Context Engineering: The New Backbone of Scalable AI Systems
TL;DR
- Context engineering goes beyond prompt engineering by managing all inputs to an LLM, including instructions, memory, history, and structured formats.
- RAG (Retrieval-Augmented Generation) is central to this process; it retrieves real-time, relevant data from external sources like docs, APIs, or code to reduce hallucinations through contextual retrieval of codebase, documentation and history..
- Unlike fine-tuning, RAG is dynamic and more maintainable; it separates knowledge from model weights and adapts context per query.
- Context engineering involves combining multiple strategies: prompt design, memory systems, and RAG to better control and guide model behavior.
- Tools like Qodo streamline this process by compiling and injecting the right context automatically from your codebase, docs, and team inputs, without changing the model.
Generative models often surprise us with how inconsistent their outputs can be, even when asked the same question in different ways. In a 2023 study by the Stanford Center for Research on Foundation Models, GPT-3.5 was shown to answer a coding problem correctly 52% of the time when the prompt included step-by-step reasoning, but only 19% without it.
Similarly, OpenAI’s own evaluation revealed that retrieval-augmented prompts could improve factual accuracy by over 30% compared to naive completions without retrieved evidence (OpenAI Cookbook). These results highlight a growing realization: how you provide context to an LLM often matters more than what model you’re using.
As a Developer myself, I’ve often run into situations where I had to prompt an LLM repeatedly just to get a useful answer. I can’t afford to waste time re-explaining the same context over and over. If the model doesn’t “remember” or isn’t given the right context up front, accuracy drops and productivity suffers. That’s why context engineering is the perfect solution for all the problems that I face, or many other senior developers do.
As systems become more complex, with hybrid architectures, vector stores, and long context windows, the need to carefully shape what information is delivered, in what format, and with what retrieval logic, has become central to model performance and safety.
If we want LLMs to be useful, safe, and consistent in real-world applications, we have to shift our attention from just writing better prompts to creating and delivering better context. That includes not just what we retrieve, but how we format it, when we inject it, and how we control the flow of information into the model. The smarter our context pipeline, the smarter our LLM system becomes.
What Do We Mean by “Context”?
When I talk about context in the world of LLMs, I’m referring to more than just a cleverly worded prompt. Context is the entire input sequence the model sees before it generates a single token. It’s the combination of every piece of information, explicit or implicit, that guides the model’s reasoning and response.
As Andrej Karpathy aptly put it, “LLMs don’t think in abstract, they read tokens” (Karpathy on X). That tweet sums it up well. Models don’t intuit what you mean; they process raw token streams. That’s why it’s important to carefully construct the right context, so the model has the best possible input to reason over.
Karpathy points to the broader architecture that wraps this context work: routing logic, retrieval layers, eval harnesses, UI/UX flows, and generation-verification loops. That’s why context engineering isn’t just a developer task; it’s infrastructure. It’s how modern LLM apps maintain consistency, correctness, and performance under load. So, if the right tokens aren’t in the input, the model can’t guess its way to the right answer. How we construct that input, what we feed, and how we feed it directly shape the output.
So, What is Context Engineering?
We all have heard about “prompt engineering,” which is mainly about giving the right instructions to a large language model (LLM). But “context engineering” is like an umbrella that spans across several types of context.
Take this illustration as an example:
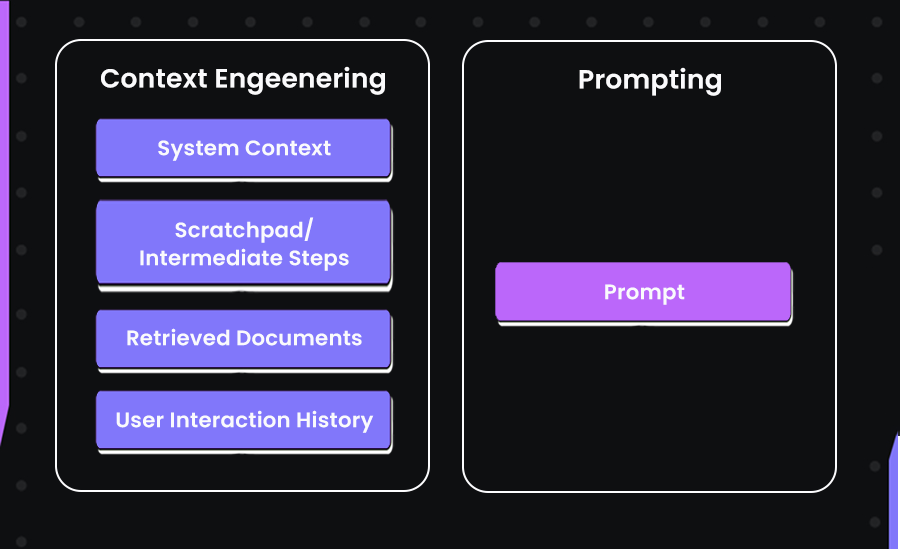
In this image, we can see that on the right side, we see traditional prompting, where a single block of instruction is sent to the model. It’s simple but often limited in depth and can result in hallucinations as there’s no context to the prompt.
