Qodo Ranked #1 AI Code Review Tool in Martian’s Code Review Benchmark
We’re excited to share that Qodo is ranked #1 on Martian’s Code Review Bench, the first independent evaluation for AI code review tools. These latest results build on our earlier milestone where Qodo ranked #1 in finding the toughest bugs, and #2 overall on Martian’s offline benchmark.
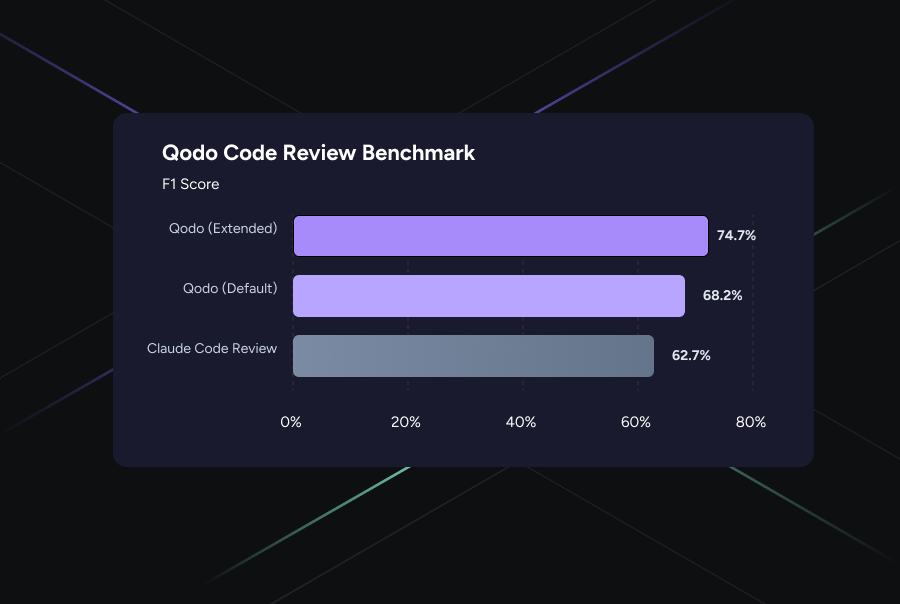
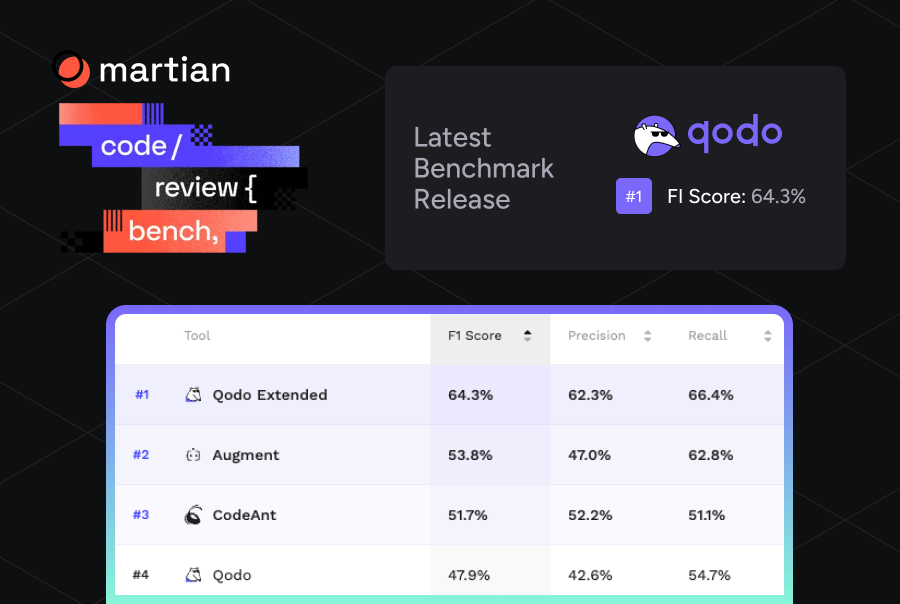
The ranking is based on the benchmark’s F1 score, which measures how effectively a system balances precision and recall when identifying real issues inside pull requests. With an F1 score of 64.3%, Qodo surpasses other AI code review tools, ahead of the next leading tool by +10.5%.
An Independent Benchmark for AI Code Review
We wrote in our first post about this benchmark that these evaluations are not static. They evolve as datasets expand, methods improve, tools continue to develop and new ones are introduced. The Martian Code Review Benchmark reflects that dynamic with results representing a snapshot in time rather than a fixed ranking.
In the latest results, Qodo now ranks #1 overall.
As seen in the benchmark, we evaluated two distinct configurations of Qodo’s code review platform:
- Qodo Extended achieved 64.3% F1 score. Currently in research preview, this is our orchestrated multi-agent layer. Rather than a single-pass review, it dispatches specialized agents, each tuned for specific categories like logical edge cases, security, and cross-file dependencies, and then merges their findings through a rigorous verification step.
- Qodo (Standard) ranks #4 with a 47.9% F1 score. This is our current production version. It is already a leader in the field, providing high-precision reviews that focus on actionable code quality.
The F1 score captures a balanced view of performance by combining precision and recall into a single metric. Ranking highest in F1 indicates that a system both identifies real issues reliably and avoids overwhelming developers with incorrect suggestions.
The results show that while both versions maintain high precision, Qodo’s Extended mode provides a massive recall boost.
Qodo’s performance reflects its ability to consistently surface meaningful problems in pull requests while maintaining feedback that developers find accurate and actionable.
These often include issues such as:
- subtle logic errors
- edge case failures
- cross-file inconsistencies
- architectural violations within repositories
Catching these issues early in the review process helps teams reduce debugging time, prevent regressions, and maintain higher overall code quality across their codebases.
Why This Matters for Engineering Teams
Most tools struggle with a recall-precision trade-off: if you try to find more bugs, you usually drown the developer in noise. In a production engineering environment, this trade-off isn’t just a statistical hurdle, it is a direct tax on developer velocity and morale.
Maintaining signal at scale
We believe the best AI reviewer is the one that only speaks when it has something valuable to say. By maintaining a 62.3% precision rate even at high volume, Qodo ensures that every comment is high-signal. This shift is critical: it moves the AI from being a source of noise to a trusted collaborator.
A Safety Net for “Expensive” Bugs
Low recall typically means an AI is only catching the low-hanging fruit, like syntax errors or style violations that a simple linter could find. This leaves the expensive issues like logic regressions, security flaws, and architectural mismatches, entirely on the shoulders of senior engineers. With an industry-leading 66.4% recall, Qodo acts as a critical review pass. It identifies the complex, cross-file issues that typically require hours of manual investigation, allowing your team to focus on high-level design instead of hunting for edge cases.
Shipping with confidence
Qodo’s +10.5% lead in F1 score isn’t just a metric for a leaderboard. It translates directly to a more stable development cycle. In most workflows, code review is a primary bottleneck. If the automated layer is unreliable, it either adds extra work for the developer (who has to debunk incorrect comments) or extra anxiety for the reviewer (who fears the tool missed a critical flaw).
When a system successfully balances thoroughness with accuracy, the feedback loop actually closes. Developers can address valid issues before the human review even begins, and reviewers can approach the PR with the confidence that the “structural” heavy lifting has already been done.
Try It Yourself
Benchmarks are one input. The best way to evaluate a code review tool is to run it on your own codebase, with your own PRs, against your own standards.
→ See the full benchmark results → Try Qodo