7 AI Code Refactoring Tools for Enterprises
TL;DR
- Enterprise codebases accumulate technical debt as part of their infrastructure, not as bugs to fix but as constraints to manage. Manual refactoring at that scale isn’t sustainable, which is why AI code generators are redefining how large organizations maintain code integrity.
- Tools like Qodo, Augment, Gemini, Copilot, Cursor, Codex, and Zencoder each solve different layers of the problem, from developer productivity to governance and large-scale modernization.
- For regulated or complex environments, Qodo stands out with its context-aware, multi-agent design and compliance-grade automation. Others like Copilot and Cursor shine in daily workflows, while Zencoder and Codex enable verified, multi-file, or custom pipeline refactors.
- The takeaway: AI isn’t replacing engineers, it’s taking over the repetitive, high-risk parts of refactoring so teams can keep massive systems evolving safely and continuously.
In any enterprise codebase that’s been through years of releases, people, and product pivots, technical debt isn’t a side effect; it’s infrastructure. You inherit it with every sprint: duplicated logic, outdated frameworks, tangled dependencies, and legacy APIs still serving critical workloads. These systems keep the business running, but they also trap velocity. Every small change risks breaking something no one fully owns anymore.
Refactoring is the only way to restore confidence in that kind of environment. It’s not about rewriting everything; it’s about making large, complex systems predictable again, where engineers can ship safely without fearing regressions or ripple effects across hundreds of services. But refactoring manually at enterprise scale is a non-starter. You’re looking at millions of lines across multiple languages, compliance gates, and CI/CD pipelines that can’t afford downtime.
That’s where AI is starting to alter the fundamentals. As This Week in Startups noted recently in their Twitter post, “AI is writing 30%+ of enterprise code, and it’s just getting started.” Google reportedly attributes about 30% of its codebase to AI generation, Microsoft around 20–30%, and Cursor claims to process roughly a billion lines of accepted AI-generated code per day. The takeaway isn’t that AI is replacing developers; it’s that it’s starting to handle the repetitive structural work that engineers used to grind through manually.
Refactoring is a natural extension of that shift. When AI understands the context of a system, dependencies, test coverage, and architecture, it can automate large-scale transformations safely. Instead of freezing a team for a “refactor sprint,” enterprises can now move toward continuous, verifiable code improvement built into their normal delivery flow.
This piece compares seven tools that are purpose-built for enterprise use, enabling integration with existing workflows, governance requirements, and CI/CD pipelines. Each one approaches refactoring differently, but all aim for the same goal: restoring code integrity at scale without halting delivery.
Evaluation Criteria for Code Refactoring in Enterprises
Refactoring tools look impressive in demos, until you try them on a 10-million-line monorepo with mixed tech stacks, legacy code, and strict compliance rules. At that scale, the difference between a useful AI tool and an expensive experiment comes down to how it handles enterprise realities. Here’s how to evaluate them.
1. Codebase Scale
Enterprise codebases aren’t just large; they’re uneven. You might have a Java backend from 2013, a React frontend from 2019, and a few Go microservices spun up last year, all sharing data contracts and CI/CD pipelines. A serious refactoring tool must operate across that heterogeneity. It should parse, reason, and apply consistent patterns across multiple languages and repositories, without losing architectural integrity.
Tools built for individual developers often choke on large diffs or lose context across modules. Enterprise-grade tools handle scale with indexing strategies, distributed processing, and incremental refactor passes that respect dependency graphs instead of brute-forcing text replacements.
2. Workflow Integration
In an enterprise, code doesn’t live in an IDE; it lives in pull requests, pipelines, and deployment gates. The right refactoring system integrates directly with those flows: IDE plugins for developer convenience, Git or PR review hooks for validation, and CI/CD integration for automated enforcement. The key is reducing friction; the tool should assist without forcing a workflow change. A refactor that bypasses review or breaks build parity is a nonstarter in a governed environment.
3. Context Awareness
Blind refactoring is worse than no refactoring. A capable system understands architectural context, not just syntax trees. It should detect coupling, dependency chains, and usage frequency to avoid over-optimization or breaking shared utilities. Context awareness means the AI doesn’t just “rename methods” but understands why that method exists, how it’s used, and what ripple effect a change might cause. This is what separates one-off AI suggestions from system-aware transformations.
4. Security & Compliance
Refactoring doesn’t exempt an organization from its security posture. For many enterprises, AI tooling must run in controlled environments, ideally on-prem or in a private cloud. SOC 2 compliance, audit logs, and GDPR adherence aren’t checkboxes; they’re preconditions for procurement. Every tool on this list is evaluated for deployment flexibility, from SaaS to air-gapped setups, because compliance teams will block anything that exposes internal IP or telemetry to third-party servers.
5. Testing & Validation
Automated refactoring is useless if it breaks behavior. The right tool should run or generate tests to confirm functional equivalence post-change, ideally with automated code review and integrated test generation. This includes unit and integration coverage tracking, test scaffolding, and diff-based assertions to ensure no silent regressions. Tools that integrate test generation into their pipelines shorten the validation loop dramatically, turning what used to be weeks of QA cycles into hours of automated checks.
6. Collaboration & Governance
Refactoring at enterprise scale involves distributed teams and multiple approval layers. A useful tool supports collaboration, surfacing changes in PRs, tracking who approved what, and enforcing consistency via policies or linting rules. Governance features matter as much as intelligence: versioned change logs, code health dashboards, and rule-based enforcement help maintain alignment across hundreds of contributors.
AI Refactoring Tools: Detailed Profiles
1. Qodo
Qodo positions itself not as a coding assistant but as an AI-driven code integrity platform, designed for teams managing multi-million-line repositories with strict compliance and governance requirements. Its strength lies in a multi-agent architecture: each agent operates at a different layer of the workflow, IDE, pull request, and testing, which allows it to manage refactoring continuously and contextually.
Key Features
- Qodo Gen (IDE agent): Provides local refactoring and context-aware code transformations directly inside IDEs like VS Code and JetBrains. It doesn’t just rewrite code; it understands dependencies, usage graphs, and naming conventions specific to the organization.
- Qodo Merge (PR review): Evaluates pull requests for code integrity, architectural consistency, and adherence to code review best practices. It can automatically block merges if the refactor violates dependency rules or test coverage thresholds.