On the left, context engineering takes a more layered approach. It combines system instructions, retrieval-based documents, prior interactions, and even scratchpads to form a richer environment for the model. Each of these elements plays a role in helping the AI understand not just what you’re asking, but also the broader context around it, much like how a developer thinks through previous code, documentation, and current tasks before writing a new function.



You might ask, “Isn’t this just the same as RAG?” That’s a fair question. It does include retrieval, but context engineering means more than that. It’s about choosing and organizing the right details to fit into the LLM’s limited input space, making sure every part of that space is used wisely.
We’ll see further how context engineering is useful for modern LLMs and what applications we can use to make the most out of it. But before that, let’s understand what the key components are that make up context engineering.
Key Components of Contexts
Let’s now understand the key components of context that enable large language models to operate effectively across a variety of tasks. A well-designed context setup combines these elements together, giving the model the right information at the right time.
The diagram below offers a simple way to visualize how context is constructed and passed into a large language model. Just like how a CPU depends on data loaded into RAM to operate, an LLM relies on a context window filled with the most relevant information for a given task.
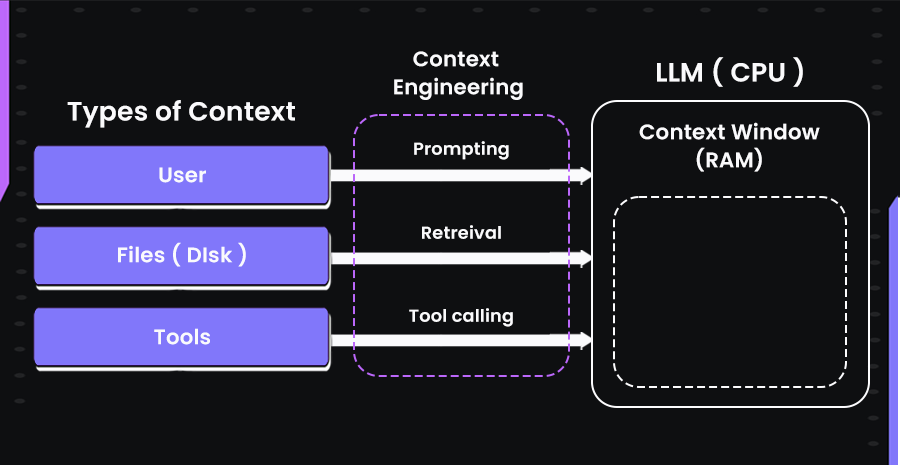
Here are the core components that make up such a context system:
System Instructions
These are overarching rules or identity definitions that set the boundaries for the model’s behavior. For example, setting the model’s role as “You are a senior Python developer assisting with AI code reviews” ensures that every response is shaped through that lens. These instructions persist across interactions and influence how the model interprets ambiguous input.
User Input (Current Prompt)
This is the immediate question or command from the user. It might include parameters, constraints, or goals (e.g., “Refactor this function to improve performance”). Though simple, this part often determines how the rest of the context is used.
Chat History (Short-Term Memory or Files)
To maintain continuity in a session, models rely on recent messages. For example, if a user previously asked, “Generate a Flask route,” and now says, “Make it async,” the system needs access to prior exchanges to respond correctly.
Long-Term Memory / User Profile
Some systems store persistent information like usernames, past decisions, or prior project states. If a user often prefers TypeScript over JavaScript, that preference can be carried over to new sessions. This is especially useful for developer agents that repeatedly assist with large codebases or teams.
Retrieved External Knowledge (RAG)
To provide up-to-date or highly specific answers, models often retrieve documents or facts in real time. For example, fetching internal API docs, searching a vector database of past tickets, or retrieving relevant Stack Overflow threads. These retrieved chunks are embedded directly into the context window, improving factual grounding.
Tool and API Context (Tools)
When working in environments with external tools, models need to know what functions are available. This might include a schema for lookup_weather(city) or CLI commands available to the model. The definitions, capabilities, and even outputs of these tools (e.g., response from an API or logs from a terminal) are passed back into context for further processing.
Code Files and Terminal Outputs
In coding assistants, raw code from the open editor tabs, the directory structure, and even terminal output (like test results or build logs) can be passed as context. This mirrors real-world usage in tools like Qodo, where the model’s suggestions depend heavily on what’s visible in the code buffer or recently executed in the terminal. This context helps disambiguate imports, detect missing dependencies, and provide highly relevant completions.
Structured Output Templates
Sometimes the model needs to follow a specific format, such as a JSON schema, YAML config, or markdown table. Including this structure in the prompt helps enforce the correct output format. These templates are particularly helpful when integrating LLMs into pipelines or workflows expecting machine-readable results.
