Agentic RAG Explained: Building Smarter, Context-Aware AI Systems

TL;DR
- An industry study found 87% of enterprise RAG deployments fail to meet expected ROI, often due to challenges like fixed retrieval logic, static chunking, and difficulty handling unstructured or scattered data.
- Agentic RAG introduces autonomous agents that dynamically plan, adapt queries, switch tools, and iteratively retrieve relevant context until the task goal is met.
- Architectures like Single-Agent and Multi-Agent RAG enable flexible workflows, allowing agents to route queries intelligently or delegate tasks across specialized retrieval agents.
- Qodo’s Agentic RAG uses Model Context Protocol (MCP) tools to integrate with Git, code, files, and APIs, enabling multi-step reasoning, dynamic refactoring, and autonomous PR reviews.
- Unlike static pipelines, Qodo’s approach supports enterprise-scale control, reproducibility, and adaptability, which makes it ideal for debugging, multi-service orchestration, and high-stakes code reviews.
From what I’ve seen in production, most Retrieval-Augmented Generation (RAG) pipelines start strong in theory but break down quickly under real-world complexity. One industry analysis estimates that 87% of enterprise RAG deployments fail to deliver expected ROI, largely because of overly broad indexing, static retrieval paths, and evaluation methods that don’t reflect the actual task environment.
As a Technical Lead, I know how this happens, and I’ve come across this many times. I have used a standard RAG setup to resolve cross-service incidents by pulling data from Confluence docs, GitHub threads, and monitoring dashboards. But, even after retrieval, the system would pull irrelevant chunks, miss key log references, and ignore dependencies unless we manually tuned the index. The common thread across these failures is rigid retrieval logic that assumes clean, well-labelled, and consistently structured data.
After several failed experiences, I finally found the solution: autonomous decision-making with retrieval done by Agentic RAGs.
Instead of running a fixed retriever, it deploys agents that dynamically select what to query, how to query it, and when to stop. Retrieval becomes iterative and contextual. Retrieval stops being a one-shot API call and becomes a contextual, multi-step loop.
Traditional RAG assumes you can chunk once, run a vector search, and get relevant results. However, chunking, source selection, and query phrasing must adapt in real workflows based on the task and data.
Agentic RAG treats retrieval as an active process, where the agent has a goal, evaluates what it’s already found, and decides the next step. It can rephrase queries, switch sources, or stop once the context is sufficient.
In my case, I’ve used Qodo’s Agentic RAG to implement agentic flows that operate across git repos, files, PRs, and even terminal logs. Using Model Context Protocol (MCPs), I define what the agent is trying to retrieve, how it should approach the task, what fallback logic to use, and when it should stop.
In this post, I’ll explain how Agentic RAG works in practice, what makes it different from traditional RAGs, and how we can use Qodo’s Agentic RAG.
What is Agentic RAG?
Agentic RAG combines retrieval-augmented generation with autonomous decision-making. Unlike traditional RAG, where the retrieval process is fixed and executed in a single pass, Agentic RAG systems treat retrieval as a dynamic, iterative process driven by an agent with a specific goal. The agent plans how to search, adapts based on intermediate results, and stops only once enough context has been gathered.
Below is a diagram explaining how Agentic RAGs are formed:
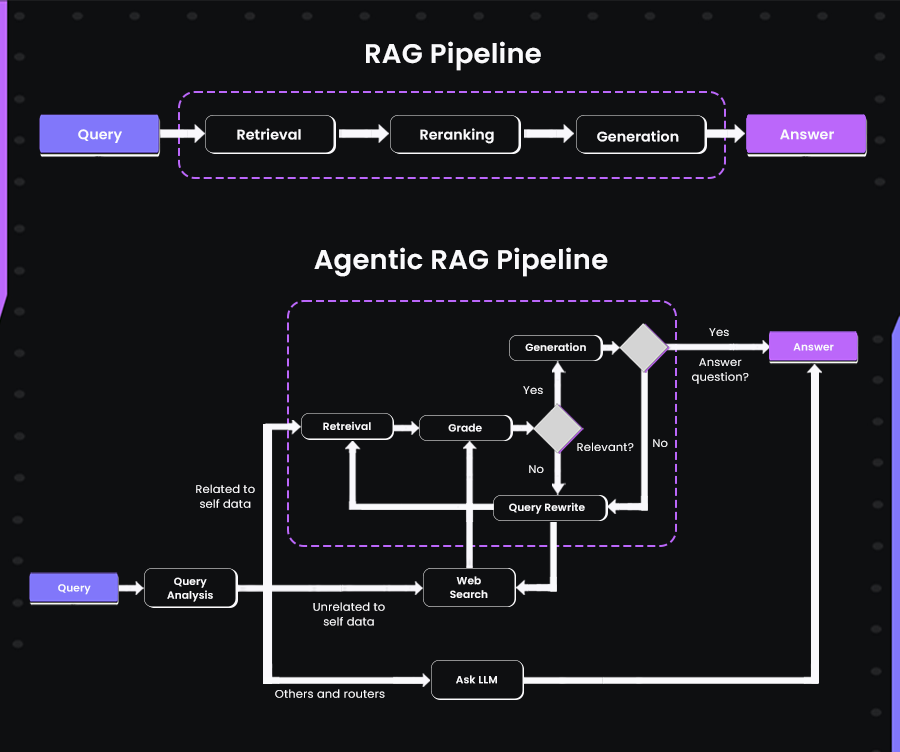
In the RAG pipeline (top), the process is linear: a query goes through retrieval, re-ranking, and generation, leading directly to an answer. It’s a fixed, one-pass system, whereas the Agentic RAG pipeline takes a flexible, loop-based approach. It starts by analyzing the query and deciding whether to search internal data or external sources.
