NVIDIA Nemotron 3 Super is Closing the Gap for Open-Source Models



Open-source models are evolving fast. Every few weeks brings a new release pushing the boundaries of what’s possible with openly available weights in reasoning, code generation, and agentic tasks.
We’ve been paying close attention to this space, as a team building developer tools. Model choice affects cost, deployment flexibility, privacy constraints, and the ability to run AI systems in environments where external APIs are not an option. As open models improve, they are starting to compete with closed frontier systems in tasks that require deep understanding of code.
Code review is one of the most demanding of those tasks. It requires models to reason about logic, identify subtle bugs, understand context across files, and give actionable feedback rather than surface-level comments. Strong performance here is a signal that a model can meaningfully support real development workflows.
We decided it was time to take a rigorous look at where the current generation of open-source models stands on this problem. We ran nine models, both open-source and closed frontier, through an internal version of Qodo’s Code Review Benchmark. The results tell a compelling story about how quickly the open-source frontier is advancing.
Why Code Review Is Uniquely Hard for AI
Code review is not the same as code generation. When a senior engineer reviews a PR, they reason about the entire system, how a small change ripples through APIs, database schemas, concurrency patterns, and deployment constraints. They catch what linters can’t: the config change that silently breaks migrations, the missing edge case that only matters under load. This process is knowingly complex for humans, and the same applies to AI systems.
At Qodo, we tackle code review and AI code governance with a multi-agent architecture.
That architecture makes code review a demanding task for LLMs.
It’s a complex agentic system that requires multiple capabilities working in concert: deep code understanding across large and interconnected codebases, efficient and accurate agentic retrieval to pull in the right context from repos, history, and documentation, and the ability to produce complex, structured outputs that must be precise with actionable review comments grounded in the actual code. Previous generations of open-source models have consistently fallen short on these complex demands.
Why Open Source Matters for Code Review
Qodo serves enterprise customers that operate in air-gapped and regulated environments where sending code to third-party APIs isn’t an option. These customers run models in their own infrastructure and use them through Qodo’s platform for production code review.
In practice, that means self-hosting open-source models like NVIDIA Nemotron 3 Super and running them through Qodo’s platform to review real pull requests. This setup gives teams AI assistance without giving up control over data residency, compliance requirements, or intellectual property.
For these environments, model quality is not optional. Code review is a discriminative, context-heavy task that requires strong reasoning across large codebases. If an open model cannot handle that level of complexity, it cannot be deployed in production. Every improvement in open-source model quality directly translates to better review coverage for our most security-conscious customers.
That is why we continuously evaluate new open-source releases against our benchmark. The goal is simple: identify which models are strong enough to recommend and support for real code review workloads. Each improvement in open-source performance directly expands what our most security-conscious customers can run inside their own environments.
Evaluation of Open-Source Models Closing the Gap
We evaluated six open-source models and three frontier models on an internal version of Qodo’s Code Review Benchmark (an open benchmark is publicly available on Hugging Face) The benchmark focuses on two key capabilities: identifying defects and enforcing code governance rules across real pull requests from production repositories. Performance was measured using precision, recall, and F1.
All evaluations were conducted using our multi-agent harness without model-specific optimization. To ensure robustness, the system retried tasks up to three times if a model failed to complete them with a valid output.
