Unleashing System 2 Thinking? AlphaCodium Outperforms Direct Prompting of OpenAI o1
The release of OpenAI’s o1 model brought with it a flood of discussion about its new capabilities. OpenAI’s President Greg Brockman aptly framed the conversation by describing previous models as exhibiting “System I thinking,” where quick, instinctive responses dominate, while the promise of o1’s “chains of thought” might unlock “System II thinking” – more deliberate, reasoned processes.

In this context, we wanted to put these claims to the test. Our tool, AlphaCodium, already shines in boosting performance for various foundational models in solving competition coding problems, and we thought – why not take OpenAI’s latest and apply our methodology? We were especially curious about how well o1 could perform when utilized within the broader framework that AlphaCodium provides.
What is AlphaCodium?
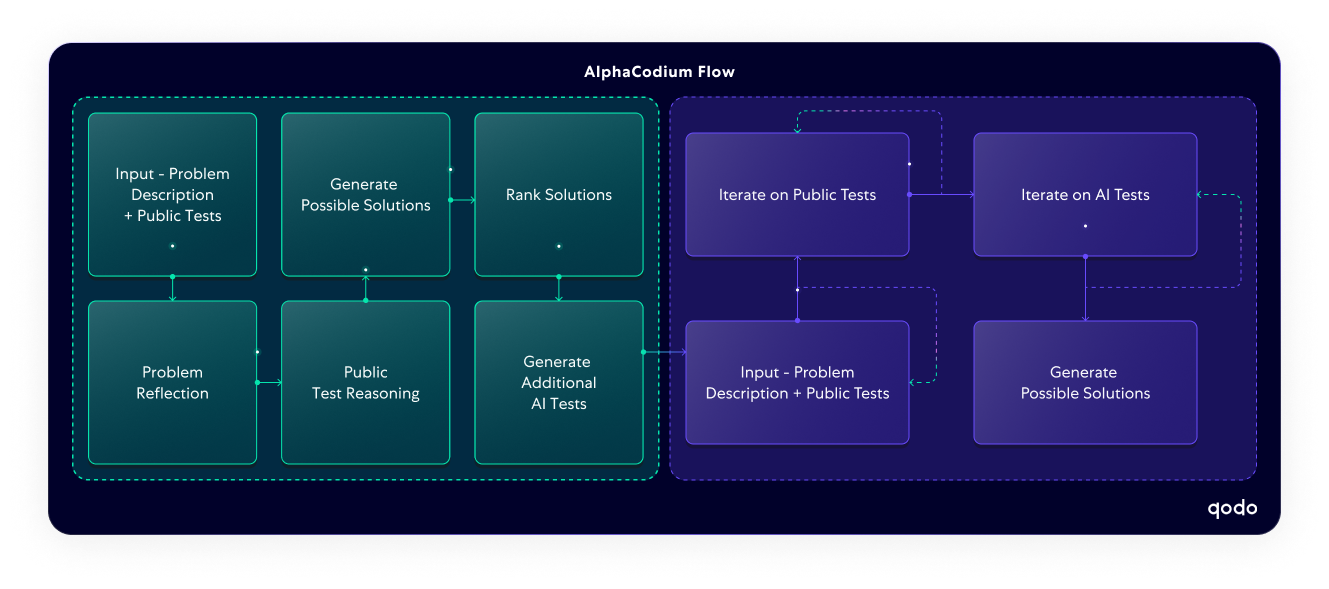
AlphaCodium, developed and open-sourced by Qodo’s research team, represents a novel approach to code generation with LLMs. Unlike traditional one-shot code generation methods, AlphaCodium employs a code-oriented, multi-stage flow that emphasizes continuous improvement through iteration. This two-phase iterative process involves generating code, running it, testing it, and fixing any issues, ensuring the system arrives at a fully validated solution. With GPT-4, AlphaCodium increased accuracy of solving coding problems from 19% to 44%. This was a significant improvement over the previous best approach, Google DeepMind’s AlphaCode.
Two key elements distinguish AlphaCodium’s flow. First, the system generates additional data to aid in the iterative process, such as problem reflections and test reasoning, which help the model better understand and refine its approach to solving complex problems. Second, AlphaCodium enriches the existing public test cases with AI-generated tests, introducing additional layers of scrutiny to validate the robustness of the solutions. With this structured process, AlphaCodium focuses not just on the code itself but on the reasoning and testing necessary to ensure a high-quality, reliable output.
