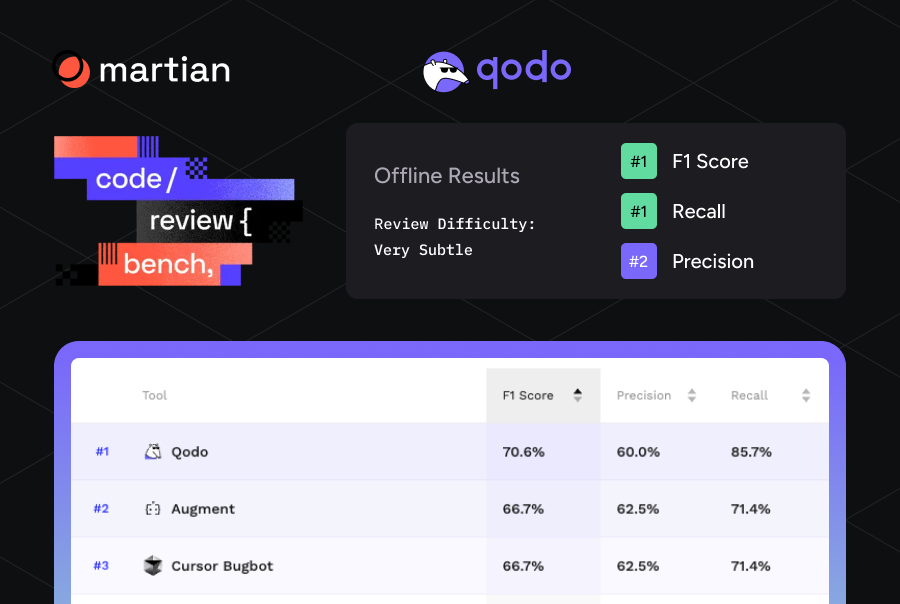
Qodo #1 on Toughest Bugs in Martian’s Code Review Bench

Last week, Martian released their Code Review Bench, and it’s already sparking much-needed conversations across the industry.
Qodo ranks #1 on the hardest reviews with nuanced bugs, leading where the issues are most complex and most likely to cause production failures. Across most other scenarios, Qodo consistently ranks #2, following only the company whose internal benchmark served as the Martian’s offline dataset.
As AI coding agents move from “cool experiment” to “daily coworker”, the stakes for how we verify their output have never been higher. AI coding agents are now responsible for a growing share of new code. As output increases, the surface area for