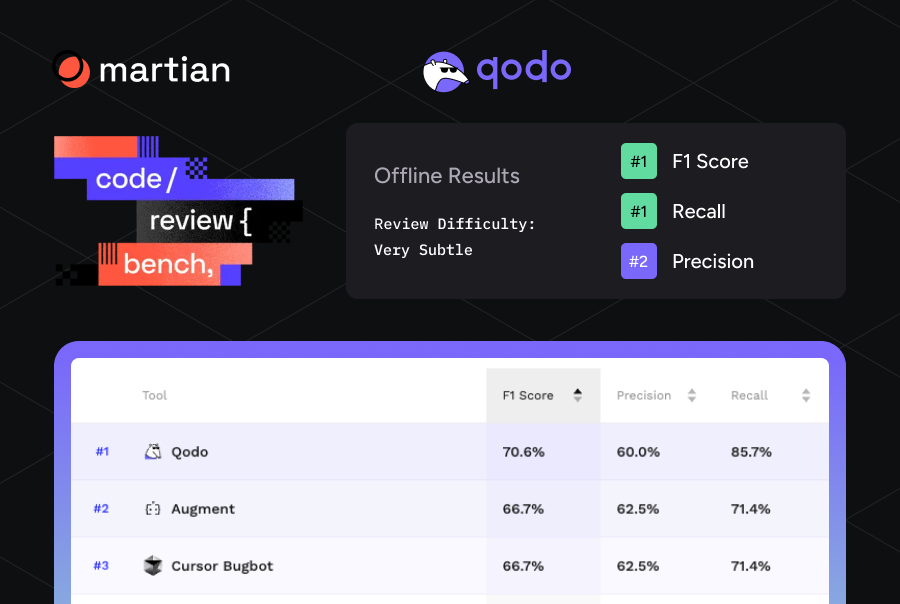
Understanding Context Windows: How It Shapes Performance and Enterprise Use Cases

TL;DR
- A context window defines how much text or code an LLM can attend to at once, acting as its working memory. Larger windows enable reasoning across entire documents or codebases without fragmenting input.
- Modern models now support massive windows: GPT-4 Turbo (128k), Claude 2.1 (200k), and Gemini 1.5 (1M). These expand possibilities but also increase compute, latency, and noise sensitivity.
- Limited windows previously forced teams to rely on prompt compression, Retrieval-Augmented Generation (RAG), and orchestration pipelines. While effective, these added overhead and complexity.
- Longer windows are powerful but imperfect. Issues like “lost in the middle,” irrelevant context distraction, and high compute costs still affect accuracy and scalability.
- Qodo tackles these challenges with structured pipelines, asymmetric context loading, inline context injection, and strong retrieval models, giving enterprises scalable and efficient context-aware workflows.
Large language models (LLMs) are dependent on various factors such as model size, training data quality and quantity, fine-tuning, etc, that define their performance in real-world cases, and the context window remains one of the most important ones. The context window defines the amount of information an LLM can “see” and reason over at once, essentially, its working memory. It represents the sequence length over which the model applies its self-attention mechanism.
In my experience with deploying LLMs to process enterprise-scale documents, context window size directly influences both performance and usability. A longer window enables the model to consider more context, for example, analyzing a full design spec or lengthy codebase in one shot, while a shorter window forces segmentation, often degrading coherence and increasing engineering overhead.
Because of this, context window size has become essential in performance tuning and usability planning. For prompt engineering, the window limits design complexity: to reference earlier content or chain logical steps, I need enough tokens to preserve critical context. When the context window is too short, even succinct prompts can cause dropped dependencies unless I explicitly carry forward summaries. This impacts accuracy and reliability in multi-step workflows.
From a team productivity standpoint, models with generous context windows reduce orchestration complexity. We spend less time implementing retrieval-augmented generation (RAG) pipelines or window slicing logic, focusing instead on core logic. However, longer windows increase compute and memory use, so balancing resource allocation and latency becomes a scaling concern.
One Reddit user in r/ExperiencedDevs asked how large context windows could reshape developer workflows. They noted:
Extended context capability empowers richer prompts, but doesn’t eliminate reasoning errors or hallucinations. It shifts where and how those errors manifest, and underscores the need for robust prompt validation and error handling even with long contexts.
