How we built a real-world benchmark for AI code review


This blog reflects a collaborative effort by Qodo’s research team to design, build and validate the benchmark and this analysis.
This blog introduces the Qodo’s code review benchmark 1.0, a rigorous methodology developed to objectively measure and validate the performance of AI-powered code review systems, including Qodo Git Code Review. We address critical limitations in existing benchmarks, which primarily rely on backtracking from fix commits to buggy commits, thereby narrowly focusing on bug detection while neglecting essential code quality and best-practice enforcement. Furthermore, previous methods often utilize isolated buggy commits instead of simulating a complete pull request (PR) review scenario on genuine, merged PRs, and are constrained by a small scale of PRs and issues.
Our research establishes a new standard by intentionally injecting defects into genuine, merged pull requests sourced from active, production-grade open-source repositories
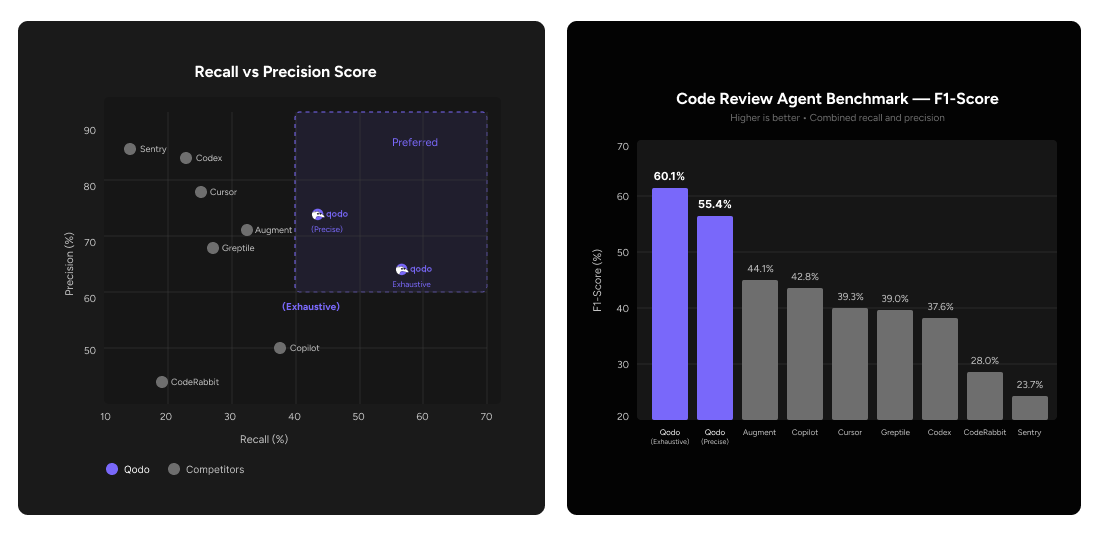
This novel approach is uniquely designed to simultaneously evaluate both code correctness (bug detection) and code quality (best practice enforcement) within a realistic code review context and at a significantly larger scale – 100 PRs containing a total of 580 issues. In a comparative evaluation pitting the Qodo model against 7 other leading AI code review platforms, Qodo demonstrated superior performance, achieving an F1 score of 60.1% for reliably identifying this diverse set of defects. The benchmark, including tools evaluated reviews, is publicly available in our benchmark GitHub organization. The following sections detail our benchmark creation methodology, experimental setup, comparative results, and key takeaways from this evaluation.
Related work
While there are many benchmarks for AI code generation and bug fixing, SWE‑Bench being the most well-known, the code review domain has historically lacked robust evaluation datasets. Greptile made an important first step by creating a benchmark based on backtracking from fix commits, measuring whether AI tools could catch historically fixed bugs. Augment also used this approach to evaluate several AI code review tools. These methods are effective at spotting real bugs but are limited in scale, often only a single bug per commit review, and do not capture the size, complexity, or context of full pull requests.
Qodo takes a different approach by starting with real, merged PRs and injecting multiple issues, including both functional bugs and best-practice violations. This enables the creation of larger, more realistic benchmarks for testing AI tools in system-level code review scenarios, capturing not just correctness but also code quality and compliance. By combining larger-scale PRs with dual-focus evaluation, Qodo provides a more comprehensive and practical benchmark than prior work, reflecting the full spectrum of challenges encountered in real-world code review.
