How I Built a Policy Enforcement Layer for Coding Agents with NVIDIA NIM

I built PolicyNIM to test a simple idea. If an agent can fetch the right standards before it writes code, then reviewing pull requests could get smaller, cleaner, and more useful. That sounds obvious, but proving that meant designing an entire AI system for agentic coding agents.
The ‘NIM’ in PolicyNIM is not accidental. It runs on NVIDIA’s NIM-hosted embedding and reranking models via the API Catalog. And the code quality was battle-tested with Qodo.

At what point should we steer AI coding agents?
In spite of the known and unknown limitations of LLMs, power users of AI coding tools (myself included) have assumed the responsibility of tuning their agent experience in a direction most beneficial for software development.
Problems have persisted, despite this, so we pile on all of the latest, most popular tools we can.
AGENTS.md, CLAUDE.md, and a ton of agent skills, context engineering (ad hoc with engineering leaders trying to figure out how to manage this at scale), manual code reviews and AI code reviews (ad hoc).
The #1 resounding issue we’re attacking is code quality.
This is finally being discussed in a more meaningful way beyond shaming vibe coders for building software blindly.
Agents, designed to generate code as quickly as possible, struggle to infer coding rules and other derivatives of context just as easily as they make code blocks flood laptop screens.
By the time quality discrepancies between original task and output show up in a pull request, I argue that it’s already too late.
If code review is the first place your workflow checks team standards, you (your time) and your agents have already committed to the wrong shape for the solution.
So at what point should we steer AI for code quality?
My take: as soon as possible in your workflow. To be specific, right before your agent starts coding. And that’s what this project verified.
What I built
I built PolicyNIM as a thin, pre-coding layer for coding agents. The goal was to give agents policies on security and backend implementations that mirror high quality standards for shipping software. With that type of context, agents can begin generating code in line with the policies.
Ideally, you can trigger policyNIM during the planning mode with your agents. For code review, agents can validate the code against those policies as well.
I kept the design small on purpose. PolicyNIM uses a Markdown policy corpus, a retrieval layer, and two access surfaces.
The policy corpus
The policies are security, backend, and authentication-focused. I scaffolded this from deep research into best practices and codified them into structured Markdown files that the tool’s LanceDB database will ingest. Here’s an example. More policies can be added, but I started with these since they address critical aspects of software.
The NVIDIA stack
The retrieval layer runs on NVIDIA-hosted embeddings (nvidia/llama-nemotron-embed-1b-v2) and reranking (nvidia/llama-nemotron-rerank-1b-v2), both accessed via the NVIDIA API Catalog.
PolicyNIM’s intelligence layer is entirely NVIDIA-hosted. I wanted production-grade semantic retrieval that I could wire in cleanly and trust. The NVIDIA API gave me exactly that.
