Top 5 DevOps Tools for Enterprise Engineering Teams in 2026
TL;DR
- DevOps tools act on changes committed in pull requests, such as updates to application code, such as API handlers, and business logic, infrastructure as code (IaC) definitions in Terraform, configuration like environment variables and service endpoints, and database schema. Pull request changes such as including application code, infrastructure definitions, configuration, and schema, trigger CI pipelines, apply infrastructure updates, deploy services, and generate runtime signals
- GitLab confirms pipeline execution, Terraform shows infrastructure changes, Kubernetes reflects runtime state, and Datadog flags system behavior in production. Pipelines confirm execution, Terraform shows infrastructure changes, Kubernetes reflects runtime state, and Datadog surfaces system behavior in production.
- Qodo evaluates application logic and infrastructure changes, including Terraform diffs, schema updates, and API behavior, during development and review, before they reach CI/CD pipelines.
- This guide explains where each tool fits, what it validates, and how they work together in a DevOps workflow
Most infrastructure failures don’t show up in CI — they show up after merge. Across GitLab pipelines, Terraform, Kubernetes, and Datadog, the pattern is consistent: pipelines pass, Terraform applies cleanly, workloads stay healthy, dashboards stay green, and the incident still happens hours later in a downstream environment.
The failures share a shape. An API change removes a fallback and breaks older clients; a Terraform update shifts resource dependencies and causes a partial rollout; a schema change adds a required field that existing rows don’t populate; or a config change hardcodes a value that works in dev but fails everywhere else.
Pull requests make this worse by bundling the risk into a single diff that touches application logic, API handlers, configuration, and Terraform together, so reviewers approve what’s in front of them while the blast radius extends to services and environments no one opened during review. Qodo’s 2025 State of AI Code Quality report found that over 80% of developers now use AI coding tools regularly and 65% report missing context in AI-generated code — and that gap between fast generation and confident deployment is where post-merge failures accumulate.
How to Evaluate DevOps Tools for Multi-Repo, Multi-Service Environments
In setups where backend services, frontend clients, shared libraries, and Terraform modules are maintained in separate repositories and deployed independently, a single pull request can affect multiple components that are not versioned or released together.
| Criteria | What is Evaluated | Example Scenario |
| Post-Merge Failure Types | Failures that appear after deployment despite passing CI | API change breaks existing clients or schema change affects existing data |
| Cross-Repository Dependency Impact | Impact of a change across services, APIs, and shared modules | API update in one repo breaks consumers in another |
| Review Load from AI Changes | Increase in PR volume and reduced familiarity with changes | Large AI-generated diffs with unfamiliar code paths |
| Enforcement at Pull Request Level | Whether checks are applied at the point of merge decision | Issues surfaced directly in PR vs delayed reports |
| Consistency Across Repositories | Whether the same validation and security checks run across all repos | One service enforces validation while another skips it |
Here’s how each tool performs across these criteria, starting with Qodo.
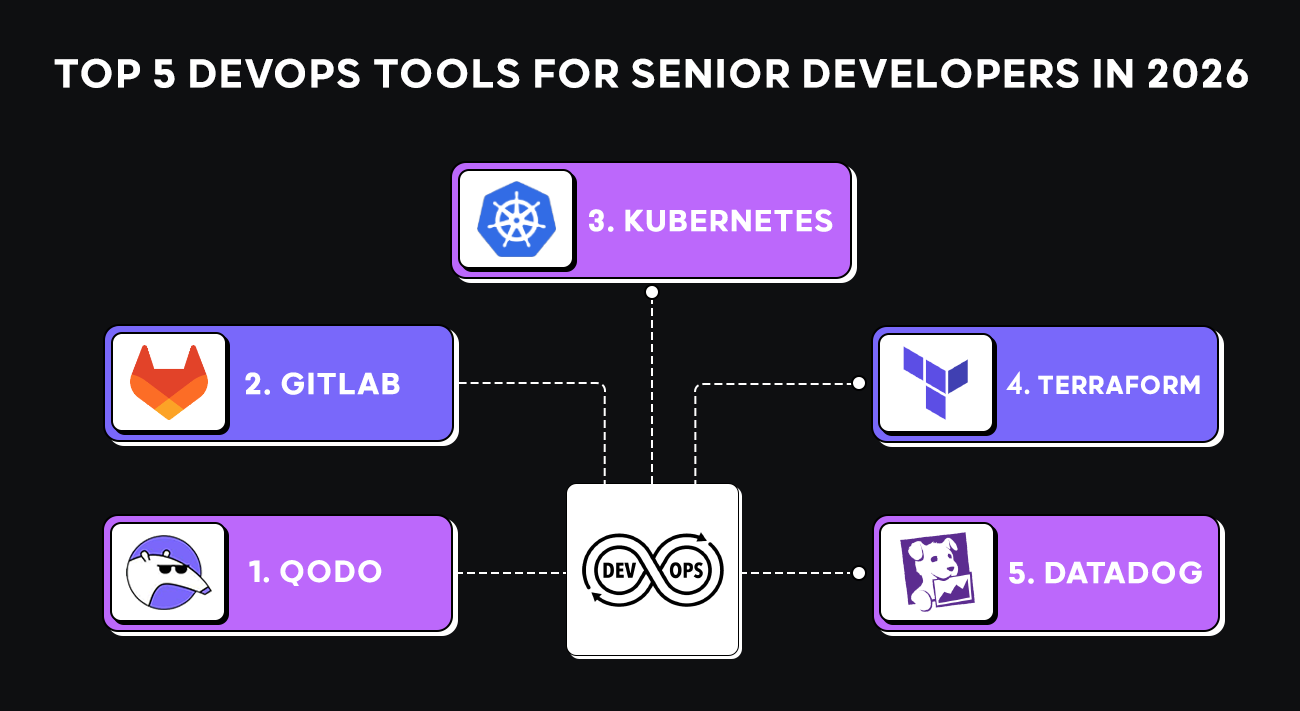
Top 5 DevOps Tools For Enterprises in 2026
1. Qodo
Qodo is an AI code review platform that operates inside pull requests, before changes reach CI/CD. It analyzes application logic, API behavior, Terraform diffs, and schema changes to flag risks that pipeline tools don’t evaluate.