AlphaCodium: Paper, Code, Blog.
We wondered – if o1 already exhibits System 2 thinking, would inserting it inside AlphaCodium improve or actually deteriorate its results?
System thinking: a framework for AI decision-making
As a point of comparison, let’s think about System I and II thinking. Nobel laureate Daniel Kahneman referred to these distinct modes of human thought that govern decision-making and problem-solving, and they provide a useful framework to understand the evolutions of LLMs and their role in problem-solving.
System 1: fast responses with surface-level understanding
System 1 thinking corresponds to a person giving a fast, instinctive response. In the context of AI, this is analogous to models that quickly produce vast amounts of data to produce near-instant outputs. Most current LLMs operate in this mode, generating code by recognizing patterns in the training data, often relying on heuristics similar to how human intuition works. This approach allows for the rapid production of code snippets or solutions to common programming problems.
While this speed is advantageous, System 1-style models can be prone to errors in more complex or unfamiliar coding challenges. They tend to focus on surface-level patterns and may not fully understand the deeper logic required for sophisticated tasks. As a result, generated code might appear correct but fail under edge cases or when subjected to rigorous testing. For instance, such models may miss underlying dependencies, fail to handle intricate data structures, or generate syntactically correct code that lacks semantic correctness.
System 2: deliberate problem solving
System 2 thinking represents the next step in AI for coding—moving from fast, instinct-driven responses to more deliberate, methodical and reasoned processes. This shift is critical for addressing complex coding challenges that require deep understanding and logic. In a System 2 framework, LLMs focus on careful analysis, reasoning and reflection before arriving at a solution. Unlike the speed-oriented, heuristic-driven nature of System 1, System 2 is designed to engage in an analytical process, ensuring that the final output is not only syntactically correct but also logically sound, semantically meaningful, and efficient under a variety of conditions.
For example, imagine a developer working on a task like building a REST API that handles complex database transactions. A System II AI would deconstruct the problem by analyzing different components of the task, reason through various decisions, and simulate potential solutions. Throughout this process, the model would iteratively refine its code by responding to feedback from tests—analyzing scenarios where deadlocks might occur, performance bottlenecks arise, or race conditions affect data integrity, and would even ask for more data or integration if it realizes they are necessary.
Narrowing the gap with OpenAI o1
After benchmarking OpenAI’s o1, we found it to be more of what I’d call “System 1.5.”—a middle ground where the AI demonstrates some reasoning capabilities beyond pure intuition, but still lacks the full depth and deliberation of multi-step problem-solving seen in System 2 thinking.
To this extent, we can define the levels of system thinking as:
System 1 – quick inference
System 1.5 – guided chain-of-thought
System 2 – deep, deliberate reasoning reinforced by information arriving from validation processes, using relevant thinking frameworks and tools, including devising and choosing between options
“The best we can do is a compromise: learn to recognize situations in which mistakes are likely and try harder to avoid significant mistakes when the stakes are high.” ― Daniel Kahneman, Thinking, Fast and Slow
Terence Tao, winner of the Fields Medal and widely considered to be the world’s greatest living mathematician, conducted an evaluation of o1 that offers a useful comparison. Tao describes o1 as a “mediocre graduate student” capable of solving complex problems, but only with significant prompting and guidance, and noted that it “did not generate the key conceptual ideas on its own”. This aligns with the definition of System 1.5 AI as requiring external direction to navigate complex tasks.
While o1 can handle well-structured problems, it does struggle with deeper reasoning, falling short of System 2 thinking, where models operate independently with multi-step problem-solving and validation. Tao suggests that with further improvements and tool integrations, AI models could eventually reach the competence of a “competent graduate student”—aligning with our belief that these models are inching closer to System 2 but aren’t quite there yet.

See Tao’s full experiment: https://mathstodon.xyz/@tao/113132503432772494
This limitation is tied to one of the more prominent issues with o1. By now, the internet is full of cases where o1 exhibits extreme hallucinations (although to be fair, people also “hallucinate”, even when applying System 2 thinking). While o1 can generate plausible-looking code, it can also produce incorrect or nonsensical outputs when pushed beyond its reasoning capacity. Because o1 doesn’t fully reason through problems, it may generate flawed solutions—particularly when reasoning through complex problems.

