Contextual Retrieval: How Code Intelligence Understands Your Codebase
TLDR;
- Every developer knows the pain of spending hours tracing logic through a maze of files just to understand one bug. Contextual retrieval solves that by connecting code, commits, and configs into one coherent view, so you see why something happens, not just where. The result is faster debugging and better code quality through consistent visibility across the codebase.
- Traditional search shows you keywords; contextual retrieval shows you reasoning. By combining semantic, architectural, and temporal layers, it transforms scattered fragments into a complete story your AI (and you) can actually follow.
- In my codebase demo, Qodo’s contextual retrieval mapped dependencies between PaymentService and RefundService, uncovering a stale cache bug that standard search missed entirely. It even traced committed history to show when and why the issue began.
- For large teams, contextual retrieval acts like shared memory. It bridges knowledge silos by linking code, docs, and commit intent, so reviews, debugging, and onboarding feel less like detective work and more like collaboration.
- With MCP-driven systems like Qodo, contextual retrieval turns understanding into action. It surfaces relevant methods, suggests precise fixes in pull requests, and makes the path from detection to resolution fast, traceable, and intelligent.
- Contextual retrieval redefines how developers work with complex systems by enabling deeper understanding of code behavior. It speeds up debugging, streamlines reviews, and improves decision-making with precise, context-aware insights.
In every enterprise codebase I’ve worked on, the real bottleneck isn’t writing code, it’s understanding it. According to a LinkedIn poll by JetBrains, nearly half of the 2,500 respondents said that understanding code is the most time-consuming part of their workflow. That aligns with my own experience. Most of my time in large, modular codebases goes into figuring out where logic resides, which dependencies I might break, and why a past fix was implemented in a particular way.
As a Developer Relations Lead, I recently faced this challenge while debugging a cache invalidation issue in a distributed service. The bug seemed simple: data wasn’t refreshing after updates. But the root cause was hidden three layers deep, an old patch had silently restored stale data from Redis during retries. Tracking it down required hours of tracing, reviewing commit history, and jumping between repositories.
This is exactly the kind of problem contextual retrieval is designed to solve. Contextual retrieval connects fragments of logic across services, test cases, commits, and documentation, creating a coherent view of why the system behaves a certain way. It eliminates the need to manually trace or reconstruct the chain of reasoning yourself.
Effective retrieval focuses on keeping the logical structure and relationships in the code intact. In this blog, I’ll walk through how contextual retrieval works in real engineering environments, the traits I look for in a context-aware system, and how I applied it to my own codebase using Qodo’s MCP (Model Context Protocol). For teams working with large repositories or multi-service architectures, this approach can simplify development, lower down code review times, and improve cross-team clarity.
What Is Contextual Retrieval?
Every developer knows the frustration of losing track of how different parts of a codebase connect while debugging or reviewing code. Whether switching branches, scanning commits, or referencing internal documentation, it’s the surrounding information that helps you understand why a piece of code exists, how it interacts with other modules, and what might break if you make a change.
Imagine you’re working on a large Node.js + Go microservices application where user authentication occasionally fails. You open the auth-service repository and look at this function. At first glance, the logic seems fine — but something feels off. You start digging.
Git blame shows this function was added six months ago by another engineer.
Commit message: “temporary fix for partner SSO.”
You open that pull request and find a detailed discussion about an edge case where tokens could be issued by multiple providers. Then you check Confluence, where an architecture document explains that the ValidateToken method was meant to delegate validation to the newer identity-service, but the migration was postponed.
Now, here’s where contextual retrieval changes everything. Instead of manually navigating through Git history, PR threads, and docs, a contextual retrieval system (powered by embeddings or retrieval-augmented generation) automatically brings this context to you.
For example, if you ask:
“Why does ValidateToken not use identity-service yet?”
The system retrieves:
- The original PR discussion where engineers agreed to delay the migration.
- The design document outlining identity-service’s intended role.
- Related Slack messages referencing the temporary fix.
- A commit diff showing a previous attempt that broke partner logins.
This transforms your understanding from isolated code fragments to a connected narrative, showing not just what the code does, but why it exists in its current form.
In the next sections, we’ll look at what contextual retrieval actually means in software engineering, how it’s different from plain search, and why it’s becoming essential for teams building with AI-assisted development tools.
The Core Idea Behind Contextual Retrieval
Contextual retrieval refers to the process of fetching relevant code, documentation, and metadata around a query so that the AI can reason in the same context as a developer. It changes AI behavior from producing isolated guesses to providing responses grounded in the actual structure, logic, and relationships within the project.
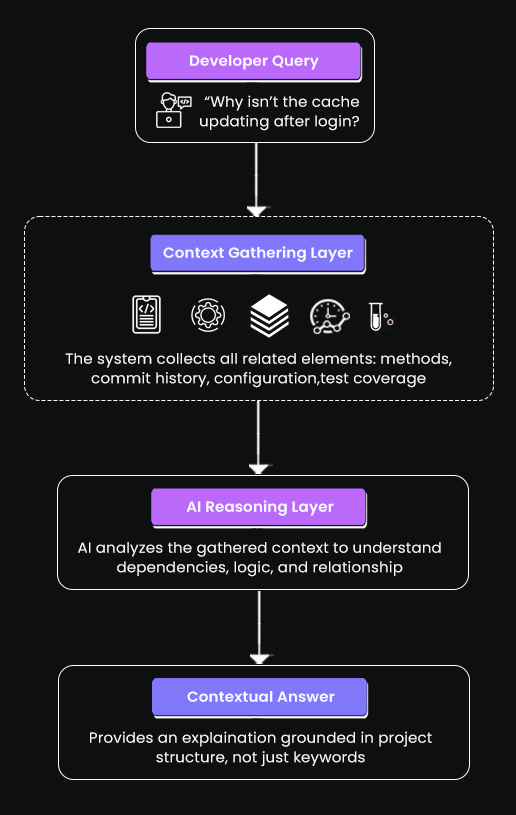
In simple terms, when a developer asks a question such as, “Why isn’t the cache updating after login?”, the system does more than locate keywords. It gathers connected elements that explain why something is happening, from method definitions to commit history, configuration, and test coverage.