bugs, security gaps, and logic errors also grows. Code review becomes a core control layer, not a secondary step.
Catching What Others Overlook
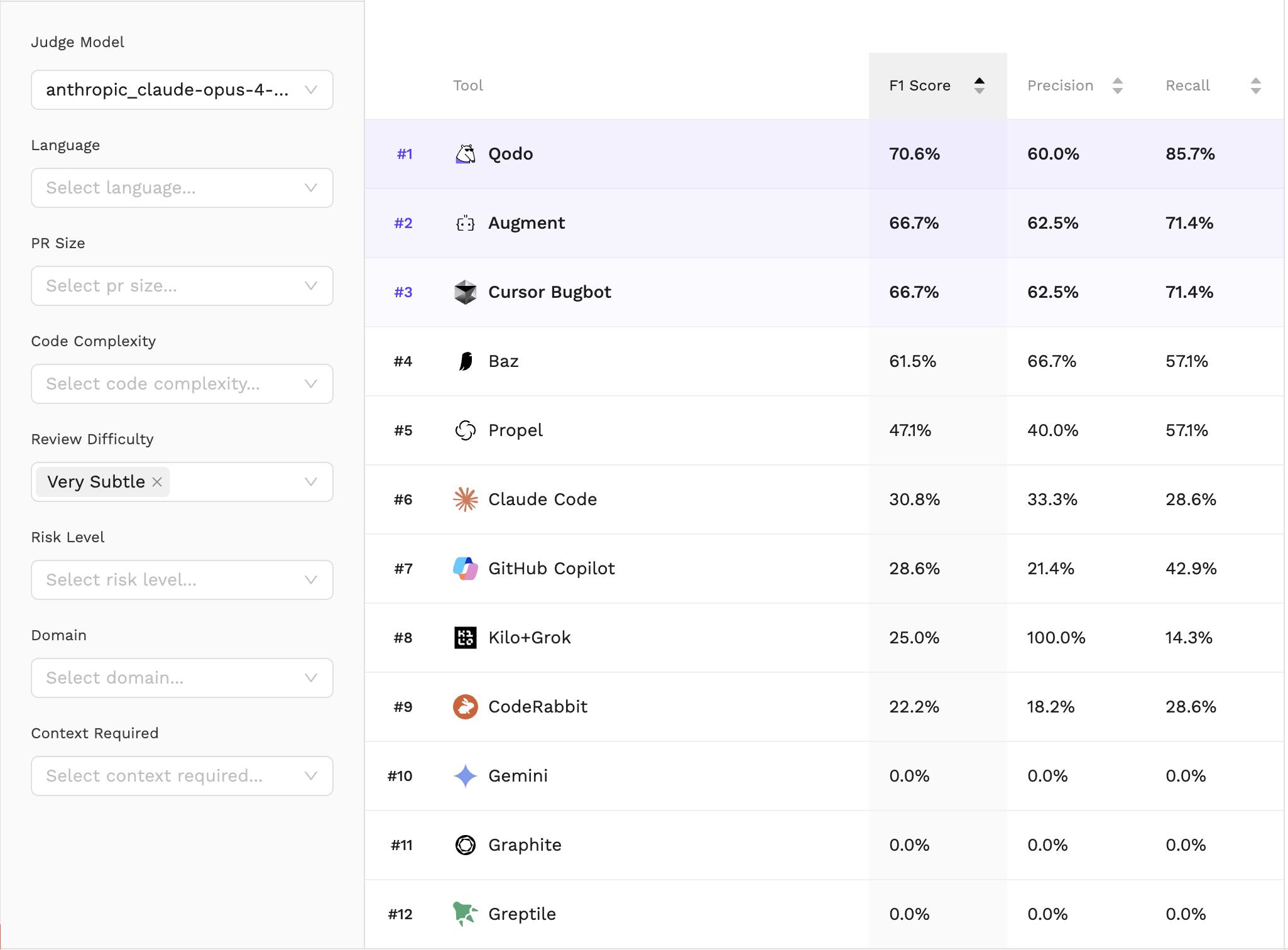
The benchmark is most striking when looking at the most elusive logical flaws. In these high-stakes scenarios, Qodo ranks #1 overall, achieving a dominant 85.7% recall and a 70.6% F1 Score. The data confirms a powerful narrative for Qodo: we catch the critical failures that others consistently miss.
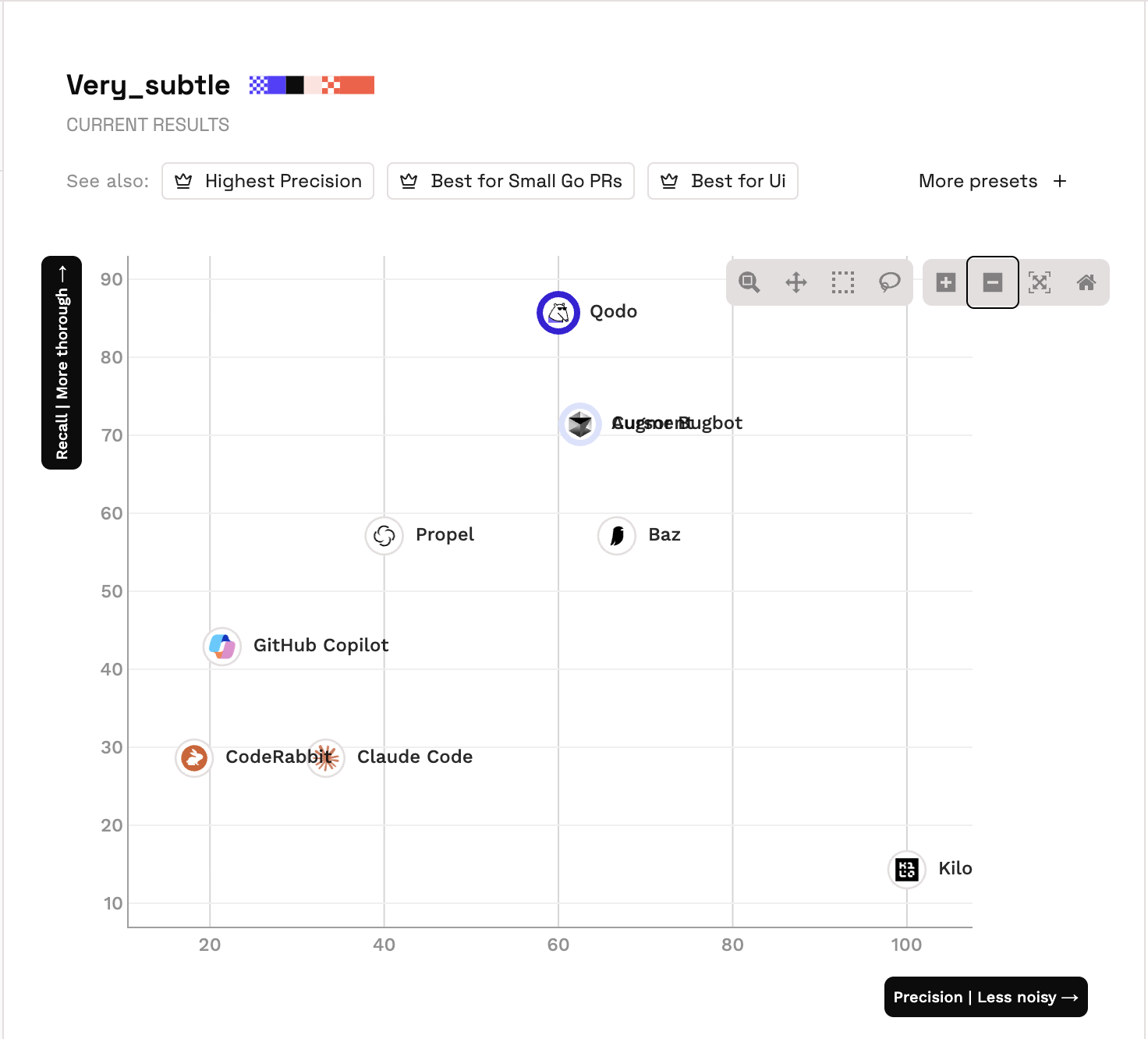
While other tools might maintain a clean signal by staying quiet, they often miss the very logic gaps that lead to production incidents. Qodo’s philosophy is different: a missed bug is a far greater risk than a slightly noisier review.