Retrieved results are graded for relevance, and if they fall short, the agent rewrites the query and tries again. This cycle continues until enough useful context is gathered to generate a reliable answer.
Types of Agentic RAG Architectures
Agentic RAG systems can range from simple to highly modular, depending on how retrieval and reasoning responsibilities are distributed. At their core, they shift away from fixed one-shot retrieval toward a more dynamic system, where agents make decisions based on task goals and available tools. Below are two foundational patterns commonly used to structure Agentic RAG workflows.
Single-Agent RAG (Routing Agent)
The simplest form of an Agentic RAG system uses one agent acting as a decision-maker. Single-Agent RAGs are like smart routers that work like this: when a question comes in, the agent evaluates where the best information might live; it could query a vector store, search a document database, or even hit a live API like a company’s Slack channel or a search engine. The point isn’t just choosing from databases and tools that provide real-time or specialized context.
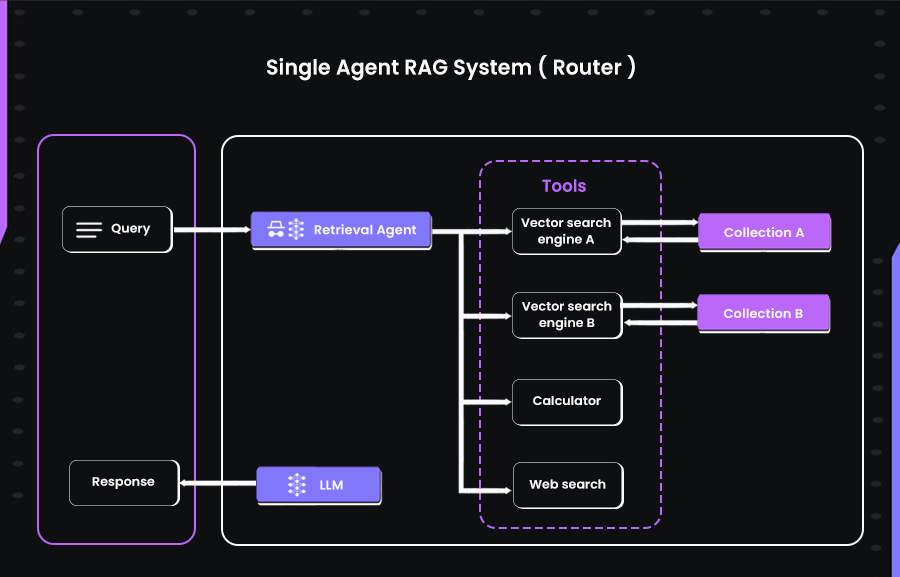
This model works well when there are just a few retrieval sources and lightweight coordination is enough. It’s still agentic because the agent makes the retrieval decision at runtime, not through hardcoded rules.
Multi-Agent RAG (Specialized Retrieval Agents)
In more complex setups, a single agent isn’t enough to handle the growing diversity of data and retrieval needs. Multi-agent systems solve this by distributing responsibilities. A lead agent handles the overall task and delegates subtasks to other agents, each specialized in accessing certain data or tools.
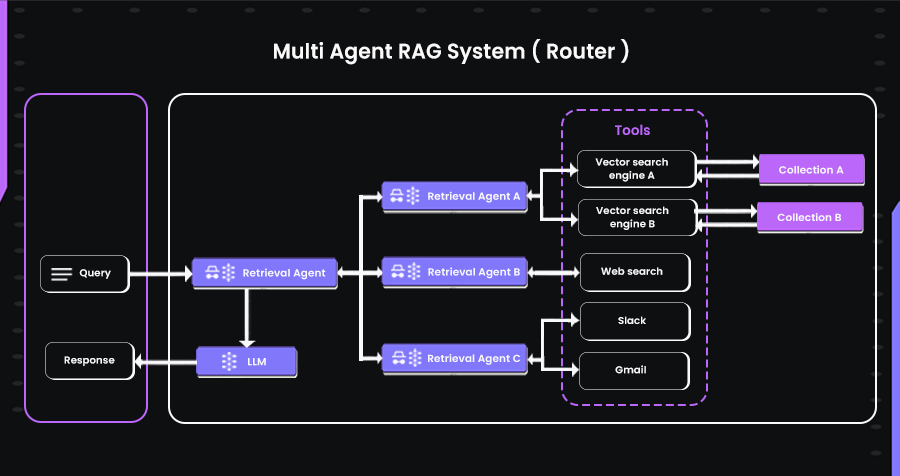
For example, one agent might focus on querying internal technical documentation, another might scan your email or chat history, and a third could pull relevant insights from the web. The primary agent coordinates the process, ensuring each sub-agent contributes context aligned with the original task.
