Qodo scores 71.2% on SWE-bench Verified


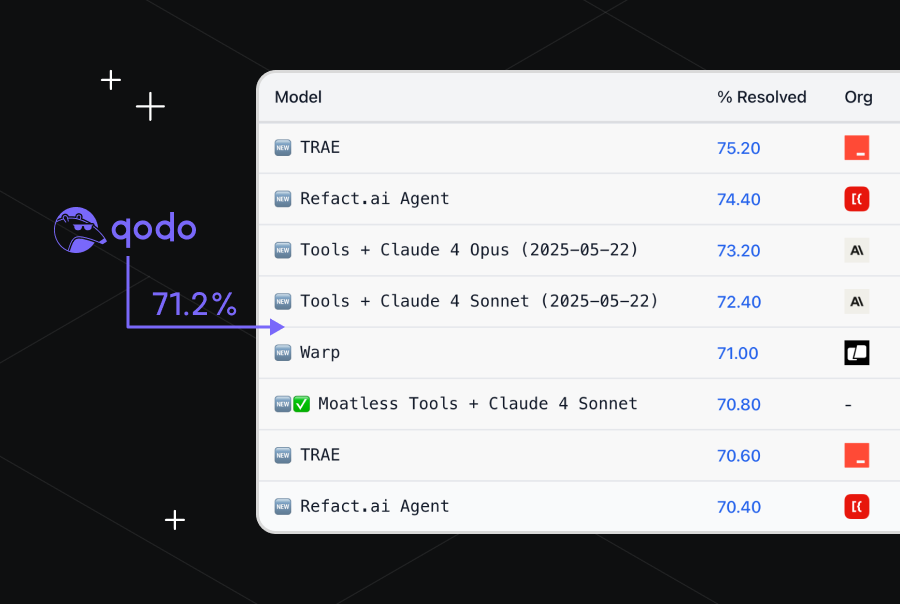
We’re excited to announce that Qodo Command, our CLI agent, achieved a scored of 71.2% on SWE-bench Verified (submission pending review), the leading benchmark for evaluating AI agents on real-world software engineering tasks.
This achievement is a strong signal that Qodo’s agents are built for the realities of production development. For use cases like reviewing code, writing tests, fixing bugs, and generating features, our CLI agent goes beyond autocomplete to deliver thoughtful, context-aware, and high-integrity code.
One-Shot, Real-World Execution
Most AI benchmarks evaluate agents in isolated, simplified environments. However, SWE-bench Verified tests coding agents in messy, complex, real-world software engineering scenarios. Each test case in SWE-bench is built from a real GitHub issue in one of 12 widely-used, open-source Python repositories. Agents are given the GitHub issue and the codebase in the state it was in when the issue was opened, and must reason, plan, and edit code, iterating over many turns as a developer would – without shortcutting the problem.
Qodo Command scored 71.2% using a single run of the production version of Qodo Command—no finetuning or benchmark-specific adjustments—exactly the way any developer would by running it out-of-the-box with the simple install package: npm install -g @qodo/command.
LLM Model Flexibility & Claude Partnership
While Qodo Command is designed to support all top-tier LLMs, Claude 4 emerged as our model of choice for SWE Bench Verified results. Thanks to a strong partnership with Anthropic—Qodo is a “Powered by Claude” solution, we’re collaboratively building the world’s most adaptive and learning-oriented coding agents, leveraging one of the most advanced language models available today.
The Architecture Behind Our 71.2% SWE-bench success
Achieving high performance on SWE-bench wasn’t about optimizing for the benchmark–it was the natural result of engineering Qodo Command to excel at real-world software engineering challenges. Here’s how our architectural decisions directly contributed to its performance:
Context Summarization
SWE-bench Verified tests AI on complex, muli-file codebases where understanding interdependencies is crucial for success. Succeeding in this environment requires more than feeding raw files to an LLM, pattern-matching or autocomplete.
Qodo Command solves this by distilling multi-layered code into precise, high-signal summaries—ensuring that language models receive only the most relevant, structured context at every step. This enables deep reasoning, accurate generation, and high-quality reviews without hitting context limits or losing essential detail.
