From Prompt Engineering to Flow Engineering: 6 More AI Breakthroughs to Expect in 2024

Last year in March, we wrote a blog post predicting six AI breakthroughs to come over the next year. It’s been a busy year since then. With so many notable developments having happened, we wanted to take a step back to reflect on our predictions and think ahead to what exciting things the coming year will bring.
Where were we in 2023?
Let’s review some of the major limitations of LLMs near the beginning of 2023.
Content hallucinations: Especially as LLMs were still gaining speed, models would often over confidently give incorrect answers, or give answers that say a lot without actually giving the answer.
Small query context: For complicated tasks, LLMs may need more information than they have been trained on, such as contextual background information that gives more details on how to solve a problem. Unfortunately, LLMs often had small input sizes that restricted them from taking in these additional pieces of information.
Prompt engineering magic: LLMs were extremely sensitive to the input prompts that users gave, so much so that changing just a few words or rephrasing the prompt could lead to drastically different results, which hampered the generalizability of LLMs.
In last year’s essay, we highlighted the key difference between knowledge (understanding of a particular subject or field) and intelligence (the ability to apply knowledge to reason, learn and solve new problems). GPT and other popular models were highly knowledgeable systems but they weren’t quite at the level of intelligence yet. Last year, we made six predictions that we anticipated would bring us closer to unquestionable artificial intelligence. Let’s see how our predictions turned out and look forward to what new developments we anticipate will come in the remainder of 2024.
What happened in 2023-and what’s coming in 2024
If you’ve only got a few minutes, here’s a tl;dr of AI advancements over the past few years (and what we’re expecting this year and beyond).
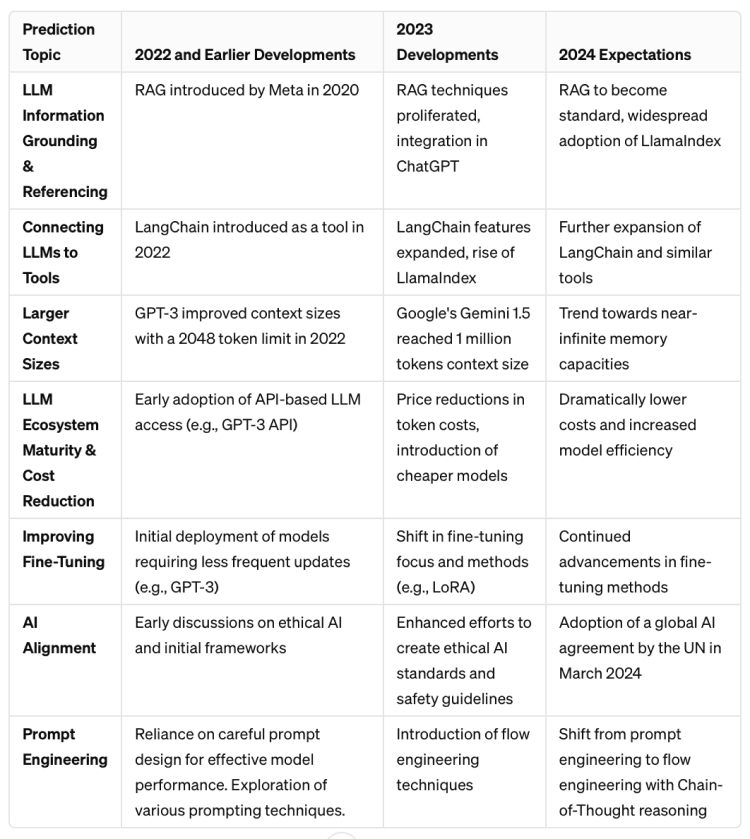
1) LLM information grounding and referencing
We predicted new practices and techniques would reduce the “Content Hallucination” problem through grounding and referencing information outside of the initial data set a model was trained on. In 2023, we saw the rise of RAG (Retrieval Augmented Generation) systems as an informational grounding technique for LLMs.
RAG is not entirely new, as it was first introduced in a paper published by Meta research in 2020. However, we saw a proliferation of changes that boosted the popularity and use of RAG techniques. OpenAI incorporated Microsoft’s Bing search engine into ChatGPT, looking to bolster the chatbot’s power by giving it access to up-to-date information from the internet.
