Evaluating RAG for large scale codebases

In a previous post, we introduced our approach to building a RAG-based system—designed to power generative AI coding assistants with the essential context needed to complete tasks and enhance code quality in large scale enterprise environments.
Given the RAG system’s pivotal role in many of Qodo’s products and workflows, ensuring its outputs are both accurate and comprehensive is a top priority. This led us to develop a robust and rigorous solution for evaluating and monitoring RAG performance.
As it turns out, evaluating RAG systems presents several unique challenges. A key challenge is figuring out how to verify the correctness of RAG outputs, given they are derived from large, private data corpora.
In this post, we share some of the methodologies, insights, and solutions we developed to build an effective evaluation framework.
Evaluation strategy
Like most RAG systems that require evaluation, we had to tackle the following questions: what to evaluate, when to evaluate and how to evaluate.
What to evaluate
This decision involves two steps: selecting the system output we want to evaluate, and selecting the facet of the output we want to evaluate.
Which system output to use?
RAG systems often contain many moving parts, such as query preprocessing, embedding, chunk re-ranking and multiple phases of generation, each with its own output.
We chose to focus on the final retrieved documents from the retrieval phase, and the final generated output from the end-to-end flow.
Focusing on the main outputs is useful in two ways: First, it focuses on the outputs that affect the end user experience. Second, it allows us to have consistent measurements of the system’s quality regardless of the internal implementation details. This way, we can evolve the internal implementation of the RAG and still be able to leverage our evaluation in order to gain confidence that the change made sense, without needing to change the evaluation tool itself.
Which facets to evaluate?
A free text answer to user questions about a codebase can be measured in many different ways, from style and tone to succinctness, etc.
To avoid evaluation fatigue, we decided to focus on the following facets:
Answer correctness – This is an end-to-end metric about the quality of the RAG-powered system response, which we believe is a good proxy for usefulness and user satisfaction from the system.
Retrieval accuracy – Here we look at the output of the retrieval sub-system, and check whether it is fetching the right chunks of information needed to generate the correct answer.
The rest of the post will contain examples that focus on answer correctness. However, many of the details we share are also relevant to evaluating the retrieval accuracy.
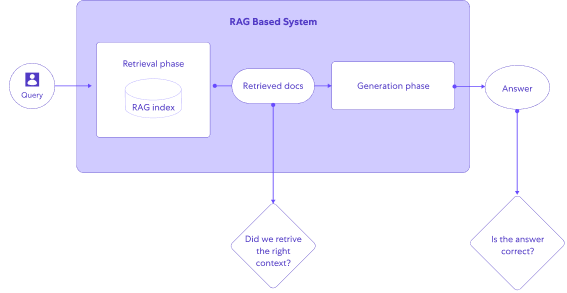
When to evaluate
Similar to the software testing pyramid, LLM evaluation can range from a lightweight process we run frequently during local development to a comprehensive and lengthy process that runs infrequently in complex, full blown environments before major version releases.
We prioritized running our evaluation against a local build of the RAG system, as part of our experimentation flows during RAG system development.
The lightweight approach allows us to use the evaluation locally, as well as inside our CI and before a version release.
How to evaluate answer correctness
Dealing with natural language outputs
Unlike most software systems, which output structured data, LLM outputs often take the form of free text. This means we cannot rely on “hard” verifications, such as string equality, to test if the output is correct.
Luckily, we have a tool at our disposal that is highly capable of understanding natural language. You guessed right: we can use an LLM to assess the quality and accuracy of other LLM outputs.
This approach is called “LLM-as-a-judge”, and has become a common way to deal with evaluating LLM outputs.
Verifying factual answers
In the case of non-RAG applications, an LLM is quite capable of both comprehending the answers, and verifying their factual correctness, since it can access all the knowledge it needs to judge any output, either:
- Through prior knowledge (acquired during the LLM training), or
- Through receiving the entire knowledge needed as context in its prompt.
In RAG-based systems, on the other hand, this is not the case since:
- The answers are grounded on private data that the LLM couldn’t have trained on.