GitLab confirms pipeline execution, Terraform shows planned infrastructure state, Kubernetes reflects runtime health, and Datadog surfaces production behavior, all after the change is already in motion. Qodo evaluates whether the change itself is safe to merge.
| What Qodo analyzes | Risk identified |
| API changes (response structure, removed fallbacks, validation logic) | Response change breaks existing clients |
| Database schema (new fields, constraints, existing data handling) | Required field not populated in existing records |
| Infrastructure definitions (Terraform/Pulumi dependencies, provisioning order) | Resource dependency causes partial rollout |
| Configuration (environment variables, endpoints, feature flags) | Hardcoded value fails outside development |
| Service interactions | Downstream service not updated for upstream API change |
Key capabilities
- Context Engine: Multi-repo indexing and cross-repo impact analysis, works across 10 repositories or 1,000
- Review Agent Suite: Specialized agents for Critical Issues, Breaking Changes, Duplicated Logic, Ticket Compliance, and Rules Enforcement
- Rules System: Auto-discovers coding standards, enforces them in review, and tracks whether rules are working over time
- Git Plugin: Integrates with GitHub, GitLab, Bitbucket, and Azure DevOps, no process rewrite required
- IDE Plugin and CLI Plugin: Catch issues before the PR is opened
- 4M+ PRs reviewed annually; 800+ potential issues prevented per month at monday.com; saves approximately one hour per pull request
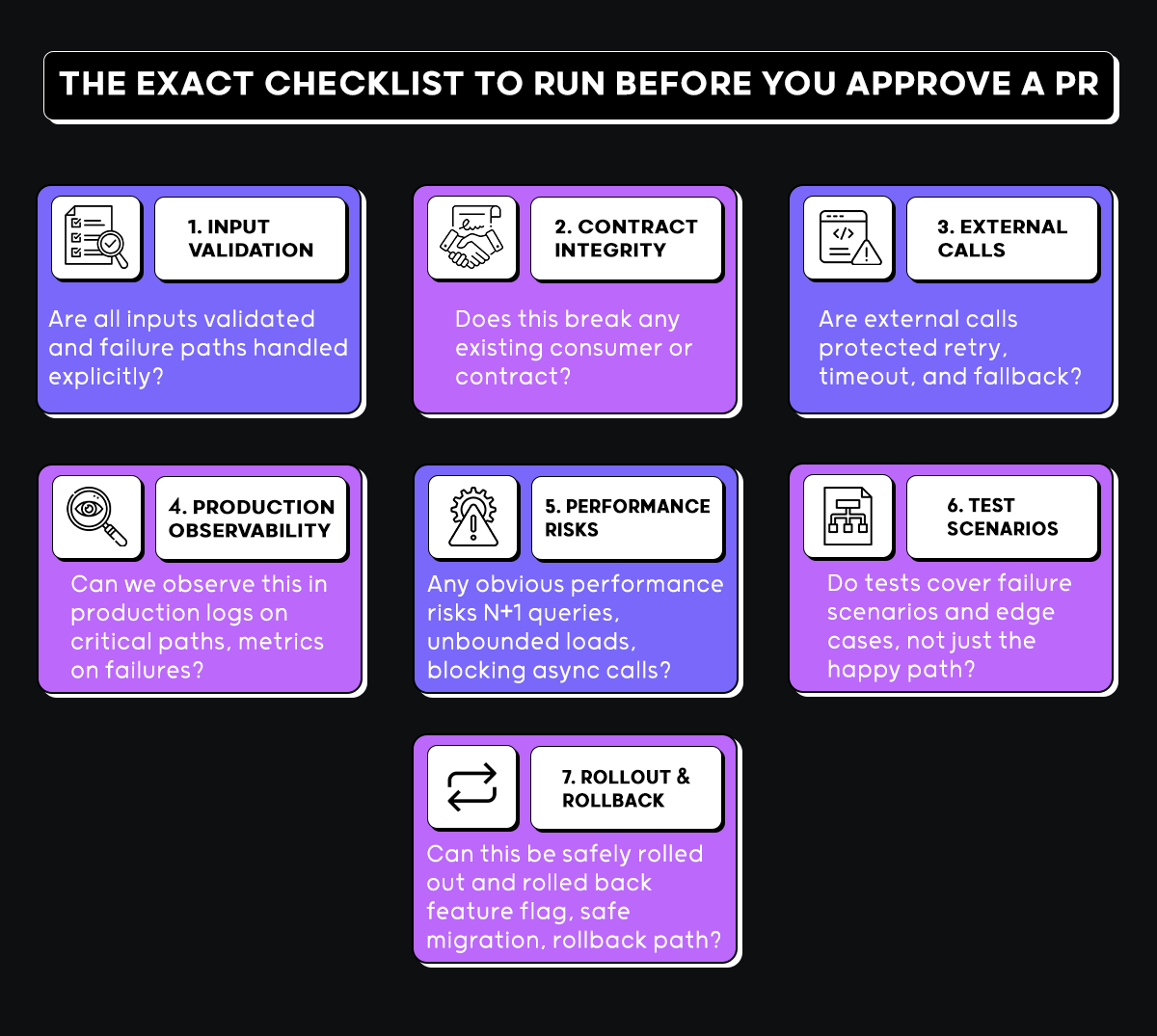
Hands-on example: Reviewing Deployment Risk and Quality Drift in a Production PR
When reviewing a pull request that crosses data models, APIs, and frontend consumption, the question is simple: can this change be deployed safely without coordinating multiple teams or accepting hidden risk?