What to expect in 2024 RAG will continue to flourish and become the gold standard default and a must-have for all LLM systems in 2024 and 2025. And new tools, such as LlamaIndex, that are focused on making RAG easier to integrate into LLM workflows will also become more popular and widely adopted.
2) Efficiently connecting LLMs to tools
In 2023, we talked about LangChain as an early example of a developer tool enabling the trend of LLM grounding with external data sources. Fast forward a year and LangChain has exploded in popularity and deeply matured with new features like LangGraph, allowing for more complicated, stateful LLM application flows.
Briefly mentioned above, tools such as LlamaIndex, a library specifically built for streamlining RAG workflows, also gained huge popularity due to the rise in interest of RAG. LlamaIndex is also a great example of the saying “A rising tide raises all boats” in action for the AI industry, as it is a library directly built on top of LangChain and its popularity.
Finally, we wanted to highlight the rise of open-source libraries that help make developing with LLMs easier than ever before. Libraries such as vLLM allow any developer to easily start experimenting with a huge variety of LLMs using their own machines, all while being easy to set up, maintain and customize.
What to expect in 2024: LangChain and other developer tools focused on LLM pipelines will continue to expand, and the advancement of infrastructure-like tools (such as LangChain) will help power the development of more specialized tools (like LlamaIndex). Code libraries facilitating easy access to open-source LLMs will also be a growth area for the next year.
3) Larger context sizes
When GPT-4 was first officially announced by OpenAI in a blog post, the context size of the models were still limited to an absolute max of 32,000 tokens. Now we have models like Google’s Gemini 1.5 that have context sizes of a million tokens. Within the next year, context sizes should no longer be a problem as models reach near infinite memory capacities.
Larger context sizes bring their own set of issues however. With so many input tokens, is the LLM properly understanding and utilizing all these inputs to create its output? People have rightfully been curious about this and developed “Needle in the Haystack” tests to see if LLMs can correctly find key pieces of information hidden in a large input prompt. So far results have been mixed, so we expect to see large improvements in this area as larger context sizes for LLMs become the norm.
What to expect in 2024: LLM systems will trend towards near-infinite memory capacities, and they’ll become better at using all input context for tasks.
[blog-subscribe]
4) LLM ecosystem maturity leading to cost reductions
As any industry matures, processes become more efficient-which leads to lower costs across the board. LLMs in the AI space are no exception. Back in 2023 March, OpenAI’s GPT3.5 turbo was priced at $.002 per thousand tokens or $2 per million tokens. The same model today is now 4x cheaper, priced at $0.50 per million tokens. This is good, but it’s still way off from what’s ideal-and far off from what will likely happen over the next year or so.
There has also been an industry trend towards offering scaled-down and cheaper versions of existing models. Aside from OpenAI’s GPT-Turbo, Anthropic, the creators of the popular Claude family of models, have released their own cheaper offering called Haiku. Priced at only $0.25 per million tokens, it aims for speed and price efficiency compared to its larger parameter-sized cousins.
In general, closed-source models (such as GPT from OpenAI and Claude from Anthropic) only accessible through APIs are known to be more expensive. This is verified by this handy chart that gives a great overview of costs of many model options today. Even more so than their gated counterparts, open-source models have made huge strides in cost reduction, with LLM computing platforms like Anyscale now offering open-source offerings as low as $0.15 per million tokens.
We believe even further cost reductions will likely come from more startups working on efficient LLM inference. In November, Grok was unveiled by xAI with a blog post highlighting a focus on “training LLMs with exceptional efficiency”. Continuous speed and efficiency improvements of models will trickle down and help reduce the end cost incurred by developers and end-users alike.
What to expect in 2024: Increased model efficiency will help reduce LLM costs across the board. And, startups (like Foundry) should help to reduce cost by making compute more accessible, reliable, and cost-effective.
5) Improving fine-tuning
Last year we highlighted fine-tuning as a process to improve a model’s knowledge and accuracy in certain tasks. RAG has largely now become the main tool for LLM systems to improve a model’s factual accuracy, mainly because it’s easier to update with new information without the expensive overhead of retraining a model that comes with fine-tuning.
