Why Your AI Code Reviews Are Broken (And How to Fix Them)

When I attended AWS re:Invent, I had the same conversation three different times with three different engineering leaders. All variations of this theme:
“If our AI can generate code, why can’t it review its own code?”
I get it. Same model. Same system. Adding specialized review agents feels like unnecessary complexity. On the surface, it makes sense. However, under the hood, that logic is costing you code quality.
The Problem a Developer Might Ignore
When you use the same AI system to both write and review code, you’re not getting a second opinion. You’re getting confirmation bias at scale.
Think about your own coding process. When you write a function, your brain is in “creation mode.” You’re optimizing for getting something working. When you review code (especially someone else’s code), you switch to “detective mode.” You’re looking for what could go wrong.
You activate different neural pathways, leverage different problem-solving patterns, and optimize for different objectives.
These aren’t the same cognitive processes. And they shouldn’t use the same AI architecture either.
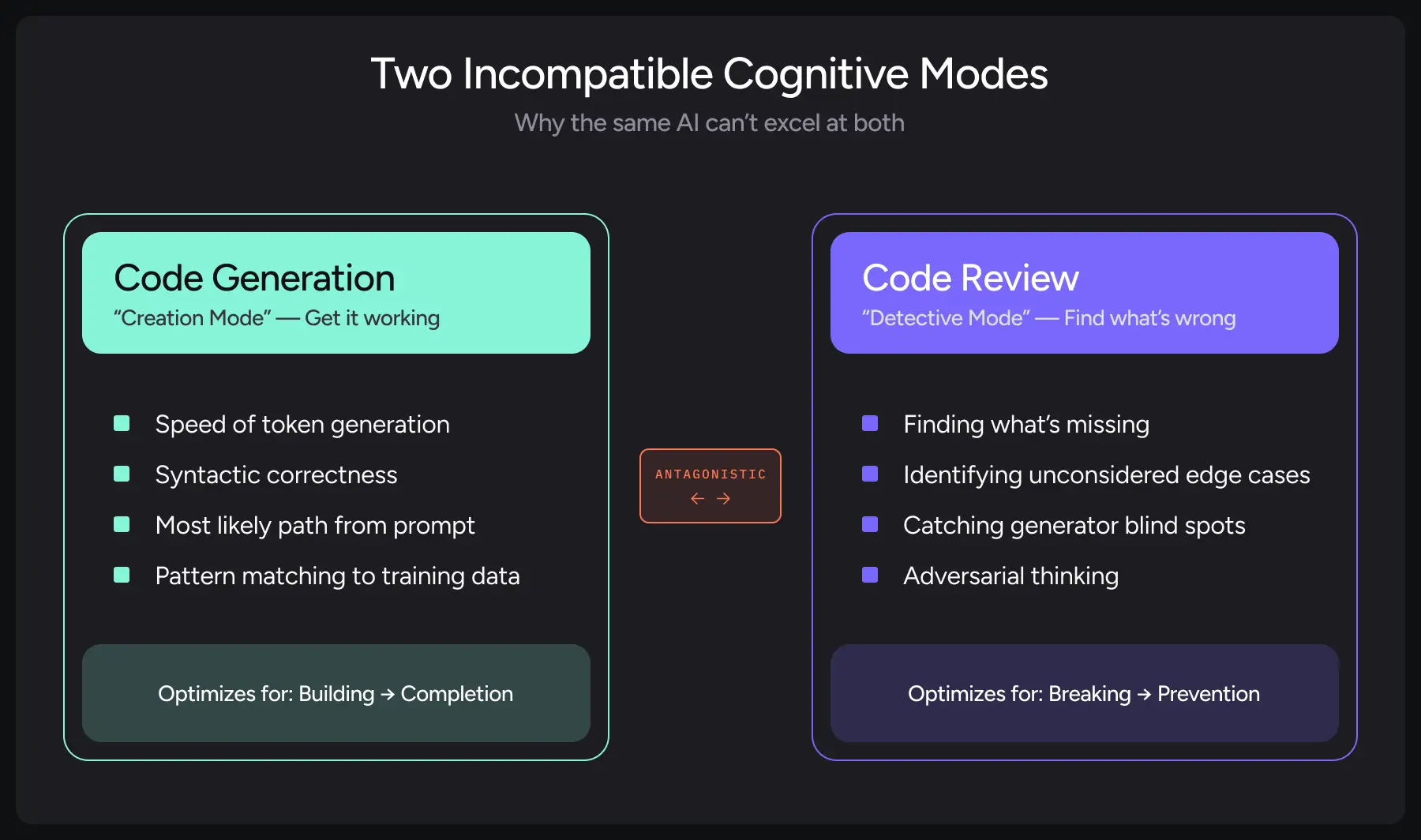
When you prompt an LLM with “write production-ready code that handles edge cases gracefully,” the model activates different probability distributions across its parameter space than when you prompt it with “find every possible way this code could fail and write comprehensive tests.” The model is predicting the next token given a specific cognitive framework.
