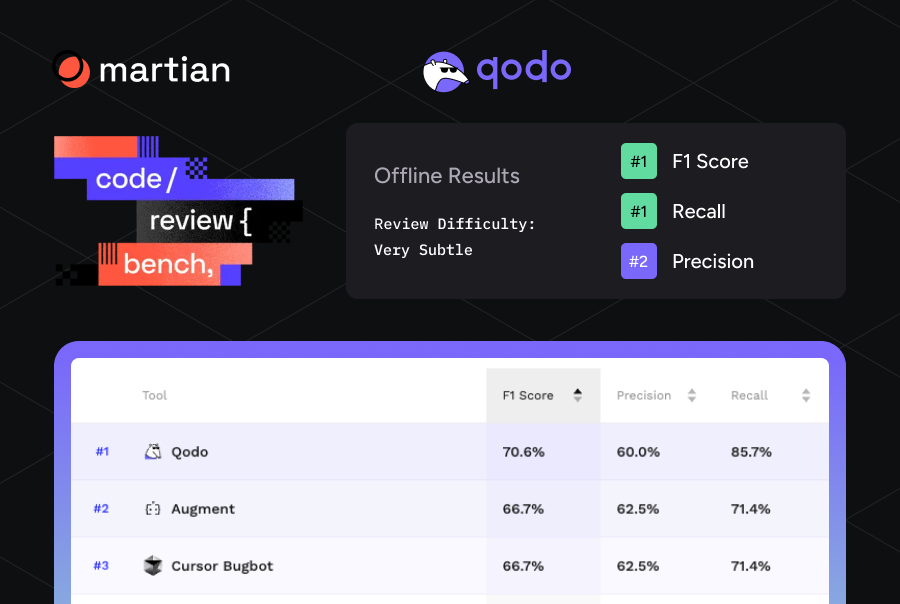
The Enterprise Guide for Code Quality Measurement Across the SDLC
TLDR;
- Measuring code quality in enterprises goes beyond checking whether code runs. AI-generated code may introduce hidden flaws that traditional metrics like test coverage or linting often miss. Evaluating code in its full context is crucial to ensure it is ready for production.
- Metrics such as coverage, complexity, duplication, and code churn can give a false sense of security. They catch only obvious issues, while problems like architectural misalignment, missing edge cases, or subtle logic errors may remain unnoticed until production.
- Qodo strengthens code quality by embedding checkpoints throughout the lifecycle, from local development to production. With shift-left checks, enterprise-grade PR reviews, and one-click fixes, it ensures issues are caught and resolved before merges, keeping standards consistent across teams.
- Context-driven reviews help identify high-risk files, flag potential edge cases, and guide expert reviewers. This confirms AI-assisted changes do not compromise system integrity and are production-ready. Tools like Qodo have one click remediation that helps developers to turn insights into immediate fixes while keeping architectural and business rules intact.
- Operational metrics such as rollback frequency, mean time to detect, and mean time to recover show which modules cause incidents, how fast problems are found, and how easily they are fixed. These insights help teams prioritize testing and review efforts.
- I personally prefer using context-aware tools like Qodo that help enterprises with context-aware guidance into pull requests with contextual retrieval guided insights into pull requests.. This helps me to maintain code quality by preventing technical debts and enforcing code standards consistently across multiple teams and repositories, making sure code is mergeable and production-ready.
As a developer who has managed large production systems like e-learning platforms and enterprise SaaS tools in private equity, I’ve noticed that the real challenge is rarely writing code that runs. The harder part is knowing whether the code is reliable enough for production. This challenge has grown with the increasing use of AI-assisted code generation. While LLMs can accelerate development and generate functional code, they often miss broader context, leading to hidden technical debt and overlooked edge cases. These risks lower overall code quality, making systematic measurement and review even more essential.
This shift is especially relevant as AI tools are no longer optional experiments but are becoming standard in development workflows. According to the 2025 Qodo survey, 82% of developers are either using or planning to use AI tools. The trend is understandable: AI-generated code often works, but it can quietly introduce tech debt, missed edge cases, and context gaps. Without proper checks, those flaws slip through to production, leading to more frequent bugs, longer debugging cycles, and growing maintenance overhead that can slow down teams over time.
The question is: Are teams here treating AI as just a helper, or do they actually let it take part in code reviews? And if so, how do you measure the quality of what it creates?
In this post, I want to explore how enterprises can move from vague ideas of “good code” toward measurable, repeatable signals of production-ready code. I’ll draw on metrics, examples, and real workflows (from my teams) to show what measurement looks like when your goal is to ensure code quality through review, deployment, and beyond.
Traditional Code Quality Metrics And Why They Aren’t Enough
Code quality measurement in AI-generated code is the process of evaluating whether the code meets technical standards such as correctness, readability, maintainability, security, and performance, while also ensuring that it fits the specific context of the project.
When most teams talk about measuring code quality, they point to the same set of traditional metrics: test coverage, linting, complexity scores, and static analysis checks. These are useful signals, but they were designed for a world where code was written manually, with developers carrying full context about architecture and business rules in their heads.
For example, when I reviewed AI-generated code in a project, I found cases where the code passed all linting rules and unit tests but still introduced inefficiencies. For example, an AI assistant once generated this Python snippet to check if a value exists in a list:
def exists_in_list(my_list, value):
for item in my_list:
if item == value:
return True
return False
This works correctly, is readable, and passes tests. But it’s inefficient for large lists, and duplicates functionality already available in Python:
def exists_in_list(my_list, value):
return value in my_list
Traditional metrics like test coverage or complexity scores would mark both versions as fine. Yet the AI version adds unnecessary loops and makes the code harder to maintain. These traditional metrics provide signals worth tracking, but when applied to AI-generated code, they often produce a false sense of readiness. They measure surface-level correctness and style, but they cannot validate whether code fits into the architecture, aligns with team conventions, or closes the gaps AI leaves in business logic and context.



Factors I Use To Ensure Code Quality Measurement (Enterprise Context)
In today’s enterprise environments, code quality can’t be reduced to static metrics like coverage or linting. The real question is: Is this code ready to merge? That means safe, maintainable, and efficient enough to support production without creating hidden risks.