Methodology
The Qodo Code Review Benchmark is constructed through a multi-stage process of injecting complex and non-obvious defects into real-world, merged pull requests (PRs) from active open-source repositories. This controlled injection approach is fundamentally designed to simultaneously evaluate both core objectives of a successful code review: code correctness (issues detection) and code quality (best practice enforcement). This integrated design allows us to create the first comprehensive benchmark that measures the full spectrum of AI code review performance, moving beyond traditional evaluations that focus mostly on isolated bug types.
Importantly, this injection-based methodology is inherently scalable and repository-agnostic. Because the process operates on real merged PRs and extracts repository-specific best practices before injection, the benchmark generation can be applied to large volumes of PRs and to any codebase, open-source or private. This makes the framework a general mechanism for generating, high-quality code review evaluation data at scale.
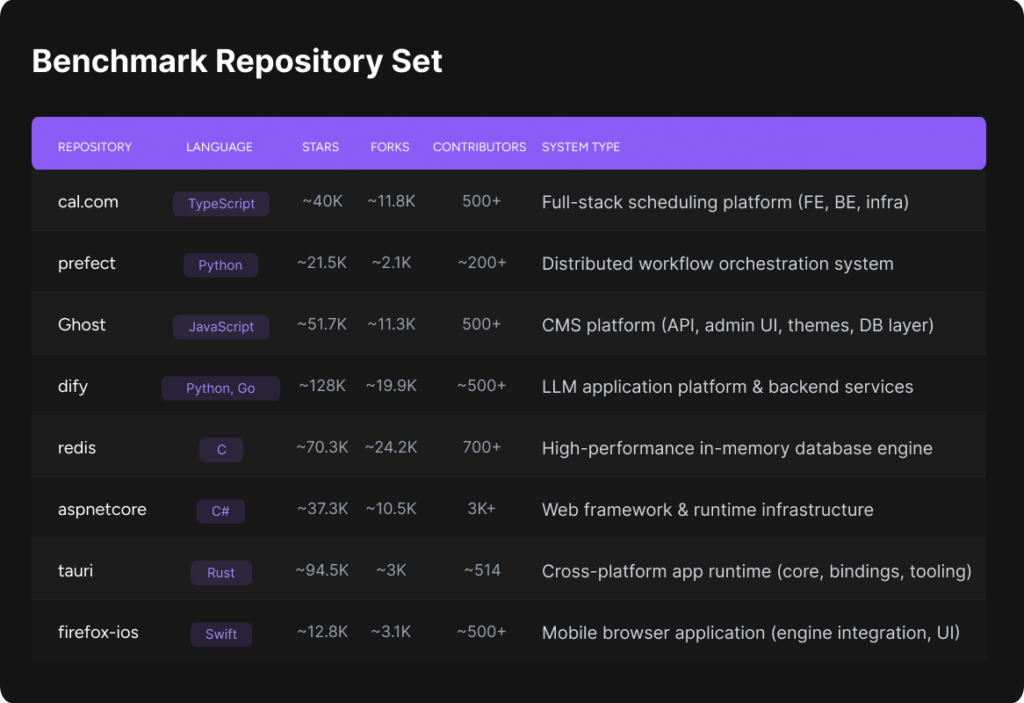
- The benchmark repositories were strategically chosen to create a realistic, system-level code review environment. The core selection criteria focused on two aspects: 1) System-Level Code: Projects are production-grade, multi-component systems (e.g., server logic, FE, DB, API) that reflect the complexity of enterprise pull requests involving cross-module changes and architectural concerns. 2) Language Diversity: The set intentionally spans diverse technology stacks and ecosystems. including TypeScript, Python, JavaScript, C, C#, Rust, and Swift.
- Repository Analysis and Rule Extraction: We first analyze each target repository to collect and formalize a set of best practice rules. These rules are carefully curated to align with the repository’s current coding standards, style guides, and contribution guidelines, extracted from documentation and full code base analysis using an Agent-based parsing process and human validation.
- PR Collection & Filtering: PRs from targeted open-source repositories are collected via the GitHub API and subjected to strict technical filters (e.g., 3+ files, 50-15,000 lines changed, recently merged). To ensure the highest quality of ‘clean’ code for injection, we exclusively select PRs that were merged without subsequent reverts or immediate followup fix commits. After identifying all quality candidates, we validate that the selected PRs align with the extracted best practice rules before any compliance issues are injected.