Code generation prioritizes:
- Speed of token generation
- Syntactic correctness
- Following the most likely path given the prompt
- Pattern matching against training data
Code review requires:
- Finding what’s missing
- Identifying edge cases the generator didn’t consider
- Catching what the generator is biased toward not seeing
- Adversarial thinking
These aren’t complementary modes of the same system. They’re antagonistic.
How Same-Model Review Suffers
I’ve been digging into the data, and it’s worse than I thought:
GitClear analyzed 211 million lines of code in 2024 and found:
- 8x increase in duplicated code blocks when AI reviews its own output
- 39.9% decrease in refactored code
- 37.6% increase in critical vulnerabilities after multiple AI “improvement” cycles
Veracode’s security analysis shows AI-generated code failing basic tests:
- Java: 72% failure rate
- JavaScript: 43% failure rate
- Python: 38% failure rate
Most of these failures go undetected when the reviewing system is the same one that generated the code.
The Confirmation Bias Problem
LLMs exhibit confirmation bias: a well-documented cognitive bias where systems preferentially seek, interpret, and generate information consistent with their own outputs.
When the same model that wrote code reviews the same code, it faces a problem: its initial generation act has created an anchor. That anchor constrains all subsequent analysis.
Research on anchoring bias in LLMs shows that models are remarkably sensitive to initial information. Here’s what’s actually happening when your AI reviews its own code:
- Model generates code with specific logic patterns
- Same model reviews the code but is anchored to those original decisions
- Review validates the generation because it matches the model’s training patterns
- Critical flaws go unnoticed because the reviewer can’t see outside its own reasoning
In production systems, this manifests as code that passes “AI review” but fails when humans or different systems analyze it. This isn’t a prompting problem. It’s not even a fine-tuning problem. It’s an architecture problem.
The Separation of Concerns Solution
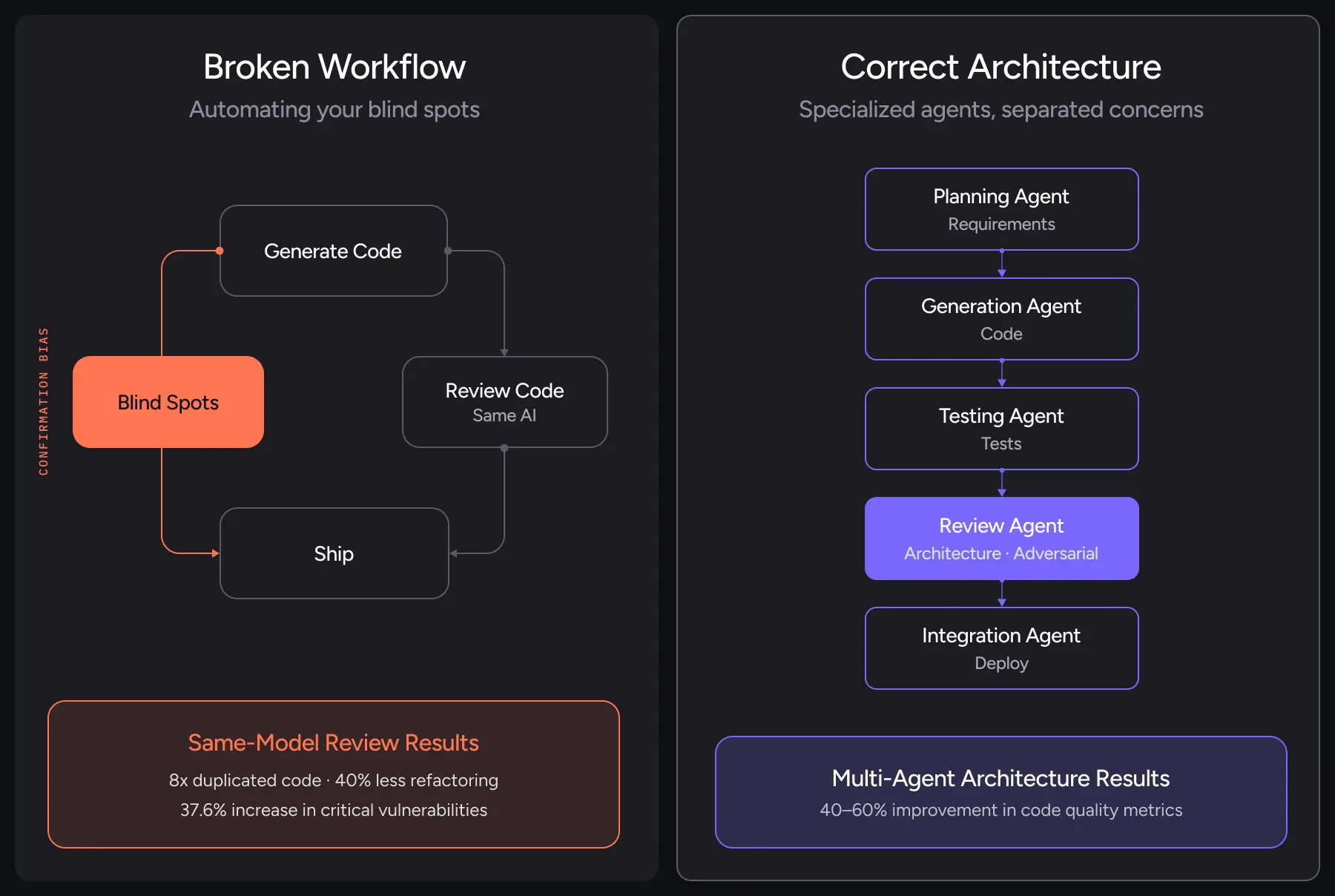
Remember when we learned that monolithic architectures don’t scale? The same principle applies here.
Different AI agents should handle different phases:
Generation Agent: Optimized for speed, syntax correctness, and pattern matching. Its job is to get from requirements to working code quickly.
Review Agent: Configured for adversarial thinking. No access to the original generation prompt. Different optimization targets. Its job is to find problems, not validate solutions.
Why this works: The review agent approaches the code with fresh context. No anchoring bias. No confirmation bias. Just clean analysis of whether the code actually solves the problem safely.
How Specialized Review Agents Actually Work
A review agent optimized for code quality needs a fundamentally different context architecture than a generation agent:
Purpose-built for adversarial thinking:
Review agents should be configured to find problems, not validate solutions. This means different prompting frameworks, different reasoning patterns, and different success metrics.
Deep context without generation bias:
Review agents need access to your codebase, test suites, and architectural patterns—but without being anchored to generated code. This is why context engines matter. They encode your code structurally, semantically, and with embeddings, turning raw code into knowledge the review agent can reason over independently.
Specialized tool access:
Generation agents need tools for file creation and modification. Review agents need tools for issue detection, multi-step analysis, and contextual comparison. Different tools for different cognitive modes.
Reasoning depth:
Review agents should use multi-step reasoning specifically designed to surface hidden insights. A generation agent optimized for speed won’t perform the iterative reflection needed to find security vulnerabilities or architectural flaws at an optimal level.
Separation of knowledge:
This is the most critical element: review agents should not have access to the original generation prompt or the generation agent’s intermediate outputs. This prevents anchoring and confirmation bias at the architectural level.
Real Results from Real Teams
Companies adopting this multi-agent approach are seeing 40-60% improvement in code quality metrics. Not from better models. From better architecture.
One enterprise client switched from single-agent to specialized agents and saw a 60% reduction in post-deployment bugs.
This isn’t marginal improvement. This is the difference between sustainable AI development and technical debt spiraling out of control.