Execution Planning
Qodo’s default plan-first approach ensures that implementation begins only after a structured breakdown of user intent. Instead of rushing into action, we first deeply analyze the user’s goal, then decompose it into clear, actionable subtasks arranged for optimal execution. This creates a roadmap for the LLM, enabling precise task tracking and reliable validation. Completion is judged not just by output but by strict adherence to the original plan—gaps trigger feedback and retry loops until full alignment is achieved
Retry and Fall-back Mechanisms
When a tool call fails, Qodo agents don’t stop—they adapt. The system extracts error feedback, invokes the LLM to diagnose the failure, and intelligently adjusts the tool parameters or structure. Agents are empowered to retry up to three times if needed, refining their calls each round. If resolution isn’t possible through retries, the agent pivots to alternative strategies, ensuring progress continues despite initial breakdowns.
Powered by LangGraph
Qodo Command uses LangGraph, a framework for agents and agentic workflows that require structure, modularity and state management, giving Qodo Command modularity and speed. LangGraph enables graph-based orchestration, where each step is a configurable node. This foundation allowed us to reuse and extend proven components from Qodo Gen, our IDE extension—including code analysis, summarization and security scanning—while giving us the flexibility to split, extend and repurpose workflows effortlessly.
Agent Tools
Qodo Command combines agentic reasoning with a powerful set of execution tools. These tools allow Qodo’s agents to operate more like expert developers—interacting with real environments, scanning large codebases, and thinking in structured steps.
- FileSystem: Standard tools for reading, writing, and editing files and directories. Since even state-of-the-art (SOTA) LLMs may produce errors when using exact matches with the edit file tool, we have implemented a fallback mechanism that allows fuzzy matching to improve the tool’s success rate.
- Shell Tool: executing like a real developer, Qodo agents can interact with the system shell to run build scripts and linters, execute test suites and validate hypotheses in real-time
- Ripgrep: for deep codebase understanding, Qodo Command is natively designed for optimized usage of ripgrep recursive search tool to locate relevant code across large repositories
- Sequential Thinking: structured agent reasoning helped contribute to the benchmark results by breaking down tasks into actionable steps. This shows the importance of interacting with ai coding agents in a step-by-step iteration, and how well structured tickets or PRDs can yield better code results. While this tool is not enabled by default, it can be easily added via MCP to any custom agent with Qodo Command.
- Web Search: this tool has been disabled for SWE-bench run to prevent data leakage in solutions
What Makes Qodo Command Exceptional for Complex Codebases Code Quality
We recently announced Qodo Command and it’s already transforming how we develop software at Qodo. What makes Qodo Command unique is our foundational focus on automation with integrity. Here’s what you can do with Qodo Command:
Code Integrity Automations
Since launch, the Qodo team, our customers and community contributors have been actively building agents using Qodo Command,enabling teams to automate high-impact tasks such as:
- Code review automation
- Test generation
- Documentation generation
And many more agents that enhance code quality, which you can explore in Qodo Command agents repository.
UI Mode for Reviewing Code
Code quality doesn’t stop at generation—it depends on consistent, structured review. That’s why Qodo Command includes a dedicated UI mode with Qodo Merge, our advanced code review agent, built in.
This integration enables developers to generate and review code in a single, streamlined flow. Every AI-assisted task is automatically routed through a review process that checks for correctness, completeness, and quality—helping teams ship faster without lowering standards.
What will you build next?
Qodo Command isn’t built for benchmarks – it’s built for your production environment. The same version that ranked in the global top 5 on SWE-bench Verified is available today with a single command:
npm install -g @qodo/command
Use it to automate your code integrity workflows, accelerate code reviews, and generate tests, docs, and feature code—all while maintaining the quality standards your team depends on. It’s the CLI agent we’ve built for ourselves and continue to improve weekly, in the open. And we’re just getting started. Don’t wait, get started today at Qodo Command https://www.qodo.ai/products/qodo-command/


