Introducing Qodo 2.0 and the next generation of AI code review


Code review has always been a last line of defense in the software development lifecycle. With AI generating code at rapid speed, that line is under pressure. Because of the growth of AI generated code, massive volume is now moving through pull requests, and mistakes carry wider impact when they are repeated across the system.
Qodo introduced our first review tool in 2023 and since then, we’ve expanded it into a full code review platform. We built an advanced context engine capable of bringing in context from across large-scale codebases, and added powerful agentic review workflows.
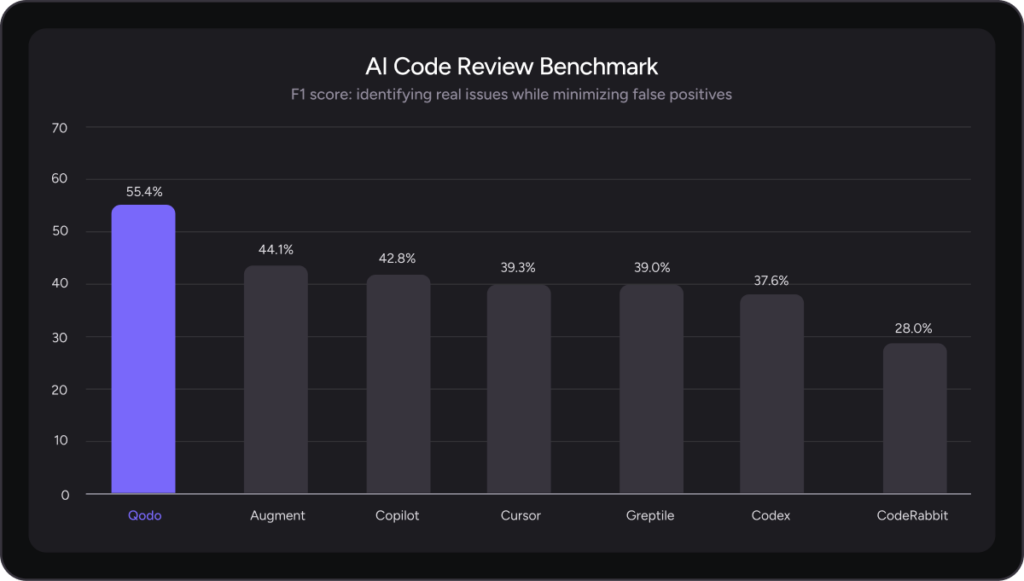
Today, we’re excited to announce the next generation of our review experience with the release of Qodo 2.0. With this release, Qodo introduces advanced innovations in context engineering and multi-agentic architecture to help close critical gaps in managing and enforcing AI code quality at scale. This SOTA Agent Architecture is validated by a new industry benchmark on real PRs with simulated real world bugs. Qodo 2.0 leads on this benchmark, achieving the highest overall F1 score at 60.1%, outperforming the next best solution by 9% and delivering the highest recall at 56.7%, finding more real issues than any other solution tested.
Why AI Pull Request review needed a rethink
The “AI Code Paradox” is showing up across engineering teams: AI-generated code has outpaced the systems meant to govern software quality. At the same time, AI review is emerging as a necessary tool to help tame this volume. But most AI reviewers simply add another layer of output without improving how review decisions are made. Without better reasoning and context, it risks amplifying the same problems teams already face.
The feedback we are hearing from customers is that most AI code review tools struggle in three areas:
- Too much noise from low impact comments: Over-flagging creates clutter, alert fatigue, and bulk-dismissed comments.
- Missed issues due to limited context and organizational understanding: Shallow context leads to blind spots on architecture-level reasoning, concurrency, maintainability trade-offs, and domain-specific rules.
- Review process friction: Without prioritization and control, AI review feels like bureaucracy, especially in large, fast-moving repos.
Enterprises with expanding AI development stacks are missing a layer of governance that enforces standards consistently and surfaces critical risk without slowing teams down.
A benchmark built for modern code review
Despite the growing need for effective code review tools, there is little rigorous benchmarking of AI code review, especially in real production conditions. As we evolved Qodo’s review system, it became essential to build a benchmark that matched the reality we were designing for. We created a new code review benchmark that evaluates AI tools on full pull requests from active, production-grade open source repositories. We inject multiple verified issues, spanning complex, non-obvious functional bugs and rule violations, to mirror real review scenarios.