- Qodo Cover (test generation & validation): Generates and runs unit and integration tests for refactored code, ensuring functional equivalence before and after a change. This closes the loop between refactor and validation, something most tools leave to QA.
- Enterprise security and deployment: Offers SOC 2 compliance, on-prem and air-gapped deployment options, and full audit logging for traceability.
- Retrieval-augmented context indexing: Qodo builds an internal semantic index of the codebase, allowing AI agents to make contextually correct edits even across large monorepos and polyglot stacks.
Installation
Qodo integrates across development environments:
- IDE plugins (VS Code, JetBrains) for local development.
- CI/CD hooks through Qodo Merge, enabling automated enforcement during pull requests.
- Terminal CLI (npm) for batch operations or integration into scripting workflows.
Use Cases
- Refactoring legacy services at scale without destabilizing core systems.
- Automated PR review and merge validation, catching regressions before integration.
- Standard enforcement across teams through codified architectural rules.
- Test generation as part of modernization or migration projects.
Hands-on Example: Modularizing a Terraform GCP Compliance Pipeline with Qodo
In one of our internal compliance validation pipelines for Google Cloud Platform (GCP), we use Terraform to provision resources and Open Policy Agent (OPA) to enforce configuration rules. The repository looks like this:
├── .github/workflows/ │ └── terraform.yml # GitHub Actions workflow ├── policy/ │ └── storagepolicy.rego # OPA policy for GCS buckets ├── main.tf # Terraform main configuration ├── variables.tf # Terraform variables ├── terraform.tfvars.example # Example variables file └── README.md
The pipeline provisions a Google Cloud Storage bucket, validates its configuration against OPA policies, and blocks non-compliant deployments, for example, enforcing uniform_bucket_level_access = true.
To refactor this setup, I prompted Qodo’s IDE agent to modularize the Terraform configuration:
@gcp-compliance-validation Refactor the current main.tf by extracting the Google Cloud Storage bucket definition into a reusable Terraform module under modules/storage_bucket.
Qodo started by:
- Analyzing the existing Terraform files (main.tf, variables.tf, and terraform.tfvars.example).
- Extracted the google_storage_bucket resource into a new module under modules/storage_bucket.
- Created supporting files:
- main.tf: copied the resource exactly, including all comments.
- variables.tf: defined bucket_name, region, and environment inputs.
- outputs.tf: exposed bucket_url and bucket_name outputs.
- Updated the root main.tf to call the module instead of defining the resource inline, keeping the provider and Terraform settings untouched.
- Preserved functional behavior entirely, including the intentionally non-compliant uniform_bucket_level_access = false, ensuring the OPA policy still triggers correctly in CI/CD validation.
The resulting diff looked like this:
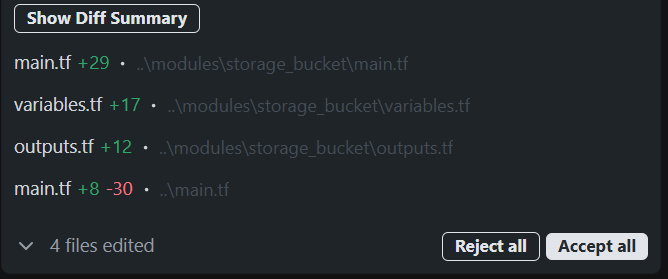
This change turned a simple Terraform setup into a modular, reusable configuration without introducing any behavioral drift, which would have been a tedious task for an engineer to manually write .tf files. Qodo performed it automatically while maintaining auditability and test validation through its PR integration.
Pros
- Deep context awareness across files and services.
- Multi-agent setup covering IDE, PR, and test layers.
- Enterprise-grade governance (SOC 2, audit logs, on-prem deployment).
Cons
- Requires a heavier initial setup compared to lightweight AI IDE assistants.
- Best suited for organizations that already have established CI/CD governance in place.
2. Augment
After Qodo’s deep architectural automation, some teams prefer something closer to where engineers actually work, inside the editor, during day-to-day coding. That’s where Augment fits in.
Augment is an AI-powered development assistant that runs inside your IDE and understands your entire codebase. It helps engineers read, refactor, and edit code faster without leaving their workflow. It’s designed for teams that want practical help improving code quality and consistency, not another standalone tool to manage.
Key Features
- Chat: lets you ask questions directly about your code , what a function does, how a module connects to others, or how to fix a specific issue.
- Next Edit: walks you through larger refactors step by step. You can apply multi-file changes safely instead of dumping a single massive diff.
- Code Completions: offers smart suggestions that use your project context , imports, naming conventions, and internal APIs , not generic boilerplate.
- IDE Support: available for VS Code, JetBrains IDEs (IntelliJ, PyCharm, WebStorm), and Neovim.
- CLI Integration: the Auggie CLI provides command-line access to the same features, useful for scripts and automation workflows.
- Rules and Permissions: You can define what Augment is allowed to do, who can run specific refactors, and how it handles certain files or modules.
Hands-on Example: Centralizing Environment Configuration with Pydantic
This example comes from a small but production-grade FastAPI microservice handling payment processing. The service used SQLAlchemy 2.0, JSON-based structured logging, and environment-driven configuration through .env files. It followed 12-factor principles, config through environment, stateless app containers, and per-environment overrides.
Over time, as new environment variables were added across modules, configuration access became inconsistent. Some components used a local Settings class in main.py, others accessed os.getenv() directly, and a few relied on implicit .env loading during test runs. Nothing was broken, but it was fragile; adding or changing an environment variable meant checking multiple files for correctness.
The goal was to centralize all configuration management into one place without altering runtime behavior or deployment compatibility.
I asked Augment to handle the refactor:
Consolidate all environment variable access into a single Pydantic BaseSettings class under app/core/config.py. Replace any direct os.environ or .env access across the codebase with imports from this class. Keep variable names unchanged and do not modify runtime behavior.
In response, Augment began by scanning the entire repository to identify all environment variable usage in the FastAPI app, repositories, tests, and deployment files. It found multiple access patterns: direct os.getenv() calls, inline variable defaults, and references inside test utilities.
From there, Augment executed the refactor step by step:
- Analyzed and mapped all environment access points: It lists five key variables used across the system: APP_NAME, ENV, LOG_LEVEL, API_KEY, and DATABASE_URL. It confirmed that main.py already used a Pydantic-based settings pattern, while tests still had hardcoded environment calls.
