How 2023 AI Predictions Aged: Looking Back from the Start of 2026
Part 1 of 2 — Reflection & Reality Check
Neural networks alone are not products. Systems are. Well, at least not for software development, and specifically for high-quality real-world SW Dev. I made that case in an early 2023 blog post, arguing that the real AI breakthroughs would not be a sudden leap in LLM intelligence, but a set of enablers that make AI models and agents reliably useful in real systems. Once those matured, the “ChatGPT moment” would look more like a starting point than a peak.
Starting 2026, three things are clear:
- The model hype did not collapse.
- Models did not plateau (at least not until now)
- The biggest gains did not come from scale alone
This series is about where those gains actually came from, and what that shift means going forward.
- Part 1 (this post): What held up, what evolved, and what actually mattered since the hype started
- Part 2: New predictions for 2026–2027
The 2023 Thesis (Brief Recap)
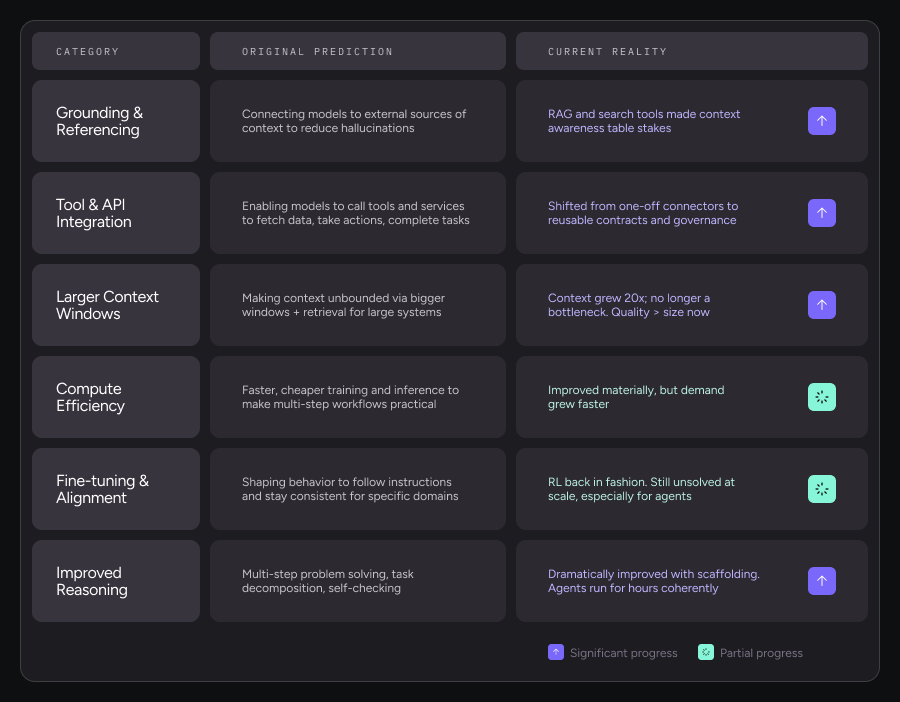
The original argument in my 2023 post was specific: for AI to move beyond chatbots to operational intelligence, real acceleration would come once six categories of breakthroughs matured:
- Grounding and referencing: Reducing hallucinations by connecting the model to external sources of context
- Tool and API integration: Enabling models to call external tools and services to fetch data, take actions, and complete tasks reliably.
- Larger and more usable context: Making context effectively unbounded by combining bigger windows with retrieval, so the model can reason over large systems
- Compute efficiency and cost reduction: Making training and inference faster and cheaper so multi-step workflows and higher usage become practical in real products.
- Fine-tuning and alignment: Shaping model behavior so it follows instructions, stays within policies, and is consistent for a specific domain or workflow
- Improved reasoning: Strengthening multi-step problem solving and planning so the model can decompose tasks, make decisions across steps, and self-check along the way
The implication was that the next wave of value would not come from better prompts, but from turning models into reliable components inside real workflows: agents able to pull the right context, call tools, reason through multi-step tasks, and produce outputs you can verify and ship.
Looking back, these predictions turned out to be more correct than I initially appreciated.
2025 Reality Check: from data to wisdom
While LLMs keep getting better, the most practical leverage in 2024 to 2025 came from engineering layers that made them more reliable and scalable in real-world systems. The pattern looks like a move from information generation toward system-level intelligence: Data → Information → Knowledge → Intelligence → Wisdom.
