Qodo Outperforms Claude in Code Review Benchmark


This blog reflects a collaborative effort by Qodo’s research team to design, build and validate the benchmark and this analysis.
Anthropic launched Code Review for Claude Code, a multi-agent system that dispatches parallel agents to review pull requests, verify findings, and post inline comments on GitHub. It’s a substantial engineering effort, and we wanted to see how it performs on a rigorous, standardized benchmark.
However, according to the Qodo Code Review benchmark (which is being adopted throughout the industry, most recently by NVIDIA in its announcement of Nemotron 3 Super),
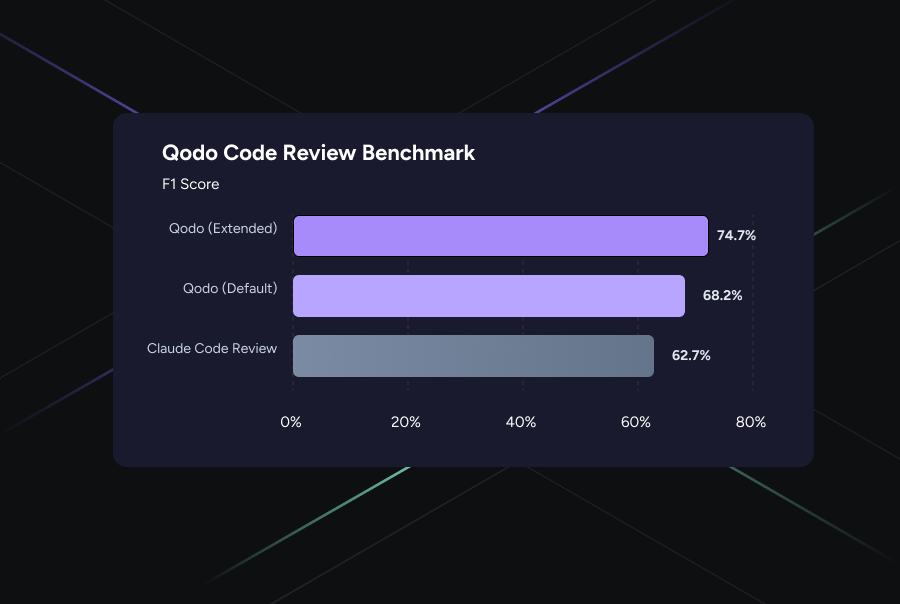
Qodo outperforms Claude by 12 F1 points!
Here’s what we learned:
The Benchmark
Our research paper “Beyond Surface-Level Bugs: Benchmarking AI Code Review on Scale” introduced the Qodo Code Review Benchmark 1.0, a methodology built around injecting realistic defects into genuine, merged pull requests from production-grade open-source repositories.
The benchmark covers 100 PRs with 580 issues across 8 repositories spanning TypeScript, Python, JavaScript, C, C#, Rust, and Swift. Unlike prior benchmarks that backtrack from fix commits and focus narrowly on isolated bugs, our approach evaluates both code correctness and code quality (best-practice and rules enforcement) within full PR review scenarios. The injection-based methodology is repository-agnostic and scalable, as it can be applied to any codebase, open-source or private.
Our initial evaluation covered 8 leading AI code review tools. Qodo led the field across all configurations. With the release of Claude Code Review, we added it as the ninth tool under identical conditions. We also applied this same benchmark to the latest generation of open-source models, such as NVIDIA Nemotron-3 Super, which is rapidly closing the gap with proprietary models.
This benchmark is designed as a living evaluation, rather than static snapshots. Each run reflects the most current iteration of the tools involved. While we prioritize real-time accuracy over static version numbering, these results represent the latest performance parity in the field
Claude Code Review: Setup
We configured Claude Code Review using its default settings, exactly as a new customer would. PRs were opened on the same forked repositories, and AGENTS.md rules generated from the codebase and committed to each repo root. Claude Code Review ran automatically on PR submission, and we collected its inline comments for evaluation against our validated ground truth using the same LLM-as-a-judge system applied to all other tools.
No tuning, no special configuration. Just a fair, head-to-head comparison.