- Created a dedicated configuration module: Augment generated a new file, app/core/config.py, defining a single Settings class based on Pydantic’s BaseSettings. This class became the single authority for all configuration values. It also implemented a cached accessor function get_settings() to prevent redundant instantiation, following FastAPI best practices.
- Refactored application imports: In main.py, Augment removed the inline Settings definition and replaced it with:
from app.core.config import get_settings settings = get_settings()
This ensured every part of the app now consumed configuration from one place, without altering any environment defaults or validation logic.
- Updated test suite: In tests/test_payments.py, a direct call to os.getenv(“API_KEY”) was replaced with:
from app.core.config import get_settings
settings = get_settings()
return {"X-API-KEY": settings.API_KEY}
This aligned test behavior with production code, removing duplicated environment logic.
- Verification and validation: Augment ran automated searches to ensure no remaining os.environ or os.getenv calls existed, then executed all tests. Every test passed, confirming the refactor introduced no behavioral changes. The application started normally in both Docker and local environments.
In short, Augment turned what’s usually a manual, error-prone cleanup into a safe, deterministic refactor. The resulting configuration module followed FastAPI’s recommended pattern, central config via BaseSettings, .env integration, and cached loading, while maintaining the reliability expected in production systems
Pros
- Works inside existing workflows; no new systems to manage.
- Strong at developer-level refactoring and understanding project context.
- Supports multiple editors and automation through CLI.
Cons
- Cloud-based, with limited on-prem options.
- Focused more on developer productivity than enterprise compliance or governance.
3. Gemini (Google)
Gemini is Google’s AI coding assistant designed to integrate with the Google Cloud ecosystem. While most AI code tools focus on local development assistance, Gemini’s real advantage is its understanding of cloud context, APIs, SDK versions, and GCP service dependencies. For enterprises heavily invested in Google Cloud, it effectively bridges the gap between code and infrastructure.
Gemini isn’t just a completion model; it operates across files and understands architectural intent. It can reason about how one service interacts with another, detect outdated SDK usage, and recommend refactors that align with current Google Cloud best practices.
Key Features
- Context-Aware Refactoring & Completion: Gemini analyzes multiple files to understand service interactions before suggesting edits. For example, it can recognize that a storage service’s retry logic conflicts with a new GCP client library pattern and suggest a migration.
- Native Google Cloud Integration: Deep ties with Google Cloud Console and SDKs let it automatically align refactors with updated APIs, IAM policies, and service endpoints.
- Workspace Collaboration: Gemini integrates with Google Cloud Workstations and AI Studio, allowing teams to collaborate in shared environments with synchronized context.
- Multi-File Reasoning: Capable of cross-file dependency analysis , useful for large GCP microservices where configuration, logic, and infra code are split across multiple layers.
- Security & Compliance Alignment: Since it operates within Google Cloud, Gemini inherits GCP’s enterprise-grade compliance standards (SOC 2, ISO 27001, HIPAA readiness), an advantage for regulated environments.
Installation
Gemini comes integrated within Google Cloud Console and can also be accessed via AI Studio APIs. It supports IDE extensions for VS Code, JetBrains, and Cloud Shell Editor, so developers can work in familiar environments while retaining GCP context.
Use Cases
- Refactoring GCP-based Microservices:
Identify deprecated SDK methods, recommend replacements, and update API calls across multiple services. - API Migration:
Automatically refactor code when GCP client libraries update their interfaces (for example, moving from google-cloud-storage v1 to v2). - Consistency Enforcement:
Suggest uniform logging, retry, and error-handling patterns across distributed systems that follow GCP best practices. - Operational Hardening:
Detect missing observability hooks (e.g., Cloud Trace or Cloud Logging) and suggest instrumentation during refactors.
Hands-on Example: Aligning Test Configuration with Centralized Settings
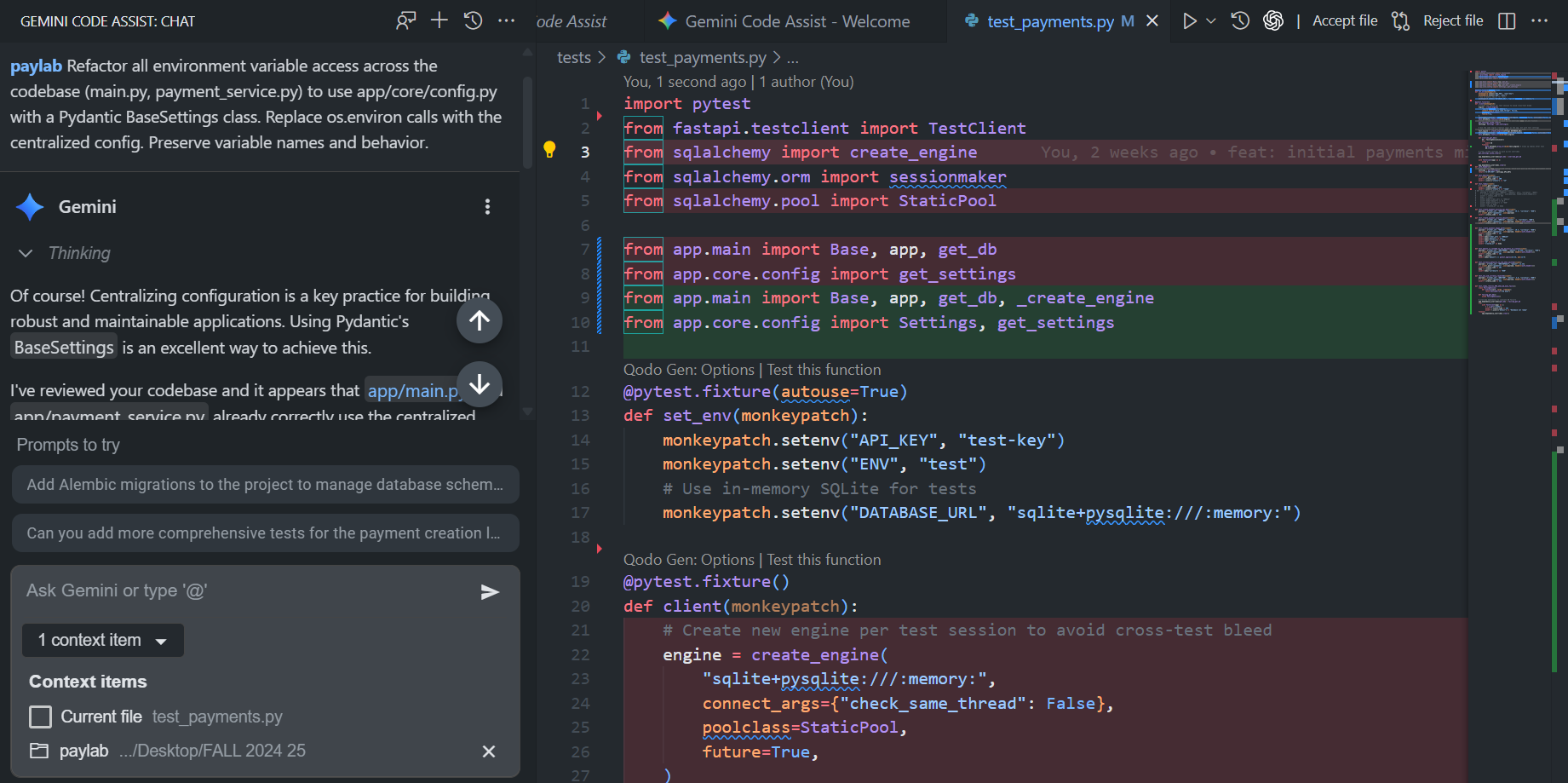
In the same FastAPI-based payments microservice, built with SQLAlchemy, structured JSON logging, and environment-driven configuration, I used Gemini to audit and refactor how configuration was being accessed across the codebase. The goal was to centralize all environment variable usage through a single Pydantic BaseSettings class under app/core/config.py, replacing any direct calls to os.environ while preserving runtime behavior. As visible from the snapshot from VS Code:
I prompted Gemini with:
Refactor all environment variable access across the codebase (main.py, payment_service.py) to use app/core/config.py with a Pydantic BaseSettings class. Replace os.environ calls with the centralized config. Preserve variable names and behavior.
