Why AI Self-Review Fails: The Technical Case for Independent AI Systems

When the same AI system writes your code and reviews it, you’re not getting quality assurance. You’re getting confirmation bias at scale.
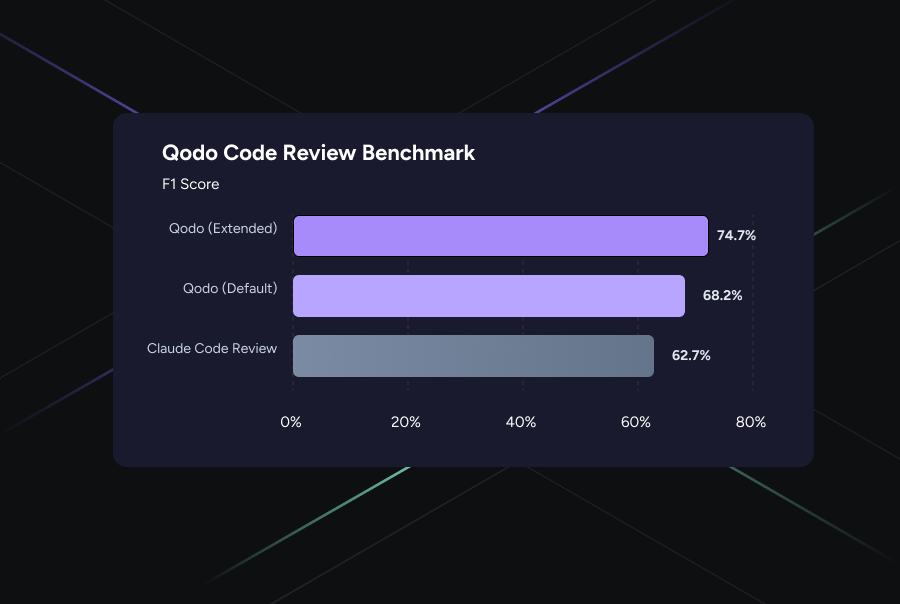
GitClear’s analysis of 211 million lines of code surfaced a pattern: when the same AI system generates code and then reviews it, the results are measurably worse. We’re talking about 8x more duplicated code, 39.9% fewer refactors, and a 37.6% increase in vulnerabilities.
In this post, “self‑review” includes any tight coupling of generation and review within the same vendor stack.
The problem lies in using the same system for two fundamentally different tasks.
The Architecture Problem
Generation tools like Cursor or Claude Code are optimized for one thing: helping you write code fast. They need to respond with functional code in seconds, maintain your flow, and suggest code that matches your current context.
AI code review tools need to do something completely different: to catch what the generator missed, with a level of scrutiny akin to a principal engineer as a code quality enforcer. They need deep codebase context, cross-repo awareness, historical pattern recognition, and the architectural space to calculate risk and suboptimality against your code.
These are different systems with different architectures, and they need to be, because self-review doesn’t work as well as it might seem.
Some developers attempt to mitigate this by using different models for generation and review. That helps, but misses out on crucial optimization gains from a separate system.
In this post, I’ll explain why this matters for software engineers using AI to accelerate development.
Why AI Self-Review Fails
Confirmation Bias is Built into the System
When an LLM generates code following a particular pattern, it interprets that code through the lens of “this pattern is correct.”
The first generation constrains all subsequent analysis. The model sees its own output and validates it based on the same training data and decision patterns that produced it initially.
Research published in the Proceedings of the National Academy of Sciences (PNAS) in July 2025 demonstrated this systematically: LLMs exhibit “AI-to-AI bias,” favoring content generated by other LLMs over human-written content. When reviewing their own output, this bias compounds.
The model recognizes its own patterns as familiar and therefore correct.
The strongest version of this effect shows up when foundational model providers cross‑validate their own outputs, but variants of the same failure mode appear whenever review depends on similarly trained, similarly optimized models looking at the same constrained context.