This layered structure allows for modularity, flexibility, and better fault isolation. It’s especially useful when dealing with enterprise-scale systems or a mix of public, private, and semi-structured sources.
Agentic RAG vs Traditional RAG
As IBM notes, “Agentic RAG systems add AI agents to the RAG pipeline to increase adaptability and accuracy,” allowing LLMs to pull data from multiple sources and manage complex, multi-step workflows.
In other words, standard RAG is like a single-shot search against one dataset. In contrast, Agentic RAG treats the model as an active agent that can iteratively refine queries, consult different databases or tools, and revalidate information to solve harder tasks.
Below is a table for you so that you can understand the differences from different aspects:
| Aspect | Standard RAG | Agentic RAG |
| Data Sources | Single knowledge base (one vector store or DB) | Multiple sources and tools (vector DBs, web APIs, etc.) |
| Retrieval Process | One-shot: retrieve then generate | Iterative: agents decide when/how to retrieve and can re-query |
| External Tools | Typically none | Full tool usage (search, calculator, databases, APIs) |
| Planning & Logic | No query planning; static prompts | Agents plan, decompose tasks, and adapt strategy |
| Memory | Stateless (no shared memory between queries) | Short- and long-term memory to remember context and past results |
| Adaptability | Reactive (fixed retrieval logic) | Proactive and adaptive (can change approach mid-task) |
| Multimodal Capability | Usually text only | Can integrate text, images, audio via multimodal LLMs and tools |
| Complexity & Cost | Simpler, lower compute | More complex, higher cost (more tokens, compute) |
How Does Agentic Mode Work in Qodo?

We have seen what agentic RAGs are and how they differ from traditional RAGs or self-RAGs. Now, to better understand its impact on your codebase and deliverables, I have picked Qodo. The Agentic Mode in Qodo lets you run autonomous agents that can plan, reason, and act to achieve a goal, without relying on fixed prompts or manual control. Each agent is customizable. You define its objective, what tools it can access, and how it behaves across iterations.
Agents use a set of modular components called MCP tools (short for Model Context Protocol). These tools allow the agent to interact with your codebase, external APIs, project files, documentation, and the web. For example, it can call a /fetch tool to load recent PRs, a /review tool to check code quality, or a /search tool to query internal docs.
The combination of agents and MCP tools enables true agentic behavior. Instead of running one prompt at a time, Qodo agents can dynamically retrieve more context, revise their plan, and decide what to do next, just like a developer would.
To understand better, let us start with an example. I maintained a repository with multiple services: auth-service, billing-service, and notifications-service, and asked Qodo to add features to two services.
Coming to MCP integrations, Qodo has some in-built MCPs already integrated, such as Git, Code Navigation, File System, and Terminal. These are the basic ones – if you need more, you can easily integrate them via the ‘Add new MCP’ option or search for popular MCPs.