Here’s how Qodo flags deployment order risks, environment mismatches, and silent data drift during PR review:
The PR Reviewer Guide screenshot above shows Qodo’s output for a real pull request running through that engine. Here’s what each flagged issue in that review means for deployment safety:
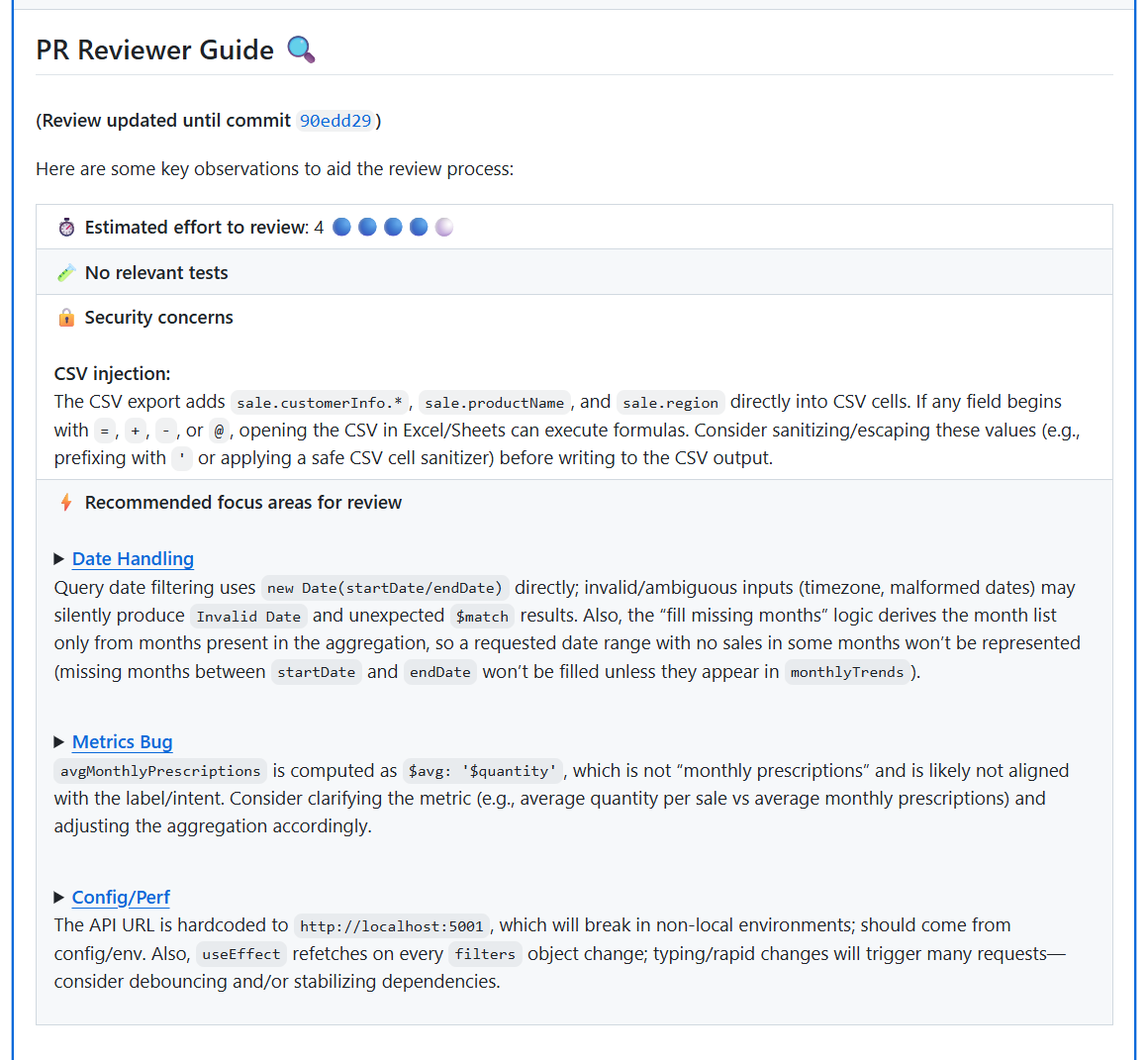
Deployment order risk: The frontend depends on a new backend endpoint for monthly trends. If the frontend deploys before the backend, the Reports page breaks immediately. Deploying the backend first is safe, the reverse order is not. This deployment order assumption isn’t encoded anywhere in the pipeline. On top of that, the frontend hardcodes the API base URL to localhost, which fails in any real deployment outside development, flagged in the screenshot under Config/Perf.
Data evolution risk: The PR adds a required region field to the Sale model with a default value. New writes succeed, but existing MongoDB documents don’t get region populated retroactively. The aggregation logic groups by $region, which means legacy records silently fall into null buckets. Dashboards render, but the numbers are wrong, this only surfaces after deployment when product teams start questioning reports. Qodo flags this directly under Metrics Bug in the PR Reviewer Guide.
Security risk: The CSV export adds sale.customerInfo.*, sale.productName, and sale.region directly into CSV cells without sanitization. If any field begins with =, +, –, or @, opening the file in Excel or Google Sheets can execute formulas, a CSV injection vulnerability that passes every CI check and lands silently in a production export. Flagged under Security Concerns in the screenshot above.
These are exactly the kinds of risks that pass CI and fail in production. Qodo surfaces them inside the PR, where the merge decision is made, not after deployment when the cost of fixing them is highest.
Strengths
- Surfaces risks at the merge decision point, before CI runs, before deployment
- Works across heterogeneous environments (multi-repo, multi-language, multiple Git platforms)
- Review Agent Suite provides focused, specialized feedback rather than broad noise
- Rules System enforces standards consistently across teams and repositories
Limitations
- Full value depends on aligning rules and standards upfront
- Best suited for organizations managing review across many repositories or large engineering teams
2. GitLab
GitLab usually enters an organization when teams outgrow ad hoc CI setups and need a repeatable way to manage merge requests, pipelines, and baseline security checks across many projects. It becomes the coordination layer between engineering and delivery, with the same pipeline structure, merge flow, and visibility, regardless of which team owns the repository.
GitLab runs what’s configured. It doesn’t evaluate whether a change is consistent with the broader system or organizational context, which sits outside pipeline execution.