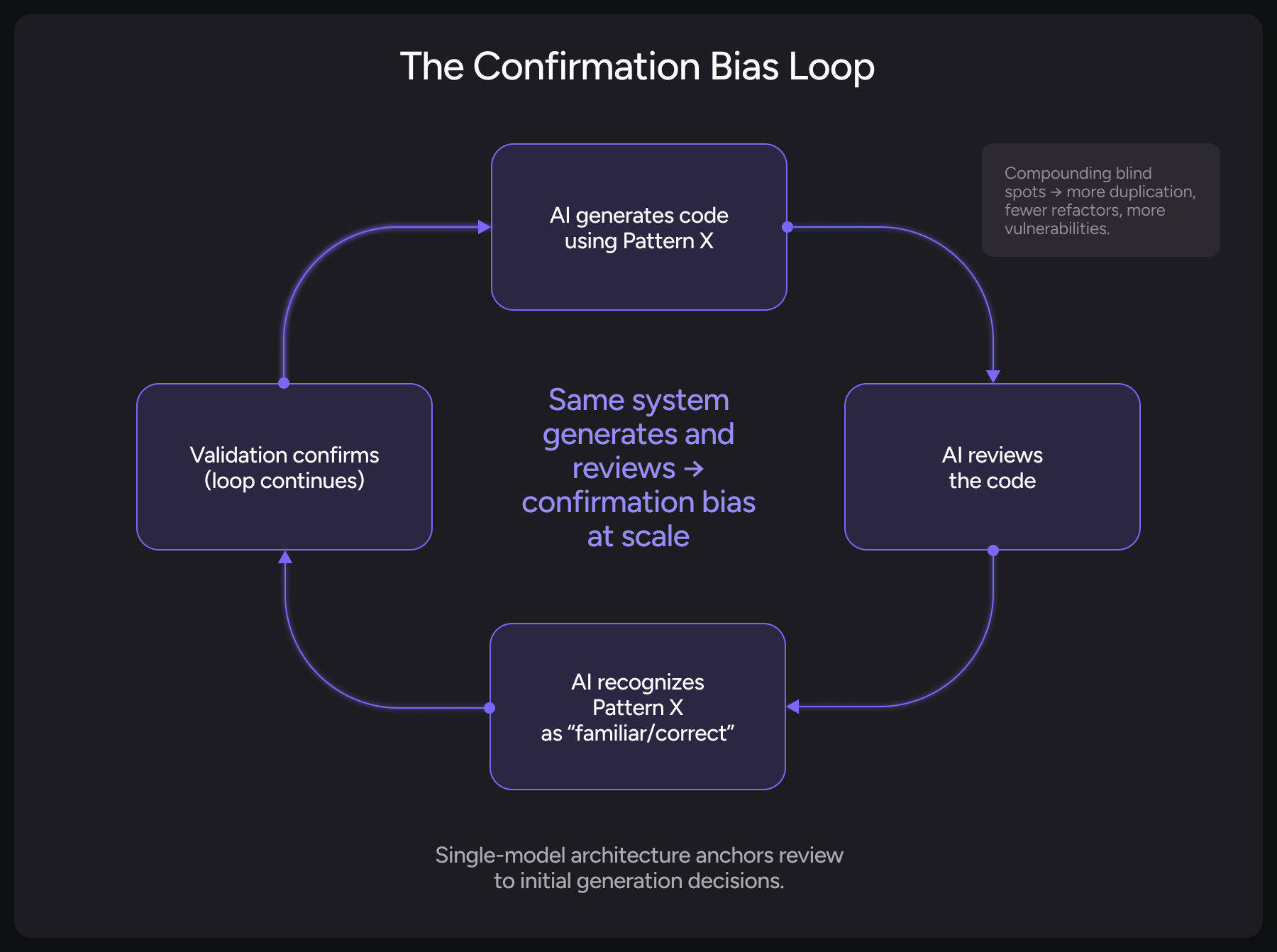
Think about it from a systems architecture perspective.
You wouldn’t use the same tool for linting and testing because they serve different purposes with different optimization targets. Yet that’s exactly what happens when one AI tool both generates and reviews code.
Except the consequences are worse because both operations draw from the same decision-making substrate.
AI Has Predictable, Measurable Blind Spots
AI’s blind spots aren’t random errors. They’re systematic, repeatable patterns that persist across model versions and vendors.
Veracode’s 2025 GenAI Code Security Report analyzed AI-generated code across multiple languages and found that 45% of AI code introduces security flaws. More troubling: when given a choice between secure and insecure implementation options, AI models chose the insecure option 45% of the time. And this performance showed no improvement over time.
Here’s why this happens: AI models are trained on massive code repositories including StackOverflow, GitHub, and other public sources. Not all of that code represents production-grade implementations or best practices.