In response, Gemini first confirmed that both main.py and payment_service.py already followed the proper pattern, using the centralized configuration module rather than direct environment access. Instead of redundantly rewriting what was already correct, it looked deeper into the test suite, where configuration handling was slightly inconsistent.
The tests/test_payments.py file was manually recreating a SQLAlchemy engine and session using hardcoded environment variables, which meant the tests weren’t using the same configuration lifecycle as the application. This caused subtle differences between test and runtime behavior.
Gemini identified the issue and refactored the test setup to respect the centralized configuration system. Specifically, it:
- Removed hardcoded environment calls and ensured test overrides used monkeypatch properly.
- Cleared the cached Pydantic settings before each test to re-read environment overrides.
- Used the same engine creation logic (_create_engine(settings.DATABASE_URL)) as the main app, ensuring database connections behaved identically in both environments.
- Added cleanup logic to drop test tables after each run, keeping the test database isolated and preventing cross-test state bleed.
Here’s a simplified version of the refactored fixture:
@pytest.fixture(autouse=True)
def set_env(monkeypatch):
monkeypatch.setenv("API_KEY", "test-key")
@pytest.fixture()
def client(monkeypatch):
from app.core.config import Settings, get_settings
from app.main import _create_engine, Base, app, get_db
from sqlalchemy.orm import sessionmaker
# Reset cached settings to pick up test overrides
get_settings.cache_clear()
settings: Settings = get_settings()
test_engine = _create_engine(settings.DATABASE_URL)
TestingSessionLocal = sessionmaker(bind=test_engine, autoflush=False, future=True)
Base.metadata.create_all(bind=test_engine)
def override_get_db():
db = TestingSessionLocal()
try:
yield db
finally:
Base.metadata.drop_all(bind=test_engine)
db.close()
app.dependency_overrides[get_db] = override_get_db
return TestClient(app)
The change above made the test suite behaviorally valid for production:
- Tests now consume configuration the same way as the live app, through get_settings() and Pydantic’s BaseSettings.
- No direct environment variable calls remain in the codebase.
- Database handling is unified, tests use the same connection creation path as runtime, ensuring parity.
- Cleanup is automatic and safe, removing leftover test tables.
Gemini’s output was clear and incremental; it explained each modification, validated that the main app files were already compliant, and limited its edits only to where they improved correctness.
This kind of surgical precision is what makes Gemini valuable in enterprise settings: it doesn’t rewrite for the sake of rewriting; it understands system intent, validates consistency, and applies changes only where structural alignment is needed.
Pros
- Deep integration with Google Cloud services and SDKs
- Strong multi-file reasoning and dependency analysis
- Compliance-ready by default within GCP
Cons
- Less flexible outside the Google Cloud ecosystem
4. GitHub Copilot
GitHub Copilot has become the de facto entry point for AI-assisted coding in most engineering organizations. Unlike tools that aim to rebuild workflows, Copilot’s strength is its frictionless integration; it embeds directly into existing IDEs, GitHub PR reviews, and enterprise development pipelines. For large teams, it’s not about novelty anymore; it’s about how deeply Copilot fits into the everyday development loop without adding management overhead.
Key Features
- Copilot Chat: Context-aware conversational assistant inside VS Code, JetBrains IDEs, and Neovim. It can explain code, suggest refactors, or generate missing logic inline.
- Inline Refactoring and Suggestions: As developers type, Copilot suggests better patterns, replacing nested callbacks, simplifying conditionals, or proposing async rewrites where applicable.
- Multi-language Support: Works across all major enterprise stacks, Python, Java, Go, C#, JavaScript, TypeScript, Rust, and more, with context maintained per repository.
- Enterprise Edition: Provides SOC 2 Type II compliance, data privacy guarantees, and optional telemetry isolation, allowing deployment across regulated environments.
- Pull Request Integration: Through GitHub Enterprise, Copilot can assist in PR reviews, highlight code smells, and suggest localized fixes before merge.
Installation
Copilot integrates via IDE extensions for VS Code, JetBrains IDEs, and Neovim, and links to GitHub Enterprise Cloud or Server. Once linked, it automatically uses organization-level policies and access control. Setup for enterprise tenants includes SSO, access scoping, and organization-wide seat management via GitHub Admin.
Use Cases
- Incremental Refactoring: Clean up nested or duplicated logic while developers are already working on the file.
- Legacy Code Modernization: Suggest replacements for outdated constructs (e.g., migrating Python 2-style classes to modern syntax).
- Query Optimization: Inline improvements to inefficient SQL queries or ORM filters.