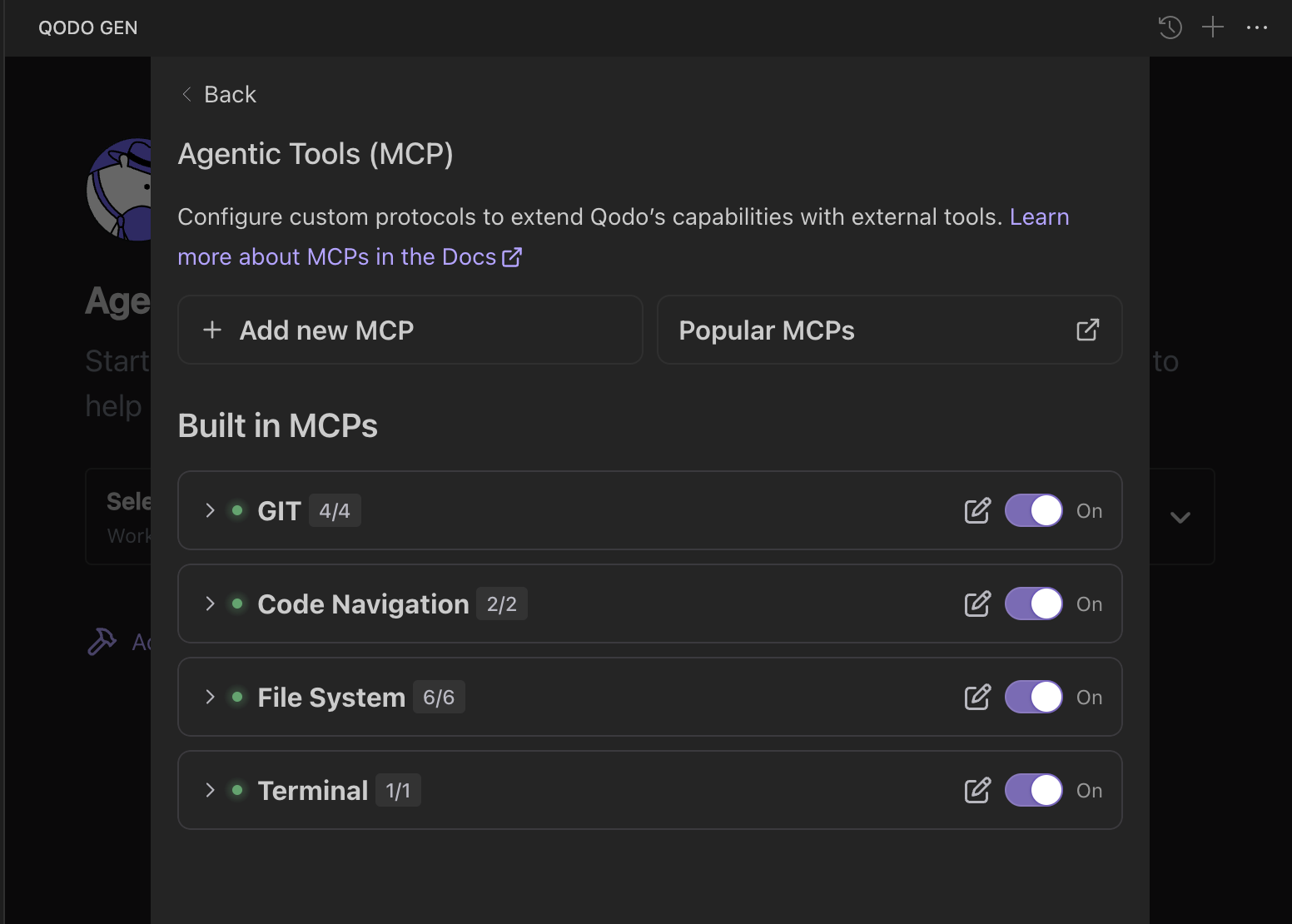
Qodo Gen supports two types of MCPs – Local MCPs and Remote MCPs. Local MCPs directly run on your environment without needing network calls. These are perfect for logic that is independent of any external APIs.
The other one, Remote MCPs, is preferred for Enterprise environments per the official Qodo docs. These run on external servers and interact with Qodo over HTTP. To configure a Remote MCP, supply the endpoint URL and, if needed, include custom HTTP headers, such as those used for authentication.
I am just following the built-in MCPs for demonstration. Using Git MCP, I will ask Qodo about the latest changes in my remote repository. Qodo’s Agentic RAG will then inspect the repository through the Git MCP.
It doesn’t just pull commit logs; it analyzes the structure of the codebase, change sets, and even traces file dependencies if needed. I asked it to fetch the most recent changes in the repo, and it listed all commit summaries across my services. Below is a snapshot of the same:
With all the core MCPs set up and services synced, I moved on to a more advanced task: orchestrating a multi-service refactor workflow using Qodo’s agentic execution layer. My goal was to generate refactor commits for auth-service and billing-service, while ensuring test integrity and clarity around what exactly changed.
So, I issued the instruction directly through Qodo Gen:
“Generate refactor commits across services auth-service and billing-service, explain changes, and ensure tests still pass.”
Qodo immediately understood the instruction in a multi-step, autonomous way. First, it created the testing layer for the billing service, writing both a requirements.txt file and a test file (test_billing.py). This ensured that any changes it made could be validated via pytest before being committed.