AlphaCodium + o1: An Incremental Step Towards System II?
Our experiment with AlphaCodium used o1 as its internal model, specifically in the context of the Codeforces benchmark, also known as CodeContests. AlphaCodium acts as the strategy provider, designing the approach, setting up a framework, and providing the tooling to fuel and guide o1’s chain of thought, while o1 executes meaningful portions of the inner reasoning and processes.
The results were striking – a clear improvement in accuracy, demonstrating that AlphaCodium elevates o1’s performance significantly. As seen in the charts below, accuracy rates showed consistent improvement when AlphaCodium was paired with o1 compared to direct prompts alone.
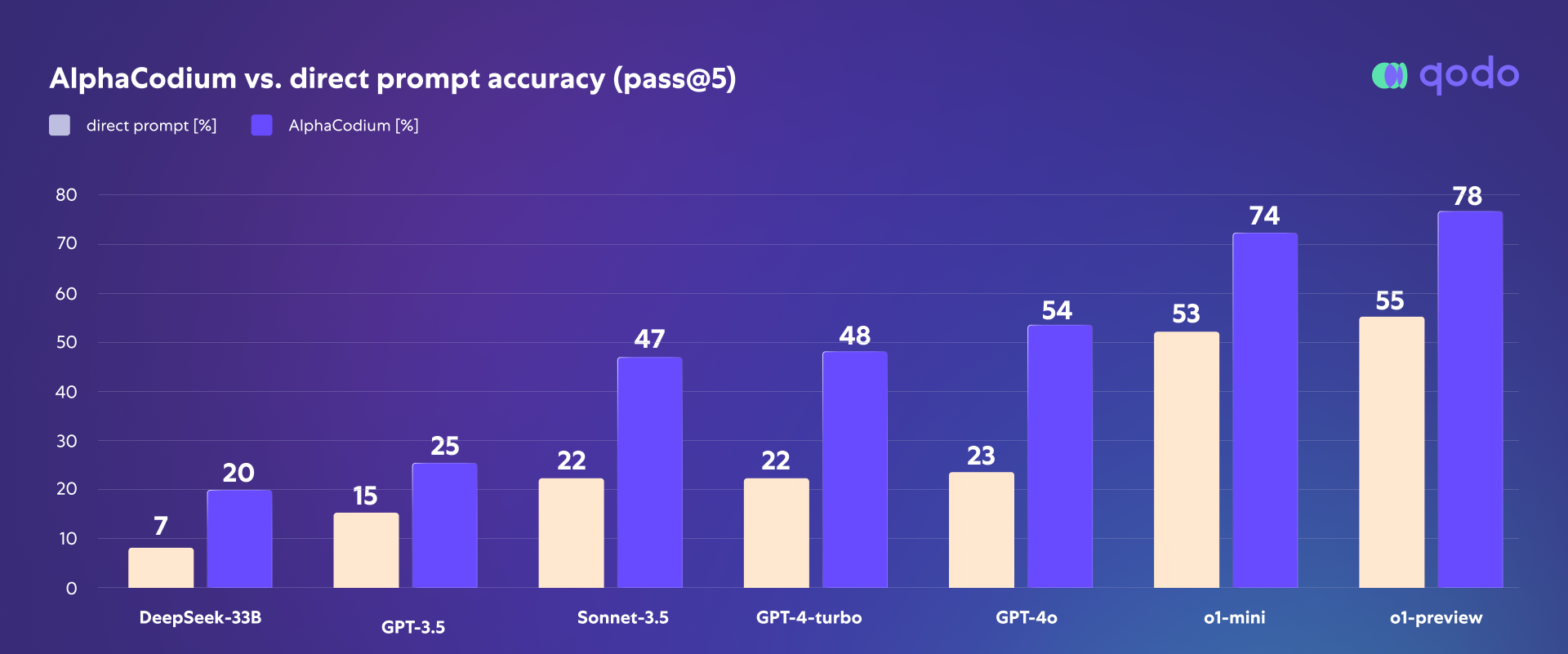
According to our understanding of the OpenAI report, AlphaCodium-o1 achieves better results compared to o1 (which we didn’t have access to—we used o1-mini and o1-preview) and even o1-ioi (!), a model that was further trained specifically for programming skills, which makes it the state-of-the-art solution for this coding benchmark.