- Code Review Assistance: Generate or refine comments during PR reviews, highlighting complexity or missing validation.
Hands-on Example: Reorganizing API Routes into Domain Subpackages
In another project, RBAC-dash, a Python-based Role-Based Access Control dashboard, the application defined authorization logic using Oso’s Polar policy language and structured its API endpoints in a single flat app/api/ directory.
The structure worked for early iterations, but as the application grew, having multiple domain-specific files (documents.py, users.py) in one place made it harder to maintain imports and scale the API cleanly.
To improve clarity, I asked Copilot to reorganize the API structure:
Move domain-specific routes in app/api/ into subpackages app/api/documents/ and app/api/users/, and create __init__.py files to aggregate routes. Update imports without changing route URLs or functionality.
Copilot began by analyzing the repository layout and scanning the relevant files:
- It inspected documents.py and users.py to understand route definitions and blueprint registration.
- It confirmed that no __init__.py existed in the app/api/ directory, and verified imports and dependencies from models.py and authz.py.
- It also checked for any missing modules (like roles_bp) referenced but not defined, flagging them for cleanup instead of leaving broken imports behind.
Once it had context, Copilot performed a multi-file structural reorganization:
- Created Subpackages:
- app/api/documents/ and app/api/users/ directories were created.
- Existing route logic was moved into each subpackage’s new routes.py file.
- Generated Initialization Files:
- Each subpackage received an __init__.py exporting its respective blueprint.
- A top-level app/api/__init__.py was created to import and register blueprints from the new structure.
- Updated Imports:
- Adjusted all relative imports to reflect the new layout.
- Replaced missing or incorrect imports in __init__.py, removing unused references (e.g., roles_bp).
- Cleaned Up Legacy Files:
- Removed the old flat documents.py and users.py files to prevent conflicts.
- Verified imports and blueprint registration to ensure the application is still exposed /users/* and /documents/* endpoints exactly as before.
- Validation:
- Ran route discovery to confirm all endpoints were still reachable.
- Verified that Oso’s authorization policies (policy.polar) continued working with no import resolution errors.
Result
- The API structure is now domain-driven, with each domain owning its own routes and initialization logic.
- Imports are cleaner and predictable, following Python’s standard package layout.
- All route URLs and authorization behavior remain unchanged, ensuring full backward compatibility.
- Future extensibility has been improved, allowing new domains to be added as separate subpackages without refactoring the entire API layer.
Copilot’s refactor was incremental and safe: it reasoned about how Flask/FastAPI blueprints were registered, preserved existing route paths, and eliminated dead imports automatically.
What would normally require manual restructuring and route validation was completed interactively in a single pass, with Copilot validating the project state after every change.
Pros
- Seamless integration into daily development workflows.
- Strong coverage across languages and frameworks.
- Low operational overhead, runs where developers already are.
Cons
- Limited repository-wide reasoning, context is mostly local to open files.
- Cloud dependency, on-premises, or air-gapped setups are not supported.
5. Cursor
Cursor takes a different approach to AI-assisted development. Instead of embedding into existing IDEs, it is the IDE, built on top of VS Code but redesigned for AI-first workflows. It’s built for engineers who want AI to operate as a true collaborator across multiple files, not just a text predictor.
Cursor’s strength lies in multi-file reasoning and conversation-driven refactoring. It maintains an internal context graph of your project, so when you ask it to make a change, like “update all API handlers to use a new authentication class”, it doesn’t just search and replace. It traverses dependencies, understands type usage, and orchestrates changes across the entire workspace.
Key Features
- Composer Mode: Enables coordinated multi-file refactors. Cursor builds a dependency graph, executes the changes across affected files, and provides a consolidated diff view.
- Chat-Driven Development: Every refactor begins as a natural-language instruction , “extract the validation logic into a middleware,” “rename this interface globally,” or “update all imports to match the new module layout.” Cursor translates that intent into executable code edits.
- Project-Wide Context Awareness: Cursor keeps track of how files reference each other, so refactors respect imports, type definitions, and interfaces without breaking linkage.
- Built-in Collaboration Tools: Developers can share refactor sessions or code discussions directly within Cursor, similar to pair programming with history tracking.
- Native Git Integration: Each AI-generated change appears as a diff, making it easy to stage, review, or discard specific edits.
Installation
Cursor is a standalone IDE available for macOS, Windows, and Linux. It’s compatible with VS Code extensions, meaning developers can continue using their usual linters, formatters, and language servers. Setup is lightweight, login with GitHub, open a project, and Cursor begins indexing immediately.
Use Cases
- Large-Scale Code Migrations: Rename or move modules across a monorepo while automatically updating imports and type hints.
- Interactive Debugging: Ask the Cursor to trace where a particular variable is set or modified across files.
- Multi-File Refactors: Safely propagate API or data model changes through service layers.
- Cross-Team Collaboration: Share interactive refactor sessions where each participant can view and approve changes in real time.
Hands-on Example: Updating Rego Package Names and Workflow References
In the GCP Compliance Validation repository, there is a Terraform and Open Policy Agent (OPA) setup that validates Google Cloud resource configurations. I wanted to bring the Rego policy naming in line with a more consistent and future-proof convention.
The project’s OPA policy (storagepolicy.rego) enforced uniform bucket-level access on GCS buckets. However, the package name was defined as package terraform.gcs, while our broader policy structure was moving toward more modular naming like terraform.gcs.policy. To align with this convention and ensure all workflow references still resolved correctly, I asked Cursor to handle the update:
Rename the Rego package name in storagepolicy.rego to follow package terraform.gcs convention and ensure the workflow eval command still resolves policy_summary.
Cursor began by inspecting the relevant files, policy/storagepolicy.rego, the GitHub Actions workflow file .github/workflows/terraform.yml, and the README.md. It confirmed that the current package was already close to the standard (package terraform.gcs), but suggested an enhancement for future extensibility:
- Rename to package terraform.gcs.policy
- Update all workflow and documentation references that query the policy summary (data.terraform.gcs.policy.policy_summary)
Cursor then executed the following automatically:
Updated the Rego package declaration: Changed the top line of the storage policy.rego from package terraform.gcs to package terraform.gcs.policy
- Modified GitHub Actions Workflow: Updated .github/workflows/terraform.yml to reference the new Rego path in its evaluation command:
opa eval -d policy/ -i tfplan.json "data.terraform.gcs.policy.policy_summary"
- Synchronized Documentation: Updated README.md to reflect the same path for local validation commands, keeping developer instructions consistent with CI behavior.