Key Features
- Source code management with merge request workflows
- Integrated CI/CD pipelines configurable per project or shared across groups
- Built-in security scanning and compliance reporting
- Support for mono-repo and multi-repo setups
- Permissions and governance controls suited for enterprise teams
Hands-on example: What a Green GitLab Pipeline Confirms
When I review a change that touches .gitlab-ci.yml, my first check is whether the pipeline encodes any new delivery assumptions. As shown in the snapshot below, a green pipeline confirms that configured checks passed:
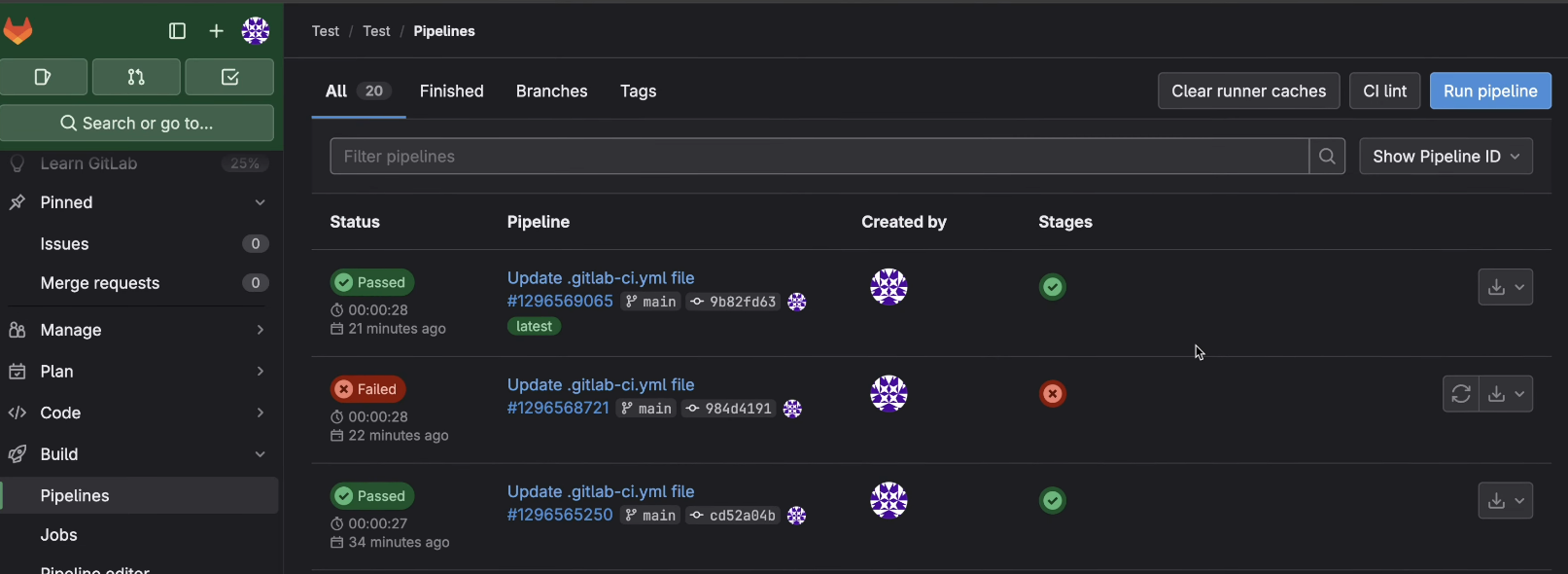
The code compiled, tests ran, and defined security scans completed. It confirms the correctness of execution, not system safety.
It doesn’t show whether services can deploy in any order, whether frontend and backend versions are compatible during staggered rollouts, or whether a rollback would leave the system in a consistent state. Those assumptions have to be caught elsewhere, ideally before the PR is merged.
GitLab gives me confidence in execution correctness, not system safety. When pipelines are green, the remaining risk lives in assumptions that aren’t represented in CI: runtime dependencies, schema evolution, and organizational standards.
Pros
- Provides a unified platform for source control and CI/CD
- Creates consistent pipeline definitions across many teams
- Cuts operational overhead compared to managing separate tools
- Scales well for organizations with many repositories and contributors
Cons
- Focuses on pipeline execution rather than deep code reasoning
- Review quality still depends heavily on manual processes
- Advanced quality and governance use cases often require complementary tools
3. Kubernetes
Kubernetes emerges when deployment stops being a single-step process and becomes an ongoing system concern. I’ve worked with it most in environments where services scale independently, traffic patterns fluctuate, and failures need to be isolated rather than catastrophic. In those systems, Kubernetes defines how code actually lives and behaves after it leaves the repository.
From a practical standpoint, Kubernetes is where many delivery assumptions are validated or broken. Resource limits expose inefficient code paths. Rollout strategies reveal whether services tolerate partial failure. Configuration mistakes show up as runtime instability rather than build errors. Senior engineers end up reasoning about deployment behavior as part of application design, not as a separate operational task.
Key Features
- Container orchestration and scheduling across clusters
- Declarative deployment and configuration management
- Built-in mechanisms for scaling, health checks, and rollouts
- Support for service discovery and networking
- Extensible ecosystem through operators and controllers
What Kubernetes Confirms During a Deployment
When I run basic cluster checks, like listing pods and deployments across namespaces, I’m validating runtime state, not delivery safety. In this case, all pods are running, replicas are ready, and deployments report as up to date. From Kubernetes’ perspective, the desired state matches the current state.