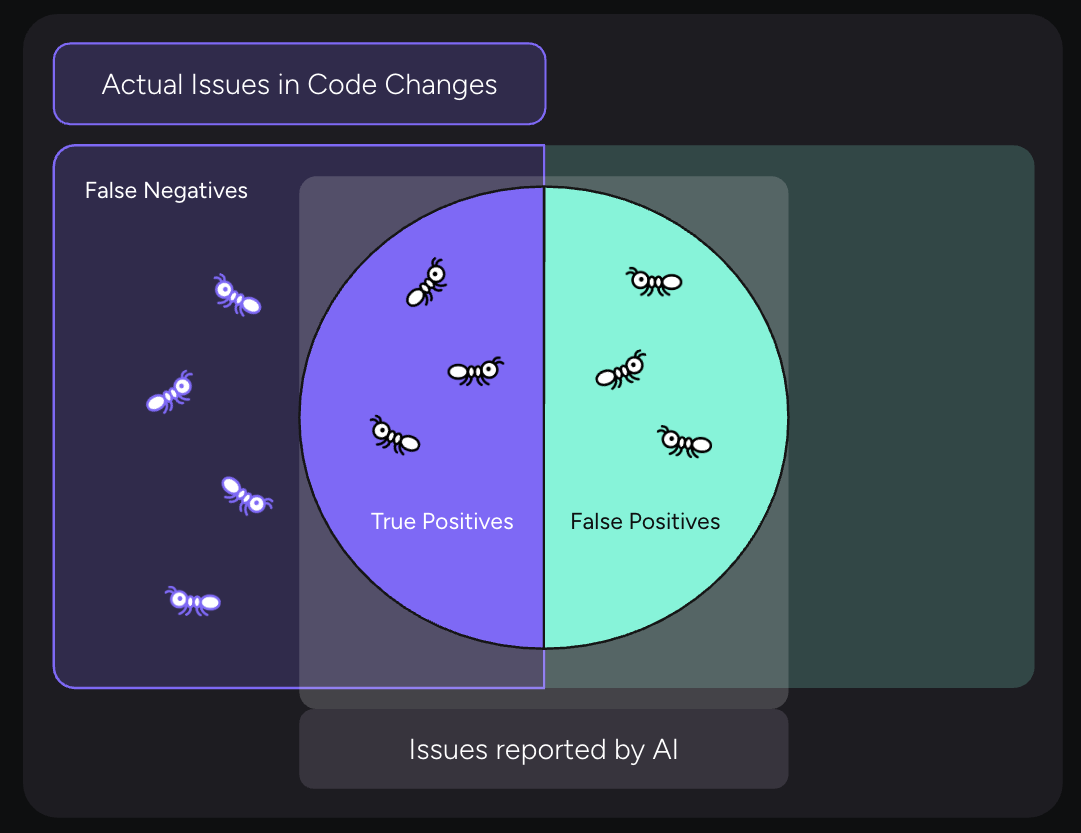
The benchmark measures precision and recall to capture both sides of review quality: how many real issues are surfaced and how much noise is introduced. Using this benchmark, Qodo 2.0 achieved the strongest overall balance of precision and recall, outperforming other AI code review tools.
What the benchmark results show
The results reveal a clear and consistent pattern across tools.
Several agents achieve high precision, however, this precision comes at the cost of very low recall. In practice, these tools flag only a small fraction of the actual issues present in the pull requests. They tend to surface the most obvious problems while missing subtler bugs, system-level risks, and best-practice violations. This inflates precision, but severely limits real review coverage.
Qodo shows a different profile.
In the benchmark, Qodo achieved the highest recall by a significant margin, while still maintaining competitive precision. This balance results in the strongest overall F1 score across all evaluated tools. We’ve also introduced a recall-optimized exhaustive mode with an even higher F1 score of 60.1, as shown in our benchmark blog.
The distinction between precision and recall matters in practice.
Precision can be tuned through filtering and prioritization once issues are found. Recall cannot. If a system fails to detect an issue, no amount of post-processing can recover it.
High recall depends on deep understanding of the codebase, cross-file dependencies, architectural context, and repository-specific standards.