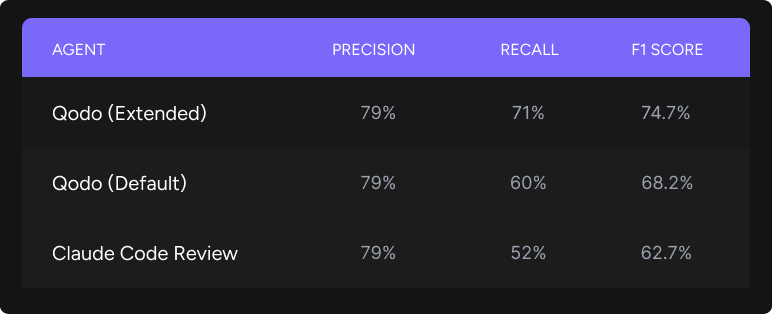
Our evaluation also includes the latest iterations of Qodo. It is important to note that because our system evolves with every run, the absolute numbers for Qodo’s production version (79% recall / 60% precision) have increased since our original report. We are therefore introducing these as the new baseline for this comparison.
To explore the upper limits of AI-assisted review, we tested two distinct Qodo configurations:
- Qodo (Default): The current production version of our system.
- Qodo (Extended): An orchestrated multi-agent layer added on top of the default agents.
While the Extended mode is currently only research results and not yet available in production, they represent a “quality-first” use case. Imagine a highly sensitive PR where a team is willing to invest extra resources to ensure the most exhaustive review possible.
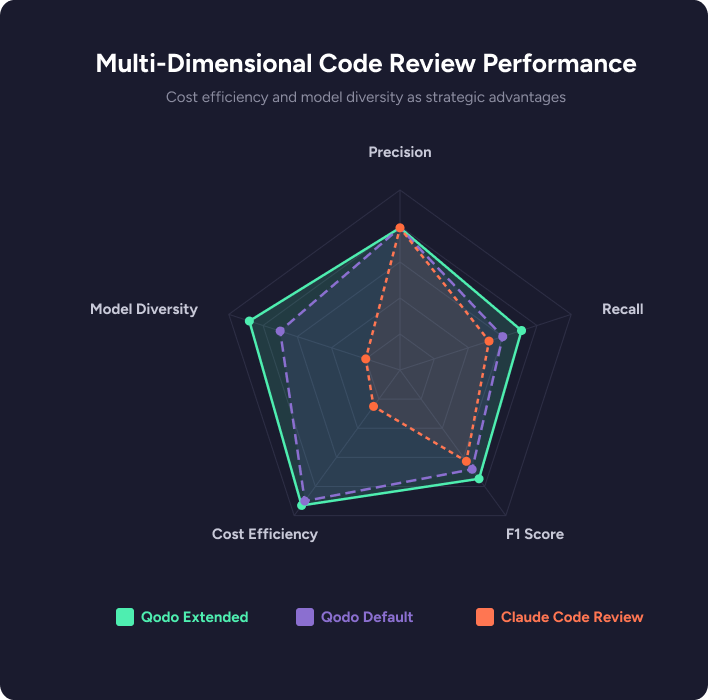
The results are striking: both Qodo configurations and Claude land at identical precision levels. This means the quality of individual findings remains high regardless of the mode. The true differentiation is in recall. Qodo in standard mode already surfaces issues with higher recall than Claude Code Review, but the gap widens substantially when our multi-agent approach orchestrates specialized agents to catch the remaining ground truth.
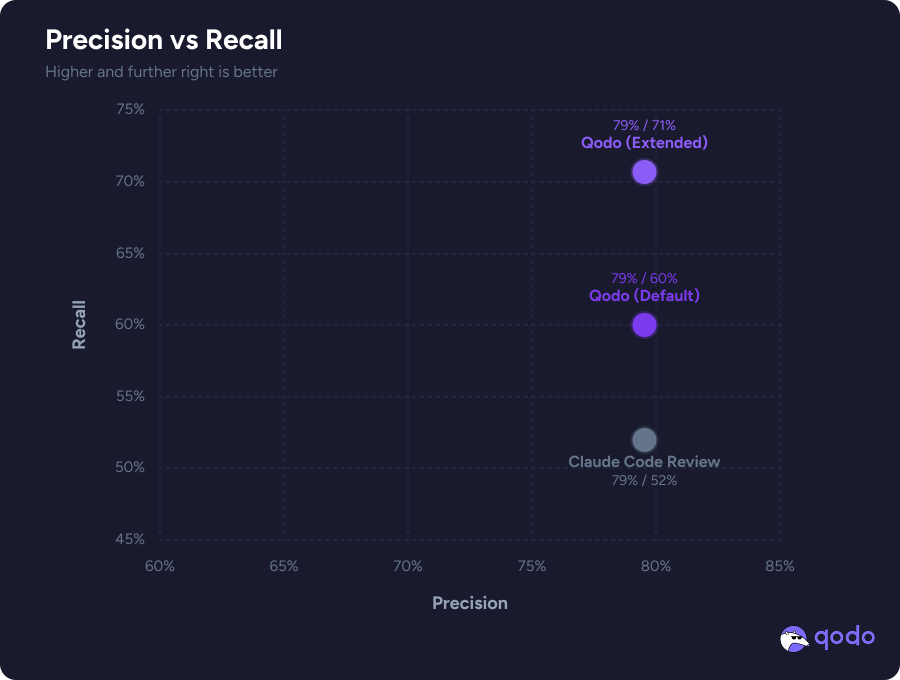
The Orchestrated Multi-Agent Harness
The research configurations shown above represent our latest architectural iteration. Rather than running a single review pass, it dispatches multiple agents,each tuned for different issue categories (logical errors, best-practice violations, edge cases, cross-file dependencies) and merges their outputs through a verification and deduplication step.