Why This Benchmark Is Important
Today there is no single widely accepted benchmark for AI code review tools. Most existing evaluations focus on related but narrower tasks such as bug detection or code generation. In many of these cases the datasets and scoring methods are not fully published or are hard to reproduce.
An independent benchmark for code review tools signals something bigger than rankings.
- Neutral Standards: It creates a shared baseline, giving teams a way to evaluate tools based on measurable performance rather than marketing claims.
- Critical Infrastructure: It reinforces that automated code review is becoming essential infrastructure in the AI development stack.
- Technical Rigor: The existence of this benchmark shows that the market recognizes code review quality as a serious technical problem that needs rigorous evaluation.
What this benchmark measures
Martian’s benchmark evaluates code review tools in two ways.
Offline (Head-to-Head): Tools are run on the same repositories, reviewing identical pull requests to allow for direct comparison under controlled conditions. It is important to note that this specific methodology is based on methodolgoies developed by competitors, which measures performance across 50 pull requests into which they manually introduced bugs.
Online (GitHub Scrape): This analyzes real-world activity by scraping data from GitHub, reflecting how tools perform on live pull requests in actual projects
In both cases, performance is measured using precision and recall.
Why a balance of precision and recall is the gold standard
Precision and recall measure two different kinds of risk.
Low precision creates noise. Developers waste time reviewing incorrect findings. Trust drops, and feedback is ignored.
Low recall creates blind spots. Real defects are missed. These are the issues that later surface as outages, regressions, or security incidents.
In code review, both risks matter. A system that optimizes only for precision may look clean, but it can allow critical issues through. A system that optimizes only for recall may surface more issues, but at the cost of developer friction.
The gold standard is balance, and the F1 score is exactly that. It combines precision and recall into a single metric, ensuring findings are both credible and complete. Precision keeps results actionable by filtering out noise; recall ensures no critical failure goes unnoticed. Together, they set the bar that any tool must clear.
The Results: Qodo Leads When it Counts
The results of the Martian Code Review Bench reveal how this balance plays out in practice. In head-to-head testing, Qodo emerged as a top performer, ranking second overall.