1. Merge-Readiness
In enterprise software development, ensuring that code is “merge-ready” is an important aspect of maintaining a stable and efficient codebase. This concept extends beyond traditional metrics, such as test coverage or linting; it encompasses a holistic assessment of whether code changes align with architectural standards, security protocols, and performance expectations.
In one project I reviewed, a teammate submitted an API change for our payment processing service. The code passed all unit tests and linting rules, but when I examined the logic and its interaction with our concurrency layer, I noticed a subtle race condition. If left unchecked, this could have caused intermittent transaction failures during peak traffic.
I walked through both automated checks and a targeted manual review of the affected components. This process helped me catch the concurrency issue before the PR was merged, ensuring the service remained stable and aligned with our architectural and performance standards.
So, to ensure that code is truly merge-ready, enterprises should implement comprehensive quality gates that assess various aspects of the code:

- Architectural Alignment: Verify that changes adhere to established architectural principles and do not introduce inconsistencies.
- Performance Standards: Assess the impact of changes on system performance, identifying potential bottlenecks.
- Maintainability: Evaluate the clarity, readability, and modularity of the code to ease future maintenance and scalability.
2. Cross-SDLC Checkpoints
Code quality is not a one-time assessment; it’s a continuous signal that must be measured at multiple points throughout the software development lifecycle. As a senior developer or engineering lead, I rely on specific checkpoints to maintain visibility and catch potential issues before they reach production.
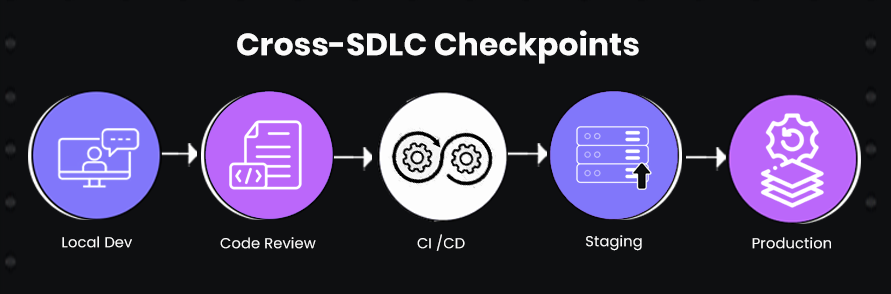
Local Development
Even before a PR is submitted, I ensure that developers run automated static analysis, unit tests, and local performance profiling. For example, I recently noticed that an AI-generated caching function caused higher-than-expected memory usage on local tests. Catching it at this shift-left stage prevents repeated CI failures and early-stage performance regressions, and allows developers to immediately remediate the code.
Code Review / Merge Request
At this stage, I assess architectural alignment, naming conventions, and potential side effects. For example, during a merge review of a payment service, I identified that a function bypassed our transaction validation layer. Code review as a checkpoint ensures that high-risk changes are scanned by someone familiar with the system’s architecture.
CI/CD Pipeline Checks
Automated builds and integration tests catch compatibility and regression issues across the system. In one example, AI-generated API code passed local tests but failed integration tests in CI due to subtle differences in data serialization between services. CI/CD as a checkpoint ensures that changes work in the context of the full system.
Staging / Pre-Production
Before deployment, I validate performance, security, and system behavior under realistic workloads. For example, an AI-generated recommendation engine logic seemed correct in CI but caused 25% higher latency under staging load tests. Staging checkpoints give the team confidence that code behaves correctly in production-like environments.
Production Monitoring (Post-Deployment)
Finally, production observability helps identify issues that only appear under real user traffic. Monitoring logs, error rates, and system metrics allows me to quickly react to regressions that escaped previous checkpoints.
So, by systematically using these cross-SDLC checkpoints, I can trace quality signals from development to production. This approach ensures early detection of performance regressions, architectural violations, or AI-generated inconsistencies, ultimately maintaining system reliability and reducing operational risk. Tools like Qodo make it easier to maintain these checkpoints, providing traceability and context-aware measurements at every stage.
3. Context-Driven Review
With AI code generation becoming common, teams are dealing with significantly higher volumes of code in each cycle. More code means more potential for subtle issues to slip through, especially when the AI isn’t aware of your system’s architecture or business logic. This makes context-driven review essential: evaluating not just whether tests pass, but whether changes impact important components, align with architectural standards, and maintain consistency across the system.
For example, in a cloud SaaS platform, our team used AI to generate several utility functions for handling multi-tenant configuration updates. While the generated code passed all unit tests and style checks, a deeper review revealed that it bypassed the central transaction and validation framework. Because we applied a context-driven review, focusing on which files and modules were high-risk, we flagged these changes before merging. This prevented potential tenant isolation failures in production.
Context-driven review ensures that, even with large volumes of AI-generated code, each change is evaluated for its systemic impact, preserves architectural integrity, and increases the likelihood that the code is production-ready. Tools like Qodo help streamline this process by highlighting high-risk changes and enforcing contextual checks across the codebase.
Top 3 Enterprise Code Quality Metrics That Support Production-Ready Code (Beyond Coverage)
Traditional metrics like test coverage, linting, or cyclomatic complexity provide surface-level insights, but in an enterprise context, they rarely tell you whether code is truly ready for production. As a senior developer, I focus on metrics that connect code changes to real operational outcomes. These are measurable KPIs that reflect system reliability, team behavior, and the actual risk of merging new code.
1. Rollback Frequency Post-Merge
Tracking how often code needs to be rolled back after merging is a direct indicator of production quality. A high rollback frequency signals that either the code wasn’t properly validated or important edge cases were missed.
Rollback frequency directly ties to quality because it signals the reliability, maintainability, and correctness of merged code in real-world contexts. For AI-generated code, which can generate many changes at once, tracking rollbacks helps prioritize review and validation for modules where the AI is more likely to introduce hidden flaws.
In one payment platform I manage, frequent rollbacks of AI-generated transaction logic prompted a deeper investigation, revealing that some concurrency scenarios weren’t accounted for in automated tests. Monitoring this metric over time helps identify teams, components, or processes that require stricter quality controls.