Here’s a snapshot:
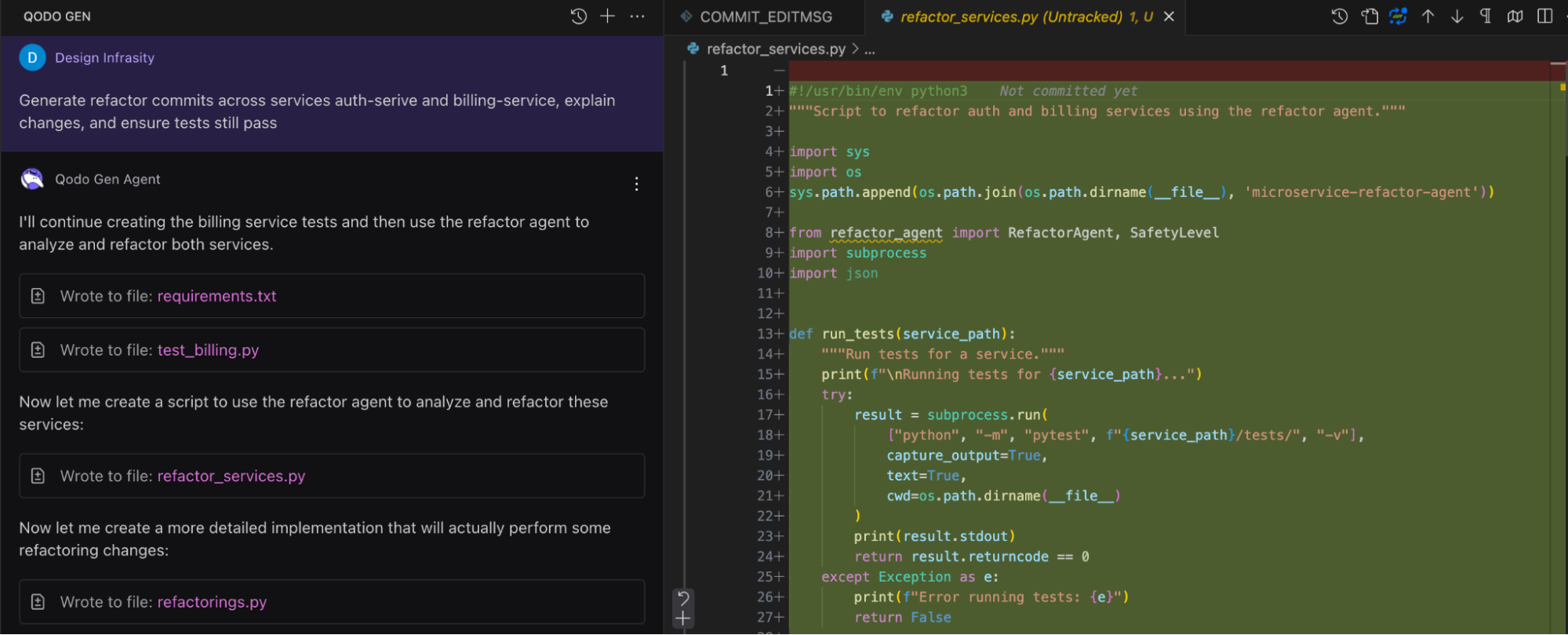
Next, it created a central script, refactor_services.py, which dynamically loads and runs a RefactorAgent. This script is particularly interesting. It imports the agent from a shared directory and defines a run_tests() method that leverages Python’s subprocess module to execute tests within the specific service paths.
After I have synced these changes to my feature branch and raised a PR