that the diff does not show. No amount of diligence fully closes that gap, because it requires holding more context than a review interface presents.
The question is not whether your team is good at code review. It is whether code review alone is enough.
This study was conducted using a subset of Qodo’s analysis capabilities. For the full list of repositories, per-language breakdown, and methodology notes, see the full report (PDF).
Guy Vago is an AI Researcher and Software Architect at Qodo, which builds AI-powered code quality tools for engineering teams.
Open-source maintainers who would like to review findings related to their project can contact Dana Fine, Global Community & Open Source Manager at Qodo, at [email protected]