Why Context Matters for Modern LLMs?
Large language models (LLMs) are extremely powerful, but fundamentally, they are stateless token predictors. They don’t carry memory across calls unless we explicitly include that memory as part of the input.
As a result, each time an LLM is invoked, it starts from scratch, processing only what it sees in the current context window. This is why context isn’t just important, it’s essential. Without it, the model has no grounding, no memory, and no way to stay consistent over time.
Real-Life Application of Context Engineering
For example, a customer-support agent with context knows the user’s order history and past tickets, so it can give personalized help rather than a generic response. A calendar assistant with context knows your free/busy times and email threads, so it can schedule meetings without asking redundant questions.
Such assistants feel intelligent because they remember past interactions, apply business rules, and access up-to-date knowledge all at once
The Constraint: Limited Context Windows
Managing these issues comes down to one thing: working within the model’s limited context window. Whether you’re dealing with 4K tokens or 100K, there’s still a boundary. And models have their own quirks; many struggle with long middle sections, get anchored on recent tokens, or ignore unstructured chunks.
That means we have to think like systems engineers. Not just “what information should go in?” but “what order, what format, what level of fidelity, and what do we trim or compress?”
And here’s where contexts work wonders in LLM development. It goes beyond prompt tuning and into the realm of runtime input management. Harrison Chase, CEO of LangChain, puts it well in a recent LinkedIn post:
“Context engineering is building dynamic systems to provide the right information and tools in the right format such that the LLM can plausibly accomplish the task.”
— Harrison Chase on LinkedIn
RAG: The Foundation of Context Engineering
Retrieval-Augmented Generation (RAG) plays a key role in context engineering, but it is just one component of a broader system. RAG focuses on retrieving relevant documents or data from external sources to enrich the context window of an LLM. This helps the model generate more grounded and informed responses, especially in scenarios where the base model’s training data is insufficient or outdated.
Here’s an image that explains very clearly how RAG is an essential part of context engineering:
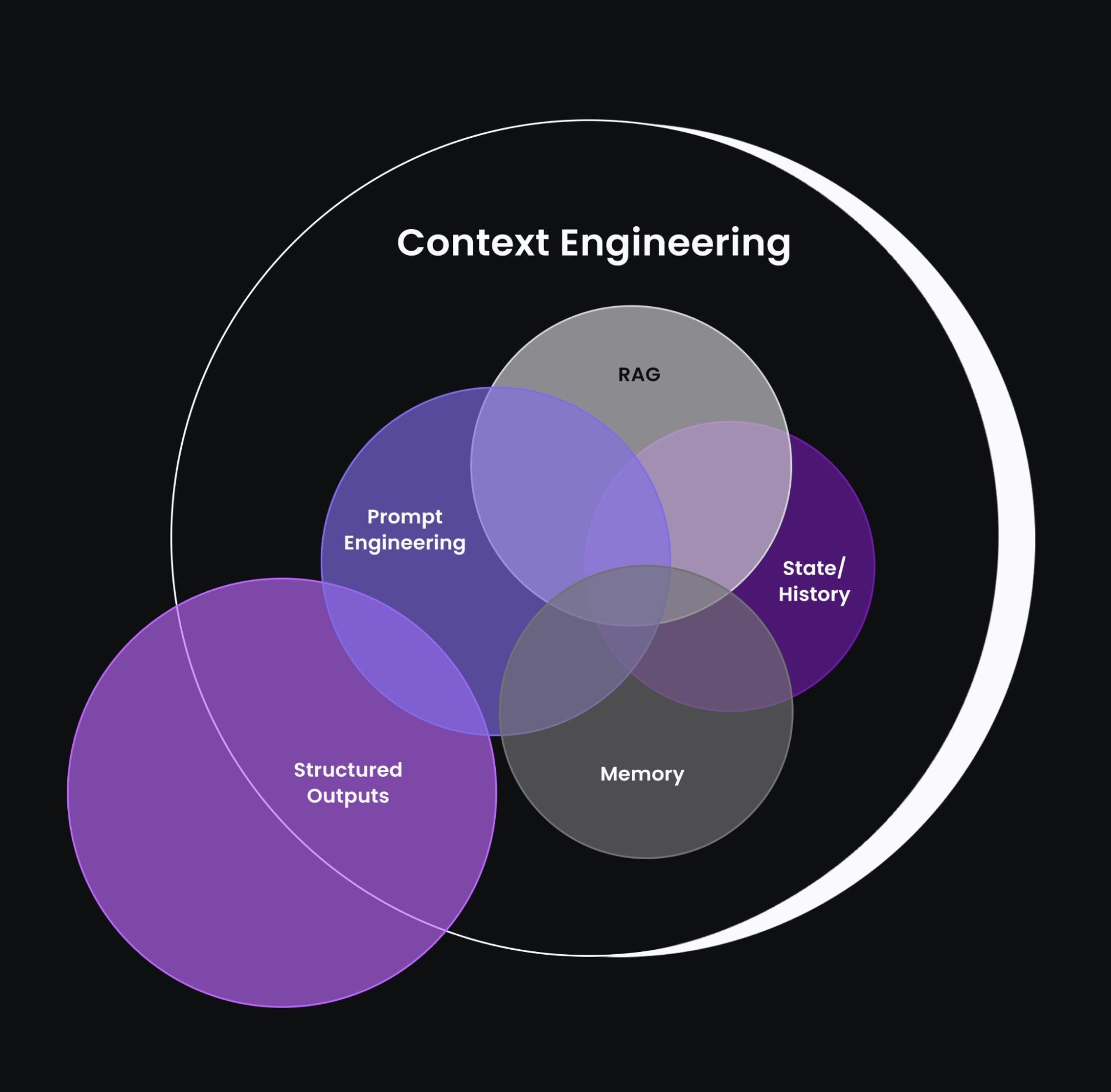
However, as the diagram shows, context engineering spans far beyond RAG. It includes prompt engineering, which involves crafting precise instructions; memory systems that persist long-term information; state and history tracking to maintain conversational continuity; and mechanisms for structured outputs that guide response formats. RAG works in conjunction with these other systems rather than replacing them.