In prompt engineering, a larger context window opens the door to chunk-free designs. I can pass entire modules or multi-tiered logic in one prompt, ensuring intra-prompt coherence and avoiding state leakage across window boundaries. This reduces complexity and increases prompt durability.
From an accuracy standpoint, long contexts allow the model to consider broader patterns or dependencies. “We can review this function’s doc, its implementation, and its usage in one shot”, which improves logical consistency. However, we must remain vigilant: even with plenty of context tokens, inaccuracies emerge if the prompt’s structure or signal-to-noise ratio is poor.
In this blog, we will cover everything from the aspects of context windows and its major challenges, and how tools like Qodo can help with enterprise use cases.
What is a Context Window?
Early systems like GPT-3 were limited to around 2,048 tokens, which meant they could only handle short snippets of text or isolated tasks. This was enough for basic Q&A or generating small paragraphs, but it quickly became inadequate for enterprise use cases such as analyzing long policy documents, reasoning over large codebases, or managing multi-step workflows.
Recent models have pushed these boundaries significantly. OpenAI’s GPT-4 Turbo supports up to 128k tokens, Anthropic’s Claude 2.1 extends to 200k tokens, and Google’s Gemini 1.5 has introduced context windows reaching 1 million tokens. These expanded limits allow models to handle far more information in a single prompt, enabling use cases like reviewing thousands of lines of source code at once or processing full research papers without breaking them into chunks.
Longer context windows matter because they reduce fragmentation and preserve continuity. When a model can process more data in one pass, it is less likely to lose important details, misinterpret instructions, or provide incomplete answers.
This capability supports practical use cases such as reviewing thousands of lines of source code in one go, performing multi-step agentic workflows, retrieving knowledge from large documents, maintaining conversation history in AI assistants, and ensuring compliance or security analysis considers all relevant files.
For enterprises, this translates into more accurate reasoning across complex workflows, better handling of domain-specific documents, and smoother integration of AI into development and decision-making processes.
How Context Windows Work in LLMs
In transformer-based architectures, the context window defines the maximum number of tokens the model attends to simultaneously during inference. Self-attention mechanisms compute pairwise relevance weights among all tokens in this window, enabling the model to understand dependencies across the sequence.
Here’s an image :
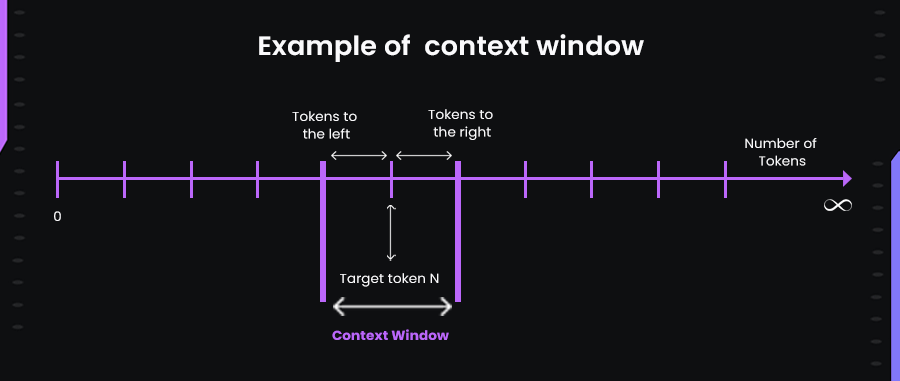
When the input exceeds the context limit, older tokens are discarded, the window effectively “slides” forward with the target token N, and attention no longer includes those earlier tokens. This can break coherence in reasoning if earlier inputs were vital.
Compute and Scaling Implications
The self-attention computation scales quadratically with the number of tokens, meaning doubling the token count requires roughly fourfold the compute effort. That growth impacts inference latency, memory usage, and cost, especially when serving enterprise-scale workflows with tight response time requirements
Why Do Models Have a Maximum Context Length?
The maximum length is not an arbitrary limitation. Models are trained on fixed input sizes, and every additional token adds computational cost. Memory and inference time increase sharply as context grows, which impacts both performance and infrastructure requirements. This is why early LLMs were designed with smaller context windows; they were faster, cheaper, and easier to deploy. Expanding context is possible, but it comes at a cost in performance, resource usage, and overall system design.
Enterprise Challenges with Limited Context
For enterprises, these limitations became significant hurdles. An insurance provider, for example, cannot reduce a 50-page policy document into a few thousand tokens without losing important details. Legal teams dealing with lengthy contracts faced similar roadblocks, often needing to break documents apart manually.