2. Mean Time to Detect / Recover (MTTD / MTTR)
MTTD and MTTR are often treated as operational metrics, but from a code quality perspective, they reveal how well code changes withstand real-world conditions and how quickly failures are addressed. If code quality is high, issues should be rare and easily traceable. Let’s understand what MTTD and MTTR are first:
Mean Time to Detect (MTTD)
MTTD or Mean Time to Detect measures the average time it takes to identify a problem after it has been introduced into the system, whether during testing, staging, or production. For code quality, a shorter MTTD indicates that issues, including those introduced by AI-generated code, are identified quickly before they can escalate.
For example, in a SaaS platform I manage, an AI-generated API update caused subtle data serialization mismatches. These issues were invisible in staging but were detected within 10 minutes of deployment due to proactive monitoring. A low MTTD allowed us to act before user impact escalated, reinforcing that code changes were validated continuously and contextually.
Mean Time to Recovery (MTTR)
MTTR measures the average time it takes to fix an issue after it has been detected. For enterprises, this reflects not just operational efficiency but also the resilience and maintainability of the code. High-quality code should minimize MTTR because it’s easier to diagnose, understand, and correct.
Example: On a high-traffic payment service, AI-generated code introduced a concurrency bug that caused intermittent transaction failures. With proper monitoring and alerting, the team could rollback and deploy a fix within 20 minutes. Tracking MTTR ensured that production stability was maintained and highlighted where AI-generated code required stricter review and testing before merging.
Using MTTD and MTTR for Code Quality Measurement
Enterprises can leverage MTTD and MTTR not just to respond to incidents, but to actively improve code quality across the SDLC. When combined, these metrics provide a feedback loop that helps teams identify weak spots, enforce standards, and validate AI-generated code.
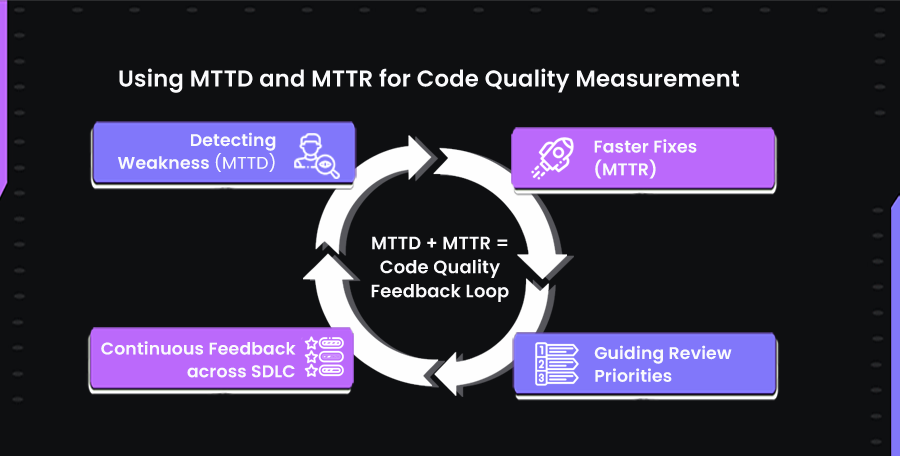
Let’s understand one by one:
Detecting Weaknesses Early
MTTD highlights where issues are occurring most frequently or taking longer to detect. For AI-generated code, modules with longer MTTD often indicate areas where automated tests or review processes are insufficient.
Example: On a cloud data platform, AI-generated code for a real-time ingestion module caused intermittent data mismatches. Tracking MTTD revealed that these issues went undetected in staging, prompting the team to add context-aware validation and additional review checkpoints for that module.
Measuring Maintainability and Response
MTTR reflects how quickly a problem can be understood and fixed. A low MTTR indicates that code is structured, readable, and consistent with architectural conventions, making it easier to maintain and adapt.
Example: A high-traffic payment service deployed AI-generated API updates. MTTR tracking showed that fixes were consistently implemented within 20–25 minutes, because logging, error handling, and modular design made the code easier to debug and correct.
Guiding Review and QA Priorities
Patterns in MTTD and MTTR help enterprises prioritize code peer review, testing, and monitoring efforts. Modules with higher detection or recovery times are flagged for deeper review, additional testing, or stricter validation before merging.
Example: Across a multi-tenant configuration service, analysis of MTTD/MTTR for AI-generated code identified certain modules that frequently caused minor incidents. The team implemented stricter peer review and automated validation for these high-risk components, improving overall reliability.
Continuous Feedback Across the SDLC
Tracking MTTD and MTTR at each stage, development, review, CI/CD, staging, and production, creates a traceable record of code quality. This helps ensure that code is not only functional but also aligns with enterprise standards from merge to deployment.
3. Review Depth on Important Files
Code changes vary in impact depending on which parts of the system they touch. Updates to root modules, security-sensitive components, or high-traffic services can have far-reaching consequences, while minor tweaks to utility functions are less likely to affect system stability. Understanding this difference is essential for measuring code quality effectively, because not all automated checks or generic reviews capture the risks associated with important files.

Review Depth measures how thoroughly changes in high-risk files are examined before merging. It considers who reviews the code, what aspects are validated (architecture, system conventions, security, business logic), and whether important modules receive sufficient scanning.
Measuring review depth ensures that changes to high-risk components are evaluated by engineers who understand the architecture, business logic, and system dependencies. This becomes especially important when AI-generated code is involved, as such changes can pass automated tests yet introduce subtle flaws that only a context-aware reviewer would notice.
Enhancing Review Depth with Qodo: A Real-World Example
While contributing to the KonfDB project, an open-source solution for multi-tenant configuration management, I added a new API endpoint to handle tenant-specific settings. Firstly, I prompted Qodo in my IDE with the:
“Add a new REST API endpoint GET /tenants/{tenantId}/settings in the KonfDB project. This endpoint should:
- Accept a tenantId path parameter.
- Retrieve all configuration settings specific to that tenant from the database.
- Return the settings as a JSON object with proper structure, including default values for missing keys.
- Include input validation and error handling for invalid or non-existent tenant IDs.
- Add unit tests and integration tests to cover normal cases and edge cases.
- Ensure changes do not break multi-tenant isolation or existing functionality.
- Add necessary documentation for the new endpoint in the API docs.”