- Validated Changes: The cursor automatically verified that the OPA workflow executed successfully under the new path and confirmed that all commands in both local and CI contexts resolved without errors.
Here’s the resulting diff view inside Cursor:
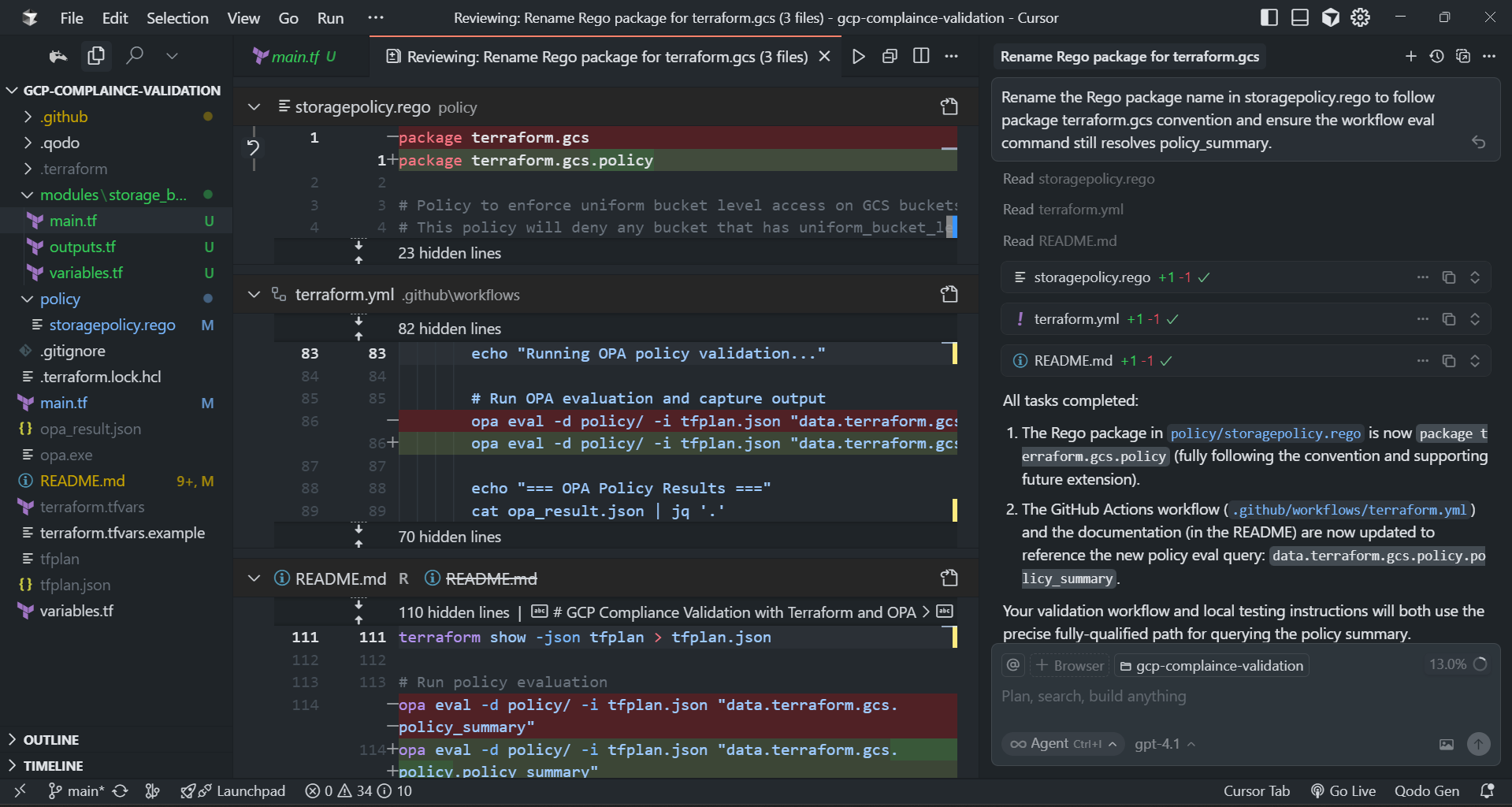
Cursor summarized the operation as:
- The Rego package in policy/storagepolicy.rego is now package terraform.gcs.policy (fully following convention and supporting future extension).
- The GitHub Actions workflow and documentation are now updated to reference the new query path data.terraform.gcs.policy.policy_summary.
This change might seem minor, but at scale, especially in infrastructure repositories, such consistency ensures maintainability. With Cursor’s multi-file context, the refactor was completed safely in minutes, with full visibility of diffs and automated verification of the OPA evaluation workflow.
Pros
- Deep multi-file awareness and dependency tracking.
- Works well for large-scale refactors and migrations.
- In the integrated review flow, every AI edit appears as a diff for manual approval.
Cons
- Adopting a new IDE can slow down onboarding.
- Smaller ecosystem compared to VS Code or JetBrains, though extension compatibility mitigates most gaps.
6. Codex (OpenAI API)
Codex, built by OpenAI, serves as the foundational large language model for many AI-assisted coding tools, including early versions of GitHub Copilot. Unlike integrated assistants or IDE-native agents, Codex is offered as an API, giving enterprises the freedom to design their own AI-driven refactoring pipelines, internal bots, and compliance automation systems.
This flexibility makes it ideal for organizations with strict security or architectural constraints that prefer to run AI-driven code transformations within their own infrastructure rather than relying on third-party SaaS tools.
Key Features
- Language-Agnostic Refactoring: Supports multiple languages, including Python, Java, Go, C#, and Terraform, allowing cross-stack transformations from a single API.
- Natural-Language Instruction Interface: Accepts plain English (or any supported language) prompts to perform structured code edits, generate refactors, or apply modernization rules.
- Custom Integration: Can be embedded directly into enterprise CI/CD pipelines, internal developer portals, or compliance validation bots.
- High Accuracy for Structured Edits: Particularly effective for standardized refactors, like replacing deprecated functions, updating SDK usage, or aligning internal libraries.
- Secure Deployment Options: Works with OpenAI’s enterprise offerings that provide data isolation, auditability, and API-level governance.