Manufacturers working with technical manuals or compliance reports struggled to fit the data into models that could only handle small fragments. In software engineering, the situation was even more pronounced; debugging large-scale systems required reasoning across multiple files, dependencies, and historical context, which small windows simply could not accommodate. Some other challenges included:
Quadratic Compute and Resource Overhead
Self-attention in transformers scales quadratically with context length, meaning doubling the token count can quadruple compute and memory usage. This rapidly increases inference latency and infrastructure costs, raising the bar for scalability and sustainability.
Positional Performance Degradation: “Lost in the Middle”
Empirical studies reveal a marked U-shaped performance curve where models attend more reliably to content at the beginning and end of long inputs, while context in the middle becomes noisy and less impactful, which researchers term the “lost in the middle” effect.
A recent analysis further refines this understanding: as inputs consume up to 50% of the model’s capacity, the lost-in-the-middle phenomenon peaks; beyond that, performance bias shifts toward recent content only. That doesn’t eliminate the issue, but reframes it.
Distractibility from Irrelevant Context
A longer window does not guarantee better focus. Including irrelevant or contradictory data can lead the model astray, exacerbating hallucination rather than preventing it. Key reasoning may be overshadowed by noisy context.
Security Risks: Expanded Attack Surface
Broader context means more opportunity for adversarial prompt attacks. Malicious instructions can be buried deeper in the input, complicating detection and mitigation. This “attack surface expansion” increases the risk of unintended behaviors or toxic outputs.
Prompt Stuffing Isn’t Always Efficient
Dumping everything into the prompt (“prompt stuffing”) may seem convenient, but it can waste compute cycles on irrelevant data. IBM researchers noted this is akin to performing a costly search (like “Command+F”) over the entire context, reducing efficiency.
Workarounds Before Longer Context Windows
To overcome these constraints, teams built clever workarounds. Prompt engineering became a common practice, where developers compressed instructions into a more efficient language to save tokens.
Retrieval-Augmented Generation (RAG) was one of the best ways to selectively pull only the most relevant passages into the context window, reducing noise while maximizing utility. Fine-tuning smaller models for specialized tasks provided another avenue, although it required ongoing maintenance.
Some enterprises even adopted prompt orchestration strategies, breaking workloads into smaller queries and stitching results together. These techniques allowed teams to operate within strict limits, but they also introduced complexity and overhead that made scaling difficult. This is where I find platforms like Qodo helpful, which provide enterprises with a more streamlined and scalable way to address context window challenges without the heavy lifting of fragmented workarounds.
How Qodo Overcomes Context Window Challenges
Qodo is designed to help enterprises work beyond the limits of fixed context windows. Instead of relying on manual prompt compression or fragmented orchestration, Qodo builds structured pipelines that supply LLMs with only the most relevant context at the right time. Qodo uses Retrieval-Augmented Generation (RAG) as a foundation for its context engineering. RAG ensures that model responses are grounded in actual code repositories, improving accuracy without embedding outdated training data.
Avoiding Information Overload and Token Waste
LLM performance degrades when supplied with excessive or irrelevant context. Qodo addresses this by using asymmetric and dynamic context strategies within Qodo Merge. The system provides more context preceding a code change than following it, and adjusts the context size based on logical structure, such as including the enclosing function or class, rather than fixed line counts. This approach ensures relevance while controlling token usage.
Controlling Compute Cost and Token Limits
By dynamically adjusting context to relevant code structures and using asymmetric context loads, Qodo prevents unnecessary token bloat. For example, while refactoring a large microservices backend with over a million lines of code spread across six repositories, I asked Qodo Merge to suggest updates for a deprecated API function.
Instead of sending the entire file or repository to the LLM, Qodo provided only the relevant class, method calls, and related dependency references. This reduced token usage by over 70%, allowing the agent to return actionable suggestions in seconds without increasing inference costs.
Eliminating Irrelevant or Distracting Content
Qodo Gen Chat is one of the best AI tools for coding as it enables inline context injection, allowing developers to explicitly add only relevant code segments, such as folders, files, classes, functions, or methods, by typing @ in the chat. This control ensures the model operates with high-signal context only.
Avoiding Fragmented Context Across Codebase
For broader contextual understanding, Qodo supports adding entire files, folders, or even the full project as context. This capability allows the model to access a wide context without manual retrieval or chunking.