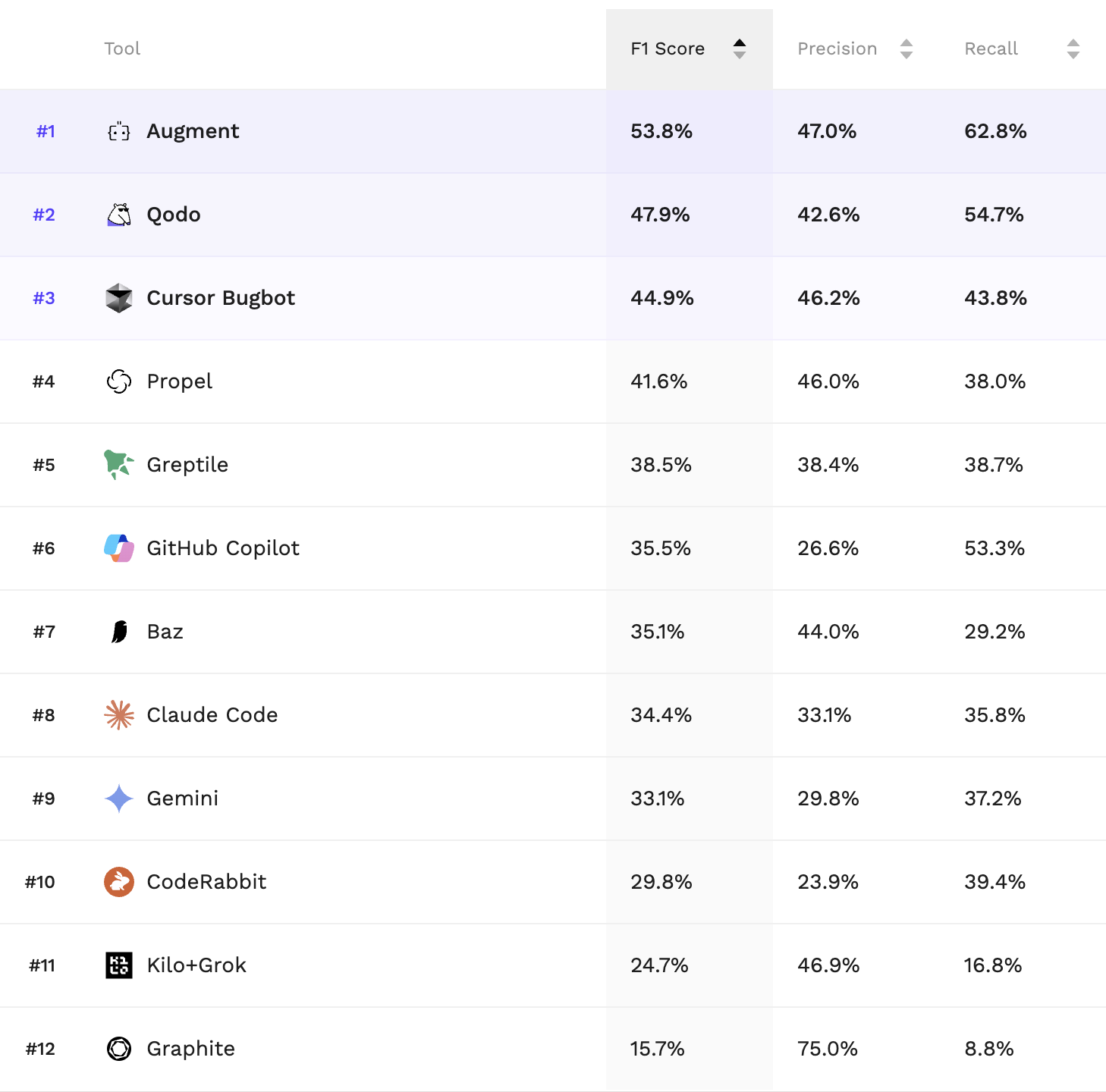
Navigating the results of the Code Review Benchmark
Benchmarks are useful, but they are not static truths. These leaderboards represent a snapshot in time rather than an absolute conclusion. A strong ranking signals capability. It shows how a system performs under measurable criteria. But long term performance depends on continuous iteration, transparent evaluation, and consistent retesting as both tools and benchmarks improve.
Maintaining accuracy also requires staying current. The initial benchmark run utilized an older version of Qodo, but the Martian team worked closely with us to re-run the evaluation using our latest release from early February. This collaborative approach ensured the results reflect the current state of our agentic technology. We remain committed to this transparency as we continue to push the boundaries of what automated review can handle.
Where We Believe Code Review Benchmarks Should Evolve
From our perspective, the Code Review Bench is an essential first step that could potentially evolve along three growth vectors:
- Scaling in Size: We expect to see the dataset expand to include a much larger volume of pull requests, providing a more robust statistical foundation for performance metrics.
- Increasing Complexity: The benchmark will likely introduce even more difficult challenges, testing the limits of how AI handles deep architectural flaws and cross-system logic.
- Broadening Technical Scope: We anticipate the evaluation will grow to cover a wider range of skills, including Model Context Protocol (MCP) integrations, documentation review (.md files), and the enforcement of complex, custom rule systems.
Qodo’s Vision to Raise the Review Bar
The benchmark is a checkpoint, not an endpoint.
We are continuing to refine Qodo’s review system to push both precision and recall higher. The objective remains consistent: surface more of the issues that matter while keeping feedback clear and actionable.
The next frontier is depth, and this is an area where Qodo already operates and continues to expand. Enterprise codebases are not clean test repositories. They include layered abstractions, legacy paths, internal frameworks, and years of accumulated decisions. Review quality depends on understanding that context, not just analyzing a diff in isolation.
Qodo is designed to reason across that complexity. It adapts to how a specific team builds software by learning recurring patterns, internal standards, architectural rules, and security requirements, then applying that understanding during review. We are continuing to strengthen this capability with wider sources of context.


