Code Aware Agentic AI: The “System” Approach


Qodo Aware is an Agentic context engineering product designed to be your AI “Principal Engineer” to tackle large complex codebase challenges. Working as a standalone, Qodo Aware can be connected to any coding platform via MCP to enable deep research capabilities while boosting existing frontier models.
When Qodo Aware’s benchmarks showed the system consistently outperforming the base models it was built upon, it raised an interesting question about the nature of intelligence in computational systems. How does a system using Claude as its reasoning engine achieve better results than Claude operating independently?
The answer reveals something fundamental about complex problem-solving in software engineering. When humans tackle architectural challenges across large codebases, we don’t rely solely on individual expertise; we create structures, processes, and collaborative frameworks that amplify our collective capability. The most senior engineers aren’t relying only on their deep knowledge, they understand how to orchestrate multiple domains of expertise toward a coherent solution.
This parallel isn’t coincidental. The approach described here suggests that the evolution of AI systems may follow a similar trajectory: from isolated intelligence to structured, multi-component architectures where the whole genuinely exceeds the sum of its parts. The implications extend beyond technical performance metrics to how we conceptualize machine reasoning itself.
Rethinking AI Agents
Consider the difference between these implementations: an LLM responding to a single prompt; an LLM within a while loop that continues until it finds a satisfactory answer; and an LLM that can invoke external functions and modify its approach based on their outputs. Where does response end and agency begin?
The interesting observation isn’t in defining precise boundaries, but in recognizing that each implementation represents a different relationship between the model and its environment. A prompt engineer might create sophisticated reasoning chains through careful instruction design. A developer might achieve similar outcomes through architectural patterns, retry mechanisms, state management, tool orchestration. Both are manipulating the same underlying capability, but through different layers of abstraction.
Perhaps the focus on whether something qualifies as an “agent” obscures a more useful question: what types of problems require which kinds of autonomy? A single inference might suffice for text transformation. Iterative refinement might be necessary for complex analysis. Multi-tool orchestration might be essential for system-wide tasks.
This perspective suggests that building effective AI systems isn’t about achieving some threshold of agency, but about matching architectural patterns to problem domains. The Qodo Aware approach becomes interesting in this context not because it creates “true” agents, but because it demonstrates how treating agency as an architectural concern rather than a model property can yield unexpected performance characteristics. The system shows that the question isn’t whether we’ve built an agent, but whether we’ve built the right kind of decision-making structure for the task at hand.
Complex code aware challenges
When we research our codebase to accomplish complex tasks we tend to think “wide” as we usually think of the implications, integration, dependencies, etc. A key for proper execution is deeply grounded in our ability to find all the interfaces and edge cases. For that,we bring all stakeholders (products, algo, backend, frontend etc.) and start to iteratively plan how we are going to achieve optimal execution.
However, when we give an LLM, even with agentic capabilities or wrapped as CLI agents, a complex task, they often fail to achieve good results as they are very good at writing code and edit files but fail to smartly manage context ([1], [2])
With the above in mind, our tools mimic this behavior in 4 levels of complexity:
- Only context is needed (/context): This level involves providing a small portion of context to the Large Language Model (LLM) to familiarize it with domain-specific knowledge. Examples include referencing documentation or asking basic questions for explicit knowledge within the codebase (e.g., “Find all areas in the code that call the auth API”).
- Multiple context representations (/ask): Superior context is not only about similarity of code chunks; for simple tasks, it gives the LLM a boost, but when facing additional complexity, having broad knowledge is key. Here, we use multiple context providers, each one an “expert” in their domain, to provide the LLM the most relevant context in one shot for each query.
- Deep reasoning (/deep-research): This level aims to deeply explore the concept of the user’s query. Similar to how humans would loop around areas of interest until they have all the answers, this approach allows an agent to fetch context around a user query and then use its reasoning and tools to ask more questions and find relevant data for a more profound answer.
- Cross-disciplines deep reasoning (/deep-research): This is the most complex level. It applies the principles of deep reasoning but adds a core step: asking at an organizational level, “What are the domains across repos / in the current repo we need to explore that are relevant to the user query?” The goal is to identify all critical areas in the system, requiring broad knowledge of the codebase and its history. Each path is then explored separately, converging to a master agent that decides if the retrieved data is relevant to the user’s query. This level aims to achieve “principal engineer reasoning and knowledge,” where the agent can map the entire organization and find all relevant exploration paths.