Here’s a snapshot of what Qodo implemented:
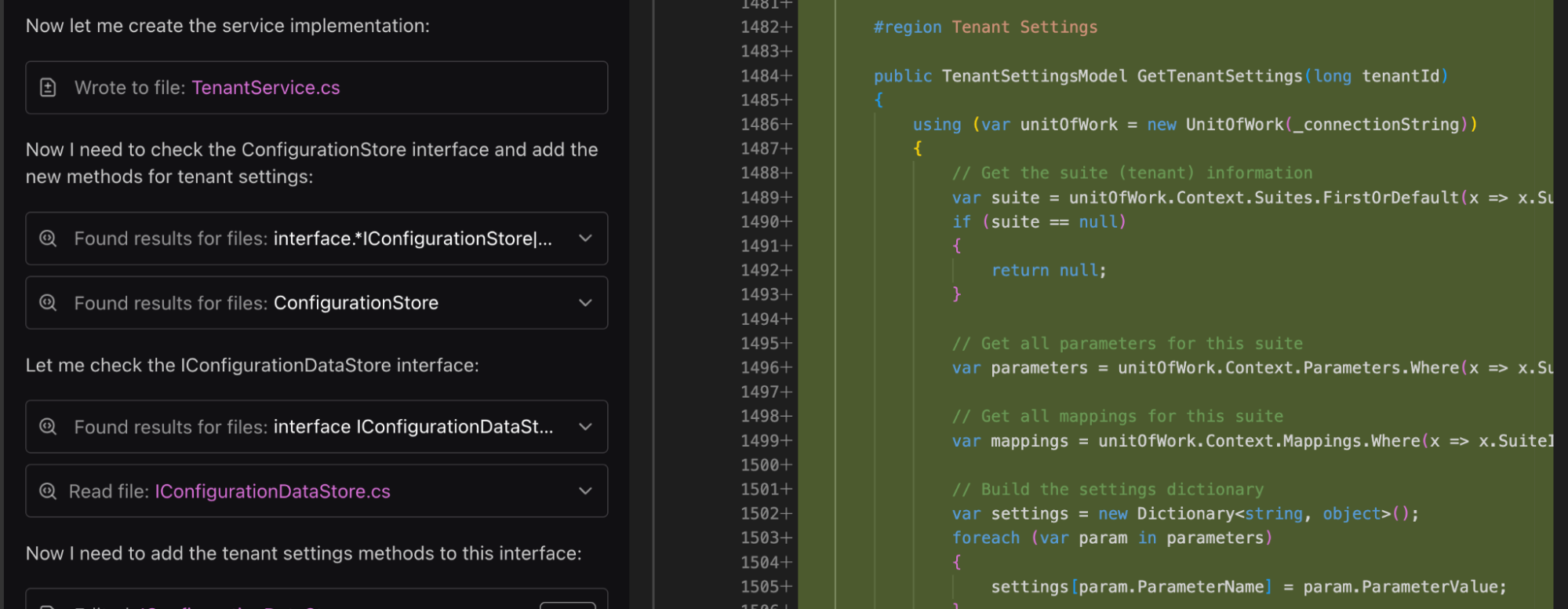
In the service layer, Qodo created TenantService.cs with methods to retrieve, update, and delete tenant-specific settings, incorporating input validation, error handling, and multi-tenant isolation logic.
On the data layer, it updated the IConfigurationDataStore interface and implemented corresponding CRUD operations in ConfigurationDataStore.cs, ensuring consistency with existing persistence patterns and handling default values, metadata, and tenant-specific mappings.
Qodo leveraged its deep code understanding and intelligent review capabilities to generate unit and integration tests covering both normal scenarios and edge cases, including missing tenants, null models, and invalid tenant IDs, ensuring that AI-generated changes do not bypass mandatory system checks while continuously learning and enforcing organizational rules.
Once the service implementation was complete, a pull request was raised for the new tenant-specific API endpoint. I used Qodo Merge to analyze the PR and submitted prompts focused on review depth for the specific file TenantService.cs:
“Which parts of this code can silently fail without raising logs or exceptions?“
While reviewing TenantService.cs, Qodo highlighted several hidden risks where the code could fail silently without raising logs or exceptions, issues that traditional metrics alone would not catch.

I noticed that fragile string matching for error handling could cause unnoticed failures, so Qodo recommended adding structured error codes and logging any unexpected mappings. It also flagged that exceptions wrapped into WebFaultException were not consistently logged, and suggested including correlation data to make failures traceable.
Qodo also suggested enforcing strict type contracts to prevent subtle object-to-string drift and writing unit tests for edge cases such as wrong data types, missing authorization, oversized payloads, or distinguishing “key not found” from “tenant not found.”
And then I asked Qodo to tell me what % of edge cases were addressed in tests and code. Qodo gave me an estimate for TenantService.cs, showing that approximately 50–60% of common edge cases were directly handled through input validation and error handling. Here’s the snapshot:

While some scenarios, like basic data validation and error logging, were covered, several important cases remained unhandled or only partially addressed, which could reduce the robustness of the multi-tenant configuration service.
Qodo highlighted missing or partial coverage, such as enforcing per-tenant authorization checks and validating settings.Metadata against a minimal schema, adding key/value validation for length, charset, and nullability, and replacing string-based error mapping with structured codes from the command layer.
Following these recommendations would increase coverage closer to 85-90%, ensuring that edge cases are consistently validated and that the service behaves reliably under a wide range of inputs.