Installation & Integration
Codex isn’t installed like a plugin; it’s integrated programmatically. Enterprises typically use the OpenAI API via Python or Node.js SDKs, wrapping calls in their CI/CD jobs, custom CLI tools, or internal bots. For high-security environments, requests can route through private network gateways or anonymized proxies to protect source code metadata.
Use Cases
- Automated Refactor Bots: Run in CI to detect deprecated SDK calls or enforce migration patterns.
- Modernization Pipelines: Auto-update outdated frameworks or APIs (e.g., Flask → FastAPI, Java 8 to 17).
- Compliance Enforcement: Scan for insecure code constructs and propose compliant alternatives before merge.
- Documentation Alignment: Auto-update README examples or inline docstrings when method signatures change.
Hands-on Example: Decoupling AI Logic Using an Interface-Based Provider Architecture
In this project, I was building an AI-driven Terraform automation agent capable of creating Google Cloud Storage (GCS) buckets from natural language descriptions. The agent interpreted user input like “Create a versioned bucket in us-central1 with public access disabled” and converted it into Terraform HCL. It also included interactive fallback logic when AI services were unavailable.
While the system worked, the NLP layer directly invoked OpenAI’s GPT-4o-mini via LangChain. This made the AI logic tightly coupled to a single provider, complicating future extensibility, such as switching to Anthropic or local models for on-prem deployments.
To address this, I prompted Codex to perform an architectural refactor:
Decouple GPT-4o-mini calls: create an AIProvider interface and move OpenAI logic into its own class. Update the NLP code to depend on the interface.
Codex approached the task methodically, breaking it into five subtasks:
- Locate GPT-4o-mini usage: Scanned the entire codebase for LangChain and OpenAI references, primarily in the main.py NLP flow, where prompt construction and response parsing occurred
- Define the AIProvider interface: Created an abstract protocol in a new file
ai_provider.py:
from typing import Protocol
class AIProvider(Protocol):
def generate_hcl(self, user_input: str) -> str:
...
This interface formalized a contract for any AI backend capable of translating natural language into Terraform HCL.
- Implement the OpenAIProvider: Added an OpenAIProvider class encapsulating all LangChain + OpenAI specifics, prompt templates, token handling, and model selection. Example:
from langchain_openai import ChatOpenAI
class OpenAIProvider:
def __init__(self):
self.model = ChatOpenAI(model="gpt-4o-mini")
def generate_hcl(self, user_input: str) -> str:
prompt = f"Convert this to Terraform HCL: {user_input}"
return self.model.invoke(prompt).content
- Refactor NLP workflow to depend on the interface: Updated main.py to import AIProvider and use dependency injection for provider creation.
- Replaced all direct OpenAI calls with provider.generate_hcl(user_input).
- Replaced _get_llm() helper with _get_provider() returning an AIProvider instance.
- Wrapped provider initialization in a runtime check to gracefully fall back to interactive mode if OpenAI dependencies were missing or the API key wasn’t configured.
- Validation and smoke testing: Codex ran a lightweight validation, ensuring imports resolved and no circular dependencies existed. It noted a missing structlog module locally but confirmed the refactor isolated OpenAI logic fully, allowing non-AI paths to function without dependency errors.
This refactor made the codebase cleaner, easier to maintain, and future-proof. What would typically take an engineer a few hours of careful dependency mapping and testing was handled in one structured prompt, with Codex reasoning about interface design, dependency injection, and runtime isolation automatically.
Pros
- Highly flexible since it can be integrated into any pipeline or workflow.
- Strong accuracy for standardized refactors across multiple languages.
- Enterprise-ready customization (governance, audit logs, isolated deployments).
Cons
- Requires a custom integration effort, no UI or IDE front-end.
- Limited context window per API call, not ideal for very large refactors without chunking logic.
7. Zencoder
Zencoder is an AI coding agent that runs in your IDE (VS Code, JetBrains, Android Studio). It analyzes your repo, helps write/modify code, and automates common dev tasks with project-aware context.
Key Features
Its foundation is built on two key components:
- Repo Grokking™: analyzes your entire repo to build a code map, recognizing patterns, architecture, and conventions.
- Agentic Pipeline: runs AI-generated code through verification and repair steps before suggesting it, ensuring correctness in your project context.
Zencoder also supports Claude Code, Gemini, and OpenAI Codex through its Universal AI Platform, letting teams plug in existing model subscriptions.
Installation
Install the Zencoder extension in your preferred IDE, sign in, and let it index your project. Once indexing completes, Zencoder provides context-aware suggestions, code completions, and refactors directly in the editor.
Use Cases
- Large multi-file refactors using the Coding Agent.
- Auto-generating unit or end-to-end tests aligned with your framework.
- Analyzing code with the Ask Agent to explain logic or suggest fixes.
- Integrating across tools like Jira and other MCP-supported systems for workflow automation.
Hands-on Example: Rewriting manual JWT parsing to PyJWT (Zencoder)
In our Python SDK, token.py was unpacking JWTs by hand: split on “.”, base64-decode the middle part, then json.loads the payload. It worked until it didn’t—padding bugs, inconsistent errors, and a few places catching the wrong exceptions. I asked Zencoder to rewrite the module to use PyJWT while keeping the same public helpers and return values.
I gave a single prompt: “Refactor token.py to use the JWT (PyJWT) library for decoding. Keep the public helpers and return values the same. Improve error handling. Don’t change routes or call sites.” Zencoder scanned the file, replaced the manual parsing with jwt.decode(token, options={“verify_signature”: False}), and routed decode failures to a clean ValueError(“Invalid token format”). The higher-level helpers—get_tenant_id_from_jwt and get_addresses_from_jwt—stayed intact; they now call the centralized extract_claims_from_jwt, which returns the payload dict from PyJWT. All the padding, math, and ad-hoc try/except blocks went away.
The diff was small and obvious: imports now include jwt, the hand-rolled parsing block disappeared, and the helpers read better. Here’s the patch as shown in Zencoder:
Functionally, nothing changed for callers, same helpers, same keys, better errors. Operationally, we reduced edge cases and made it trivial to turn on real verification later by adding key material and algorithms, e.g.:
jwt.decode(token, key=PUBLIC_KEY, algorithms=["RS256"])
Security note: this refactor intentionally mirrors the previous “claims-only” behavior (no signature check). In production paths, enable verification and pin algorithms.
Pros
- Deep repo understanding through Repo Grokking™.