Qodo Aware’s system approach
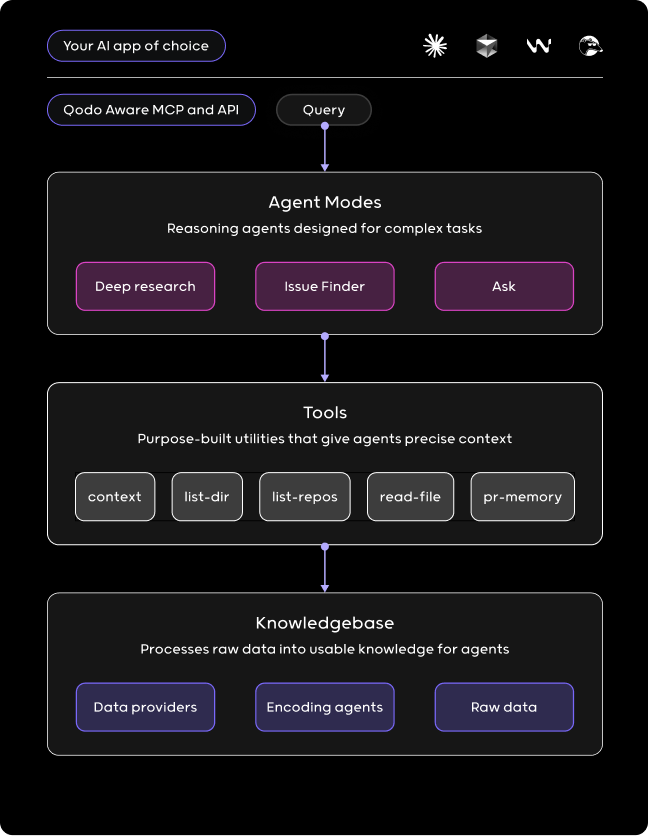
Inspired by “Sleep time compute” paradigm, we built a system to persist org knowledge in a way that our custom agent can travel and explore at run time.
- Agents: The “frontend” of the larger system, agents can operate without constant human supervision, making their own decisions based on their programming and environmental observations.
- Tools: Our agents leverage specialized tools with pre-indexed codebase access. Each tool connects directly to its designated data provider, while the agent autonomously determines the optimal tool for each task or step through intelligent reasoning.
- Knowledge: Combining agentic processing with a treesitter-like algorithm structures organizational data for efficient runtime querying. The system analyzes both the codebase and underlying business logic, traversing the data to build comprehensive indexes in three distinct forms. This multi-layered indexing approach enables intelligent, context-aware retrieval at runtime, ensuring agents can access the most relevant information precisely when needed.
- Org data: Raw data of the organization: pull requests, codebase, docs.
Here’s an example of a “hello world” agent that demonstrates a vanilla implementation of our approach.
from langchain.agents import create_react_agent, AgentExecutor
from langchain.tools import tool
from langchain_anthropic import ChatAnthropic
from langchain import hub
# Define 3 simple tools
@tool
def get_repos_graph() -> str:
"""Find cross repositories releshenships"""
return "..."
@tool
def list_file(path: str) -> str:
"""Retuen formated file tree under a filder"""
return "..."
@tool
def read_file(path: str) -> str:
"""Get contect of a file"""
return "..."
# Setup agent
llm = ChatAnthropic(model="claude-3-7-latest")
tools = [add, multiply, get_length]
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# Run agent
result = agent_executor.invoke({
"input": """
Creat a plan for incorporate billing traking service across all our backend
microservices that envlolve in transactions
"""
})
print(result["output"])
This is a basic concept implementation of an agent leveraging model reasoning together with powerful tools we created to achieve his tasks.
- Tool calling : The base model is in charge of activating each tool and deciding when to stop. It will return a summary to the user based on all the knowledge he explored.
- Tools: Well-defined tools paired with clear system prompts are critical for agent performance. While agents possess sophisticated reasoning capabilities, explicitly articulating when and how to use each tool—along with the expected value each provides—significantly enhances their effectiveness and delivers substantial operational value.
- Infrastructure: We use LangChain as infrastructure to drive our agent
This basic agent template is very similar to our production implementation, where the real power comes from the ability to build strong, well defined-tools for it to use.
Applications and Impact
After achieving all of the above, we can now confidently say we have a deep-research agent capable of thinking and reasoning about your codebase for complex tasks.
Let’s look at an example of a task involving multi-repository modifications that would typically be handled by an architect or principal engineer, one that’s particularly relevant given the recent announcement of GPT-5. Here’s an example flow for planning a base model replacement migration across Qodo’s core services.
# Task 1 - Start with mapping the services to be part of this # modification. prompt = "Create a table of qodo products uses Open AI models"
| Qodo Aware | GPT-4.1-mini-2025-04-14, GPT-4o, GPT-4.1-nano, text-embedding-3-large | Various AI tasks, Context eng), Embeddings generation, agents | Standard OpenAI |
| Qodo Gen | GPT-3.5-turbo, GPT-4o, GPT-3.5-turbo-instruct | Code completion, Search functionalities, Code analysis | Standard OpenAI & Azure OpenAI |
| Qodo CLI | GPT-4, User-selectable models | Interactive chat modes, Custom agent commands, HTTP API serving | Standard OpenAI |
| Qodo Cover | Azure OpenAI models (configurable) | Test generation, Code coverage analysis | Azure OpenAI |
| PR Agent | GPT-4o, Configurable fallback models | Pull request analysis, Code review automation, PR descriptions | Azure OpenAI with AD aut |
Output from the above prompt
After the agent mapped the services we continue the flow and instruct it to explore and suggest the plan before execution:
# Task 2 - Start to plan more granularly for the migration across services prompt = "Now plan for migration to the new GPT5 for each service, find all the places that needs to be modify and surfece any risk in replacing our current implementation"
GPT-5 Migration Plan for Qodo Services
Executive Summary
This document outlines a comprehensive migration strategy for transitioning Qodo services from current GPT models (GPT-3.5, GPT-4, GPT-4o) to GPT-5, addressing technical modifications, risks, and mitigation strategies.