The performance boost
In our analysis, the impact of utilizing AlphaCodium’s methodology with the o1 model showed a substantial improvement in pass@5 accuracy on the Codeforces benchmark. This improvement was both significant and consistent across multiple models evaluated. While the standalone o1 model does deliver performance beyond simple inference (System 1), we claim it is comparable to guided chain of thought (System 1.5).
It’s also worth noting that o1 was trained with reinforcement learning in order to become better at chain-of-thought. Recent works like RLEF (Gehring@meta et al., 2024) provide an interesting comparison to AlphaCodium-o1. RLEF uses reinforcement learning with execution feedback to enhance the performance of code generation models, achieving state-of-the-art (prior to the results of the update we share in this blog). RLEF aligns well with our hypothesis that reinforcement learning can help boost intuitive thinking (System 1.5), but isn’t yet close to a System II thinking. Even with advantages highlighted by RL/RLEF, our experiment with o1 shows that AlphaCodium’s framework, when combined with strong models like o1, can still provide a meaningful performance boost.
 Pairing it with AlphaCodium pushed o1 towards more strategic and deliberate problem-solving. The results suggest that models like o1, when scaffolded with the right tooling and guided by a strong framework to provide reasoning strategy can reach a level beyond mere instinctive responses. This combination allows the model to operate in a more thoughtful, iterative way, moving closer to the kind of System 2 deeper reasoning required for more complex coding tasks.
Pairing it with AlphaCodium pushed o1 towards more strategic and deliberate problem-solving. The results suggest that models like o1, when scaffolded with the right tooling and guided by a strong framework to provide reasoning strategy can reach a level beyond mere instinctive responses. This combination allows the model to operate in a more thoughtful, iterative way, moving closer to the kind of System 2 deeper reasoning required for more complex coding tasks.
Why we chose Codeforces
We chose Codeforces for our benchmarking because it presents algorithmically rigorous and challenging problems, which are crucial for evaluating a model’s ability to handle complex, multi-step reasoning. Codeforces pushes models beyond simple real-world coding tasks, requiring advanced problem-solving skills that align with System 2 thinking, making it more ideal for testing the depth of reasoning capabilities of AI models.
However, we noticed that more teams compete on SWE-bench than Codeforces, which raised an interesting question: Is it because competing against established teams like OpenAI, DeepMind, Salesforce, and Meta is perceived as more challenging? (These are the teams I know of that have competed on Codeforces.)
We think that it is because:
(1) SWE-Bench started with more attainable benchmarks that attracted a broader pool of participants. That said, since August 2024, we’ve noticed that there haven’t been any new submissions on SWE-Bench, which might indicate that it has now reached a similarly high bar in terms of results.
(2) SWE-bench framework is structured as an “issue” on GitHub that needs to be solved, mimicking real-world coding. This setup may appeal to a wider range of teams because it feels more practical and closely mirrors everyday coding challenges, rather than the purely competitive, algorithm-focused nature of Codeforces.
A New Open-Source Tool for the Community
We believe these findings are important for the broader AI research community. That’s why we made AlphaCodium open-source. Anyone interested can find our work on GitHub here and explore our detailed methodology in the paper on arXiv.
Where Do We Go From Here?
The promise of AlphaCodium is clear: with the right strategic flow-engineering, foundational models like o1 can be nudged toward System II thinking. We still have work to do to cross the gap from “System 1.5” to a true System 2-level AI, but when observing tools like AlphaCodium, we can better understand the gap and keep researching to get closer.
The future of AI is in collaboration, and we’re eager to see what we can all build together as we continue to innovate. If you’re interested in reaching these results for yourself, check out the README on GitHub.
At Qodo, we focus on code integrity — that is, within the context of this post, we are building toward System 2 thinking that will integrally incorporate code testing and review capabilities and flows, among other methods, to ensure that generated code and software work as developers intended and in accordance with best practices.
Final Notes
Kudos to Tal, the main author of the AlphaCodium work. You can find his original blog here.
To dive deeper into our benchmarking results and explore how AlphaCodium enhances AI performance in complex coding tasks, join our upcoming webinar: Testing the Limits: Code Integrity and AI Performance. We’ll take you through our methodology, showcase AlphaCodium in action, and discuss the future of AI in software development.
Register here: https://www.qodo.ai/webinar/testing-the-limits/