While refactoring a multi-repo microservices system for a payment processing platform, I needed to update a shared PaymentValidator module that was used across four repositories: auth-service, payment-service, billing-service, and notification-service. Instead of manually collecting relevant files or splitting the code into chunks, I instructed Qodo to include the entire module directory and related service folders as context.
The agent quickly understood inter-repo dependencies, identified where schema validations differed, and suggested coordinated updates across all services. This avoided context fragmentation and prevented potential runtime mismatches, which would have been costly to debug manually.
Improving Retrieval Precision with Embeddings
Qodo uses the Qodo-Embed-1 family of embedding models to make code retrieval more accurate. These embeddings convert code into numerical vectors that capture its meaning, allowing the system to find relevant functions or modules even when keywords differ.
In benchmark tests using the CoIR framework, the 1.5B model achieved a score of 68.53, while the larger 7B model reached 71.5. Both outperform general-purpose or larger embedding models ( models that have more parameters, basically, bigger neural networks) A model’s parameter count (like 1.5B or 7B) determines its capacity to understand patterns, relationships, and subtle semantics in the input data. This ensures that the retrieved context is precise and reduces the chance of hallucinations during multi-step workflows.
Supporting Multiple Models with Large Context Windows
Beyond its own context-aware pipelines, Qodo supports a range of leading foundation models, including Claude Opus and others that provide extended context windows. This flexibility allows teams to combine Qodo’s structured retrieval and orchestration with models capable of handling extremely large inputs, making the workflow both precise and scalable.
Hands On: Qodo’s Context Window Example
To see how Qodo helps with context management, let’s walk through a real workflow. Suppose you are working in a large Python microservices codebase where you want to refactor authentication logic spread across multiple files. We start with a backend service that ingests log data, normalizes it, and exposes analytics via REST.
“Generate a Python microservice with FastAPI that:
– Ingests JSON logs over a POST endpoint
– Normalizes log fields into a consistent schema
– Stores data in SQLite
– Provides a /stats endpoint returning error counts per service”
Qodo creates a project with main.py containing FastAPI endpoints, database.py handling SQLite models and queries, and schemas.py for consistent log structures.
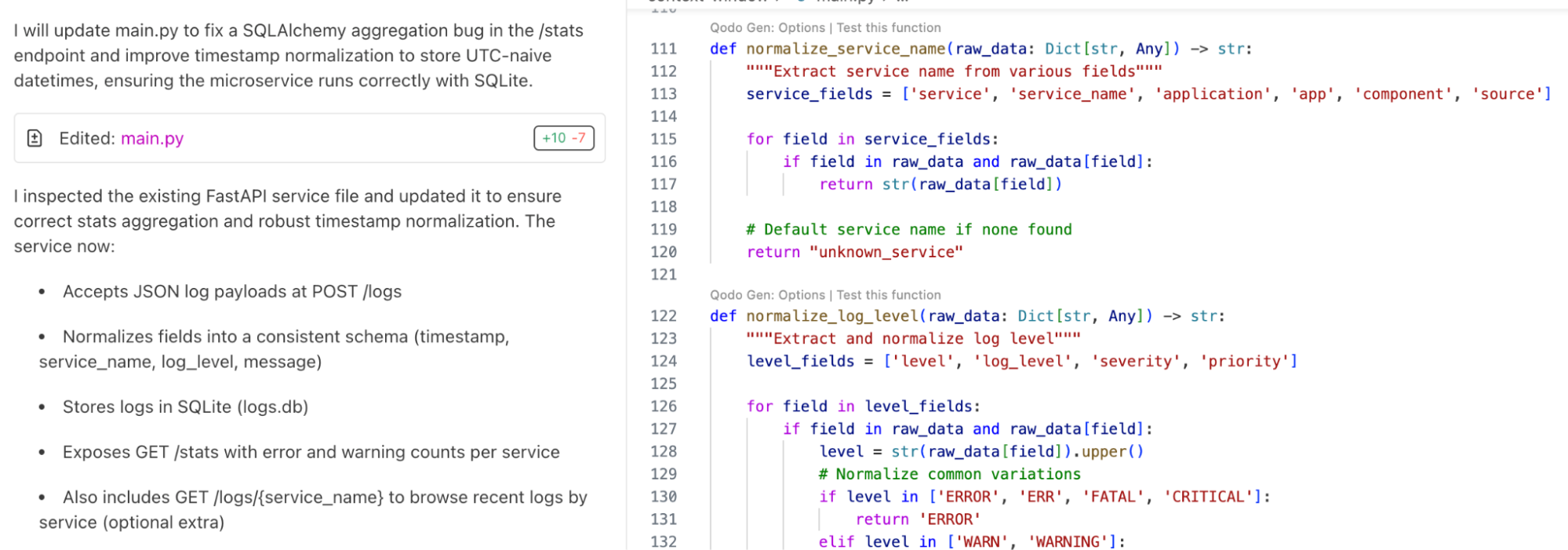
This generation respects modularity out of the box, splitting concerns across files so that scaling or refactoring later does not exceed a single file’s context length.