1. Pre-Migration Assessment
1.1 Current State Analysis
Component
Current Implementation
Migration Impact
Model Configuration
Hardcoded model names in configs
High - Requires updates across all services
Token Limits
Fixed limits (4K-128K per model)
High - GPT-5 may have different limits
API Versioning
Azure API versions (2024-02-01)
Medium - May need new API versions
Fallback Mechanisms
Model-specific fallbacks
High - Need GPT-5 fallback strategy
Authentication
Azure AD + API keys
Low - Should remain compatible
1.2 Dependency Mapping
Qodo Services
├── Direct Dependencies
│ ├── LiteLLM framework (model abstraction layer)
│ ├── OpenAI SDK
│ └── Azure OpenAI SDK
└── Indirect Dependencies
├── Model-specific prompts
├── Token counting logic
└── Response parsing patterns
...
...
...
Partial output from the above prompt
We can now collaborate with the agent to ensure the plan is accurate, conduct design reviews, and share it with our peers, just as we would do ourselves. However, the agent now extends our capabilities and unlocks skills that were previously exclusive to senior engineers in the organization.
We’re also seeing a significant boost from adding this planning mode for background agents as a preliminary step to perform deep research on problems and provide a head start for the agent. This separation of planning logic and codebase understanding allows the coding agent to focus on what it does best:code generation.
Benchmark
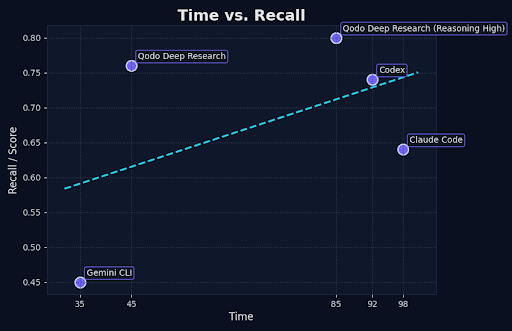
| Agent | Time | Score |
| 👑Qodo Deep Research | 45 | 0.80 |
| Codex CLI | 92 | 0.74 |
| Claude Code | 98 | 0.64 |
| Gemini CLI | 35 | 0.45 |
For in depth overview see our blog post on the benchmark methodology.
To validate our approach, we developed a benchmark using real-world pull requests as source material. LLMs generate question-answer pairs from these PRs, creating an authentic ground truth dataset. Our agents attempt these questions, with responses evaluated by an independent LLM judge. This testing on previously unseen data demonstrates that thoughtful system design enables us to exceed the performance of major research labs’ products, despite using their underlying models.
We are using Claude and OpenAI GPT to power our agent. While our prompts aren’t proprietary secrets immune to replication, our systematic agent architecture enables frontier models to excel at complex coding tasks where they typically struggle.
Consider the challenge: an LLM or agentic system with local CLI tools must navigate vast codebases for complex tasks. Traditional approaches require maintaining long-running sessions, generating summaries, establishing checkpoints for self-review, and repeating this cycle for each task. In contrast, our approach performs comprehensive analysis upfront, then leverages this pre-computed knowledge at runtime. This architecture empowers frontier models to deliver significantly higher quality results.
Real-World Performance vs. Benchmarks
Our benchmark uses open-source repositories where each question-answer pair exists within a single repository. However, real organizations face a more complex reality: answers span multiple repositories, and crucial organizational knowledge exists outside any model’s training data. Most existing tools (except Qodo deep-research) aren’t designed for this multi-repository, proprietary-knowledge scenario and would struggle to deliver meaningful results.
This benchmark demonstrates that even in single-repository scenarios, the “home turf” where traditional agents should excel at code planning and comprehension, our architectural approach delivers superior performance. The implications for real-world, multi-repository environments are even more compelling.
Next Evolution of our system
Achieving principal engineer-level intelligence represents a significant leap forward. We’re continuously evolving Qodo Aware, adding capabilities that enhance both quality and performance. As we scale, we’ve identified a critical gap: the lack of high-quality benchmarks for these complex tasks. Our roadmap includes establishing more robust benchmarking standards while simultaneously developing increasingly powerful tools to push the boundaries of what’s possible.