That tells me scheduling worked, containers started, and the control plane is healthy. It doesn’t tell me whether the application behavior is correct or whether the deployment aligns with upstream assumptions. As shown in the snapshot below:
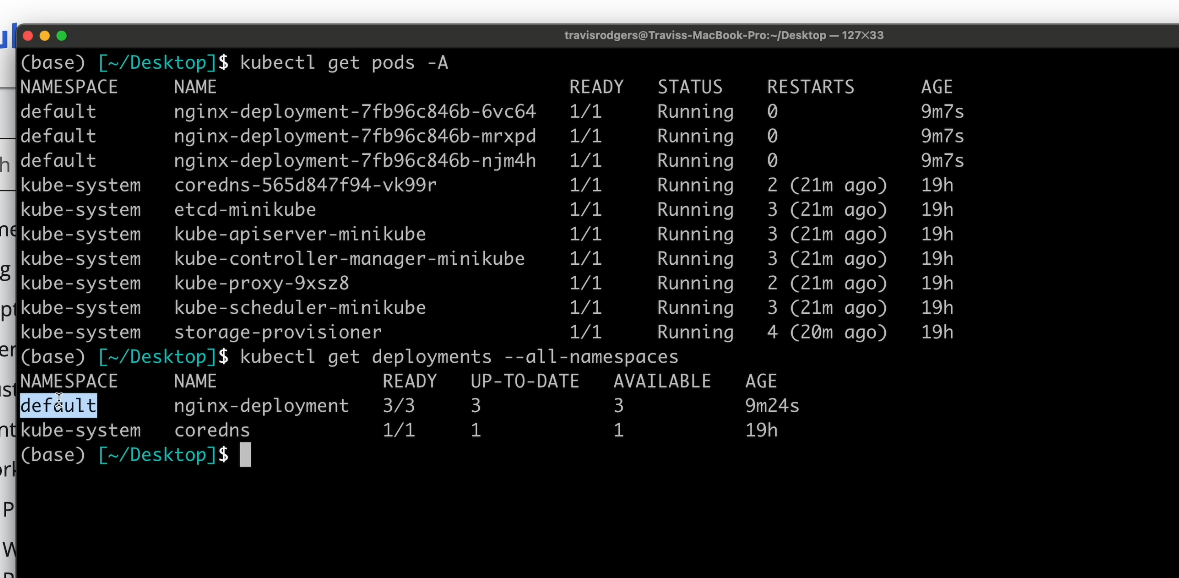
What Kubernetes shows here is operational stability. Pods aren’t crashing or looping, restarts are limited, and replica counts are satisfied. That’s a useful signal for on-call and incident response.
What I don’t see is whether this deployment is compatible with other services, whether schema changes align with consumers, or whether a rollout order matters. If a frontend depends on a backend change, Kubernetes will happily run both versions side by side without warning. It enforces availability, not correctness, across systems.
From a DevOps standpoint, this reinforces where Kubernetes fits. It validates that workloads are running and staying alive under the defined configuration. It doesn’t check whether the change should have been deployed or whether it was safe to deploy independently. Those questions have to be answered earlier, before manifests ever reach the cluster. Kubernetes tells me the system is up. It doesn’t tell me the system is right.
Pros
- Provides a consistent runtime model across environments
- Widely supported across cloud and on-prem infrastructure
- Forms a stable foundation for microservice architectures
Cons
- Adds operational complexity that teams must actively manage
- Misconfiguration can introduce availability or performance risks
- Requires complementary tooling for observability, security, and governance
4. Terraform
Terraform is the most widely adopted infrastructure as code (IaC) tool in enterprise environments. It defines cloud and on-prem resources declaratively, tracks state over time, and fits naturally into version-controlled delivery workflows.
In workloads, it becomes a focal point during scaling events, regional expansion, and compliance-driven changes. It also introduces a failure mode that experienced engineers recognize: infrastructure diffs that look narrow but have a wide blast radius. Reviewing Terraform plans becomes as important as reviewing application code.
Key Features
- Declarative infrastructure definitions across cloud and on-prem environments
- State management for tracking infrastructure changes over time
- Support for multi-cloud and hybrid architectures
- Integration with CI pipelines for plan and apply workflows
- Large ecosystem of providers and modules
What Terraform Changes Signal About Infrastructure Risk
When I review Terraform changes like this, I focus on state management and blast radius, not just whether Terraform apply would succeed. Here, the provider is configured correctly, but the backend configuration for remote state is commented out.
That means the state is being tracked locally, which works for individual experimentation but becomes a delivery risk the moment multiple engineers or pipelines touch the same infrastructure. Local state makes concurrent changes unsafe and turns rollbacks into manual recovery exercises.
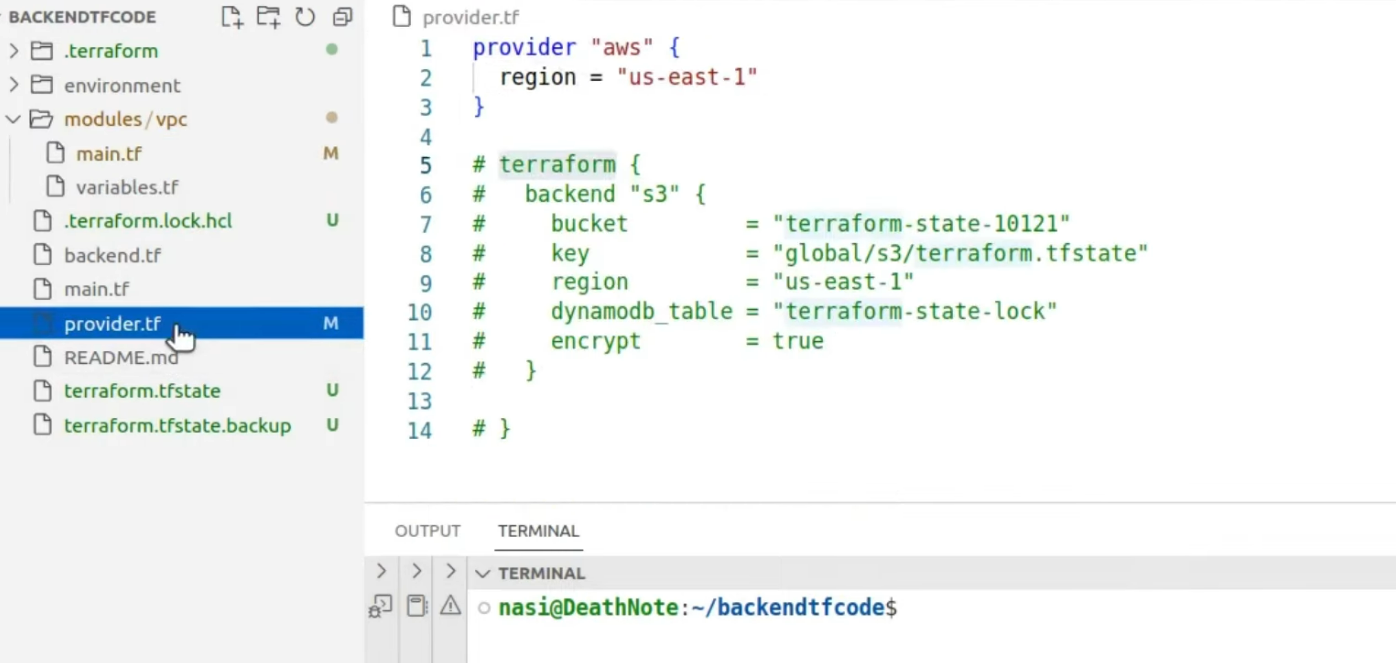
What matters operationally is whether infrastructure changes are coordinated, auditable, and reversible. Without a remote backend and state locking, two applications can race each other, state can drift, and failures become harder to diagnose.