What This Means for Your Team
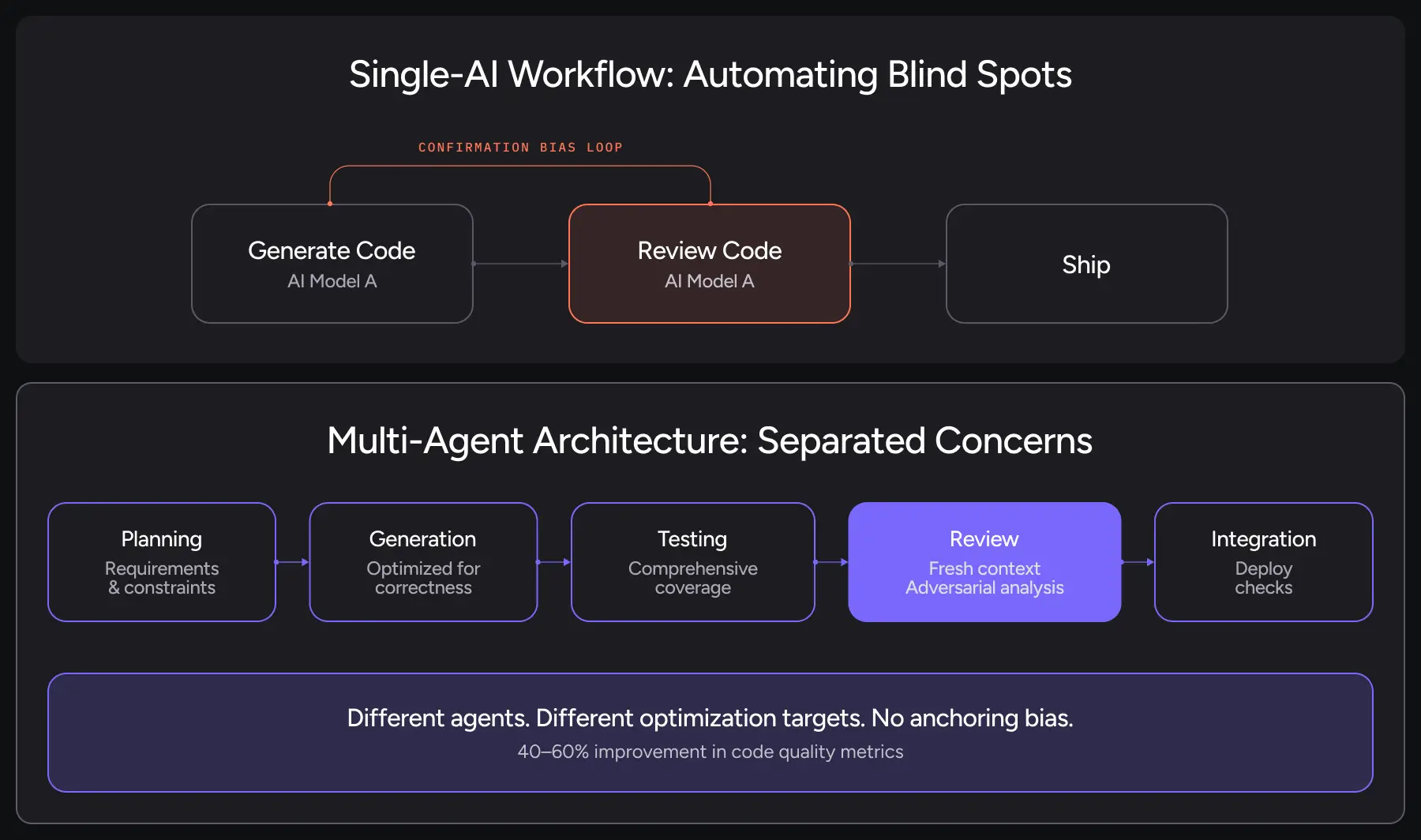
If your current workflow is:
- Generate code with AI
- Review with same AI
- Ship
You’re automating your blind spots. The correct architecture separates concerns:
- Planning agent analyzes requirements and constraints
- Generation agent writes code optimized for correctness
- Testing agent creates comprehensive test coverage
- Review agent performs adversarial analysis with fresh context
- Integration agent handles final deployment checks
This is prevention. Risk mitigation. Early detection.
The cost of a specialized review agent is negligible compared to the cost of production bugs that your generation system couldn’t see.
As AI-generated code becomes 30%, 50%, 70% of your codebase, this architectural flaw compounds. You’re not just shipping more code and doing it faster. You’re shipping more problems at a faster rate, too.
The teams that figure this out now – that stop asking one AI system to be great at two incompatible tasks – will have a massive advantage.
Because the future of sustainable AI development isn’t about better models. It’s about better architecture.
Your production systems depend on getting this right.
Key Takeaways
- Confirmation bias is structural: When the same model generates and reviews code, it cannot see its own blind spots
- Model bias compounds at scale: LLMs exhibit measurable cognitive biases that get reinforced when reviewing their own outputs
- Real costs are already visible: 69% of developers find vulnerabilities in AI code; 45% of samples fail basic security tests
- Specialized agents work: 40-60% improvements in code quality metrics from multi-agent architectures
- This is an architectural problem, not a model problem: Upgrading to a better base model won’t solve this if you’re still using the same system for generation and review