against the main, Qodo auto-generated a PR Reviewer Guide with several key observations to help developers review easily, as seen in the image below:
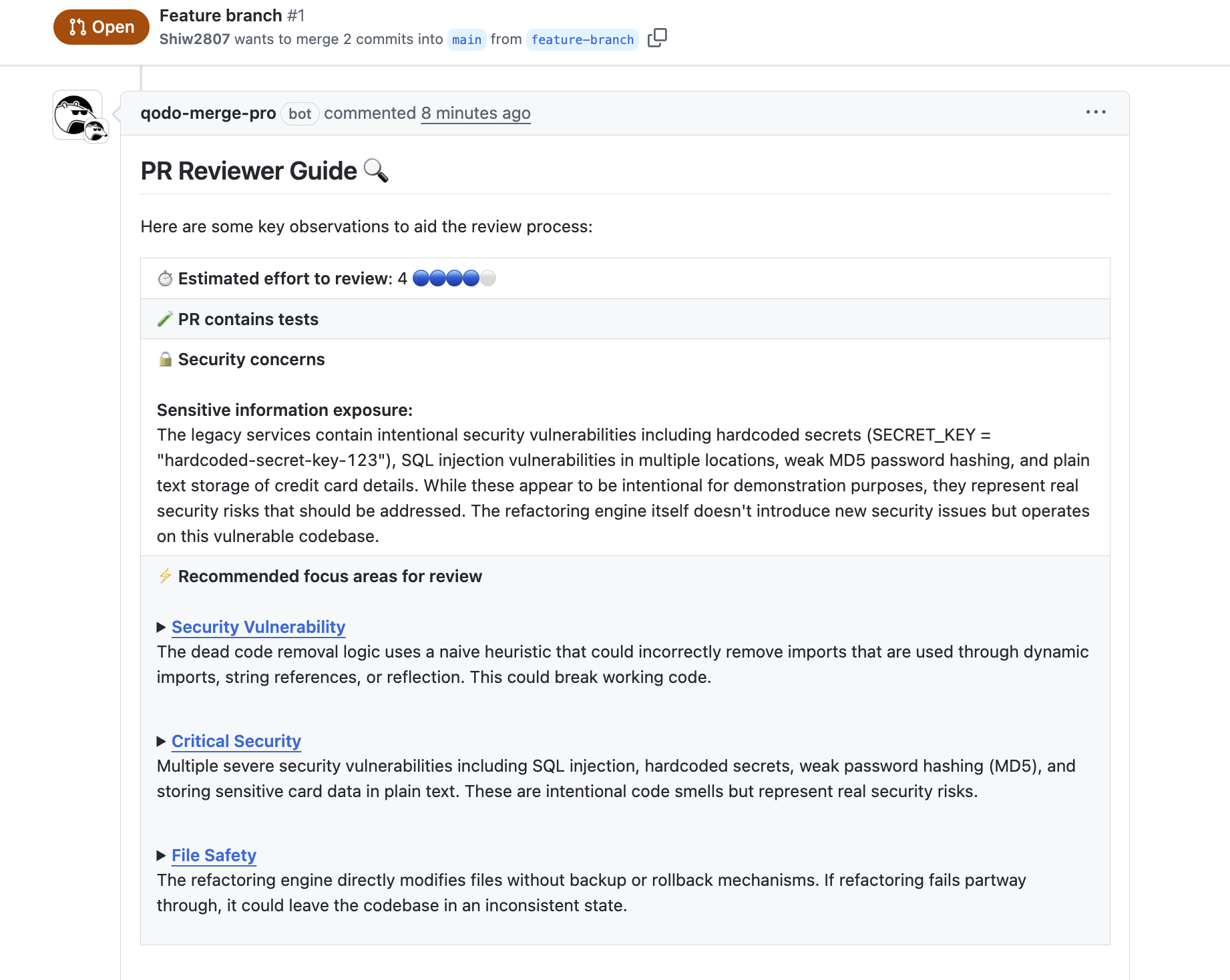
This included an estimated review effort (4/5), confirmation of test coverage, and early detection of security issues like hardcoded secrets (SECRET_KEY), MD5 hashing, and plaintext credit card storage. It also flagged potential false positives in dead code detection, especially for dynamically imported modules.