When an AI generates code using learned insecure or generic patterns, and then reviews it, the review validates the pattern match. It’s processed as “Yes, this looks like code I’ve seen before. Minimal issues here.”
“Steering models off minimum‑effort paths. Left to default objectives, most models optimize for the lowest‑effort completion that looks plausible, not the safest or highest‑quality change. In review, you have to explicitly steer the system toward security, maintainability, and team standards, or it will happily approve “good enough” code that quietly accumulates risk.”
Ofir
The Model Knows It’s Wrong, But Won’t Catch It
AI models can identify their own hallucinations 80%+ of the time when asked directly.
Present a model with its own hallucinated output and say “Is this correct?” and it will often catch errors. But during code review? The same model fails to flag the same hallucination.
Why? Context changes activation patterns. During generation, the model is in “creation mode”, synthesizing from training data. During review, it encounters text that matches patterns it would generate, so it reads as validated input.
The issue gets reinforced, not caught.
The paradox: the model knows it’s hallucinating, but only when explicitly challenged, not during routine review operations.
Why Independent Review Works Better
The core solution is understanding that code generation and code review have fundamentally different architectural approaches.
Using the same tool for both means making compromises that hurt both workflows.
1. Fresh Perspectives Break Confirmation Anchors
When a different AI system reviews code, it wasn’t present during generation.
It doesn’t “remember” the reasoning that led to the current implementation. It can evaluate the code as written, without the anchor bias that comes from having generated it.
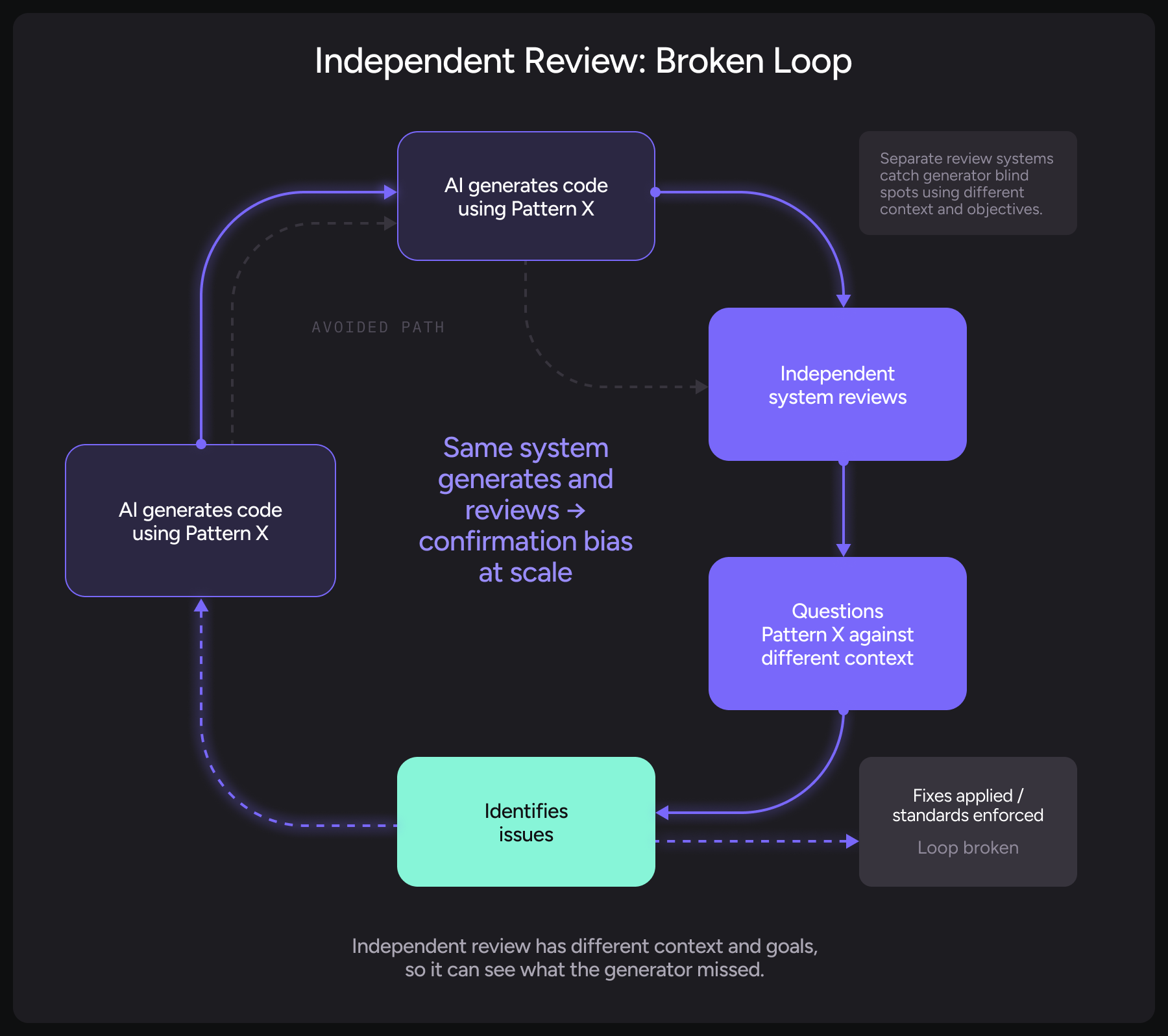
Think about code review in your own experience.