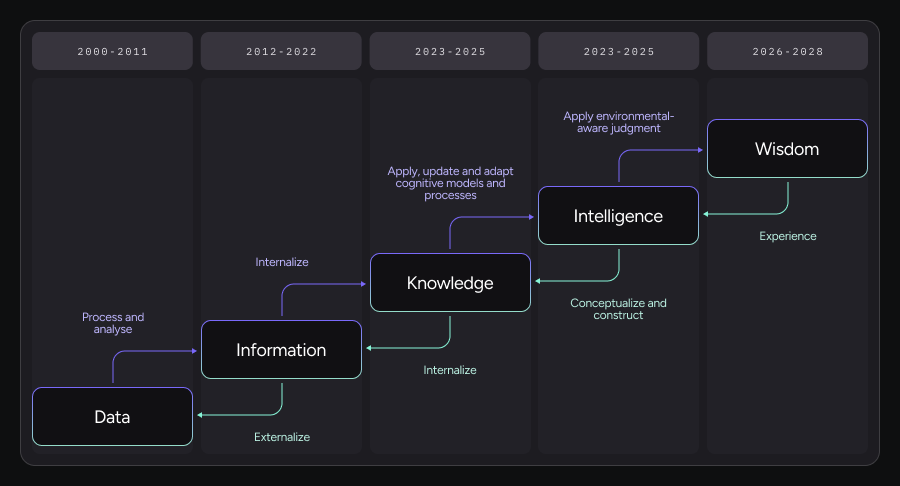
Knowledge formation
Early data science technology and techniques were astonishing at turning data into information: compressing vast corpora into fluent, probabilistic outputs. With retrieval and search, they became better at surfacing information on demand.
The next step, knowledge, required internalization. This is where techniques like Retrieval augmented generation (RAG), embeddings, structured memories, and domain-specific representations mattered. Knowledge wasn’t just retrieved; it was shaped, scoped, and contextualized. But more importantly, as LLM grew (actually becoming “Large”), and with the maturity of unsupervised learning, they captured a lot of knowledge internally in their weights.
Intelligence in action
The real inflection point came when systems began to support intelligence: the ability to apply, update, and adapt with respect to the given task or in response to changing environments. This did not live only inside a single model, although it was critical to train the models to behave in a befitting manner. Intelligence emerged from systems that combined models with tools, feedback loops, state, and execution constraints.
Early signs of wisdom
Finally, what we are only beginning to see hints of, especially heading into 2026, is wisdom: applying environmental-aware judgment, memory and continuous learning. This is not about raw reasoning depth. It’s about knowing when to act, when not to act, what context matters, and which signals should dominate, according to past experience. Wisdom is inherently system-level, slow-moving, and experience-driven.
Why the system became the moat
This progression explains why scaling models alone hit diminishing returns. Moving up the stack (from information to intelligence and toward wisdom) requires integration layers, protocols, memory, verification, and governance. Intelligence didn’t get bigger. It got externalized, structured, and orchestrated.
I do see a strong connection between intelligence and creativity. So I think the more intelligent the system is, the better it manages this tradeoff of structure thinking and learning from experience with creativity.
This is the deeper reason progress accelerates once intelligence propagates out of the model and into the system.
Nowhere was this more obvious than in what I loosely called “tool integration” in 2023 — and what we now understand as the integration layer.
The Integration Layer: Where Intelligence Becomes Operational
In 2023, “integration” mostly meant: Can the model call an API or use a calculator?
By the end of 2025, that framing feels naïve. What actually emerged is something much bigger.
The integration layer is where intelligence becomes operational.
This layer is responsible for:
- Supplying models with the right context
- Connecting them to trusted actions
- Enforcing constraints and permissions
- Preserving state, memory, and intent (although more meaningful progress is required here)
- Translating probabilistic outputs into deterministic systems
This is where LLMs stop being demos and start becoming reliable components of software systems.
From Ad‑Hoc Glue to MCP
Once that boundary was crossed, and as teams tried to scale agentic systems, they all hit the same wall:
- Every integration was bespoke
- Every tool had a different contract
- Every context injection was fragile
Prompt engineering didn’t scale. “Just give the model more context” didn’t scale.
What was missing was a standardized contract between:
- Models
- Tools
- Context providers
- Memory systems
- Execution environments
This is the gap that MCP (Model Context Protocol) emerged to fill.
MCP as the Missing Abstraction
MCP reframes the problem correctly.
Instead of asking: What can the model do?
It asks: What context is the model allowed to see, trust, and act upon, right now?
Before MCP, connecting a model to a codebase, a database, and a deployment pipeline meant writing three separate integrations with three different patterns. Each one had its own way of handling permissions, its own context format, its own failure modes. MCP provides a single contract.
At its core, MCP formalizes three things that were previously implicit and brittle:
- Context boundaries — what data is available, from where, and with what guarantees
- Capability surfaces — what tools exist, what actions are allowed, and under which constraints
- Interaction contracts — how models, tools, and systems communicate predictably
This is not just a developer-experience improvement.
It is a control plane for intelligence.
Note: The MCP ecosystem is still in its early stages of development and maturing. E.g., while an official registry emerged during 2025, it is still missing essential components fitting for statistical creatures, like benchmarks.
Why This Mattered More Than Better Models
By late 2025, it became clear that models became interchangeable. The systems did not. Two teams using the same frontier model could achieve very different outcomes. The difference was rarely the prompt. It was the integration architecture.
Teams that invested in:
- Structured context pipelines
- Typed tool interfaces
- Explicit capability routing
- Verifiable execution layers
Consistently outperformed teams that simply upgraded models faster. (Good examples: Lovable and Manus that understood and executed on this really well.)
Closing
Looking back, the original claim still holds: The AI hype peak was ahead of us — not behind us.
But not because of better models alone. Because we learned that intelligence is a system property, not a model property alone.
In Part 2, I’ll look forward and outline predictions for 2026–2027 — including where agent communication and abstractions go next, what breaks as agents become default, and where real differentiation will (and won’t) exist.