However, fine-tuning as a technique has now evolved to fill a new purpose. Instead of a focus on surface level factual accuracy across a huge variety of domains (something better suited for RAG), model fine-tuning is perfect for increasing the depth and capabilities of models in specialized domains, especially when companies are have the necessary large amounts of pre-labeled data to retrain a model. This is exactly the kind of fine-tuning that makes qodo (formerly Codium) so good at generating useful and accurate tests for developers.
Despite a course correction in the purpose of fine-tuning, there have still been great leaps over the past year in fine-tuning research. For example, LoRA is an improved fine-tuning method which aims for efficiency by fine-tuning smaller “adapters” that are then loaded into the original pretrained model, instead of fully retraining the original model.
This handy article that talks about how RAG and model fine-tuning can now be used in conjunction to improve different parts of an LLM system. We expect to continue seeing fine-tuning advancements in speed and accuracy.
What to expect in 2024: Fine-tuning models will continue to improve and evolve in its effect, speed and purpose.
6) AI Alignment
As with any new frontier in technology we’ve seen in the past, the first few years are always a wild west in terms of regulation. As LLMs are becoming more commonplace and known as a concept, there are also new pushes to make sure that any future growth is regulated in a safe and ethical direction.
In March of 2024, governments around the world adopted the first global agreement on AI. The United Nations General Assembly adopted this resolution to foster the protection of personal privacy and data rights in the context of developments in AI.
We expect “AI alignment” actions will continue to be initiated, both by governmental bodies and leaders in the AI space.
What to expect in 2024: Actions by top companies and figures and governments to align AI for societal good. Whether or not these actions will actually accomplish their stated intentions, though, is a separate matter (and the subject of much debate).
From prompt engineering to flow engineering: 2024’s mindset switch
Last year we highlighted a couple of ongoing research areas into improving LLM reasoning, one of them being Chain-of-Thought reasoning. Chain-of-Thought is a great example of a broader shift in the AI space from a single “Prompt Engineering” approach, which tried to improve model reasoning by changing single parts of a system (rewriting single input prompts) to a multi-step “Flow Engineering” approach, where AI reasoning is improved through an interactive and step-wise procedure instead.
Take our qodo Flow research as an example. We found that a multi-stage approach to code generation involving numerous steps of generating solutions, generating test cases, and then revising code based on test results, helped GPT-4 generate more accurate code solutions than single, well-constructed prompts. We believe this is a big deal (and other people think so, too).
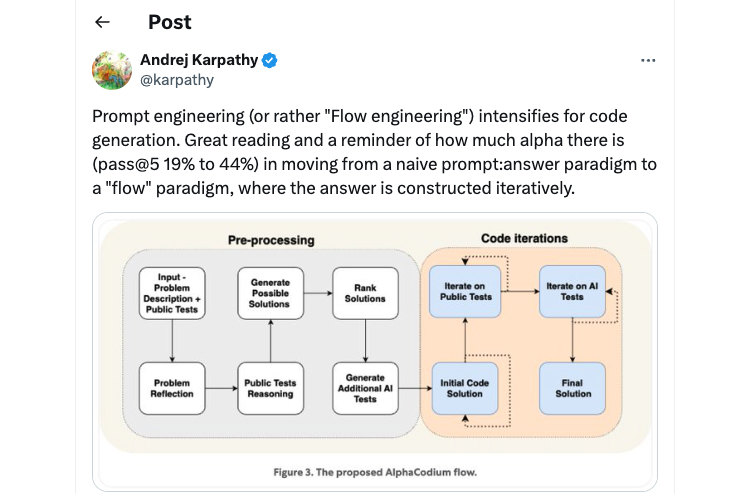
The beauty of this idea is that it is a framework for development: This same multi-stage code generation approach can be used with different models-not just GPT-4. More generally, this idea of moving away from spending lots of time on “prompt engineering” and focusing on constructing an iterative step-by-step flow approach is applicable to other AI-related tasks outside of code generation.
This flow engineering paradigm shift is a culmination of all the different points above we highlighted: A shift to LLM pipelines that allow data processing steps, external data pulls (RAG), and intermediate model calls to all work together to further AI reasoning, all made easier due to lower cost infrastructure and easier-to-use developer tools. We believe this is where the next great leap in AI reasoning will come in the next year.