When you review your own code after writing it, you see what you intended to write. When someone else reviews it, they see what you actually wrote. That difference catches bugs.
The same principle applies to AI. A separate review system can question choices that the generating system considers settled. It can suggest alternatives that the generator didn’t consider because it had already committed to a different approach.
2. Different Architectures See Different Patterns
Different tools see different patterns, even when using the same underlying model. The independence comes from architectural differences: what context the tool has access to, what it’s optimized for, and how it processes code.
A generation tool optimized for fast, in-IDE (or CLI) completion sees your current file and repo. A review tool with multi-repo indexing sees your entire codebase, historical decisions, and team patterns.
This architectural difference creates genuinely independent analysis even when the same model powers both tools.
Why generation tools can’t do deep review:
Generation tools optimize for speed by limiting context. They can’t afford expensive operations like cross-repo indexing or historical pattern analysis.
They prioritize pattern-matching for fast autocomplete. This is the right architectural choice for coding with speed.
Claude or GPT models could theoretically do better analysis, but the architecture harnessing the AI for generation doesn’t support that level of scrutiny.
3. Context Engineering Determines Review Quality
Context is the real differentiator, and it requires different tool architecture.
Research from Google and UCSD on cross-file code completion shows:
- Code LLMs perform poorly with only current-file context
- Performance improves dramatically when cross-file context is added
- All models follow the same pattern: better context equals better accuracy
A mid-tier AI model given access to your full codebase outperforms a state-of-the-art model without that context.
Generation tool thinking: “Here’s your current file context. Generate the next code block.”
Review tool thinking: “Here’s the diff, the entire codebase you’re changing, the last 50 PRs that touched these files, your team’s architectural patterns, and security requirements.”
Real-world example:
Intuit uses Qodo’s cross-repo analysis because a change in a shared library signature can ripple through dozens of services.
A generation tool working on a single file would never see those downstream breaking changes. Qodo’s architecture catches them because it indexes the entire dependency graph.
What this Means for Your Developer Workflow
When Salesforce scaled AI-assisted development and saw a 30% boost in code output, they hit a bottleneck downstream: review and integration.
The code was coming fast, but code review wasn’t scaling with generation.
The solution was specialized review tools architected for comprehensive analysis, not quick suggestions.
Code review is meant to be treated as a governance and judgment system that preserves engineering standards, intent, and decision quality as teams scale and AI accelerates change.
At its best, it encodes multi-layered judgment (individual developer, team-level, organizational level, and code quality pillars) into the review process so software can ship at the rate at which a team chooses to build/scale with AI.
Qodo’s architecture is purpose-built for review. Even when the underlying model is the same as what powers your generation tool, Qodo’s context engine, multi-agent architecture, multi-repo indexing, and continuous learning from your team’s PR feedback create genuinely independent reviews.
From independent, specialized review systems, you’re getting analysis informed by your entire codebase and team standards, built to evolve with your software, as a process and a business.
The Broader Goal
For developers using AI to accelerate their work, we want to see them shipping quality code fast with confidence in their systems and processes.
Separating code generation and code review tooling in your stack is about making sure the speed you’ve gained from AI doesn’t come at the cost of code you can’t trust, systems you can’t maintain, and quality standards you can’t sustain.
The code you ship today becomes the system you maintain tomorrow.