Qodo’s Default Reviewers: Why We Picked GPT-5.2, Gemini 2.5 Pro, and Claude Haiku 4.5

Qodo’s goal for pull request (PR) review is clear: catch real bugs, suggest safe patches, and stay close to how developers work in Git. To do this well, we need models that perform on real pull requests across real stacks.
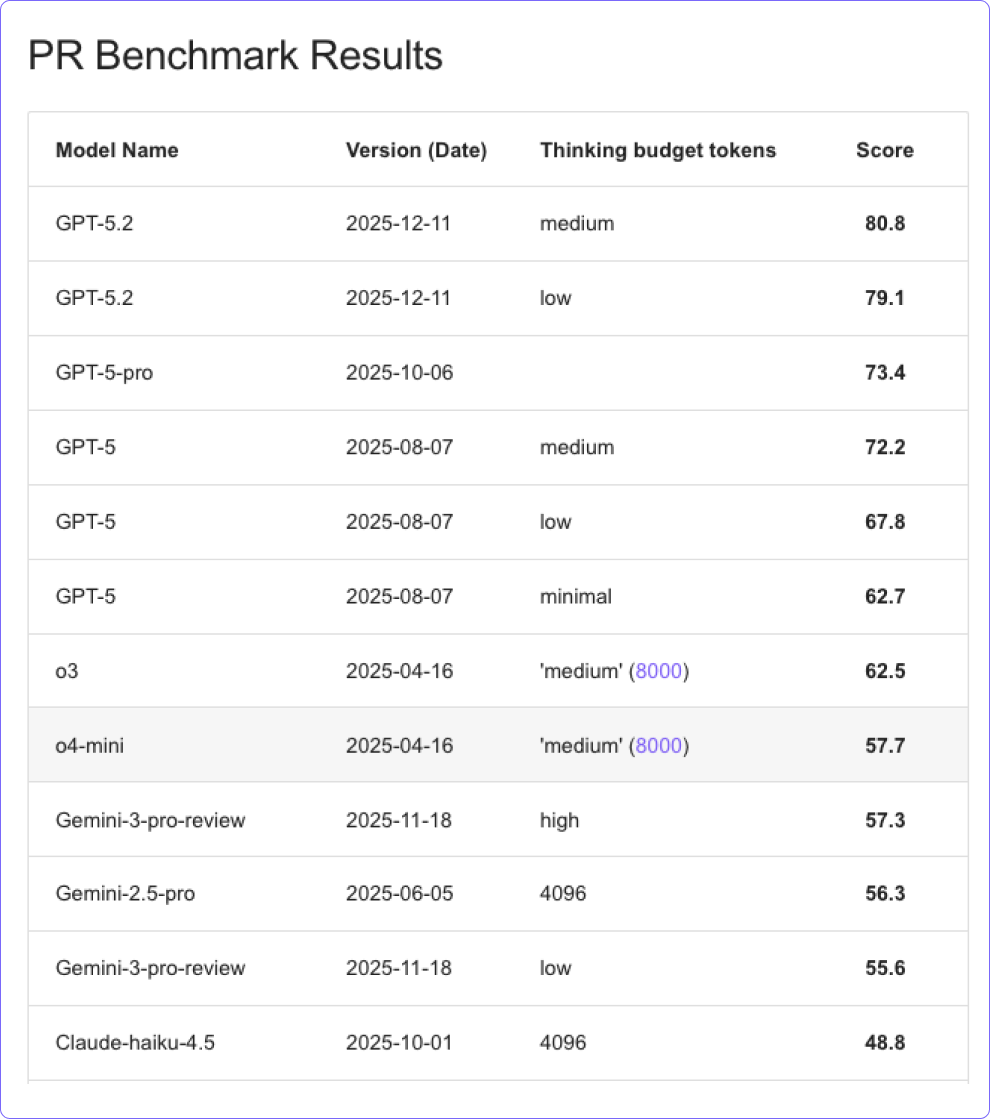
As new and more powerful models arrive, Qodo evaluates each one against our PR Benchmark[ref]. The benchmark is built from real-world PRs across many stacks. It measures how well a model spots critical issues, produces correct and minimal fixes and follows the rules that make automated reviews useful. With it, Qodo can select models that behave reliably on real code and give developers feedback they can trust. Models that perform best on this benchmark become Qodo’s default reviewers.
Based on our latest results, GPT-5.2, Gemini 2.5 Pro and Claude Haiku 4.5 are now the default model options for PR review in Qodo.
How the benchmark works
Qodo’s PR Benchmark runs each model across 400 real PRs from more than 100 repositories. The dataset covers 14 coding languages, plus common non-code files such as YAML, JSON and Dockerfiles.
For each PR we generate suggestions from each model and ask a strong judge model (OpenAI o3) to rank them. The score reflects how often a model finds critical issues, proposes valid patches and follows rules such as touching only added lines.