- There is no way to fit all of the knowledge on this domain a priori into the context – that’s actually why we use RAG in the first place!
This suggests that in order to judge correctness, we need to find an oracle that is familiar with the (private) domain knowledge.
One example of such an oracle is a human domain expert.
Ground-truth based evaluation
While domain experts are able to judge whether a RAG system generated correct answers, asking them to do so during each evaluation cycle would be both very expensive and very slow.
A solution which emerged for dealing with this challenge involves two steps:
- Using domain experts to build a dataset with ground truth questions, answers, as well as the ground truth context – i.e. references to the actual documents containing the source needed to answer the questions correctly.
- Using an LLM to compare the system’s output to the ground truth, and rank its level of correctness.
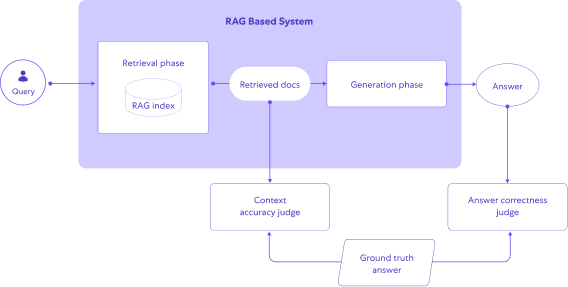
Evaluation dataset design
To make the evaluation meaningful, we needed the data to reflect a realistic distribution, and to be sufficiently diverse and challenging.
In the case of a RAG based evaluation, this means deciding what data should be used for retrieval, and which questions to test on.
Data for retrieval
To evaluate our systems under realistic conditions, the ideal domain data for indexing would:
- Be taken from a large commercial codebase
- Contain multiple repositories of different sizes
- Contain files in multiple programming languages
To this end, we chose to use Qodo’s internal code repositories, which include a representation of multiple coding languages, repo sizes, front-end/backend/libraries and more.
Question composition
To make sure our evaluation tests a broad range of realistic use-cases, we wanted to ensure that the questions we choose are diverse across:
- Programming languages
- Repositories
- Question styles
- User personas and goals
An additional important dimension we needed to represent in the data is the level of reasoning needed to answer the questions correctly.
For example, on the simple end of the spectrum, a question like “describe how foo() works” requires:
- Retrieval based on the function name which is mentioned explicitly in both the code and query
- The question is likely answerable using a single snippet of the function code
- An LLM that has general skills of describing code flows
On the other end of the spectrum, “describe what happens when the user completes a purchase on the site” requires more advanced skills:
- Query term is abstract – may not appear anywhere in the codebase as “purchase”
- Answering the query requires following code paths that may span across services
- Finally, the system will need to summarize this large codebase intelligently.
Building a Q&A dataset with a human in the loop
We started off by having domain experts write the questions and the answers from scratch, by hand. This of course turned out to be very slow and frustrating for the experts.
We observed that there were several distinct issues with this process:
For question generation – we realized that coming up with good ideas for diverse questions is a difficult mental task.
For answer generation – we noticed two issues:
- Writing answers from scratch is tedious and time consuming.
- The answer style of experts did not match the answer style of a RAG based system.
This made the task of deciding whether an answer is correct more challenging.
We needed to find a way to assist our domain experts in both the question generation and the answer generation.
LLM and automation for dataset construction
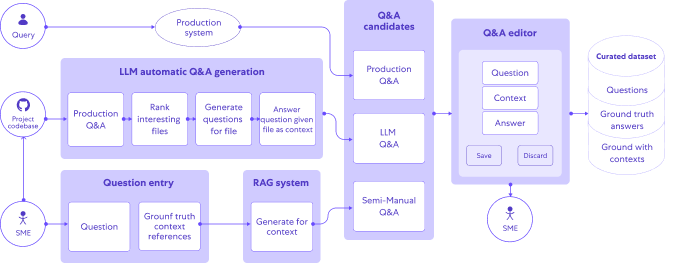
We adopted several methods for helping human experts generate high quality Q&As quickly:
- First, we tapped into (internal) user Q&As taken from our production system traces – this is a good source since it contains questions asked spontaneously by real system users.