RAG complements these systems rather than replacing them. Its strength lies in enriching the context dynamically, allowing models to operate on real-time knowledge without modifying their core parameters.
This retrieval-first approach solves a core limitation of LLMs: their tendency to hallucinate when asked about topics not well covered during training. RAG counteracts that by pulling factual payloads from a knowledge base, be it a document store, API response cache, database, or even a code repository.
The model then uses this grounded context to produce more relevant, specific, and trustworthy outputs. That’s why it’s important for engineering teams to adopt tools like Qodo that support context-aware generation natively
It’s also important to understand how RAG vs fine-tuning are different and how developers often confuse them to be more or less the same thing. While fine-tuning involves retraining a model on custom data to specialize it for a particular domain, it has key limitations. It’s expensive, requires ML infrastructure, and is static; new knowledge or changes in the source data require retraining the model.
RAG, in contrast, is dynamic and decouples knowledge from the model itself. The retriever can be updated independently, the context can adapt per query, and the generation remains flexible without altering the model weights.
Practically, teams often combine both strategies, but for most use cases where recency, agility, or domain depth are required, RAG is faster to iterate and more maintainable than fine-tuning.
Dynamic Context Engineering with Qodo’s RAG
In Qodo Gen Chat (which uses RAG), context acts as the model’s working knowledge of your codebase. It’s what the AI refers to when responding to prompts, ensuring that its outputs are relevant, accurate, and aligned with your project structure. The more meaningful and specific the context, the better the quality of suggestions or code completions it can generate.
You can provide context to Qodo Gen in several ways. One common method is to select a portion of code directly from your editor. By right-clicking on the selected snippet and choosing the option to add it as context, you make that code available to the model. For quicker access, there are shortcuts available.
In VS Code, you can use Cmd+Shift+E on macOS or Ctrl+Shift+E on Windows. If you’re using JetBrains IDEs, the shortcuts are Cmd+Option+Comma for Mac and Ctrl+Alt+Comma for Windows.
For larger projects, you might want the model to consider the complete codebase. Qodo Gen allows you to add your entire repository under the Files and Folders section. This ensures the AI has full visibility into your project’s structure, dependencies, and conventions.
Additionally, Qodo Gen supports visual context. You can upload images, such as UI mockups or design references, which the model can then use to generate matching components or layouts.
First Hand Example
Let’s understand this through an example:
I started with an existing codebase that included a basic Express server, a db/schema.sql file, and some shared packages under a packages/ folder. My goal was to introduce a new metrics service that could return analytics data based on the current database schema. Instead of writing everything manually, I decided to build this incrementally using Qodo Gen.
I started with a simple prompt:
“Create a metrics-service in services/metrics-service that exposes a /daily route. It should read from the existing Postgres schema in db/schema.sql, use shared DB utilities if available, and return dummy metrics for now.”
Qodo responded by creating the metrics-service folder with a proper Express app structure. It reused the shared DB config from packages/db-utils, connected to the database using pg, and added a /daily route that returned mocked data. The generated code respected the import conventions already used in the monorepo, including internal paths and logger patterns.
Here’s a snapshot:
Once the service was in place, I wanted to ensure schema consistency before deploying anything. So I asked:
“Create a script inside packages/db-utils/ that compares the current db/schema.sql file with the deployed schema version. It should warn about mismatches and log specific line differences.”