GPT-5.2: New quality bar for deep reviews
Key traits:
- Finds several high impact bugs in the same PR
- Produces focused patches that compile
- Explains why issues matter and stays within guidelines
GPT-5.2 sets a new benchmark record with a score of 80.8. It is the most capable model we have tested for PR review and consistently delivers deep, context-aware analysis. In many cases it identifies multiple high-impact bugs in a single diff and proposes minimal patches that compile and stay within the rules. Its explanations are direct and prioritise real failures over cosmetic concerns, which keeps reviews focused on issues that break builds or cause runtime errors.
GPT-5.2 also handles a wide range of languages and file types with strong consistency. Whether the diff contains backend logic, tests, configuration, build files or scripts, it often delivers clear guidance and practical patches. This broad coverage is a major reason it outperforms every other model in the benchmark.
There are tradeoffs. GPT-5.2 still misses critical defects in some reviews, especially when a single issue is buried among smaller changes. It also shows occasional slips such as adding speculative edits, touching unchanged lines or proposing code that does not compile. These cases are not common but remind us that even the best models need guardrails.
Overall, GPT-5.2 is the strongest reviewer available today. It offers the best mix of depth, accuracy and actionable output, which is why it is one of Qodo’s primary default options for teams that want the highest level of code review quality.
Gemini 2.5 Pro: Stable fixes and strong format reliability
Key traits:
- Writes short, clear explanations that stay focused on the changed lines
- Spots the most obvious defect in a diff with good accuracy
- Low rate of harmful fixes
- Best suited for stable, everyday reviews where consistency and low risk matter
Gemini 2.5 Pro scored 56.3 in our benchmark and stands out for its consistency. It follows format rules closely, produces clean before-and-after snippets and keeps explanations short and easy to read. For teams that rely on automated checks or CI pipelines, this level of structure matters. Responses are predictable, well formed and easy to process.
One of Gemini 2.5 Pro’s strengths is spotting the most obvious defect in the diff, such as a compile issue, a missing guard or a wrong constant. When it identifies a problem, the proposed patch is usually correct, minimal and safe to apply. It also has a low rate of harmful suggestions, which makes it a dependable reviewer for routine PRs where stability and clarity are more important than broad coverage.
The tradeoff is depth. Gemini 2.5 Pro often stops after addressing the first issue it finds. It may miss additional defects that appear later in the diff or in more complex files such as build scripts or test code. It also shows occasional rule slips, like touching unchanged lines or suggesting cosmetic edits, which can affect its ranking.
Even with these limits, Gemini 2.5 Pro offers strong value. It is stable, concise and dependable, making it a solid default option for general-purpose PR review where clarity and low risk matter as much as coverage.
This makes Gemini 2.5 Pro a solid choice when you want predictable, well structured suggestions at a lower cost than top-tier models.
Why not Gemini 3?
- It is still in preview mode
Preview model versions continuously update, leading to unstable behavior across runs. This makes them risky for workflows that depend on consistent structure, correct formatting, and predictable fixes. - It has very long latency
The current response latency and reliability fall short of production-grade performance standards for PR reviews. This is expected to improve once the model leaves preview, but today it creates friction for developers waiting on automated checks.
Once Gemini 3 Pro becomes stable and its latency improves, Qodo will benchmark it again and revisit its role in the default setup.
Claude Haiku 4.5: High precision and cost-efficient reviews
Key traits:
- Finds real, high-impact bugs with strong precision
- Produces short, easy-to-apply patches scoped to new lines
- Works across many languages and file types with steady accuracy
- Fast, cost-efficient and low noise, making it useful for high-volume PRs
Claude Haiku 4.5 scored 48.8 in our benchmark. While it does not match the depth of GPT-5.2 or the broader coverage of Gemini 2.5 Pro, it brings an important strength: precision. When Haiku raises an issue, it is usually real and high impact. Its suggestions are short, easy to apply and limited to the new lines in the diff, which keeps reviews focused and avoids unnecessary churn.
Haiku also handles a wide range of languages and file types, including backend logic, build files, tests, configuration and documentation. This makes it a reliable option for large, mixed PRs where developers want quick, clear patches without noise.
The tradeoff is coverage. Haiku often flags only one or two issues and may miss other critical bugs that stronger models find. It also shows occasional misreads or incomplete responses, which limits its usefulness on complex diffs.
Even with these limits, Haiku’s speed, cost and low rate of false positives make it a practical default choice for high-volume repositories or teams who prefer precise, minimal suggestions over exhaustive analysis.
Why we picked three defaults, not one
Code review is a multifaceted process requiring specialized capabilities at different stages. Qodo’s layered model architecture addresses this complexity by deploying purpose-built models where they deliver maximum value.
The architecture consists of three strategic components:
(1) GPT-5.2 functions as the flagship model, handling computationally intensive analysis and complex reasoning tasks.
(2) Gemini 2.5 Pro serves as the primary reviewer. GPT-5.2 excels at depth but exhibits aggressive tendencies, while Gemini 2.5 provides predictable, robust performance. This complementary pairing ensures consistent, production-grade code reviews.
(3) Claude Haiku 4.5 manages routine tasks efficiently. Deploying heavyweight models for these operations introduces unnecessary latency and often degrades output quality through overthinking.
This multi-model strategy enables dynamic task-model alignment, optimizing both review quality and system performance while eliminating the constraints of monolithic, undifferentiated review processes.