- Violation Injection (Compliance Stage): compliance violations are injected into each filtered, compliant PR using an LLM, corrupting the diff while preserving the original functionality.
- Issues Injection (Additional Bugs Stage): an additional 1-3 functional/logical bugs are injected. These issues span various categories, including logical errors, edge case failures, race conditions, resource leaks, and improper error handling, creating a final benchmark instance with multiple, simultaneous defects for AI models to detect.
- Ground Truth Validation: Following all injection steps, we perform a double verification of all modified PRs. Any additional, naturally occurring subtle issues or best practice violations found during this final check are manually added to the ground truth list, ensuring the benchmark’s accuracy and comprehensive coverage of realistic defects.
Evaluation
Set up
The evaluation setup was designed to closely mirror a production development environment:
- Repository Environment: All benchmarked pull requests (PRs) were opened on a clean, forked repository. Prior to opening the PRs, we ensured that the repository-specific best practice rules, formalized in an AGENTS.md file, were committed to the root directory, making them accessible to all participating tools for compliance checks.
- Configuration: Each of the 7 evaluated code review tools was configured using its default settings to automatically trigger a review upon PR submission.
- Execution & Validation: All benchmark PRs were systematically opened. We monitored all tools to confirm they ran without errors, re-triggering reviews when necessary to ensure complete coverage.
- Data Collection: Inline comments generated by each tool were meticulously collected.
- Performance Measurement: The collected findings, inline comments generated by each tool, were rigorously compared against our validated ground truth using an LLM-as-a-judge system. The core metrics calculated are defined as follows:
- Hit Definition: An inline comment generated by a tool is classified as a “Hit” (True Positive) if two criteria are met:
- The comment text accurately describes the underlying issue
- The localization (the file and line number reference) is correct and points to the source of the issue.
- False Positive (FP): A comment is classified as a False Positive if it does not correspond to any issue in the ground truth list.