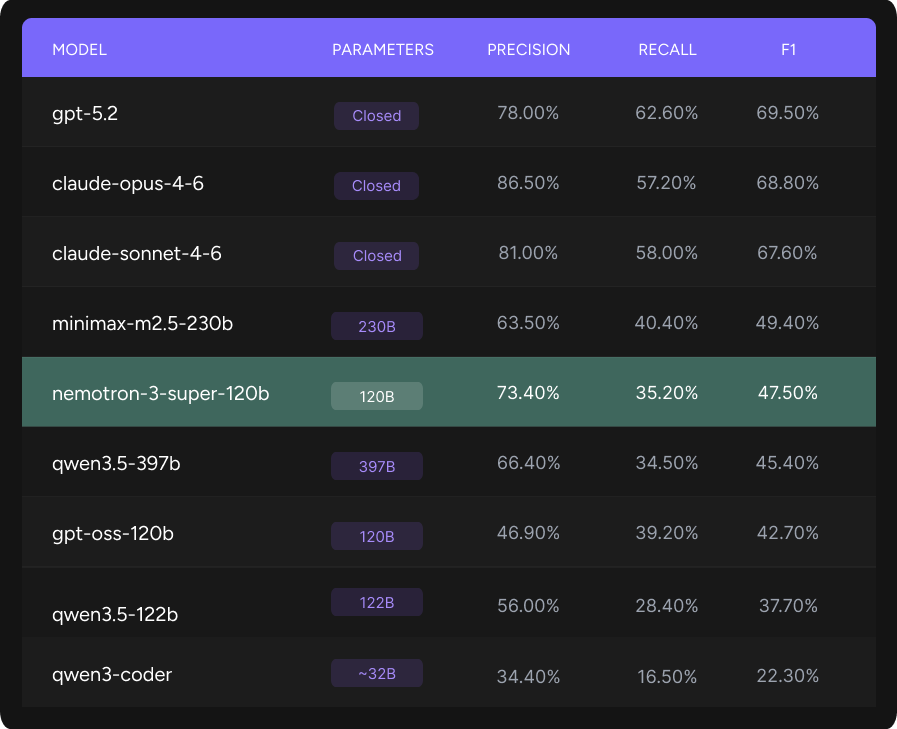
Among the recent wave of open-source releases, one model stood out in our evaluation: NVIDIA Nemotron 3 Super, a 120B open hybrid MoE model (12B active), delivers high efficiency and accuracy for multi-agent AI. It provides cost-efficient inference and a 1M context window for long-term, aligned reasoning. Being fully open, Nemotron 3 Super can be customized and deployed securely anywhere.
![]()
When looking at the Qodo Code Review Precision vs Recall graph, it’s helpful to think of it as a balance between “Trust” and “Thoroughness.” The graph compares Precision (the “Trust” factor of accuracy) against Recall (the “Thoroughness” of catching all bugs), with Nemotron 3 Super leading the open-source field with a high Precision of 73.4%.
The top right corner represents perfect results in industry. By sitting higher on the vertical axis than its open-source competitors, Nemotron 3 Super ensures that the feedback it provides is highly reliable, minimizing the “noise” of false alarms for developers.
![]()
The F1 Score graph provides a single metric for overall performance by balancing precision and recall, where NVIDIA Nemotron 3 Super secures the second-highest position among open-source models with a score of 0.475.
What stands out:
- Frontier models still lead, but open source is closing the gap. The top three spots belong to closed models, yet large open-source models are now reaching competitive territory. Surprisingly, Nemotron 3 Super delivers comparable performance despite being roughly half the size of MiniMax and a third the size of Qwen3.5-397B.
- Nemotron 3 Super achieves the highest precision of any open model at 73.4%, surpassing Qwen3.5-397B (66.4%), MiniMax-M2.5-230B (63.5%), and GPT-OSS-120B (46.9%). When it flags an issue, it’s right nearly three-quarters of the time, which is critical for developer trust.
- Competitive F1 at a fraction of the size. Nemotron 3 Super’s F1 of 0.475 is within 2 points of MiniMax-M2.5 (0.494) and ahead of Qwen3.5-397B (0.454).
For our air-gapped customers running self-hosted models, this is a significant step forward.
Nemotron 3 Super’s 73% precision makes it the most practical open model for production code review today, high enough trust that developers actually act on the feedback, efficient enough to run at scale in self-serving closed environments with multi-agent pipelines.
Nemotron 3 + Qodo: How the Pieces Fit
NVIDIA Nemotron 3 Super sits at the model layer as the core reasoning engine, while Qodo’s multi-agent system orchestrates everything around it: retrieval from large, interconnected codebases, application of code governance rules, and generation of precise, structured, actionable review comments.
Nemotron 3 Super provides efficient, long-context analysis; Qodo turns that into trustworthy code review behavior that teams can plug directly into their software development lifecycle.
What Enterprises Can Do Today with Nemotron 3 Super + Qodo
If you operate in a regulated or security-conscious environment, you can self-host NVIDIA Nemotron 3 Super behind your firewall and plug it into Qodo’s review agents to enforce security, compliance, and quality rules on every pull request.
Engineering teams that use Qodo can add Nemotron 3 Super as a first-class model option in air-gapped environments, gaining higher-precision findings for critical repositories while preserving the same audit trails, governance controls, and developer experience they rely on today.
Qodo is a member of the NVIDIA Inception program. Inception is a global program for AI startups that provides developer training and resources, valuable offers from NVIDIA and our partners, and preferred access to NVIDIA’s AI ecosystem.
The Future is Bright for Open-Source Models
The gap to frontier closed models remains real, especially on recall. But the open-source frontier is moving fast, and Nemotron 3 Super demonstrates that the efficiency-to-quality tradeoff is getting dramatically better.
We’ll continue evaluating new models as they’re released and updating our recommendations for customers across deployment environments.