The benchmark results reinforce the core design choices behind Qodo 2.0. Detecting more real issues without overwhelming developers requires a system that can reason across multiple dimensions of review, grounded in rich context.
That is what led to the multi-agent architecture and context engine at the core of Qodo 2.0.
Learn more about the benchmark methodology, results and dataset.
Introducing Qodo 2.0
Multi-agent expert review
We believe that code review is not a narrow task; it encompasses many distinct responsibilities that happen at once. Finding bugs, enforcing standards, assessing risk, and understanding context are separate forms of reasoning, even when they appear in the same pull request. In practice, reviewers switch between tasks like validating logic, checking compliance with standards, spotting risk, and understanding how a change fits into the broader system. Asking one reviewer or one agent to do all of this at once leads to tradeoffs between depth, speed, and coverage.
Qodo 2.0 addresses this with a multi-agent expert review architecture. Instead of treating code review as a single, broad task, Qodo breaks it into focused responsibilities handled by specialized agents. Each agent is optimized for a specific type of analysis and operates with its own dedicated context, rather than competing for attention in a single pass. This allows Qodo to go deeper in each area without slowing reviews down.
To keep feedback focused, Qodo includes a judge agent that evaluates findings across agents. The judge agent resolves conflicts, removes duplicates, and filters out low-signal results. Only issues that meet a high confidence and relevance threshold make it into the final review.
This multi-agent design is a key reason Qodo can maintain both high recall and high precision in real pull request conditions, as reflected in the benchmark results.
Context beyond the codebase
Even a strong multi-agent system falls short without the right context. Understanding a pull request requires more than analyzing the current diff. Many review decisions depend on why the code looks the way it does and how similar changes were handled before.
Qodo’s agentic PR review extends context beyond the codebase by incorporating pull request history as a first-class signal. The Qodo review system includes a specialized recommendation agent that references past PRs, previous review feedback, and recurring patterns to better understand intent, constraints, and tradeoffs.
This historical context helps avoid common failure modes in AI review. Our platform is less likely to flag changes that were deliberately accepted in the past, and more likely to catch regressions when behavior diverges from established patterns. Over time, reviews become aligned with how the system has actually evolved, not how a generic model assumes it should work.
PR history also enables Qodo to focus on what matters most for a given repository. Patterns in accepted fixes, rejected suggestions, and recurring issues inform which findings are likely to be relevant and actionable.
By combining full codebase context with pull request history, Qodo’s reviews reflect not just what the code is today, but how it arrived there. The result is feedback that is more consistent, easier to trust, and grounded in real engineering decisions rather than one-off judgments.
The anatomy of a Qodo issue finding
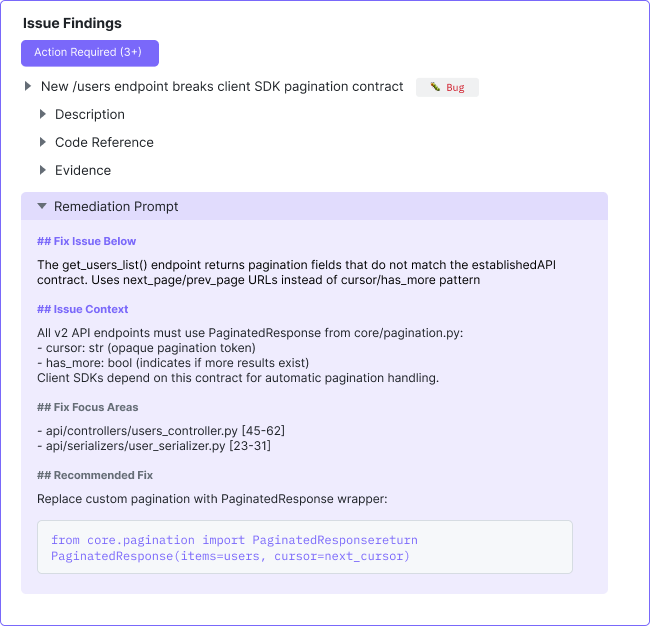
Each issue surfaced by Qodo’s agentic PR review is designed to be complete, precise, and easy to act on.
Rather than leaving scattered comments across a pull request, Qodo groups findings into a structured review. Issues are categorized by type, such as bugs, rule violations, or requirement gaps, and organized by severity so developers can focus on what needs attention first.