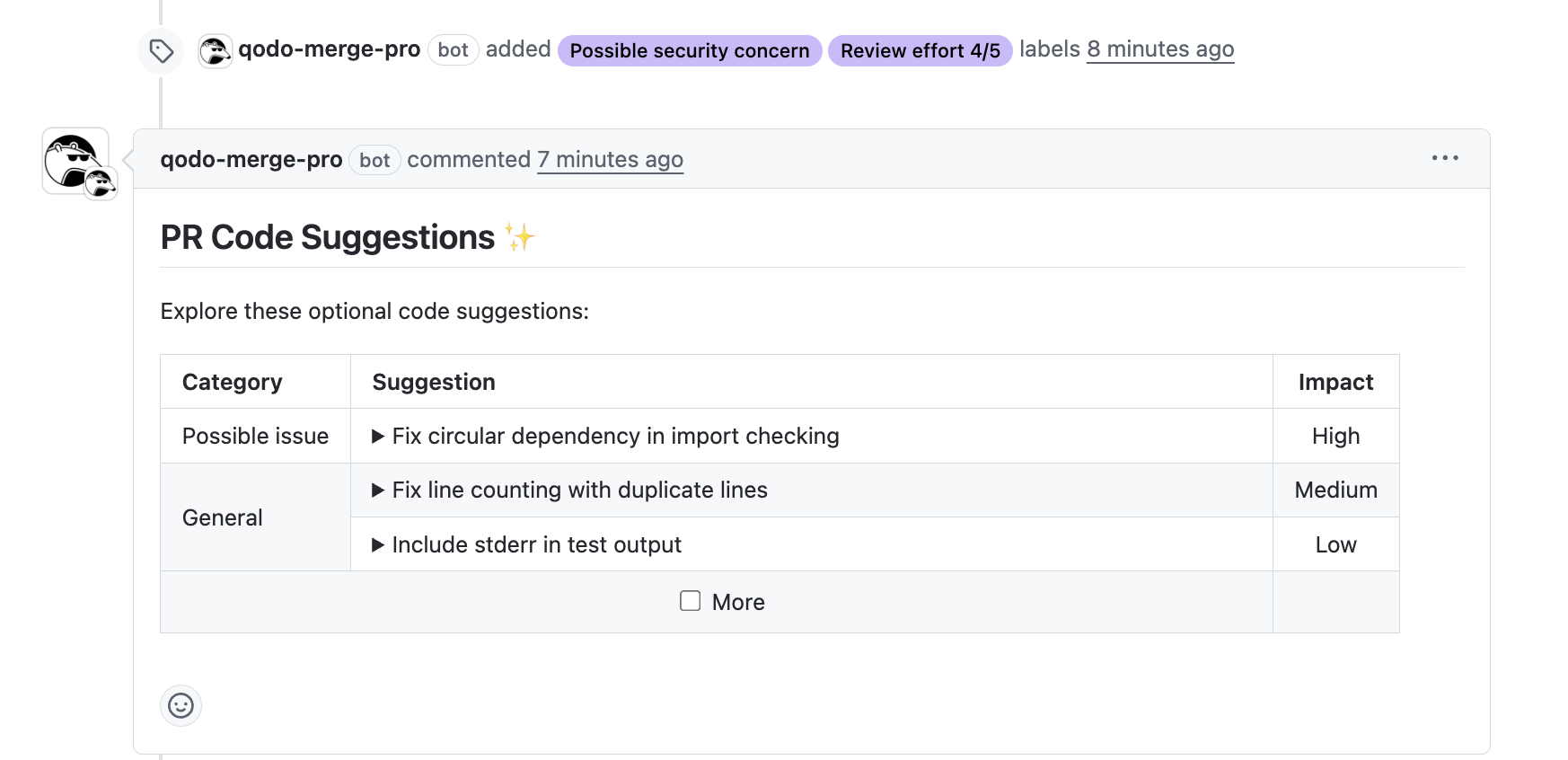
Finally, Qodo provided a diagrammatic walkthrough of the agentic refactor pipeline, mapping the interaction between the Demo Script, RefactorAgent, and RefactoringEngine. Here’s a snapshot of the diagram:
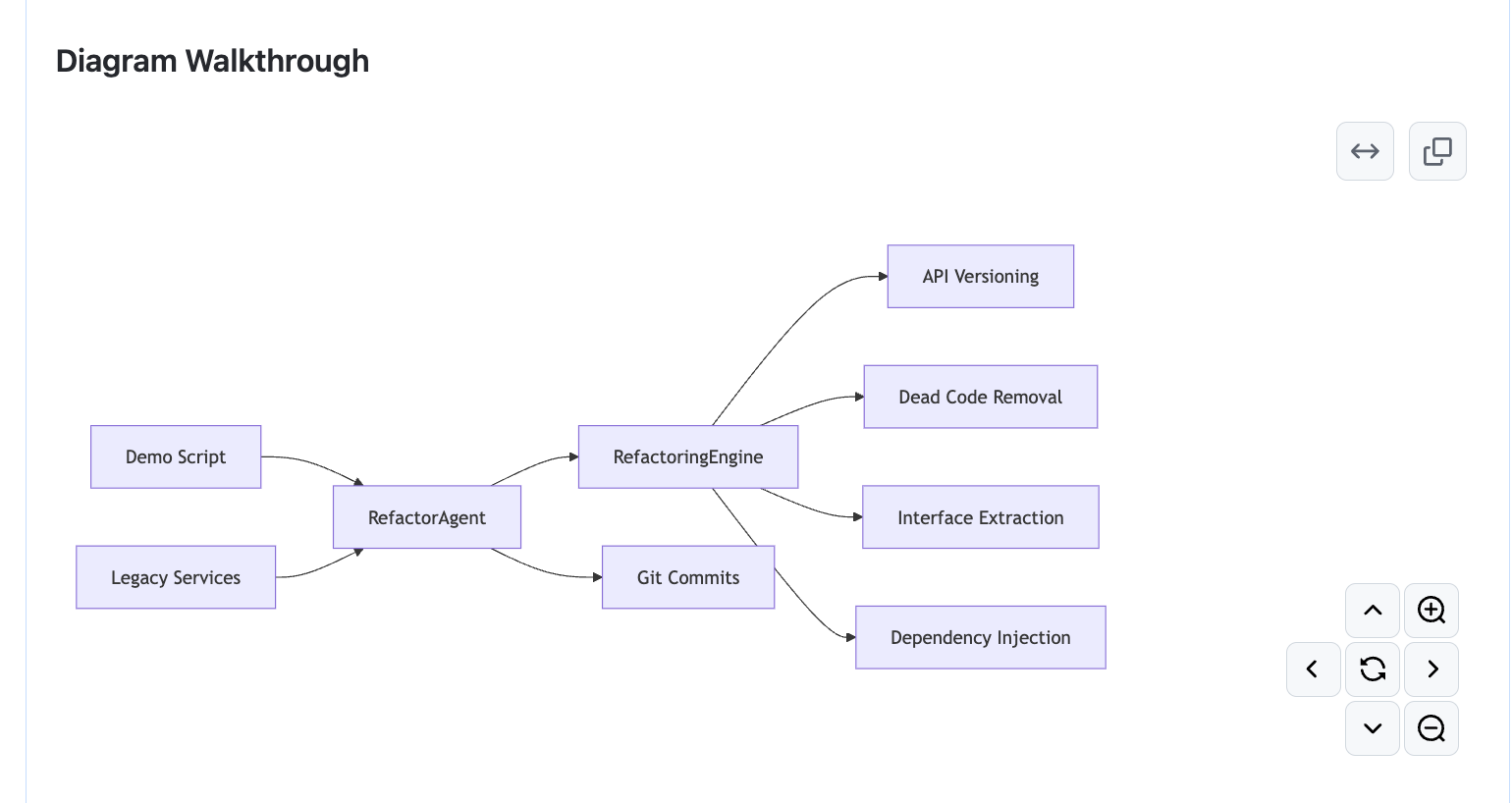
This included visual annotations of refactor stages like API versioning, dead code removal, and dependency injection.