These issues rarely show up immediately. They come up later during scale-out, region expansion, or incident recovery, when state inconsistencies block progress under time pressure.
Pros
- Creates repeatable and auditable infrastructure changes
- Cuts manual configuration drift across environments
- Supports consistent infrastructure patterns across teams
- Fits naturally into version-controlled workflows
Cons
- Infrastructure reviews can become a bottleneck without strong guardrails
- State management requires careful handling in large environments
- Complex configurations can be difficult to reason about without experience
5. Datadog
Datadog provides unified observability metrics, logs, traces, and alerting for systems after deployment. It’s the primary source of truth for understanding how services behave in production and how recent changes affected system health.
It’s most valuable during incident response and performance analysis. Datadog lets engineers correlate deployments with error spikes, latency changes, or resource anomalies, and trace issues across distributed systems.
Key Features
- Metrics, logs, and traces unified in a single observability platform
- Application performance monitoring across services and environments
- Alerting and dashboards for real-time visibility
- Integrations with common cloud, container, and CI/CD tools
- Support for distributed tracing in microservice architectures
What Datadog Tells Me After a Change Is Live
When I analyze Datadog in the context of a recent deployment, I’m looking for confirmation of runtime behavior rather than validation of the delivery decision itself. Logs are being ingested, services are emitting events, and anomaly detection jobs are running to completion. This tells me the system is observable and operational. If latency spikes, errors increase, or unexpected patterns emerge, Datadog will quickly show those signals.
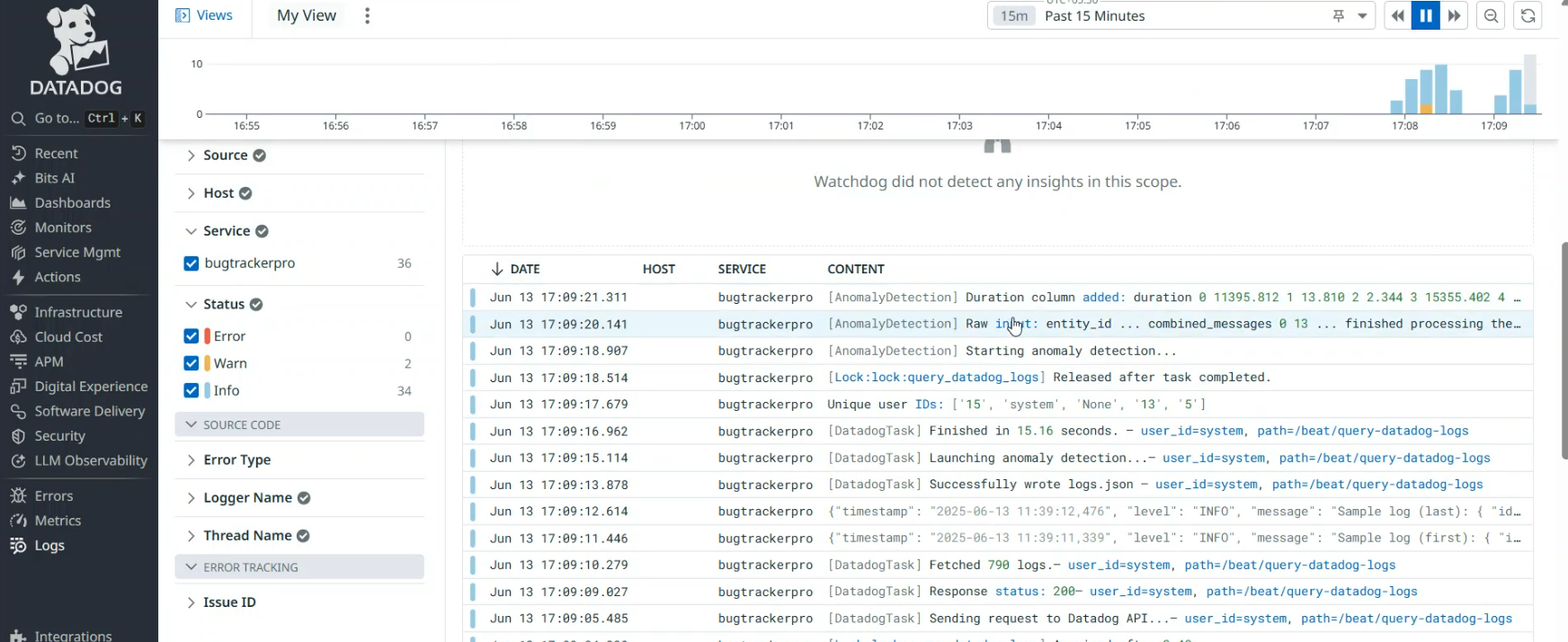
What Datadog doesn’t provide is insight into whether the change was safe to deploy in the first place. It reflects the consequences of decisions already made. Issues caused by rollout order, hidden dependencies, or incorrect assumptions only flag here after users or downstream systems are affected. Datadog is useful for lowering recovery time and understanding the production impact, but it operates after risk has materialized rather than stopping it earlier in the delivery process.