Security-sensitive areas, including the public API surfaces and configuration persistence logic, were flagged for senior scans. Here’s a snapshot of what review Qodo gave me:
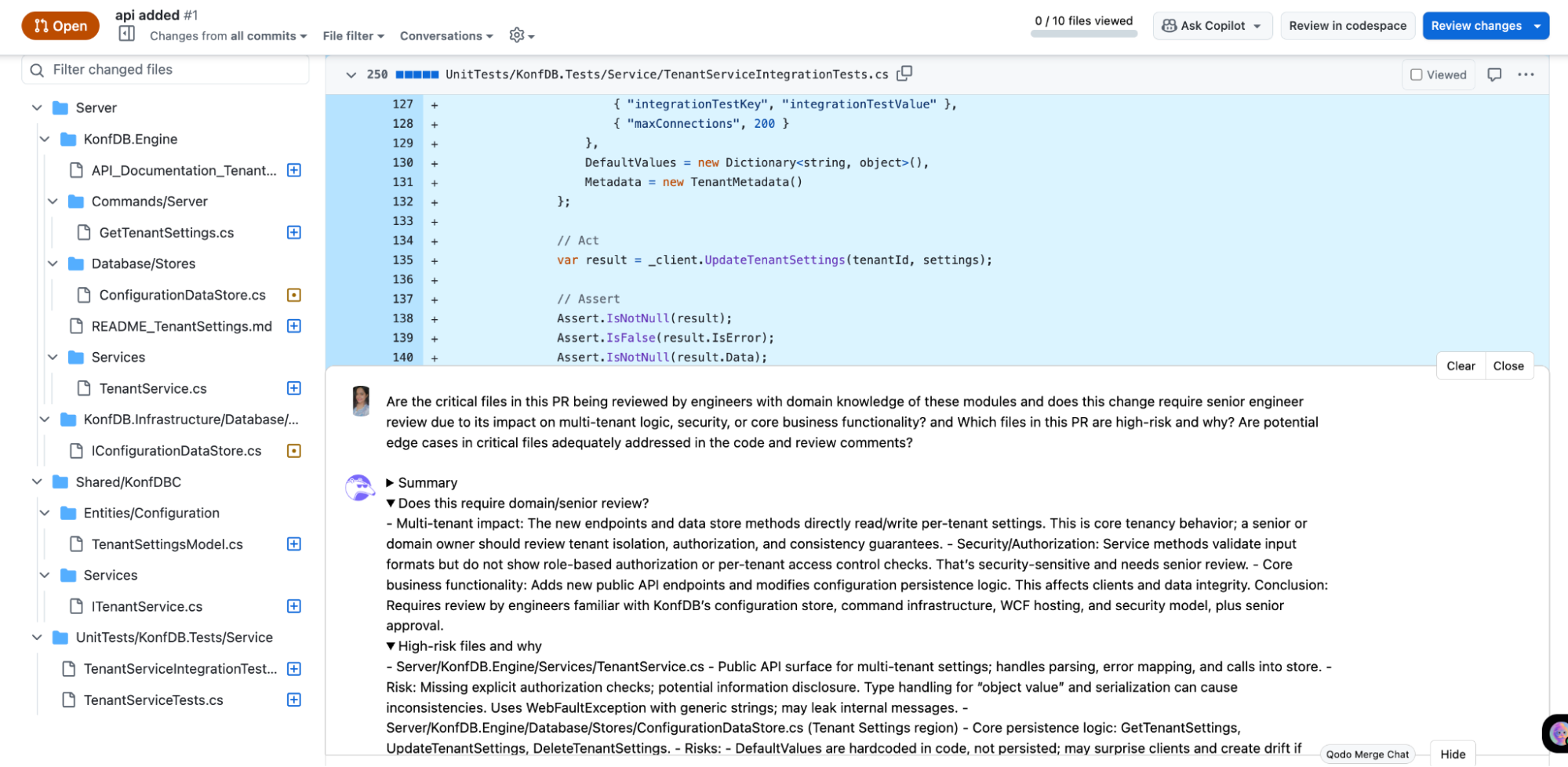
High-risk files were highlighted with specific concerns:
- TenantService.cs: Handled API parsing, error mapping, and calls into the store. Risks included missing authorization checks, object type inconsistencies, and potential information leakage through exception messages.
- ConfigurationDataStore.cs: The GetTenantSettings, UpdateTenantSettings, and DeleteTenantSettings methods were flagged for hardcoded defaults, lack of concurrency control, and type conversion issues that could affect tenant data integrity.
- ITenantService.cs: Changes to the API contract were identified as high-risk due to type ambiguity in object-valued properties that could impact clients.
As seen here in the image, Qodo highlighted some gaps that can directly affect production, making the code non-mergeable:

During the PR review, Qodo flagged discrepancies between what the documentation promised and what the code actually implemented. For example, the API docs for the tenant settings endpoints mentioned features like caching of frequently accessed configuration, encryption of sensitive values, and audit logging for changes.
In the implementation, however, caching was not explicitly applied in the service methods, encryption policies were ignored in the new update paths, and audit logging was missing for parameter changes.
Without these gaps being highlighted, it would be easy to assume that the code fully supported these features, potentially leading to incorrect assumptions downstream, where clients might expect cached responses or encrypted values, and missing audit trails could violate compliance requirements. Qodo’s deep code understanding and intelligent review capabilities ensure that such gaps are detected, enforce organizational rules with precision, and provide actionable insights to maintain compliance and reliability across the system.
Practices that Strengthen Code Quality
It’s good that we use metrics like rollback frequency, MTTD, and review depths, but metrics alone don’t define quality. What really matters is the practices and standards a team commits to and how consistently they are followed. In my experience, teams that rely only on metrics but neglect practices often end up with code that passes every automated check yet fails in real-world maintainability.
For example, I once reviewed an AI-generated module that technically worked and passed tests, but it ignored our project’s error-handling standard. As a result, exceptions accumulated in production, forcing rework and hotfixes. The issue wasn’t caught by any metric; it was a gap in enforcing coding standards.
That’s why I’ve pulled together the following table of the most important practices I believe every team should follow, and why they matter especially in the context of AI-generated code.
| Practice | What it is | Why To Choose These Practices? |
| Reviews | Manual reviews and pair programming to catch issues missed by automation. | AI may generate syntactically correct but context-misaligned code. Reviews ensure alignment with design patterns and business rules. |
| Refactoring | Improving code structure, readability, or performance without changing behavior. | AI often outputs verbose or redundant code. Refactoring makes it leaner and more maintainable. |
| Documentation | Clear functional, non-functional, and performance requirements. | AI lacks domain awareness; documentation provides the missing context to guide correct solutions. |
| Style Guides | Conventions for formatting, naming, and indentation (e.g., PEP 8). | Enforces consistency so AI-generated code is readable and easier for humans to maintain. |
| Coding Standards | Broader SOPs covering architecture, error handling, and design patterns. | Keeps AI-generated code aligned with system-level practices, not just isolated correctness. |
Qodo’s Role in Code Quality Measurement
Qodo is a developer-focused platform designed to ensure measurable, context-aware code quality throughout the entire software development lifecycle. I really root for Qodo because its approach goes beyond traditional static metrics.
Its deep code understanding and institutional memory across repositories allow it to identify subtle failures and enforce organizational rules with precision. Every recommendation, from structured error handling to validation of tenant data, is powered by this understanding.