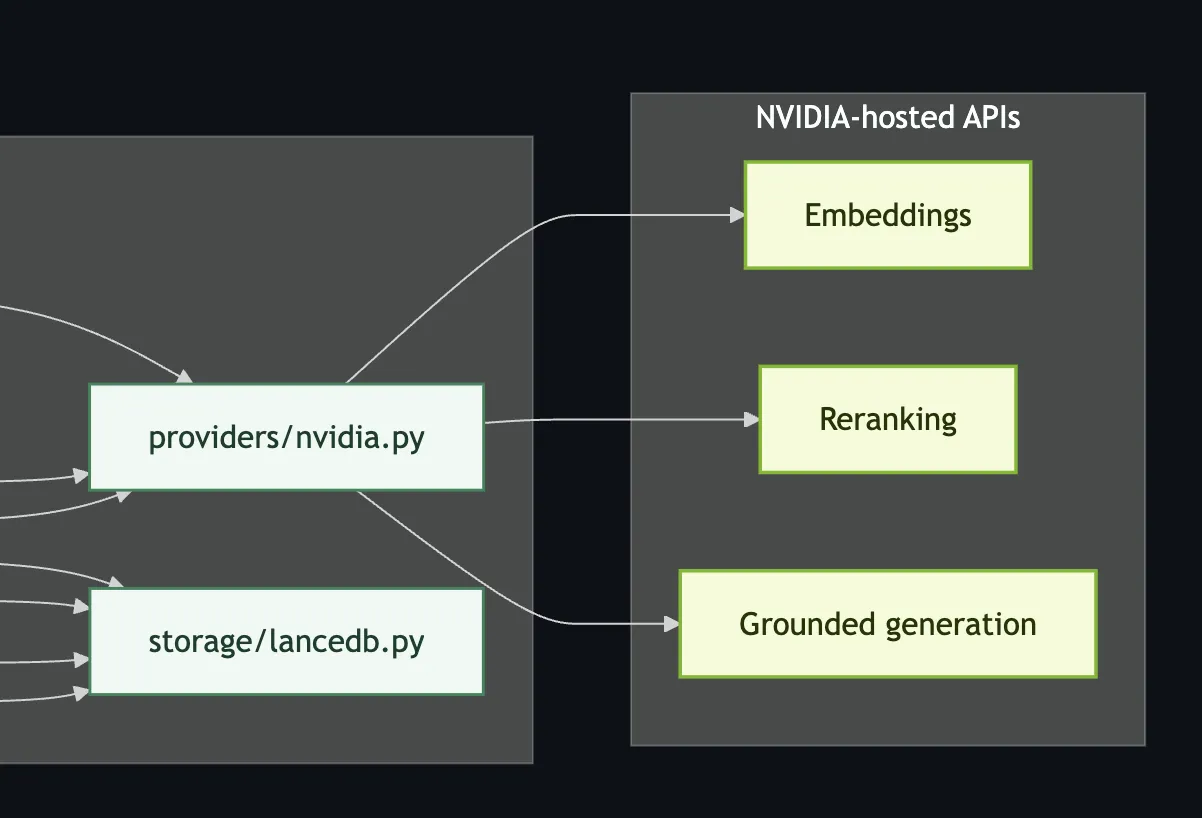
Check out the architectural diagram for the project setup and runtime flow!
Embeddings
Every policy chunk and every incoming query gets embedded using NVIDIA’s Nemotron embedding model. This is what allows PolicyNIM to retrieve semantically relevant policies, not just keyword matches.
A task like “implement a refresh-token cleanup background job” doesn’t share obvious keywords with a policy about audit logging, but the embedding model bridges that gap.
Reranking
After the initial dense retrieval pass, NVIDIA’s reranker rescores and reorders the candidate chunks relative to the original query. This is what separates retrieved from relevant. Without reranking, you get the top chunks by vector distance. With it, you get the chunks most likely to govern that specific task. The quality of preflight guidance depends heavily on this step.
Grounded generation via NVIDIA LLM API
The retained, reranked chunks are passed directly to NVIDIA’s hosted LLM API for synthesis. The LLM never sees chunks that failed citation validation.
If the grounding is weak, it will fail gracefully as opposed to hallucinating a confident answer. NVIDIA’s hosted inference makes this loop fast enough to use as a live preflight step.