Pros
- Improves visibility into production behavior and system health
- Helps teams diagnose incidents and performance regressions faster
- Scales across large, distributed environments
- Integrates well with cloud and container platforms
Cons
- Focused on observation rather than prevention
- Signal quality depends on instrumentation and alert configuration
- Requires operational maturity to extract full value
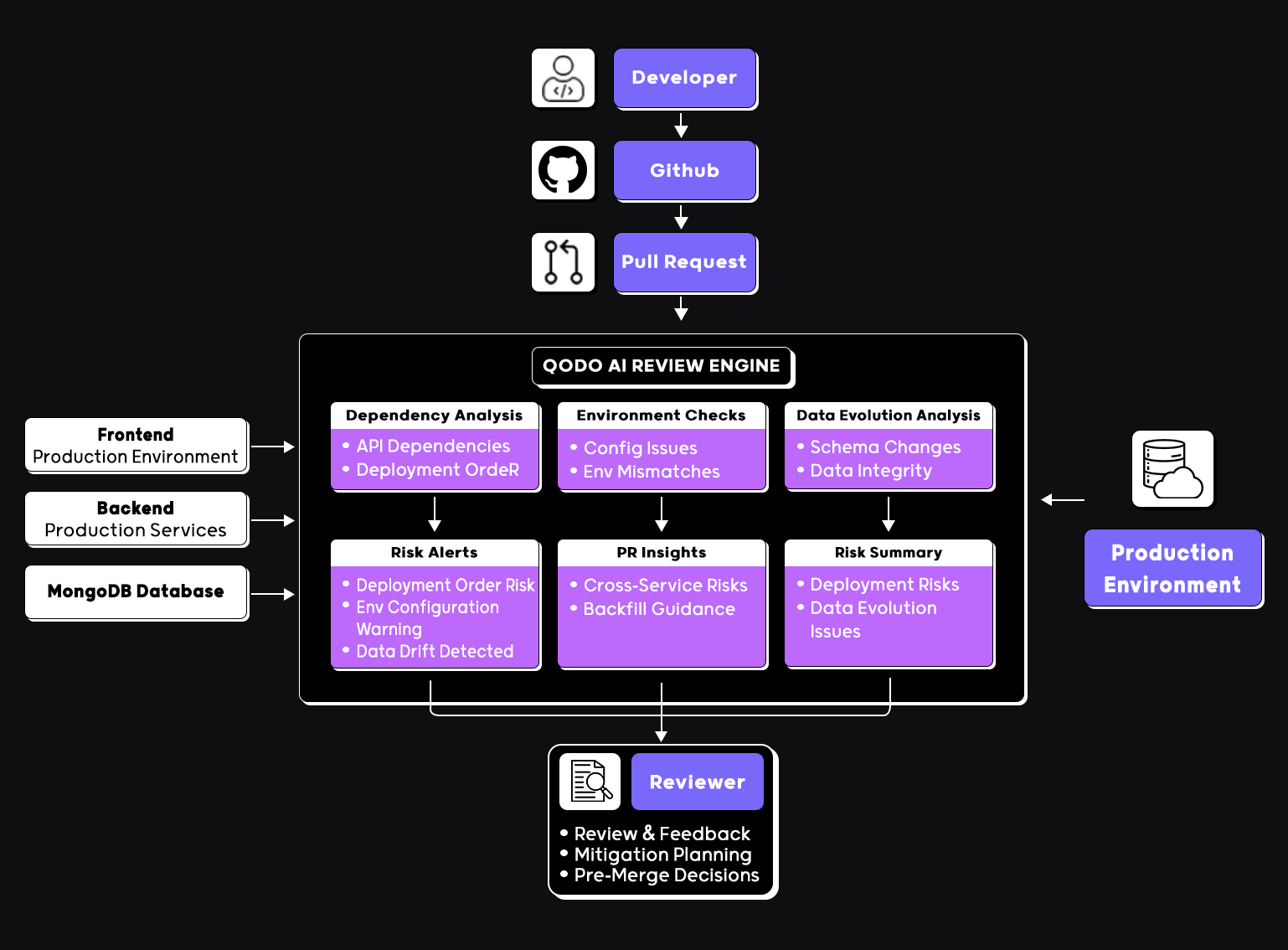
How Does Qodo Evaluate Changes Across APIs, Data, and Infrastructure in the DevOps Workflow?
In tools like GitLab, Kubernetes, Terraform, and Datadog, each tool provides a clear signal at a specific stage: CI/CD pipelines confirm execution, Terraform reflects infrastructure changes, Kubernetes shows runtime state, and Datadog surfaces behavior after deployment.
Taken together, these signals show how code moves from commit to production and how services behave once deployed. But each tool validates outcomes at a specific stage. None evaluates the change itself.
Here’s where GitLab, Terraform, Kubernetes, Datadog, and Qodo each fit in the delivery workflow, what each confirms, and what each leaves unchecked:
| Stage | Tool | What it confirms | What it doesn’t catch |
| Build & test | GitLab | Pipeline passed, tests ran | Cross-service impact of the change |
| Infrastructure | Terraform | Planned state is valid | Dependency ordering risks, state management gaps |
| Runtime | Kubernetes | Workloads are running | Whether deployment order matters |
| Production | Datadog | Services are observable | Whether the change should have been merged |
| Review | Qodo | Change is safe to merge | Runtime behavior after deployment; issues that only surface under real production traffic |
What CI explains vs. what Qodo surfaces
Here’s how a failing CI job explains why a build stopped:
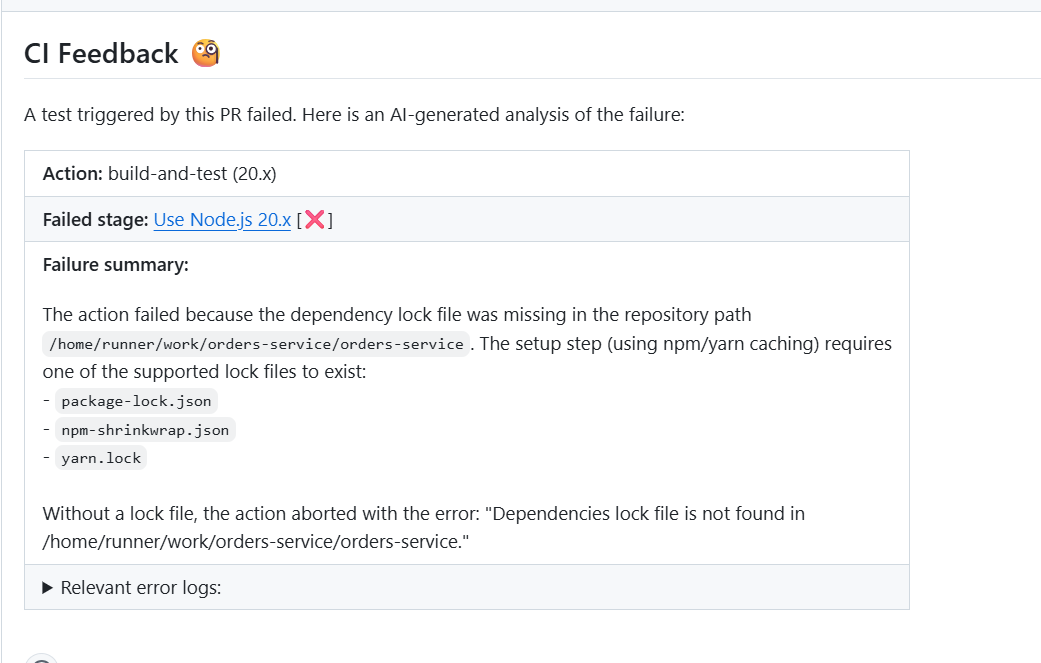
As shown above, the pipeline failed because a dependency lock file (package-lock.json, yarn.lock) was missing; the error is clear, fixing it unblocks the pipeline. This is exactly what CI is meant to do: validate execution steps and stop builds when required inputs are missing.