Moreover, Qodo focuses on addressing the last mile in software delivery by managing the full code review lifecycle across the SDLC. It adopts a shift-left strategy to detect and resolve issues early in development while enforcing strict gates in the Git environment for pull request reviews.
I will share a hands-on example from the earlier project to show how Qodo makes code production-ready and helps measure code quality.
Hands-On Experience with Qodo
In my experience working with Qodo, the platform makes code review across the entire SDLC tangible and actionable, from local development to CI/CD pipelines and even into production. As in the example seen above with the KonfDB open-source project, I added a new API endpoint to handle tenant-specific settings.
Qodo highlighted the high-risk files and surfaced the changes required senior engineer review. It flagged potential edge cases, such as tenant isolation, authorization gaps, and metadata handling, that would have been easy to miss even though the code passed automated tests.
Let’s continue on that PR, I added additional comments for Qodo. Let’s check them one by one to see how Qodo helps in making code mergeable and production-ready, ensuring consistent code quality:
“Does the PR contain AI-generated code, and if so, has it been thoroughly reviewed in the context of the existing codebase?”
Here’s what Qodo replied after analyzing my PR:
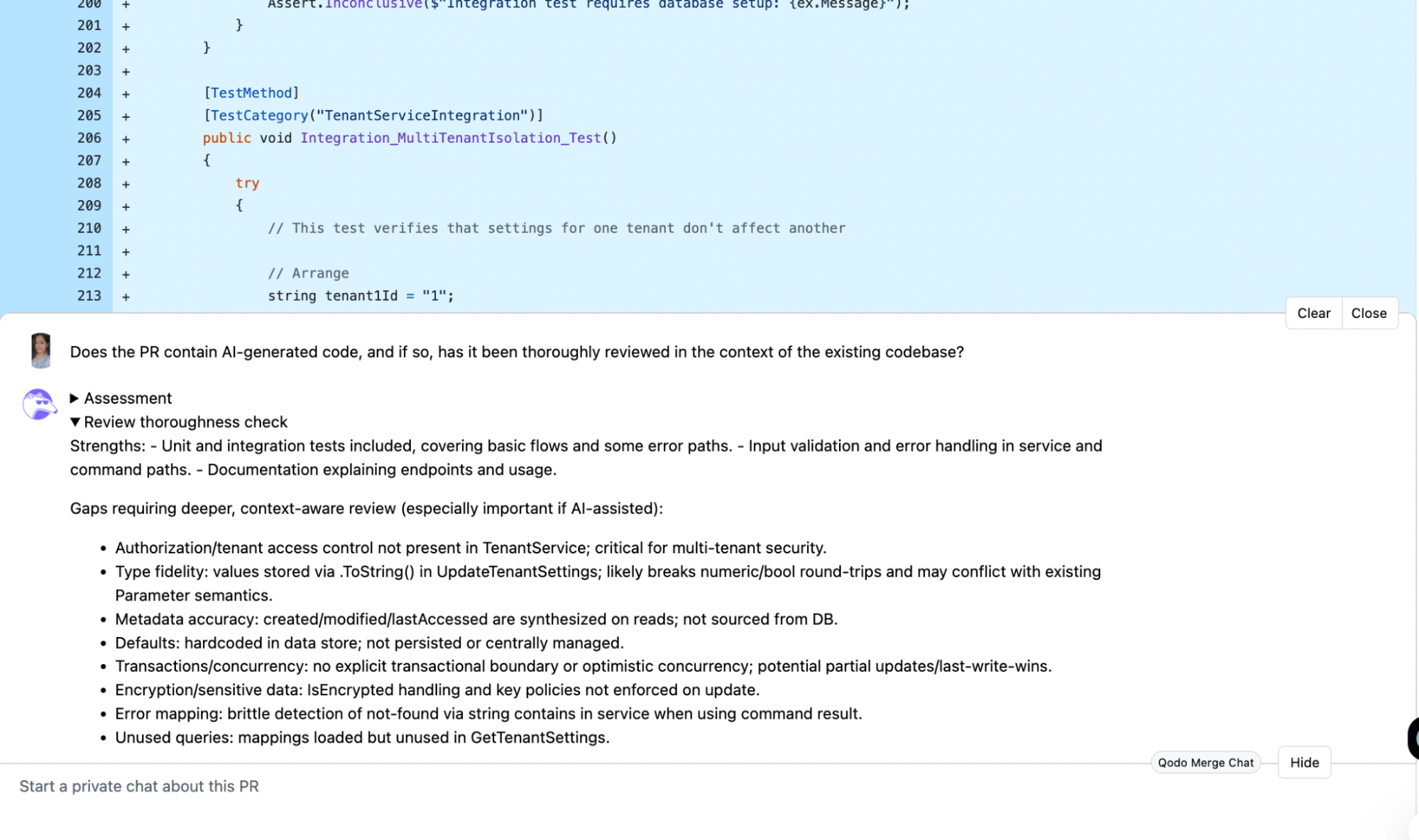 In the review, Qodo flagged that parts of the PR were AI-generated and recommended a thorough human review, particularly for tenant isolation, authorization, and multi-tenant data consistency. It identified missing authorization checks in TenantService, potential type fidelity issues in UpdateTenantSettings (values stored as strings may break numeric/bool round-trips), and synthesized metadata (CreatedDate/LastAccessedDate) not sourced from the database.
In the review, Qodo flagged that parts of the PR were AI-generated and recommended a thorough human review, particularly for tenant isolation, authorization, and multi-tenant data consistency. It identified missing authorization checks in TenantService, potential type fidelity issues in UpdateTenantSettings (values stored as strings may break numeric/bool round-trips), and synthesized metadata (CreatedDate/LastAccessedDate) not sourced from the database.
It also gave me certain gaps that required deeper and context-aware review in the AI-assisted code. This ensures that AI-generated code is not blindly merged without context-aware review. And that senior engineers could prioritize high-risk areas, preventing potential production incidents.
Qodo doesn’t just flag issues; it creates a virtuous cycle, learning from every interaction to improve future detection and remediation. This is what Qodo calls the Flywheel, where deep understanding fuels enforcement, intelligent fixes, and continuous monitoring with actionable insights back to the team.