- Validated, context-aware edits with the Agentic Pipeline.
- Works across multiple AI models under one platform.
- Integrated into standard IDEs, no separate UI needed.
Cons
- Requires initial repo indexing before use.
- Multi-repo setup and administration need elevated workspace permissions.
Comparison of Top Code Refactoring Tools
For engineering leaders evaluating these tools, the question isn’t which is smarter, but which aligns best with how your teams ship software. The table below summarizes how each platform performs against the key enterprise criteria: scalability, integration depth, context handling, compliance readiness, testing reliability, and collaboration fit.
| Tool | Context Awareness | Security & Compliance | Testing & Validation | Collaboration & Governance | Best Fit |
| Qodo | High, retrieval-augmented context indexing across large repos | SOC 2, on-prem, and air-gapped deployments | Automated test generation and validation via Qodo Cover | Enterprise-grade audit logs, standards enforcement, and merge governance | Enterprises modernizing large, critical systems with compliance constraints |
| Augment | Moderate, focuses on in-editor and PR context | Cloud-managed (limited on-prem options) | Refactors validated via tests within CI/CD | Team dashboards and collaborative review tools | Mid-size teams improving code health and review velocity |
| Gemini (Google) | Strong, cross-file reasoning tied to GCP SDKs | Inherits GCP compliance (SOC 2, ISO 27001, HIPAA) | Auto-validates refactors through Cloud SDK tests | Collaboration through Cloud Workstations | Cloud-first orgs building on GCP |
| GitHub Copilot | Moderate, local file-level reasoning | Enterprise edition with data isolation and SOC 2 | Inline fix suggestions and quick validation | Works naturally with PR reviews | Teams seeking seamless AI support inside GitHub |
| Cursor | High, project-wide dependency reasoning | Local or cloud storage; follows IDE-level permissions | Change simulation and type consistency checks | Shared refactor sessions and real-time collaboration | Teams doing continuous codebase evolution with shared AI tooling |
| Codex (OpenAI API) | Depends on integration depth | Data-isolated enterprise deployments available | Relies on external validation via tests | Governance built into the enterprise OpenAI API | Enterprises building internal AI refactor or modernization bots |
| Zencoder | High, Repo Grokking™ builds a full repo map | Enterprise-grade control; supports on-prem/hybrid | Verification via Agentic Pipeline | Multi-agent collaboration and enterprise dashboard | Orgs managing many repos or needing verified multi-file AI edits |
Code Refactoring at Scale in Enterprise Architecture
Refactoring in an enterprise isn’t a cosmetic cleanup; it’s an operational capability. The goal is to evolve production systems safely, in-flight, and at scale. When your platform spans thousands of microservices, shared SDKs, and decades-old subsystems, even a small change to a common module can impact hundreds of deployments. The real challenge is introducing structure and predictability into that process.
The Reality of Enterprise Codebases
Enterprise software systems are rarely homogeneous. A modern core might run on Go and TypeScript, but deeper layers still rely on Java 8, Python 2 remnants, or vendor-managed SDKs. These coexist in the same CI/CD pipelines and depend on each other through internal APIs. That mix makes technical debt structural, not stylistic.
Manual refactoring at this scale becomes a logistics problem: coordinating across teams, languages, and compliance gates while ensuring uptime and traceability.
Operational Challenges
- Scale and Dependency Depth: Codebases span millions of lines, multiple languages, and hundreds of services. Refactors must account for dependency graphs, version pinning, and package boundaries.
- Compliance-Driven Change: Many organizations operate under audit regimes like SOC 2, GDPR, or FedRAMP. Every automated refactor must log what changed, why, and who approved it.
- Continuous Delivery Constraints: With pipelines deploying hourly, refactors must integrate seamlessly, not block releases. This requires CI-native validation and incremental rollout.
- Distributed Ownership: Different teams own overlapping code surfaces. Refactoring safely means respecting team boundaries and code ownership while maintaining architectural consistency.
AI’s Role in Enterprise Refactoring
Modern AI refactoring systems move the process from reactive to continuous. Instead of manual bulk rewrites, AI agents can perform fine-grained, context-aware updates in small, validated increments. These systems understand architecture, not just syntax, by mapping dependencies, reading tests, and validating outputs before merging.
AI-driven refactoring now enables:
- Automated detection and cleanup of deprecated functions or APIs.
- Repository-wide naming and interface standardization.
- Consistent enforcement of error-handling, validation, and logging contracts.
- On-demand test generation and behavioral verification during refactors.
- Versioned, auditable refactor logs integrated into PR or CI/CD systems.
This transforms refactoring into a governed, incremental process, one that can run continuously in production pipelines rather than being an occasional engineering project.
Why Qodo Fits Enterprise Architecture
Among current tools, Qodo directly addresses the architectural and governance side of this problem. Its multi-agent setup, IDE Agent (Qodo Gen), PR Review Agent (Qodo Merge), and Testing Agent (Qodo Cover), connects development, review, and validation in one controlled loop making it an application of agentic workflows. It handles refactoring as an enterprise workflow:
- Refactor intent is initiated from the IDE.
- The PR layer enforces compliance, dependency validation, and coding standards.
- The test agent verifies behavioral parity before merge.
With SOC 2 compliance, audit logs, and on-prem deployment options, Qodo fits environments where code integrity and traceability are as important as velocity. It treats refactoring not as a developer activity, but as an operational part of the SDLC, governed, measurable, and reversible.
FAQs
What is the best AI tool to refactor code?
It depends on your environment. Qodo is the strongest choice for enterprise-scale refactoring; it’s context-aware, generates tests automatically, and enforces governance through audit logs. For smaller workflows, Copilot, Cursor, or Zencoder enhances developer productivity and facilitates targeted refactors.
How does GitHub help engineers learn best practices during refactoring?
GitHub’s Copilot Chat, PR templates, and protected branch rules help teams refactor safely by enforcing reviews, test runs, and clean coding patterns directly in the workflow.
How does refactoring improve code quality?
Refactoring simplifies complex logic, removes dead code, and strengthens testability, resulting in fewer regressions, clearer interfaces, and easier long-term maintenance of code quality.
What tools would you use to safely refactor code?
For enterprise-grade safety, Qodo is the most complete solution, combining automated testing, PR validation, and audit trails. Paired with GitHub Actions for CI checks and Cursor for multi-file context, it ensures clean, reliable, and traceable refactors.