Here is the screenshot of the output:
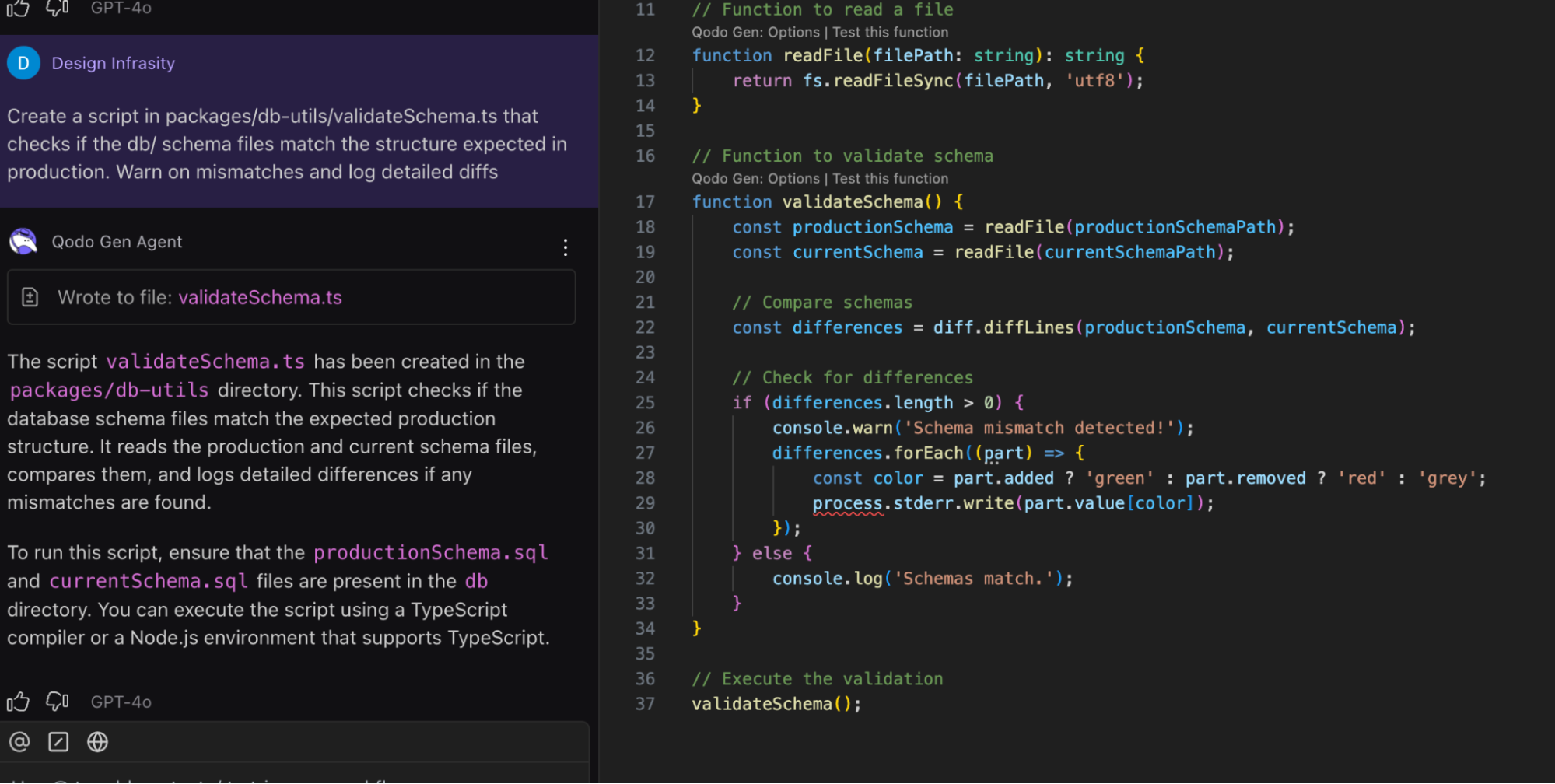
The result was a TypeScript utility called validateSchema.ts. It loaded both schema files, compared them line by line, and highlighted differences using colored console output. This helped me catch uncommitted or unintended schema changes early, without relying on an external diffing tool.