Now, let’s say we want to refine the log schema to include a hostname field for better traceability. Normally, this change would require editing multiple files: request models, database schema, and queries. With Qodo’s context window management, we can handle this seamlessly.
“Update the FastAPI log service to add a ‘hostname’ field to logs:
– Update schema
– Adjust database model
– Modify POST /logs and GET /stats endpoints accordingly.”
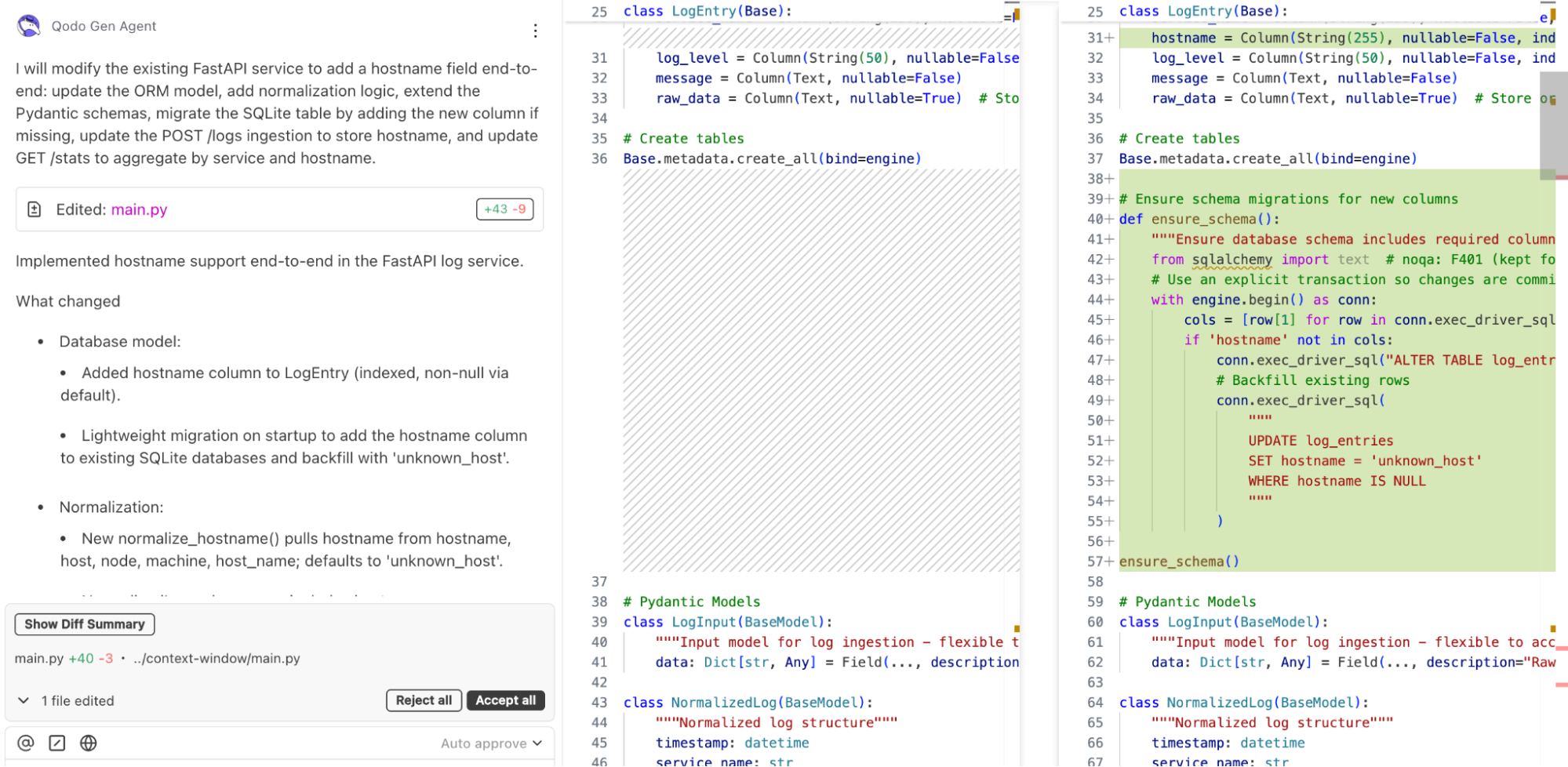
Instead of losing track across multiple files, Qodo automatically retrieves and enriches the relevant context and finds all schema definitions referencing logs. It identifies SQLAlchemy table definitions that need updates and surfaces relevant code fragments in the generation context.