For example, in TenantService.cs, Qodo highlighted silent failure spots that could occur if exceptions were wrapped without proper logging, or if type mismatches went unnoticed. It suggested unit tests for wrong data types, missing authorization, and oversized payloads, ensuring edge cases are handled consistently.
Through its shift-left approach, these issues can be caught early in the IDE or CLI before they become expensive to fix. At the same time, the enterprise-grade PR review provides a strong gate in Git, ensuring that code entering production has been thoroughly validated.
One-Click Remiadation in PR Comments
The above prompts I asked were to the Qodo Merge Chat and got the responses as per. I will now show you how you can use the Qodo Merge Tools like /review, /analyze, etc, to ensure a proper code quality measurement and reviews for your PRs.
I asked Qodo to suggest “/review what are the optional code suggestions in this PR that might affect production code?”
Like, look at the snapshot below:
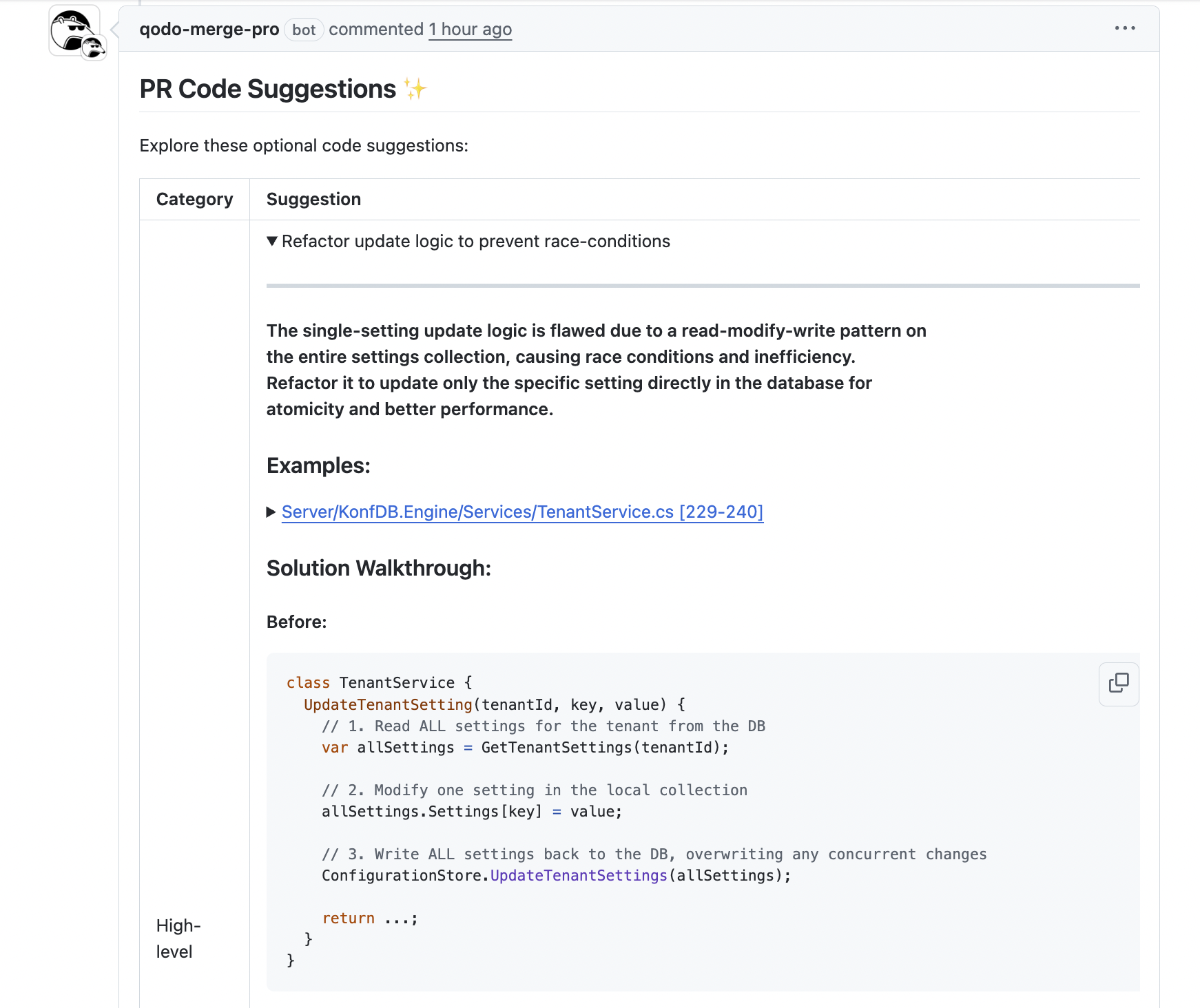
The one-click remediation feature is another game-changer. Once Qodo identifies gaps, like missing validation or inconsistent error handling, it can generate actionable fixes directly, integrating with other coding agents to implement changes efficiently.
In the image above, Qodo has identified that the original UpdateTenantSetting method followed a read-modify-write pattern on the entire settings collection. This approach created a risk of race conditions and inefficiency, especially when multiple updates occurred concurrently.