- Second, we built an LLM based automatic process for Q&A generation over a repository.
While generating complex questions and answers remains a challenge for LLMs, it turns out that they are quite adept at generating simple questions of the type which uses a relatively small, local context.
To automate the process we built a pipeline that crawls our repositories, prioritizes modules and files as candidates for question generation, and uses few-shot examples to help LLMs generate candidate question-context-answer triplets.
- Lastly, given a question (e.g. manually written by a domain expert), we use our RAG system to generate the first draft answer. However, we skip the context retrieval phase and instead use the ground truth context that the human experts provided. This increases the likelihood that the generated answers will be correct.
Each of these processes generates question-context-answer candidates.
However, these candidates may not be very good – the questions may be off or the answers may not be accurate enough.
To turn these candidates into qualified ground truth data, we use a GUI application for domain expert review.
For each instance, the expert can decide one of the following:
- In case the candidate is usable – edit it a bit if needed and save it to the dataset
- In case the candidate is not usable – discard it
Using LLMs to judge correctness
Once we had a dataset with questions and ground truth answers, we wanted to build an LLM-as-a-judge to score our system’s output correctness against the ground truth.
Understanding the task
Our first step was to simply eyeball our system’s answers side by side with the ground truth.
This allowed us to get a rough impression of our system’s quality, as well as understand the types of challenges our LLM-as-a-judge will need to face when scoring answer correctness.
We also built a manually labeled dataset where subject matter experts score LLM generated answers’ correctness relative to the ground truth answer.
As we shall see later on, this dataset helped us tune the way we perform automated scoring.
RAGAS for answer correctness
We then did a survey of open source tooling which can judge RAG based outputs, and decided to test RAGAS.
RAGAS covers a number of key metrics useful in LLM evaluation, including answer correctness (later renamed to “factual correctness”) and context accuracy via precision and recall.
RAGAS implements correctness tests by converting both the generated answer and the ground truth (reference) into a series of simplified statements.
The score is essentially a grade for the level of overlap between statements from reference vs. the generated answer, combined with some weight for overall similarity between the answers.
When eyeballing the scores RAGAS generated, we noticed two recurring issues:
- For relatively short answers, every small “missed fact” results in significant penalties.
- When one of the answers was more detailed than the other, the correctness score suffered greatly, despite both answers being valid and even useful
The latter issue was common enough, and didn’t align with our intention for the correctness metric, so we needed to find a way to evaluate the “essence” of the answers as well as the details.
At this point, we decided to build our own LLM-as-judge for evaluating answer correctness, rather than attempting to modify RAGAS’s parameters or prompts to fit our use case.
Building our own LLM-as-a-judge for answer correctness
The idea behind LLM-is-a-judge is simple – provide an LLM with the output of your system and the ground truth answer, and ask it to score the output based on some criteria.
The challenge is to get the judge to score according to domain-specific and problem-specific standards.
In this case, tuning the judge required two steps:First, we tuned our prompts to address the issues we had noticed with RAGAS’s scores, i.e. the over sensitivity to insignificant factual differences.
Second, we included a set of carefully curated examples for how to score, written by domain experts. Each example included the human expert’s score, as well as a detailed critique of the output which gave the LLM an idea about what it should pay attention to when scoring.
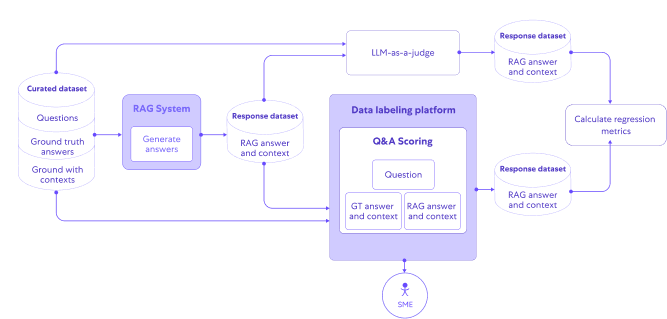
Evaluating the judges
At this point, we had both the RAGAS scores and our custom LLM-as-a-judge scores.