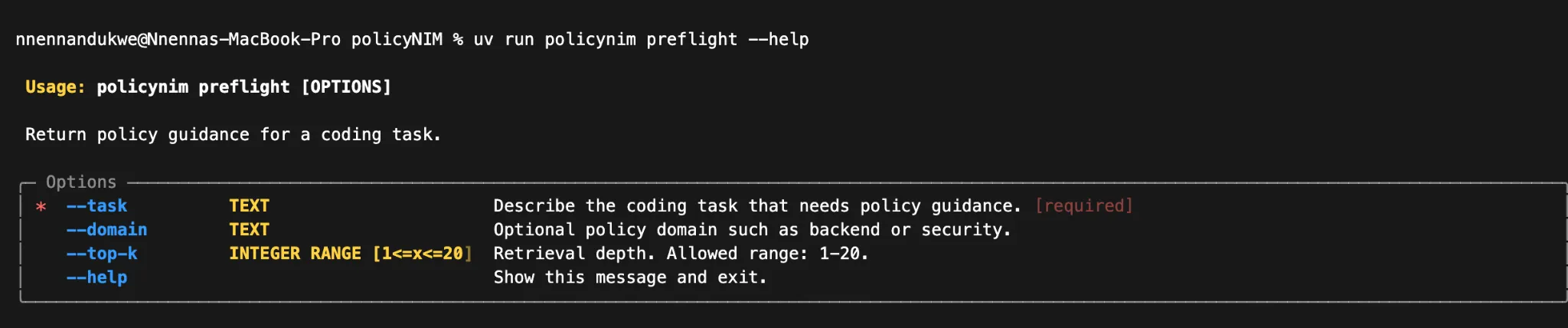
Access Point 1: the CLI
On the CLI side, I can run policynim preflight and policynim search.

Access Point 2: MCP Server
On the agent side, I can expose the same behavior through MCP with policynim mcp --transport stdio (or streamable-http), then call tools like policy_preflight and policy_search in other projects to verify coding implementation plans against best practice policies the MCP checks against.
The intent is to experiment with giving agents a verifiable starting point before code turns to AI slop too quickly.
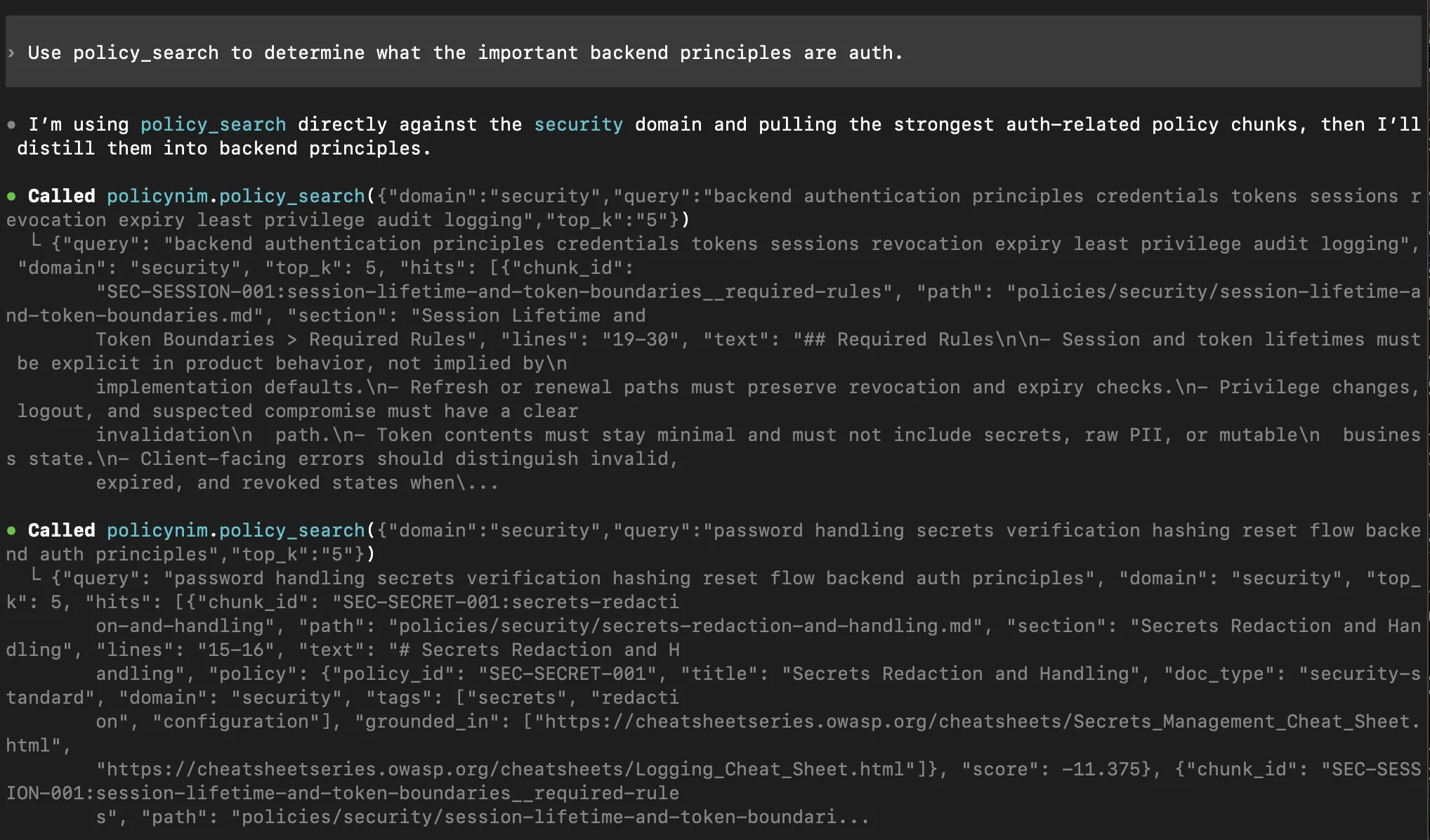
The workflow I tested
The prompt I gave to Codex CLI from an example project looked like this:
Use PolicyNIM to determine the full relevant policy surface for this task: Implement request correlation IDs and safe structured API logs for the packaged FastAPI service in this repo. Propagate the same request ID from inbound HTTP requests into background assessment execution logs for success and failure paths. Do not log request bodies, headers, target_config, prompts, payloads, secrets, or user text. Keep the change scoped to the packaged API/service surfaces and add tests.
That call gives the agent grounded guidance before generation. Then the agent writes code with the policy context already loaded. When the PR opens, I can spend less time pointing out missing standards and more time checking whether the implementation correctly handles them.

The job still needed review, but the review graduated from discovery to verification. That is a much better place for a developer to give their attention.
Patterns in code review comments point to an upstream failure
I started interpreting the review experience differently after building this.
PRs flooded with detailed, expert-level reviews are great only in theory. In some cases, they’re evidence that current AI-native dev workflows failed. And failed early.