This is where I think Qodo’s approach is helpful in regard to context windows. In my experience, most tools try to load as much of the repository as possible into the model’s context, which quickly hits the ceiling and reduces accuracy. Qodo solves this by dynamically scoping context to the task at hand.
When you request a schema update, it gathers only the relevant files, models, and commit history tied to that schema. When you review code in auth/, it enriches the context with the authentication layer alone, not unrelated services. By narrowing the scope and enriching it with targeted fragments, Qodo makes context windows a strength rather than a limitation.
Moreover, when I deal with code spread across multiple microservices, I often hit the limits of context windows during reviews. The bigger the system gets, the harder it becomes to keep everything in scope. That’s where Qodo Merge helps me keep the workflow intact.
Suppose we now want to refactor authentication logic spread across several services (auth middleware, session handling, and token validation).
With Qodo Merge, we can run:
qodo merge /review auth/
Here’s a snapshot of the review given by Qodo Merge:
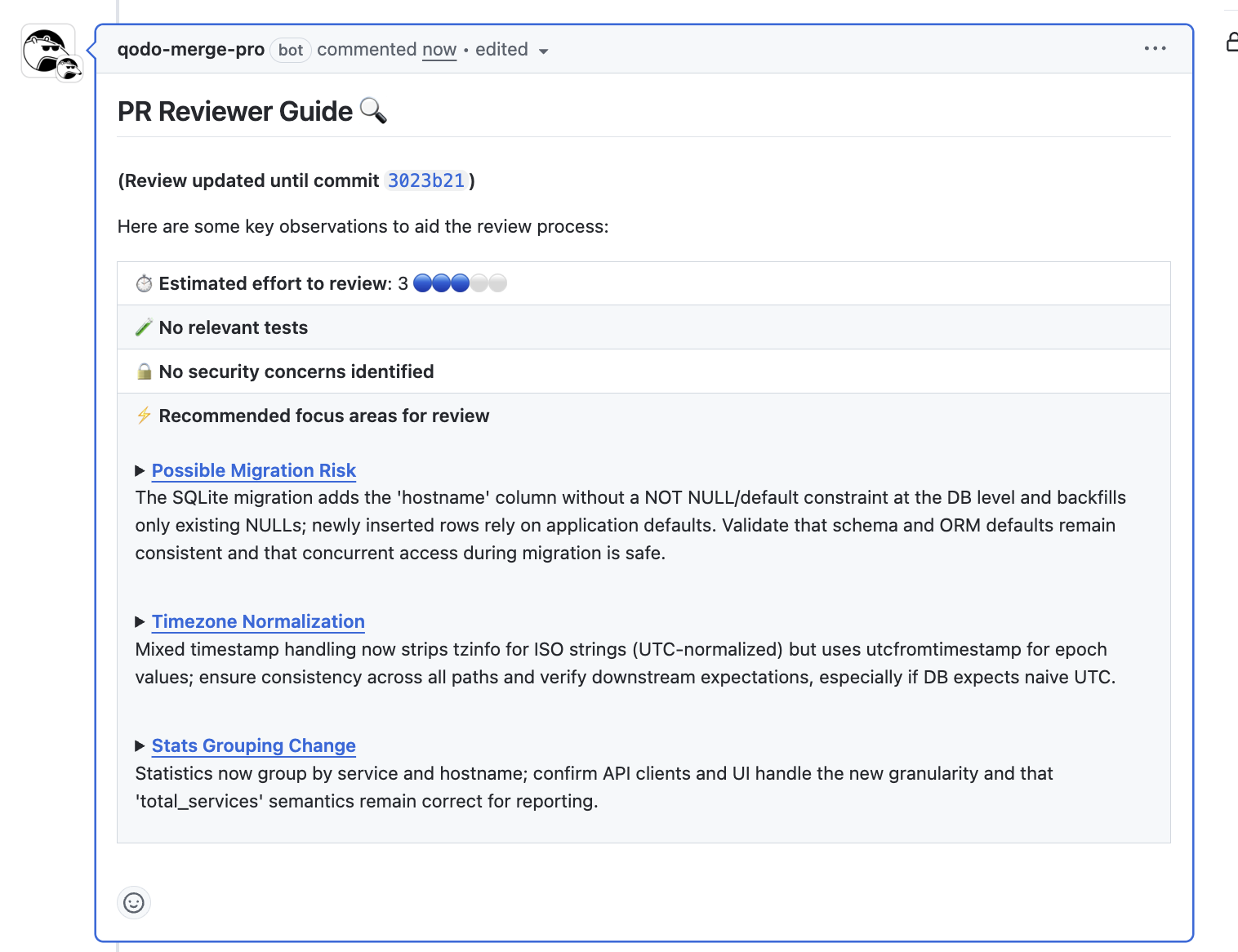
This pulls in only the relevant files from the auth/ directory, enriching the context with prior commit history, and runs automated review suggestions. Unlike generic LLM code review tools, Qodo does not try to stuff the entire repo into the context. It intelligently scopes context, ensuring reviews remain precise without hitting length or focus limits.
In traditional workflows, making schema-wide changes or reviewing distributed codebases often exceeds the maximum context window of even large models. This AI code generator’s context enrichment pipeline solves this by dynamically fetching only the relevant files, schema definitions, and commit history. The result is a workflow where large-scale edits, refactors, or reviews remain efficient without running into context cut-offs.
Conclusion
Context windows define the boundaries of how large language models reason, and they shape nearly every enterprise use case. As models scale to hundreds of thousands or even millions of tokens, they unlock richer workflows such as full-codebase reasoning, end-to-end policy analysis, and multi-step orchestration without constant context fragmentation. Yet, longer windows introduce new compromises in cost, latency, and attention.