But a passing or failing pipeline only validates what’s configured. A PR that fails due to a missing lock file or passes every check can still contain issues that never trigger a build error: hardcoded credentials, broken auth logic, or SQL injection via string interpolation.
Now, based on the snapshot below:

Qodo flags those in the review layer, in this case, flagging:
- Hardcoded Secrets: database and Redis configurations include hardcoded production credentials exported directly, risking leakage via logs or downstream imports
- Broken Auth: JWT validation that doesn’t verify signatures, hardcoded admin credentials, and timing-attack-prone API key comparison
- SQL Injection: queries built using string interpolation on user-controlled fields instead of parameterized queries
None of these fail the build. All of them fail in production. Qodo flags that layer of risk inside the PR, where the merge decision is made, not after deployment, when the cost of fixing it is highest.
The Missing Layer in the DevOps Toolchain
Delivery risk in enterprise environments in 2026 rarely comes from slow pipelines. It comes from changes that pass local checks but fail after merge when context is missing, or timelines are already committed.
AI has increased coding velocity. Review capacity and system understanding haven’t kept pace. The result is more post-merge rework, higher recovery effort, and declining release predictability.
GitLab, Kubernetes, Terraform, and Datadog remain essential for execution and observability. They validate what happens after a change ships. Qodo validates whether a change should ship by analyzing application logic, API behavior, infrastructure definitions, and service interactions inside the pull request, before those signals exist.
For teams shipping AI-generated code at scale, that review layer is what allows quality and speed to coexist. Qodo reviews 4M+ PRs a year, across organizations running 10 repositories or 1,000.
FAQs
What do DevOps tools like GitLab, Terraform, Kubernetes, and Datadog actually validate?
They validate execution and runtime behavior at different stages of delivery. GitLab runs builds and tests, Terraform shows planned and applied infrastructure changes, Kubernetes reflects the state of deployed workloads, and Datadog surfaces metrics, logs, and traces after deployment. Each tool confirms what happened, not whether the change itself should have been merged.
Why do issues still appear even when pipelines pass and deployments succeed?
Because most issues are introduced at the change level, not at execution time. An API response change can break existing clients, a schema update can conflict with existing data, or a Terraform dependency change can affect rollout order. These pass CI and only flag when the updated component interacts with other services, data, or infrastructure.
What kinds of changes are typically missed in pull request reviews?
Changes that look correct in isolation but affect other components. This includes API contract changes, schema updates that don’t account for existing records, configuration values that only work in one environment, and infrastructure changes that introduce new dependencies. These are difficult to catch without understanding how the change behaves beyond the repository.
Why is cross-repository impact hard to catch in traditional review workflows?
Because most review tools operate at the repository level. Services, APIs, and shared libraries are often maintained separately, so a change in one repository can affect consumers in another. Reviewers don’t always have visibility into those dependencies, which leads to inconsistent outcomes.
How has AI-assisted development changed code review workflows?
It has increased the volume and scope of changes entering pull requests. Developers can generate API handlers, tests, and refactorings quickly, shifting the bottleneck from writing code to validating it. Reviews now involve larger diffs and less familiarity, leading to greater reliance on automated checks.
How is change-level evaluation different from CI or runtime signals?
CI and runtime tools validate outcomes. They confirm whether a build passed, whether infrastructure was applied, and whether services are running correctly. Change-level evaluation focuses on what was modified, such as API responses, schema definitions, configuration values, or Terraform dependencies, and whether those changes introduce risk before deployment.
What does Qodo evaluate that traditional DevOps tools do not?
Qodo evaluates changes to API behavior, data schema, configuration, and infrastructure definitions while they are being developed and reviewed. It identifies risks such as breaking API contracts, unsafe schema changes, hardcoded configuration, and new service dependencies before those changes reach CI or deployment stages.
How do teams use Qodo alongside existing DevOps tools?
Qodo runs earlier in the workflow, during development and review, while GitLab, Terraform, Kubernetes, and Datadog continue to validate execution, deployment, and runtime behavior. Together, they provide coverage from change creation to production, without replacing existing tools.
What signals suggest that a review process is not catching the right issues?
Common indicators include repeated fixes after deployment, API or schema-related incidents, inconsistent validation across services, and changes that pass CI but require follow-up commits to stabilize behavior. These point to gaps in the analysis of how changes affect dependent components.
When do teams need more than repository-level code review tools?
When services are split across repositories, APIs are consumed by multiple clients, and infrastructure is defined through shared modules. At that point, analyzing changes within a single repository is no longer sufficient; teams need visibility into how those changes affect other services, data, and infrastructure.