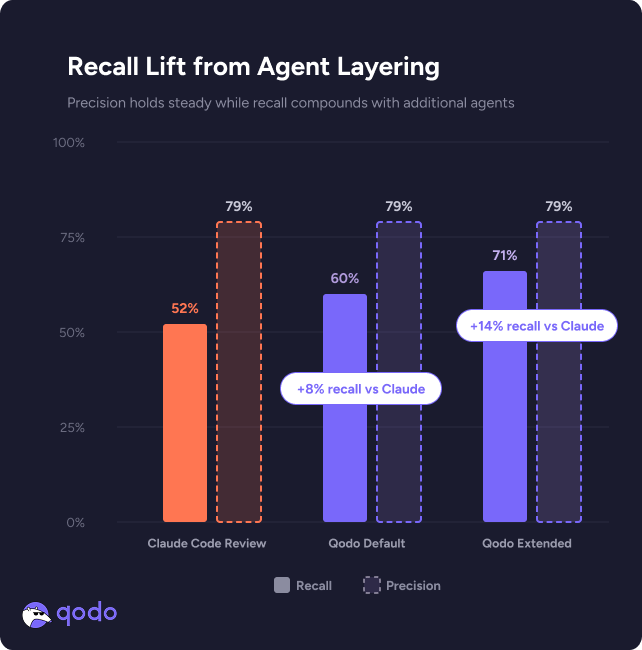
The result is a large recall improvement with no precision degradation. This matters because, as we discussed in our original paper, precision is a dimension that can always be tightened through post-processing and filtering. Recall, however, is an inherently more complex challenge since it depends on the system’s ability to deeply understand the codebase, reason about cross-file interactions, and apply repository-specific standards. You can’t filter your way to finding issues you never detected in the first place.
Finally, true multi-agent orchestration requires model diversity. While Anthropic’s system is restricted entirely to the Claude ecosystem, Qodo dynamically leverages a blend of the industry’s best SOTA models crossing OpenAI, Anthropic, and Google. By refusing vendor lock-in, our harness synthesizes the unique analytical strengths of different model families to achieve a depth of review that a single-provider system cannot reach.
On Cost
Claude Code Review is priced at $15–$25 per review on a token-usage basis. Anthropic positions it as a premium, depth-first product and the engineering behind it reflects that ambition.
That said, the cost profile is worth noting. At literally an order of magnitude less than Anthropic’s pricing, Qodo makes scaling your review process painless. You’re catching more issues and running a much deeper analysis without burning through your budget.
Higher recall at lower per-review cost is a favorable tradeoff for most engineering organizations.
What We Learned
Claude Code Review is a capable system. Its precision is on par with the best tools we have evaluated, and its multi-agent architecture clearly represents a step beyond simpler single-pass reviewers. Anthropic’s internal data on comment rates and acceptance rates aligns with what we observed when it flags something, it’s usually right (e.g. high precision).
The gap is in coverage. In a benchmark designed to test the full spectrum of code review, not just obvious bugs, but subtle best-practice and rules violations, cross-file issues, and architectural concerns, Qodo’s deeper codebase understanding and multi-agent harness approach translate into catching a significantly broader portion of real issues, at a fraction of the per-review cost.
We’ll continue expanding the benchmark as new tools and configurations emerge. The dataset and all evaluated reviews are publicly available for independent verification.
The Qodo Code Review Benchmark 1.0 is publicly available in our benchmark GitHub organization. Read the full research paper: “Beyond Surface-Level Bugs: Benchmarking AI Code Review on Scale.”