If a reviewer keeps catching the same category of issue, the team should ask a simple question: why did the agent start work without that context in the first place? I think that goes beyond a developer being a decent prompt engineer. And it’s not always something that would be documented in a ticket in JIRA.
A more robust approach
This is where Qodo becomes useful for teams that want the behavior without building the whole stack themselves.
Qodo’s Rule System gives teams a centralized way to create, activate, scope, and manage engineering rules, including repo- and path-specific rules, instead of handling standards in an ad hoc way across separate tools and files. It’s adaptive, with rule discovery from codebase and PR history, ongoing lifecycle management, and enforcement across both pull requests and the local dev environment.
That matters for the workflow I’m describing because Qodo has a concrete mechanism for loading rules before code tasks begin. In the qodo-get-rules skill, it loads org-level, repo-level, and path-level coding rules from Qodo before code generation or modification tasks begin. It determines scope from the git repository, fetches active rules from Qodo, groups them by severity, and expects agents to apply those rules during the code task.
It’s an operational rules system you can plug into the workflow without owning the whole retrieval and maintenance stack.
How to do this yourself
If I were advising a team that uses coding agents today, I would keep the workflow simple.
- Fetch the relevant rules before the agent starts coding.
- Use the rules to help influence the plan for your agent.
- Generate code with that context loaded.
- Send the result to review in a PR
If you want better AI-generated code, load the standards before generation. Then use AI code review to verify the results against your coding standards.
Expect more detailed, technical research articles on the code quality results of using policyNIM and Qodo.