In practice, enterprises can’t rely solely on context length. Careful context engineering, retrieval pipelines, and workload-aware orchestration remain essential. That’s why I really find Qodo to be helpful, especially for enterprise solutions. It follows an approach of structured context pipelines with retrieval precision, asymmetric context loading, and inline developer control. Qodo reduces token waste and improves reasoning reliability. Teams no longer need to choose between short-window hacks and inefficient prompt stuffing; they gain a balanced system designed for scale.
FAQs
How do AI Assistants like Qodo Manage and Refresh Code Context at Scale?
Qodo continuously builds a shared understanding of the codebase by indexing repositories, development history, and team-wide standards. As the code evolves, it refreshes context dynamically, ensuring that suggestions, reviews, and generated code are aligned with the latest state of the project. This allows teams to work confidently across large and fast-changing codebases without losing consistency.
How does Qodo Support Multi Language or Monorepo Projects?
Qodo is built to operate across repositories that use multiple programming languages. It recognizes shared conventions and project structures, ensuring that rules are applied consistently across services within a monorepo or mixed-language environment.
Why is Context so Important for Enterprise Teams?
In large organizations, frequent tool switching leads to productivity loss and developer fatigue. Qodo keeps workflows centralized across stacks and services, allowing teams to stay in context, maintain momentum, and deliver high-quality code at scale.
Why does Reducing Context Switching Matter for Enterprise Teams?
At enterprise scale, even small delays add up. Constantly moving between tools slows teams down, increases fatigue, and complicates onboarding. By unifying workflows, Qodo helps teams save time, reduce errors, and stay focused on complex projects.
How Does Qodo Improve Daily Work for Individual Developers?
Developers spend less time searching through documentation or waiting for feedback loops. With Qodo, testing, code review, and documentation insights are centralized, helping them stay in flow, ship faster, and reduce the mental strain of constant context shifts.
Can Qodo Adapt to Different Team Processes?
Yes. Qodo integrates with existing GitHub and CI/CD workflows, so teams don’t need to change how they work. It removes unnecessary friction while fitting into established processes, giving teams a smoother and more efficient developer experience.