Why I Prefer Qodo’s Agentic RAG For Enterprises?
I’ve worked with traditional RAG setups, where chunking strategies were hardcoded, and retrieval often relied on manually tuned prompts or fixed filters. Sometimes, RAG pipelines don’t adapt well when your data isn’t neatly organized or when your use cases and knowledge bases increase.
I found Qodo’s Agentic RAG to be very helpful here. Instead of treating retrieval as a fixed pre-step, it treats it as a dynamic process embedded into the agent’s reasoning. This means retrieval decisions evolve based on what the agent has seen, tried, and ruled out in earlier steps, making it well-suited for complex tasks like reviewing unfamiliar pull requests or debugging legacy code.
Also, I prefer Qodo for enterprises because of the level of control and context Qodo provides. You can configure the system with multiple RAG sources, like fine-tuned embeddings, structured references like design docs, or onboarding wiki. You can also specify how these should be prioritized.
For example, a Principal Engineer is often responsible for setting technical direction, maintaining architectural consistency, and reducing redundant developer effort. Their biggest friction points usually involve enforcing standards across growing teams and spending hours on manual reviews.
Qodo helps solve this by letting them encode review norms, set up scalable workflows using modular MCPs, and rely on agents to handle validation or refactoring based on those standards. Instead of chasing edge cases or enforcing style guides by hand, they can focus on higher-order design and strategic engineering calls.
Conclusion
After experimenting with different retrieval strategies and hitting the limits of traditional RAG systems, I’ve come to believe that Agentic RAG isn’t just a new feature; it’s a fundamental shift in building context-aware AI systems. It bridges the gap between static retrieval and real-world problem solving, where data is messy, context is scattered, and goals aren’t always clearly defined in a single prompt.
The flexibility and reasoning capability offered by agentic workflows bring a new level of adaptability that enterprise environments demand. It’s no longer about retrieving information, but about understanding how and why to retrieve it, and then acting on it with autonomy.
With Qodo’s implementation, I’ve seen this shift play out in theory and practice, debugging multi-service issues, automating refactor workflows, and even generating complete PR guides with test integrity checks.
FAQs
Which AI code assistants offer deep context search and refactoring support for large enterprises?
Most AI coding assistant are limited to snippet-level completions, but Qodo is designed to handle deep context across large, complex codebases. It can search across repositories, apply organizational standards, and provide structured refactoring suggestions that scale with enterprise needs.
What are good alternatives for basic AI context handling systems?
While lightweight copilots work for single-file tasks, enterprises need deeper context awareness. Qodo is a strong alternative because it embeds cross-repo intelligence, integrates with GitHub and CI/CD workflows, and adapts to team-specific best practices, something basic systems cannot provide.
How does LangGraph MCP (Model Context Protocol) relate to context management in assistants?
Protocols like MCP are important for structuring how models exchange context, but on their own, they don’t provide enterprise-ready workflows. Qodo takes the concept further by embedding context directly into IDEs, Git workflows, and PR reviews, giving teams a practical layer of context engineering built for production environments.
What are the current approaches to deep cross-repo autocomplete?
Some assistants attempt token-level scaling, but this often leads to performance trade-offs. Qodo uses a shared knowledge model that dynamically refreshes repo context, allowing autocomplete to draw from the latest code across services without overwhelming the developer with irrelevant suggestions.
How do AI assistants like Qodo build and refresh code context at scale?
Qodo continuously indexes repositories, development history, and team-wide conventions. As code changes, it refreshes this context dynamically, ensuring that reviews, autocomplete suggestions, and refactoring guidance reflect the most recent state of the project. This gives teams confidence that context-aware automation won’t fall out of sync with their codebase.
What are the best AI coding assistants for PHP that maintain context and consistency?
Many assistants lack a deep understanding of dynamic languages like PHP, especially in large frameworks. Qodo stands out by applying organization-wide context, handling dependencies across repos, and generating consistent refactoring or test suggestions for PHP projects at enterprise scale.
How does Retrieval-Augmented Generation (RAG) fit into context engineering?
RAG extends context engineering by combining repository indexing with on-demand retrieval from knowledge stores, documentation, and previous code history. For example, Qodo uses RAG-driven enrichment to surface relevant patterns and standards during code review or generation. We’ve explored this in more detail in our article on Context Engineering for Developers.