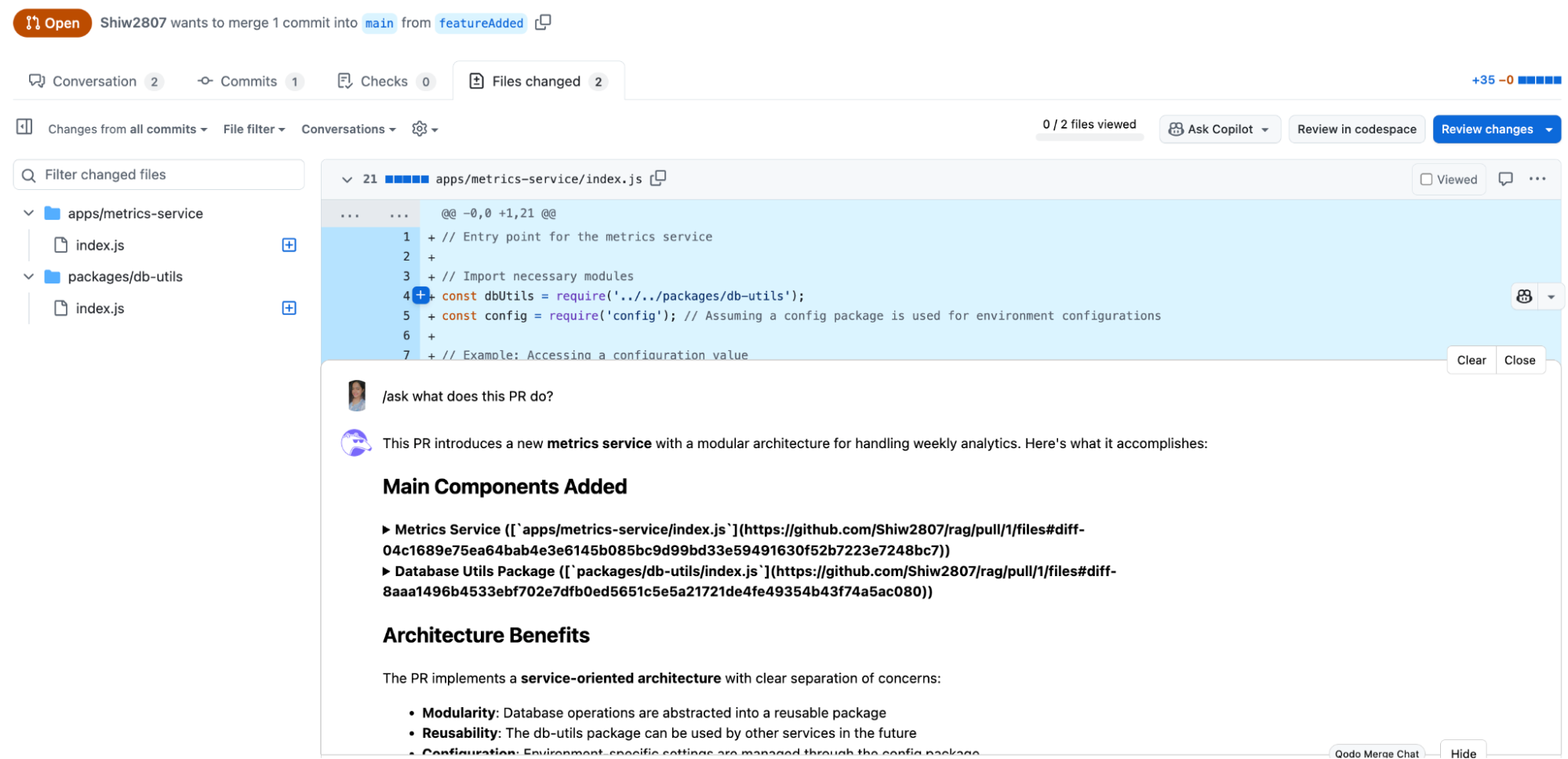
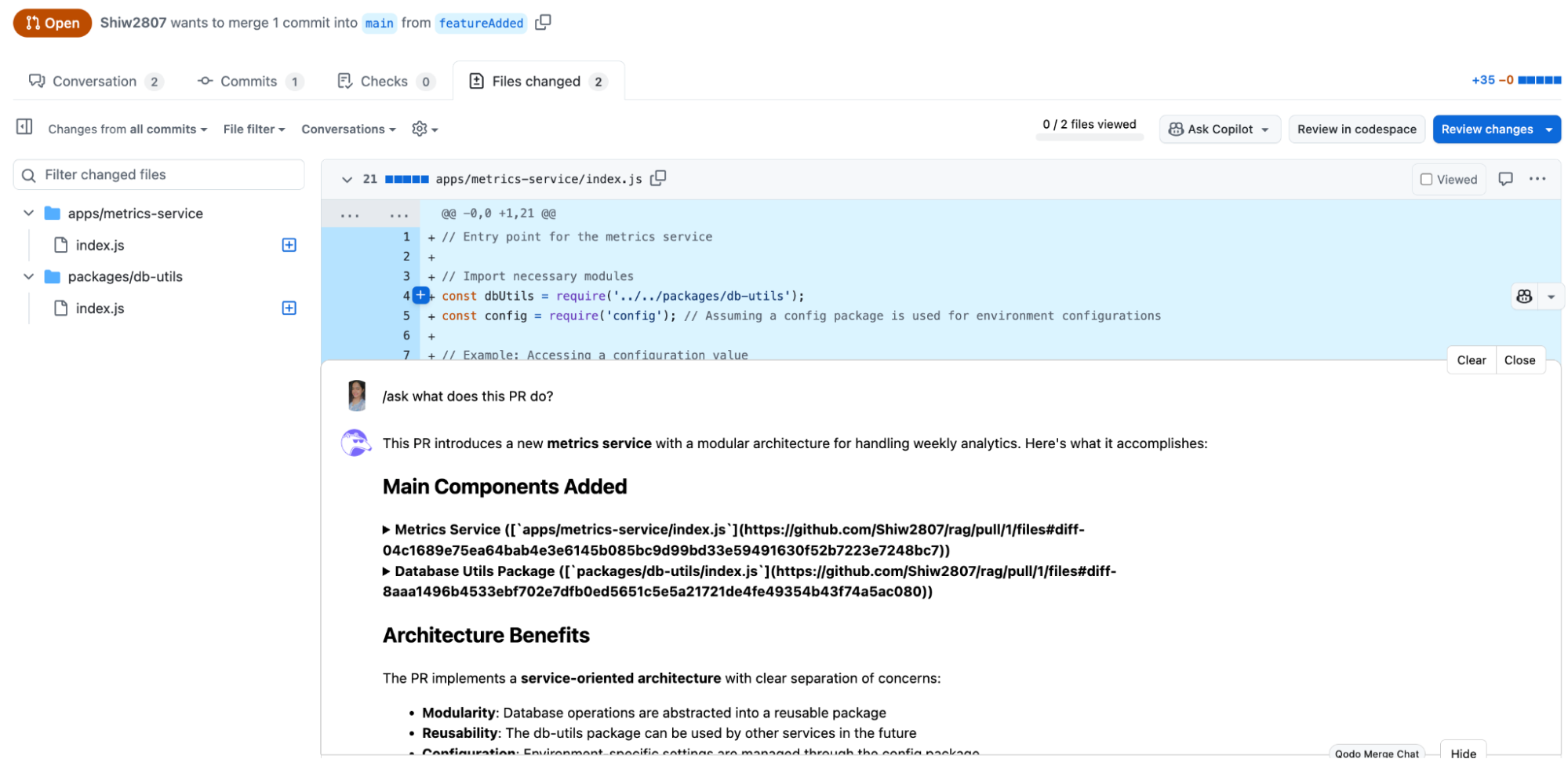
When I raised a PR for this change and asked Qodo Merge what changes were made, and what does this PR, it listed to me all the components that were added. That really made everything easier to begin with!
As I moved toward completing the implementation, I wanted to ensure the changes were safe to merge. So, I asked Qodo Merge:
“Can I safely merge this if the staging schema hasn’t changed?”
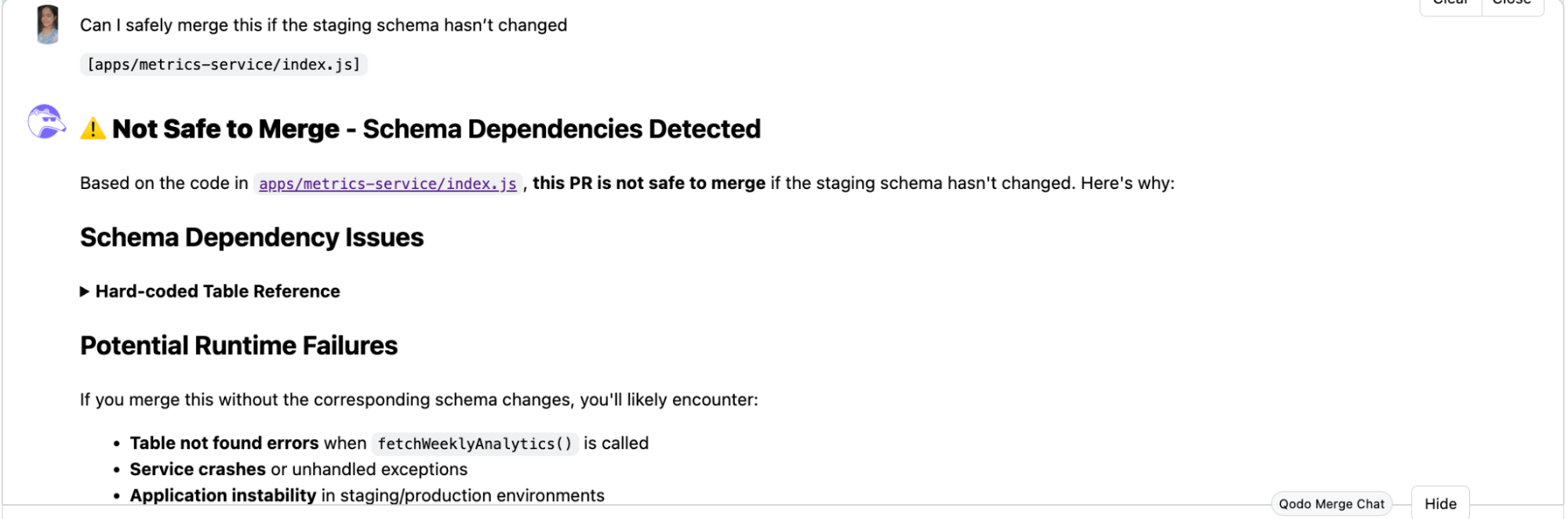
The response was immediate and insightful. Qodo flagged the pull request as Not Safe to Merge due to Schema Dependencies Detected in apps/metrics-service/index.js. It pointed out a hard-coded table reference being used inside the function fetchWeeklyAnalytics(), which relies on schema changes that hadn’t yet been applied to the staging environment.