Qodo suggested refactoring the method to update only the specific setting directly in the database using a new UpdateSingleTenantSetting method. Here’s the snapshot of the suggestion:
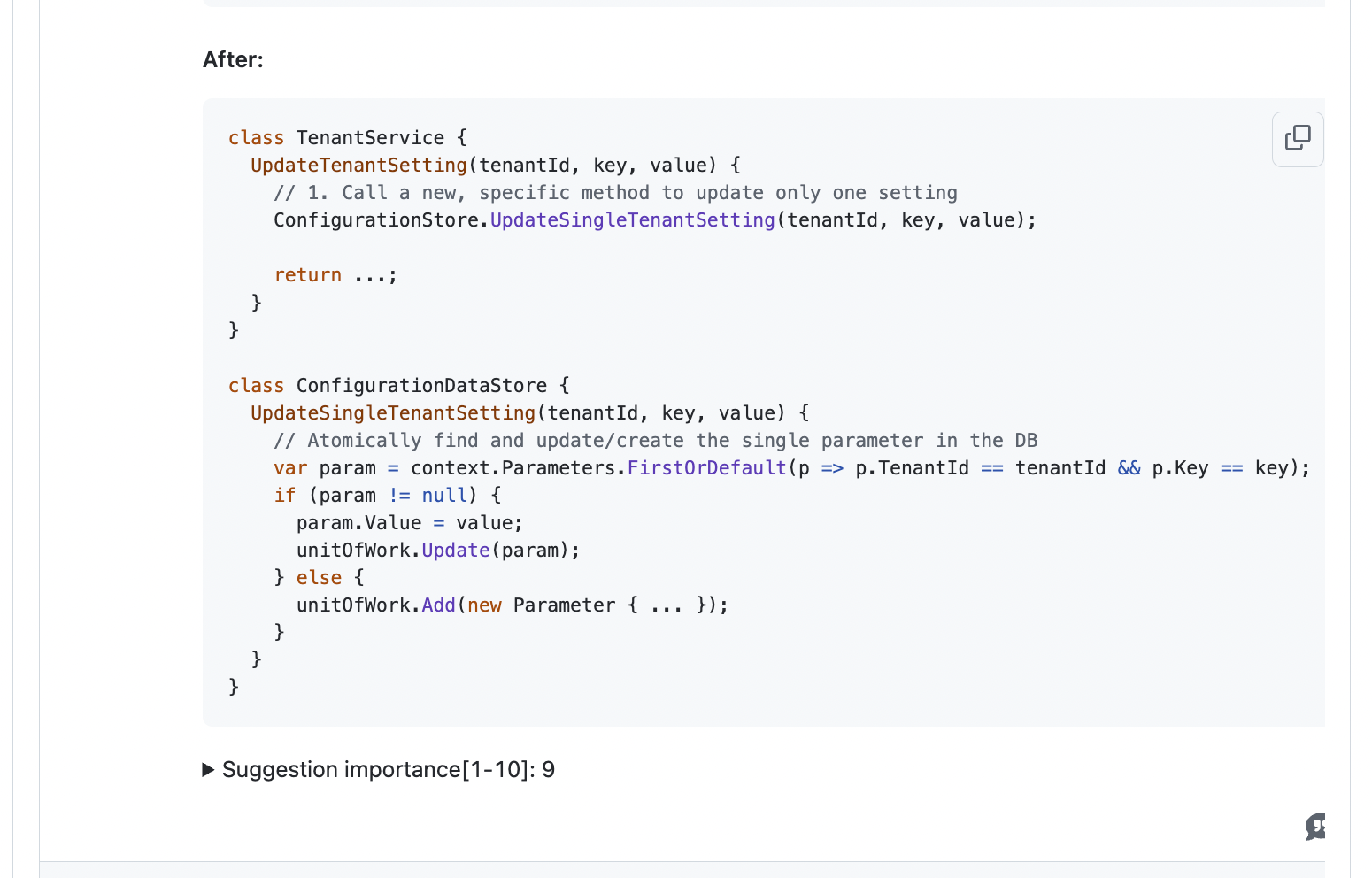
Qodo identified that the original UpdateTenantSetting method read all tenant settings from the database, modified one locally, and then wrote the entire collection back. This read-modify-write pattern introduced a risk of race conditions: if multiple updates happened simultaneously, one could overwrite another, leading to data loss or an inconsistent state. It was also inefficient, unnecessarily loading and writing the entire collection for a single change.
The suggestion was to refactor the method to update only the specific setting directly in the database via a new UpdateSingleTenantSetting method. This atomic update ensures that each setting change is isolated, consistent, and safe even under concurrent operations.
The importance of this suggestion was rated 9/10 because it directly impacts the reliability, maintainability, and correctness of the system, all of which are important for production readiness. Implementing this recommendation reduces subtle bugs, prevents potential multi-tenant data corruption, and aligns the code with architectural best practices.
These features are really helpful for someone like a Head of Engineering, who manages multiple teams and repositories. The challenge isn’t just shipping features; it’s ensuring that every change, especially AI-assisted code, meets architectural and business standards. With Qodo, each pull request highlights the high-risk files, gets edge cases, and indicates whether senior or domain-expert review is necessary.
Conclusion
Today, code quality measurement for enterprises goes beyond tests and coverage; it’s about ensuring changes are contextually correct, secure, and aligned with architecture. Qodo makes this tangible by providing context-aware insights, highlighting high-risk files, surfacing edge cases, and offering actionable PR suggestions.
Teams get clear guidance on which parts of a pull request need senior review, where AI-generated code may introduce risks, and how to align changes with organizational standards. This reduces guesswork, prevents hidden technical debt, and ensures code is consistently merge-ready.
For engineering leads managing multiple teams and repositories, Qodo transforms code quality into measurable, traceable signals across the entire SDLC, helping enterprises move fast without compromising reliability or architectural integrity.
FAQs
How can enterprises effectively measure code quality beyond traditional metrics?
Combine standard metrics with context-aware reviews and high-risk file checks. Track operational signals like rollback frequency, MTTD, and MTTR. This ensures code is production-ready and reliable.
How do AI-generated code changes impact code quality measurement?
AI-generated code may pass tests but still break architecture or business rules. Context-driven reviews and edge-case checks are essential. Tools like Qodo highlight high-risk areas and enforce production standards.
What is Qodo, and how does it help ensure code quality across the SDLC?
Qodo is a developer-focused platform designed to manage the full code review lifecycle across the SDLC. It uses deep code understanding to highlight high-risk files, identify edge cases, enforce organizational standards, and provide actionable guidance from local development through CI/CD pipelines and production. By shifting left, it detects and fixes issues early while maintaining strong review gates, helping teams ensure code is consistent, secure, and production-ready.
How does Qodo improve pull request reviews?
Qodo makes pull request reviews much easier and more effective by showing exactly which files or changes are high-risk and where edge cases might be missed. It gives reviewers clear, context-aware guidance so they can focus on things like architecture, security, and business rules instead of just checking if the code runs. By combining a deep understanding of the code with practical recommendations, Qodo helps teams catch problems early and make sure every change is safe and ready for production.
Can Qodo help manage AI-assisted development workflows?
Yes. Qodo integrates AI-awareness into code reviews, highlighting areas where AI-generated code may deviate from architecture or business logic. By combining automated suggestions with context-aware review prompts, Qodo ensures AI-assisted code is evaluated for safety, maintainability, and merge-readiness, reducing hidden technical debt.