That was great, but how could we know we should trust them to reflect the answer’s correctness?
In other words, we needed to evaluate the evaluators!
First, we ran a sanity test – we used our system to generate answers based on ground truth context, and scored them using the judges.
This test confirmed that both judges behaved as expected: the answers, which were based on the actual ground truth context, scored high – both in absolute terms and in relation to the scores of running the system including the retrieval phase on the same questions.
Next, we performed an evaluation of the correctness score by comparing it to the correctness score generated by human domain experts.
Our main focus was investigating the correlation between our various LLM-as-a-judge tools to the human-labeled examples, looking at trends rather than the absolute score values.
This method helped us deal with another risk – human experts’ can have a subjective perception of absolute score numbers. So instead of looking at the exact score they assigned, we focused on the relative ranking of examples.
Both RAGAS and our own judge correlated reasonably well to the human scores, with our own judge being better correlated, especially in the higher score bands.
The results convinced us that our LLM-as-a-Judge offers a sufficiently reliable mechanism for assessing our system’s quality – both for comparing the quality of system versions to each other in order to make decisions about release candidates, and for finding examples which can indicate systematic quality issues we need to address.
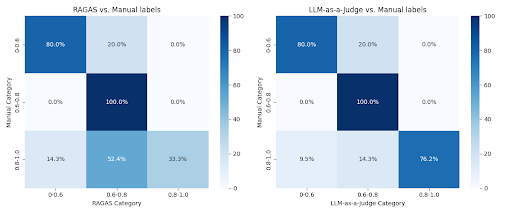
Given that our judge was simpler and performed better we considered dropping RAGAS but ultimately, we decided to keep both our judge and the RAGAS scores in our evaluation since doing so provides an additional signal – e.g. increased trust in the scores when both judges agree, and a hint to the root causes of issues when they disagree considerably.
Integrating the evaluation into our workflow
Now that we have a curated dataset of diverse questions and answers, and reliable scores for answer correctness, it was time to integrate these into our workflow and tooling chain.
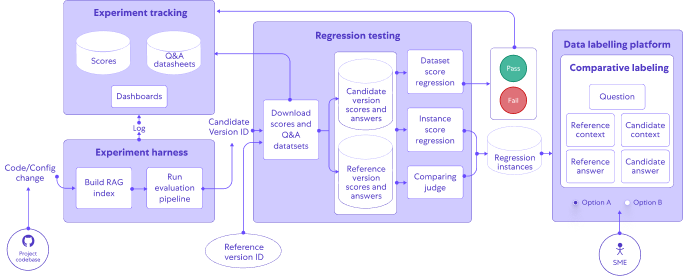
We wrapped up the workflow in a lightweight CLI tool which we can run locally as well as in the CI, which performs prediction, evaluation, and stores the results in an experiment tracking system.
Regression testing
We also built a regression test, which compares a candidate version with a “reference” version.
The regression detection is based on the average correctness scores for a dataset.
The regression tool also supports finding representative examples in which the answers’ quality has regressed – either based on their scores or by using a dedicated judge which compares two answers.
A sample of the regression examples is then sent to the labeling system for manual inspection and labeling.
Using these tools, we’ve dramatically decreased the effort involved in verifying if code changes led to unforeseen quality issue, from hours of manual probing to minutes for automated regression tests.
Conclusion
RAG systems for large scale codebases are a core capability used across many of Qodo’s products and, as such, require a robust evaluation and quality mechanism.
By focusing on the answer correctness as a key success metric, and designing our datasets and metrics carefully, we’ve managed to build a reliable evaluation process which has helped us increase confidence in our system’s quality.
As we continue to evolve our RAG system, our evaluation methods, data and tools will continue to evolve with it – from the research phase all the way to production.