- False Negative (FN): An issue from the ground truth list is classified as a False Negative if no tool-generated comment meets the criteria of a “Hit” for that specific issue.
- Recall: Calculated as the rate of ground truth issues recognized by the tool.
- Precision: Calculated as the rate of tool-generated comments that correctly correspond to a ground truth issue.
- F1 Score: The harmonic mean of Precision and Recall
- Hit Definition: An inline comment generated by a tool is classified as a “Hit” (True Positive) if two criteria are met:
Results
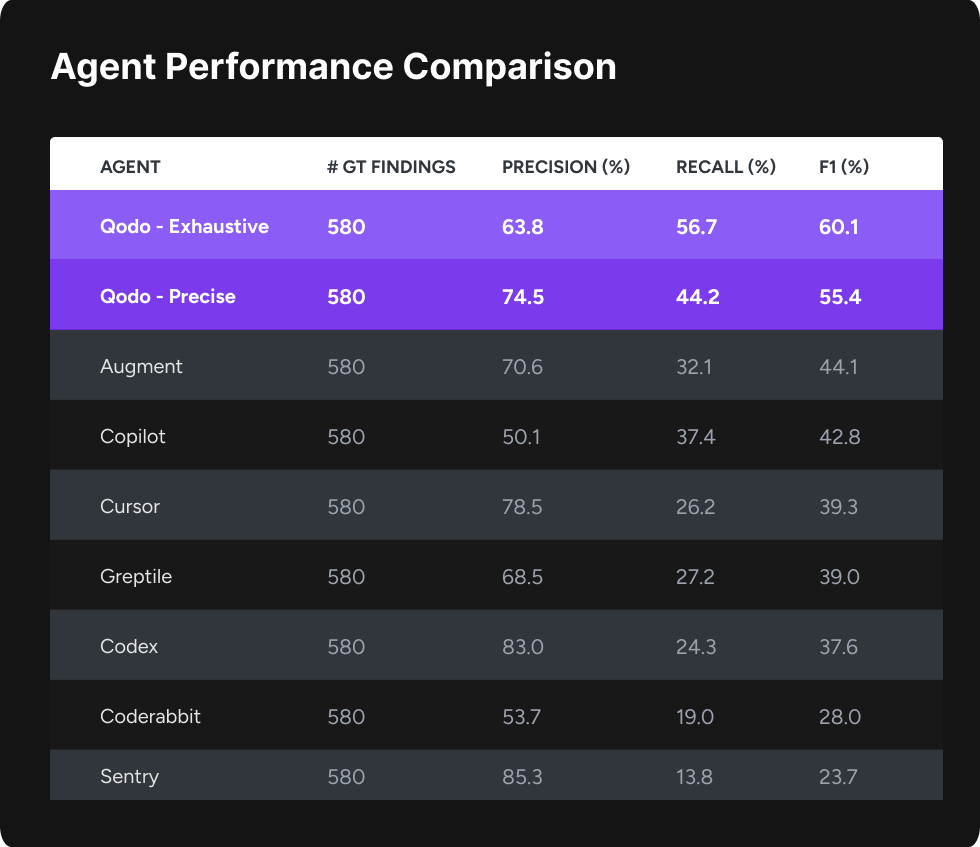
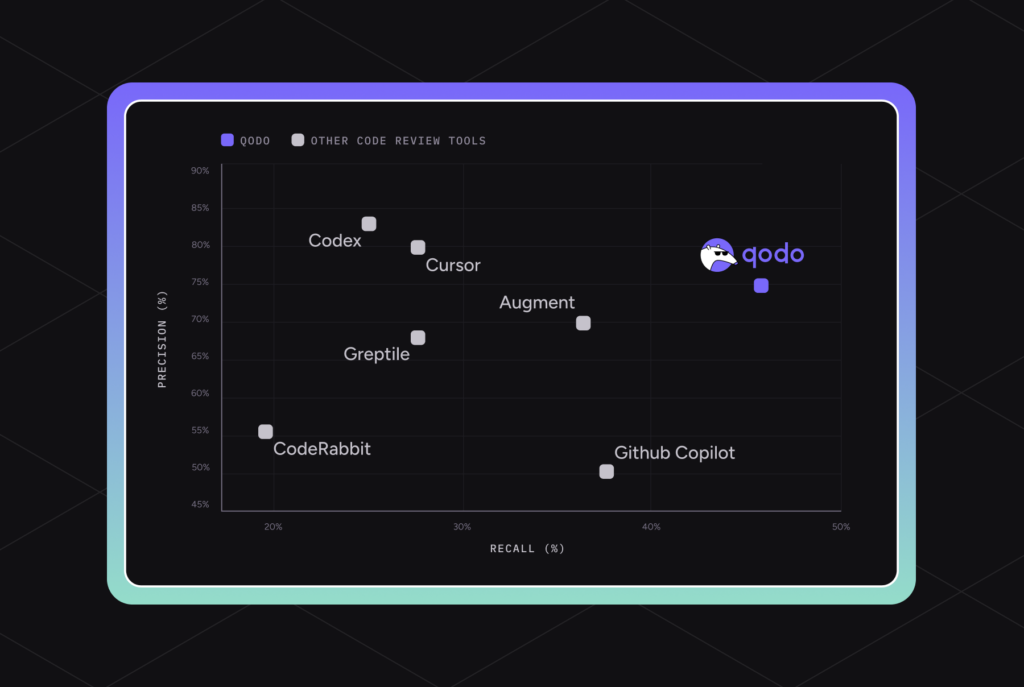
The results reveal a clear and consistent pattern across tools. While several agents achieve very high precision, this comes at the cost of extremely low recall, meaning they identify only a small fraction of the actual issues present in the PRs. In practice, these tools are conservative: they flag only the most obvious problems to avoid false positives, but miss a large portion of subtle, system-level, and best-practice violations. This behavior inflates precision while severely limiting real review coverage.
Qodo, in contrast, demonstrates the highest recall by a significant margin, while still maintaining competitive precision, resulting in the best overall F1 score. This indicates that Qodo is able to detect a much broader portion of the ground-truth issues without overwhelming the user with noise. Importantly, precision is a dimension that can be tuned post-processing according to user preference (e.g., stricter filtering of findings), whereas recall is fundamentally constrained by the system’s ability to deeply understand the codebase, cross-file dependencies, architectural context, and repository-specific standards.
Appendix
Selected repositories
The selected repositories span a broad and representative distribution of programming languages and system disciplines, covering full-stack web applications, distributed systems, databases, developer platforms, runtime infrastructures, and mobile applications, with complexity profiles ranging from single-language projects (redis in C, tauri in Rust) to polyglot systems (dify with Python/Go, aspnetcore with C#/JavaScript), making them well-suited candidates for code review benchmarking across different paradigms while reflecting the diversity of real-world codebases encountered in modern software development.