How AI helps review Kubernetes configs before they break production


Kubernetes configurations now constitute the new frontier where good intentions meet catastrophic failures. You go ahead, write what looks like perfectly reasonable YAML, push it through your CI pipeline, and then watch your evening dissolve into a frantic debugging session because the orchestration blueprint you just messed with has decided to break your entire prod workflow. The thing is, disasters such as this could have been avoided if someone had caught the subtle misconfiguration bits hiding in your manifests before they ever touched a live environment.
But it’s worth noting that the challenge with Kubernetes configurations isn’t just their complexity but their interconnected nature. Your deployment connects to services, ingresses, network policies, secrets, and RBAC rules in ways that aren’t immediately obvious to the human eye. Traditional configuration reviews struggle with this web of dependencies, often missing critical issues that only surface under production load or during security incidents.
The peculiar nature of Kubernetes configuration errors
Traditional application bugs announce themselves with stack traces and error messages that at least point you in the right direction. Kubernetes misconfigurations are far sneakier. They slip past your automated tests, survive code reviews from experienced engineers, and wait patiently for the perfect moment to surface when you’re dealing with real traffic patterns or specific environmental conditions.
In time, you’ll notice these issues span multiple categories. On one hand, resource allocation problems manifest as memory leaks that crash neighboring pods or CPU throttling that degrades performance under load; on the other, security vulnerabilities hide in overprivileged containers, exposed secrets, or overly permissive network policies. Similarly, operational failures emerge from missing health checks, unpinned image tags, or misconfigured scaling policies.
Consider the following deployment manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app
spec:
replicas: 3
selector:
matchLabels:
app: web-app
template:
spec:
containers:
- name: app
image: myapp:latest
# Missing resource limits, health checks, security context
Everything here follows basic Kubernetes syntax rules. Your linter won’t complain, your validation tools will give it a green light, and it’ll deploy successfully in development. But the issue runs deep. This configuration is riddled with red flags that will manifest under production conditions.
The unpinned image tag means your application version becomes a moving target; missing resource limits can lead to one pod consuming all available memory and starving other workloads; the absence of health checks means Kubernetes has no way to detect when your application is struggling, so it keeps routing traffic to failing instances. There are a dozen ways for things to go wrong.
Where manual reviews fall short
Human reviewers excel at spotting logical flaws and architectural concerns, but the interconnected nature of Kubernetes resources is a bit beyond our scope to deal with ever so frequently. A security group rule, for instance, that seems reasonable in isolation might create an attack vector when combined with a specific service configuration and network policy. Memory limits that work fine for a single replica can create a domino effect of failures when the deployment scales to handle peak traffic.
Manual reviews also tend to suffer greatly from context switching costs. Say, an engineer reviewing a pull request might not have the full picture of how these configurations relate to existing cluster resources, security policies, or operational patterns that have evolved dozens of times since inception. They’re essentially making decisions with incomplete information about a system where everything affects everything else.
The problem gets even worse when teams are moving fast. During crunch periods, configuration reviews getting reduced to quick syntax checks rather than thorough analysis of security implications, resource allocation patterns, and failure scenarios is all very real and possible. And before you know it, these rushed reviews become the entry point for the subtle issues that later cause major production incidents.
And if you choose to go along with traditional policy engines such as Polaris and Kube-score, all you get is rule-based validation against certain pre-defined best practices. These tools apply generic rules without understanding your specific environment, and this leads to false positives that teams learn to ignore and false negatives that allow dangerous configurations to slip through.
For example, when teams use Kustomize’s overlay pattern where base deployments define minimal resource specifications:
# base/deployment.yaml
containers:
- name: web-service
resources:
limits:
memory: "256Mi"
requests:
memory: "128Mi"
You’ll notice that the traditional tools will flag this as “incomplete resource specification” because they can’t understand that overlays in overlays/production/ will enhance these values.
Similarly, these tools will completely miss label collision attacks where individually valid configurations create security vulnerabilities when combined.
AI’s approach to configuration analysis
According to a 2024 study on AI-powered Kubernetes security, machine learning-based anomaly detection systems achieved 92% accuracy in identifying security threats and anomalies across various Kubernetes clusters, with significantly reduced false positive rates compared to traditional rule-based approaches. To that end, using AI-powered tools for Kubernetes configuration validation works well because there’s a certain contextual understanding offered here that traditional tools lack.
Pattern recognition becomes particularly powerful when applied to infrastructure configurations. AI can identify recurring problematic patterns across repositories, teams, and deployment environments. It can catch the kinds of inherent systematic issues that human reviewers might miss because they’re looking at a file at a time rather than analyzing trends across the entire infrastructure codebase.