This kind of analysis gave me a clear signal: unless I update the schema in the staging environment or abstract the dependency from the hard-coded table, merging would break the service.
Rather than risking that, I now knew exactly what needed to be done: either sync the schema across environments or implement a fallback mechanism before merging.
Qodo brings context engineering to the center of enterprise-grade development. Instead of relying on generic code generation or retrieval alone, it gives teams like mine precise control over how context is assembled, shaped, and passed into the generation process. It’s context compilation, treating your repo, your workflows, your environment as the source of truth, and using that as the real “input” to the LLM.
Context Engineering Turns LLM Work into Scalable, Testable Systems
For Senior Developers, context engineering elevates LLM work to a system-design discipline. Instead of playing around with prompts ad hoc, developers build modular pipelines (similar to software patterns) for data retrieval, memory, and API integration. This means LLM-based features become easier to debug and scale: each part of the context pipeline can be tested and optimized.
Moreover, AI coding assistants and agent frameworks that use context engineering improve over time as they gather project-specific knowledge. For example, platforms like Qodo learn a project’s structure, coding style, and recent changes (via context) and thus become more helpful to developers over time.
Build Smarter Agents with Qodo’s Modular Context
Most enterprise-grade systems today use embeddings to index internal documents and retrieve relevant chunks at runtime. But the gains don’t come from retrieval alone. The real improvements show up when teams engineer how retrieved data is shaped and delivered to the model, how instructions are structured, how formatting is aligned with downstream expectations, and how metadata like timestamps, roles, or priorities are preserved in the context window.
As a Senior developer with several years of experience on enterprise-grade projects, I’m always fond of tools that understand the codebase deeply and empower you to build smarter agents. This is where I’ve found Qodo particularly effective. As a context engineering platform, Qodo goes beyond simple RAG retrieval.
From a developer’s perspective, Qodo supports retrieval-augmented generation (RAG) by making all context sources pluggable. You can embed files from GitHub or local repos, index API responses, pull in documents from Confluence or Notion, and fetch them dynamically at generation time.
Conclusion
As large language models evolve and integrate deeper into real-world systems, the challenge is no longer just about making them smarter, but about making them context-aware. The shift from prompt engineering to context engineering marks a significant leap in how we build and scale LLM-powered applications.
It is not simply about phrasing better questions; it is about constructing the right input environment where the model can reason accurately, retrieve relevant data, and respond with precision.
Context engineering brings systems thinking into AI development. It ensures that models operate with complete awareness of user preferences, codebase structures, live data, tool access, and domain-specific instructions.
Tools like Qodo demonstrate that effective context pipelines can drastically improve developer workflows, reduce errors, and unlock new levels of productivity. As context engineering matures, it is quickly becoming the foundation of trustworthy, consistent, and scalable AI systems.
FAQs
1. What does context mean in engineering?
Context refers to all the information that the model processes during inference. This includes the user prompt, retrieved documents, chat history, metadata, and system instructions. It’s what gives the model grounding, helping it generate relevant and accurate outputs. It is the complete input environment designed to guide the model’s behavior.
2. What is the difference between prompt engineering and context engineering?
Prompt engineering focuses on crafting the right text to get the desired output, choosing the right wording, format, and examples within a single prompt.
Context engineering takes a broader view. It includes prompt design but also involves retrieving relevant information, structuring inputs, formatting knowledge, and managing what goes into the model’s context window dynamically. It’s a systems-level approach rather than just clever phrasing.
3. What is the difference between context and prompt?
The prompt is a part of the context, typically the text a user types in directly. Context is the full set of tokens the model processes: the prompt, retrieved knowledge, instructions, and any memory or history passed in. So while every prompt is context, not all context is prompt.
4. What is the full meaning of context?
Context refers to the collection of all relevant information provided to the model at inference time to help it generate accurate, relevant, and consistent responses. This includes the user’s prompt, previous conversation history, system instructions, retrieved documents, file contents, metadata like timestamps or user roles, and even codebase structure
5. Is prompt engineering in context learning?
Prompt engineering is a component of context learning, but not the whole of it. Prompt engineering focuses on crafting clear and effective instructions to elicit the desired output from the model. Context learning, on the other hand, is a broader discipline that includes not only how prompts are written but also how relevant supporting information is selected, structured, and passed into the context window.