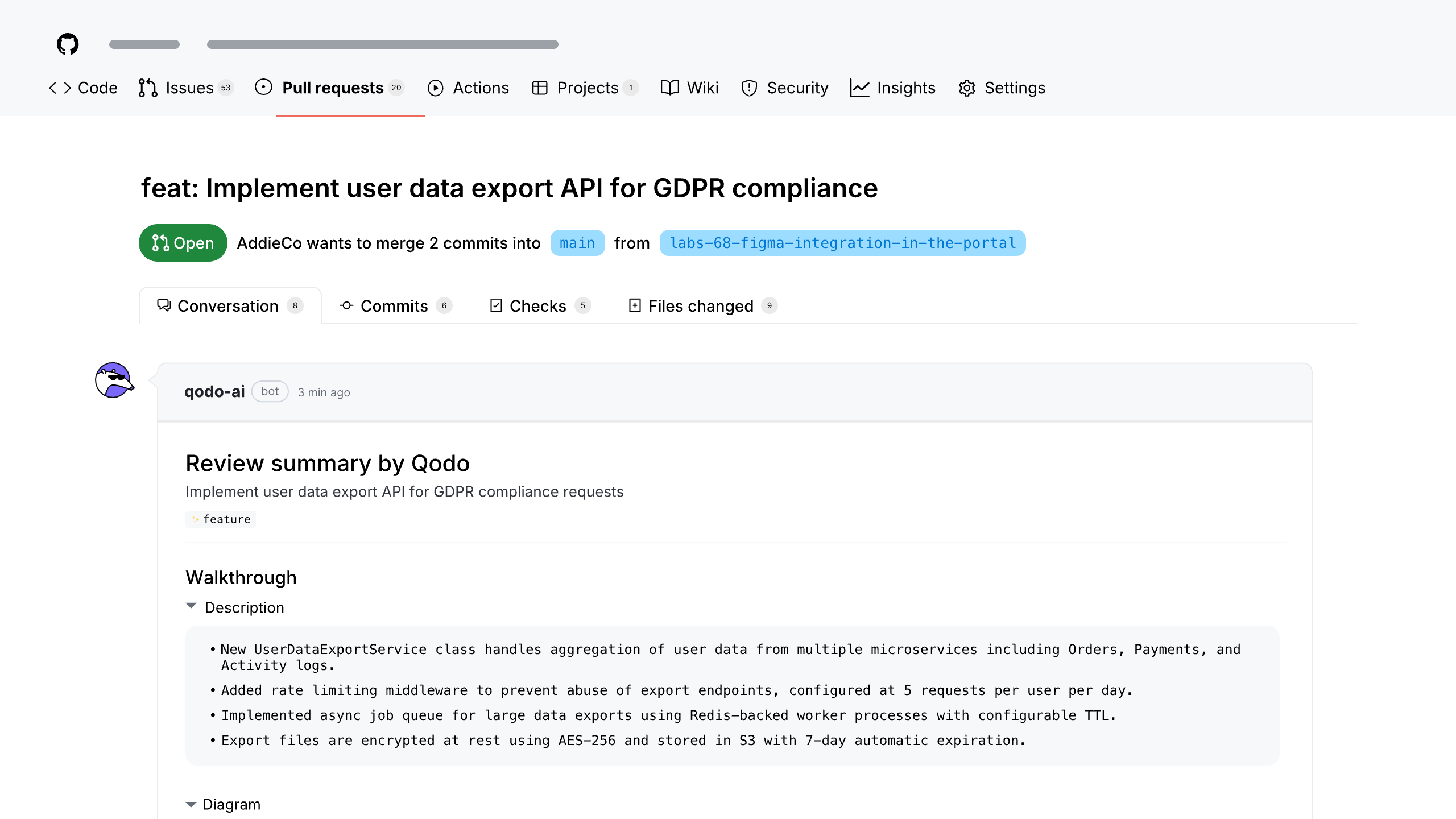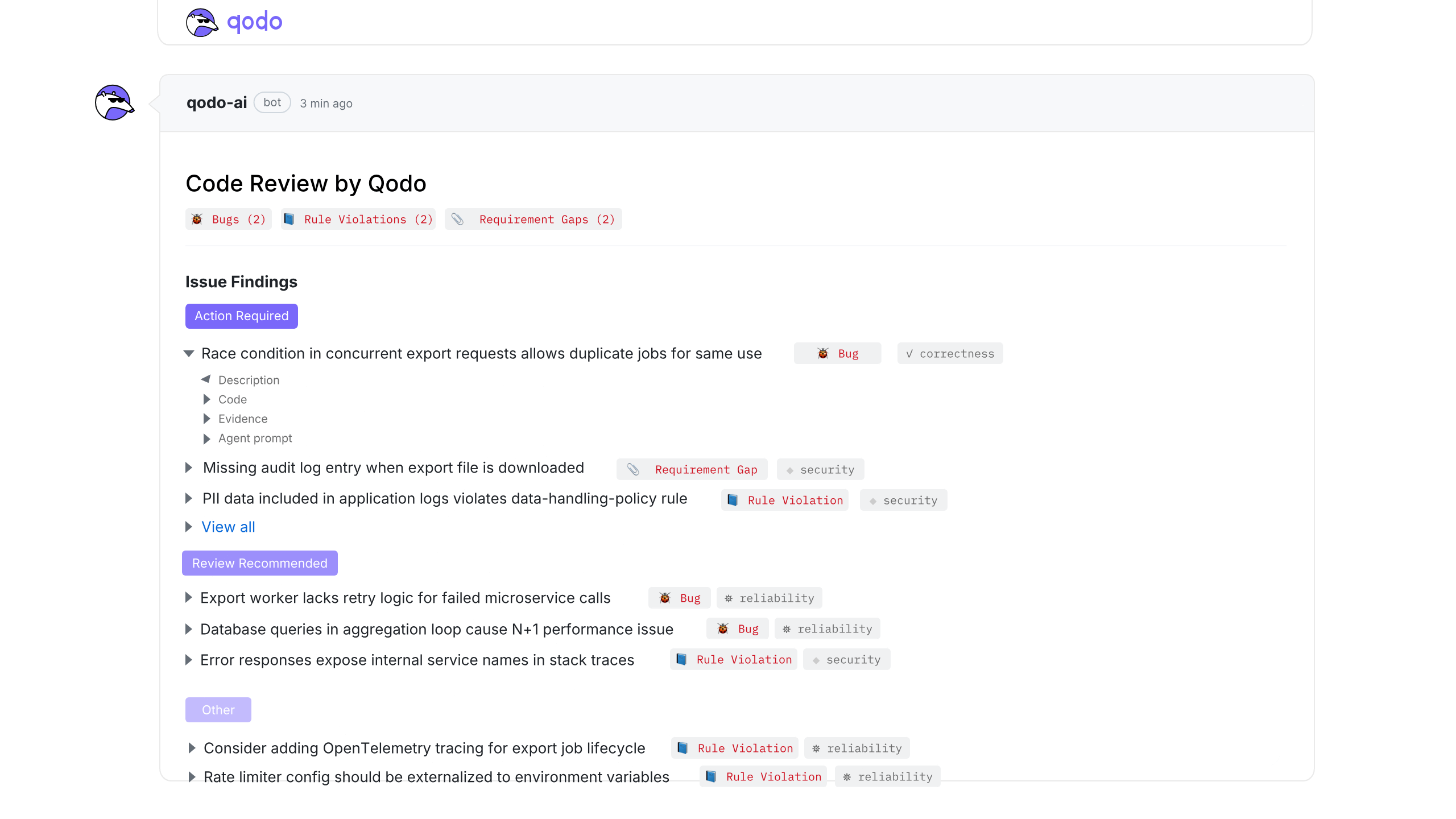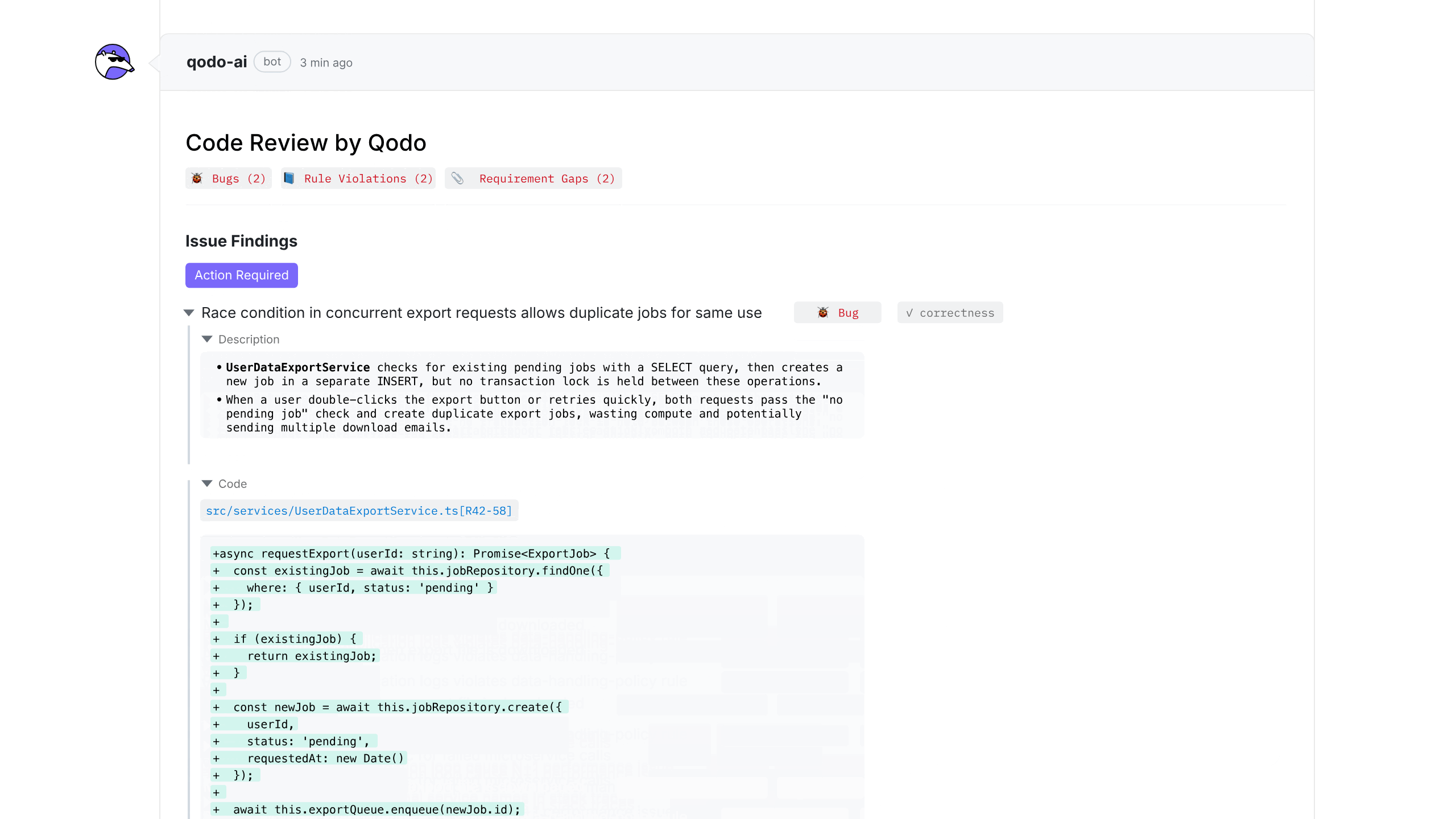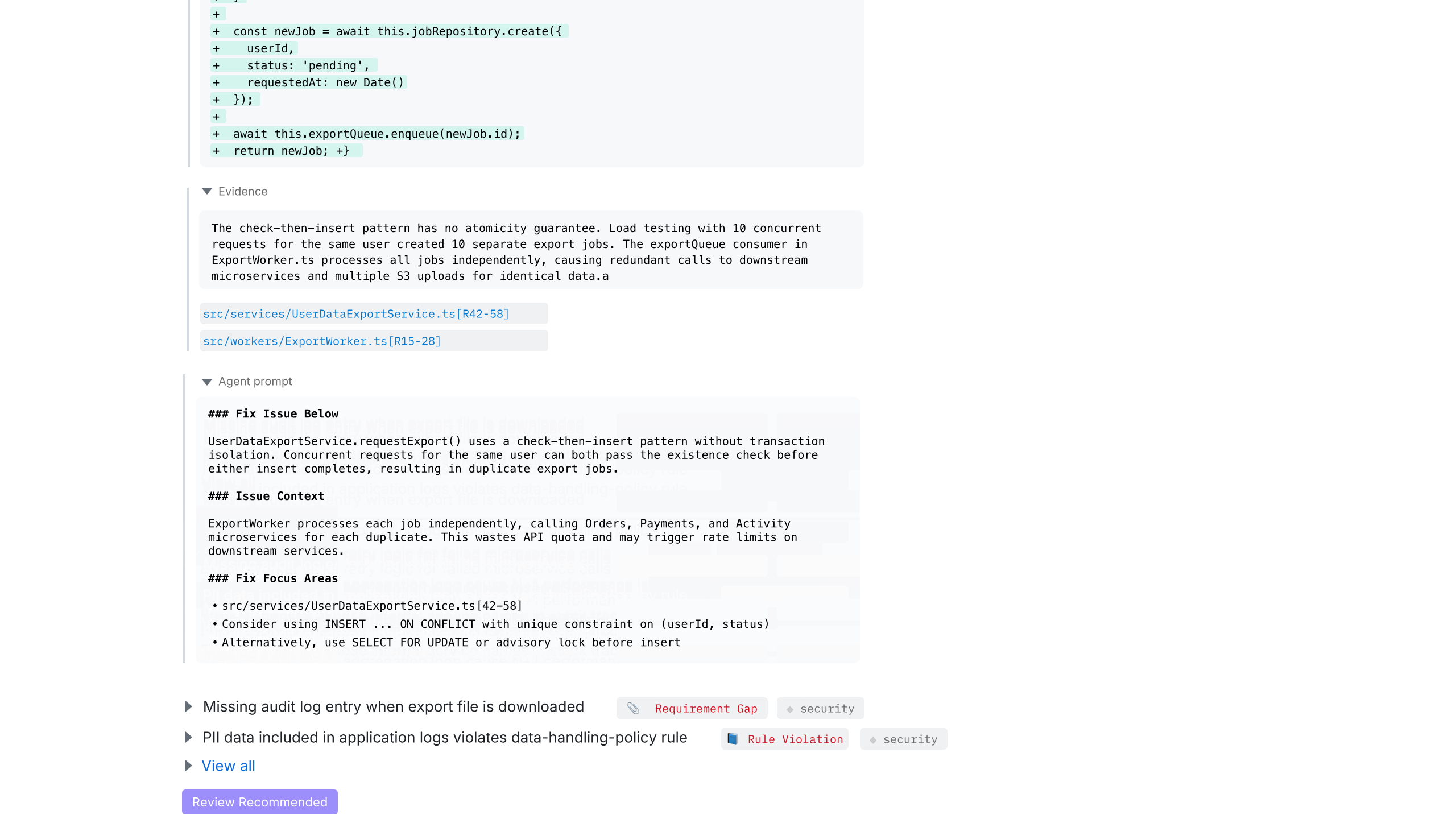
For every issue, Qodo provides:
- A clear explanation of what is wrong and why it matters
- A semantic label that shows which quality dimension is impacted, such as reliability or maintainability
- The relevant code snippet with file path and diff context highlighted
- Evidence and reasoning that explains how the agent reached its conclusion
This makes it clear that the finding is grounded in the actual code and system behavior, not a guess based on patterns alone.
Each issue also includes an agent-generated remediation prompt. Developers can copy this prompt directly into their preferred code generation or editing tool to fix the problem faster, with the full context preserved.
The goal is not just to point out issues, but to shorten the path from detection to resolution. By combining context, explanation, and a clear fix path in one place, Qodo turns code review findings into actionable work instead of back-and-forth discussion.
What comes next
Going forward we believe that if AI is going to write more of the code, review has to do more of the thinking.
The multi-agent system and context engine introduced in this release are not just features. They are the groundwork for how code quality scales when development does. They allow review to stay precise as volume increases and consistent as teams grow.
As organizations grow and development environments become more complex, this foundation becomes critical. Multiple teams, repositories, and workflows require consistency without rigidity and governance without friction.
The next phase of Qodo builds on this direction. You will see deeper support for organization-wide standards, stronger feedback loops between review and learning, and tighter integration into enterprise development workflows. The goal remains the same: help teams ship more code without losing control over quality.
Qodo 2.0 is not the end state. It is the system we needed to build to make what comes next possible. And we are just getting started…stay tuned for what comes next!