Going beyond just spotting patterns, Qodo’s contextual analysis will help you get your head around naming conventions and even previous architectural decisions. Rather than applying generic best practices that might not fit your environment, the platform learns from your successful configurations and identifies deviations that could cause problems in your specific setup.
For example, when reviewing a new deployment manifest, Qodo’s Auto Best Practices feature analyzes your repository’s accepted code patterns and learns from successful configurations:
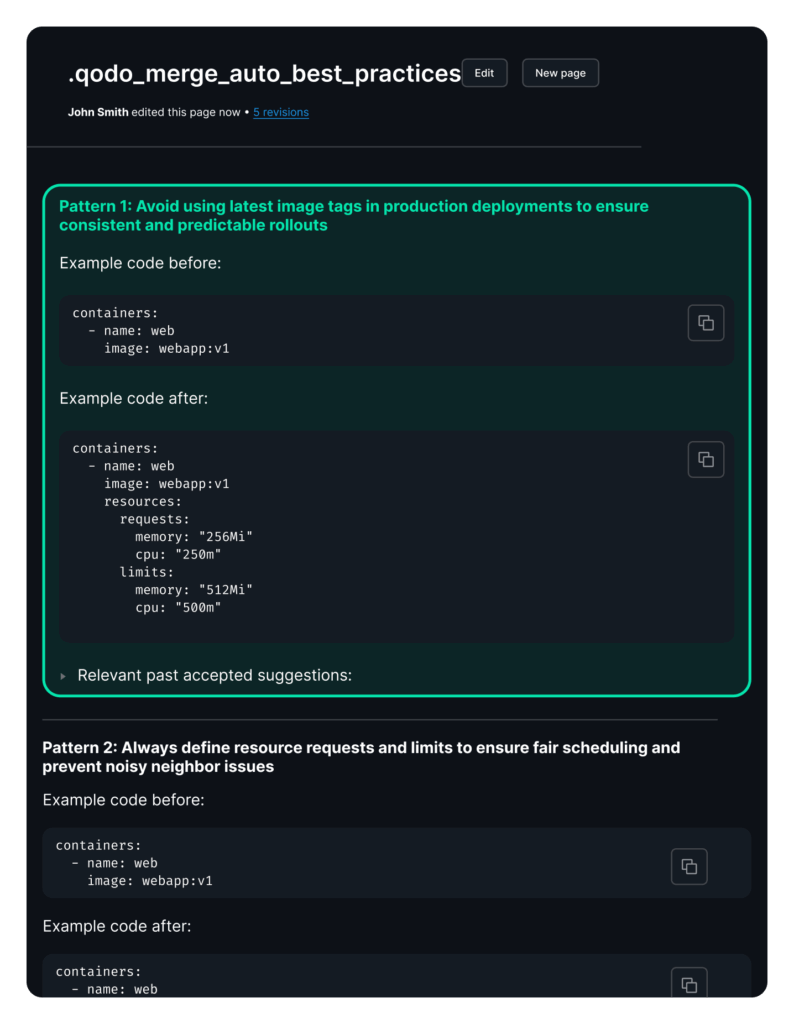
All this helps enable multi-dimensional validation that evaluates configurations across security, performance, and operational reliability simultaneously.
So, when Qodo’s AI analyzes that earlier deployment example, it doesn’t just flag individual issues but understands their combined impact. Everything from how the credential exposure creates a security risk to how that’s amplified by the missing resource limits, which could then lead to lateral movement during a resource exhaustion attack, gets called out.
What makes this approach truly powerful is adaptive learning from production environments. Results improve over time by analyzing successful deployments and configuration changes that lead to operational issues.
Making the smart choice
The shift toward AI-powered configuration review represents more than just adding another tool to your DevOps pipeline. It’s about fundamentally changing how teams approach infrastructure reliability and security. Instead of reactive debugging sessions after problems occur, teams can proactively prevent issues through intelligent analysis that happens automatically as part of their development workflow.
Qodo brings this intelligent approach to configuration review with a deep understanding of your specific infrastructure patterns and requirements. The platform’s ability to learn from your successful deployments while identifying potential risks makes it an invaluable ally in maintaining robust Kubernetes environments.
Furthermore, Qodo also analyzes resource patterns across similar workloads and recommends optimal settings based on actual usage data rather than guesswork. It can catch resource allocation mismatches between environments and simulate resource pressure scenarios to identify potential bottlenecks before they impact real users.
Think about it. When configuration errors can cost thousands of dollars in downtime and developer hours, investing in AI-powered prevention becomes one of the smartest technical decisions you can make. See it for yourself.