A Real Example from My Workflow
While investigating a caching issue in a microservice-based authentication service, I used Qodo to retrieve the context around a failed cache update. A basic search returned a large set of unrelated results containing the word “cache.” Contextual retrieval, however, provided a focused and meaningful view.
It automatically fetched the following:
- The method in auth_service/cache_handler.py responsible for cache refresh
- A related commit message describing a change in the retry mechanism
- The YAML configuration that defined cache expiration rules
- The associated test case where a failed assertion matched the reported issue
That example is context-aware because it doesn’t just return files or lines matching the keyword “cache.” Instead, it retrieves related and relevant information from multiple sources that share contextual relationships with the issue. Seeing these results together explained how a recent patch had changed the invalidation sequence. I was able to trace the issue directly to a retry handler restoring stale data. Let’s refer to the overall architecture of contextual retrieval to understand its working:
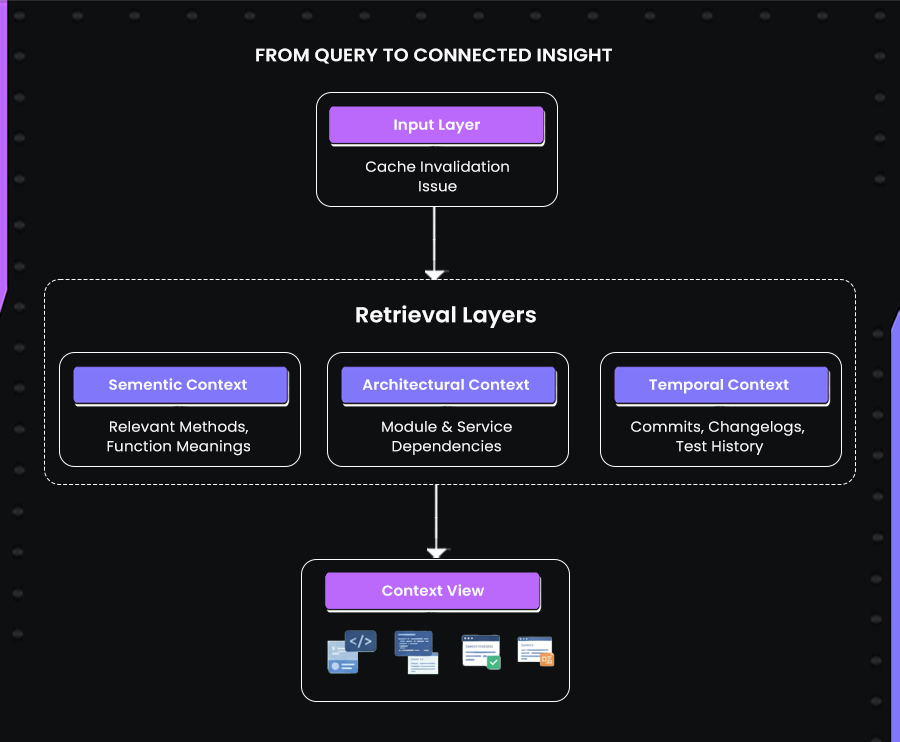
The image illustrates how AI-driven contextual retrieval converts a simple developer query into a connected, multi-dimensional understanding of the codebase.
- It begins at the Input Layer, where a developer enters a query such as “cache invalidation issue.”
- Instead of running a plain keyword search, the system activates several Retrieval Layers to interpret the query intelligently.
- The Semantic Context Layer identifies relevant methods, variables, and function meanings, helping the system understand the intent behind the query.
- The Architectural Context Layer maps module and service dependencies, showing how the issue interacts across different components.
- The Temporal Context Layer traces commits, changelogs, and test history to reveal when and how the issue evolved.
- These layers combine to form a unified Context View that merges semantic, architectural, and historical insights.
- This connected view allows developers to see all related elements in one place, enabling AI systems to reason with full project awareness.
This infographic visually explains how deep retrieval connects information across multiple dimensions, helping developers see how each layer contributes to accurate and context-aware assistance.
Shallow Search vs Deep Retrieval
Traditional search functions such as grep or basic text search work on surface-level matching. They scan files for exact keywords or string patterns and return every line or file that contains those terms. This approach works for small projects or quick lookups but quickly loses value in larger, service-oriented systems where function names and variable terms repeat across modules.
Shallow search lacks awareness of relationships. It cannot distinguish between a cache reference in an unrelated test helper and one inside a live authentication service. It treats every match equally, which forces developers to manually filter results and rebuild the missing context themselves.
Deep retrieval, on the other hand, focuses on meaning and relationships instead of mere keywords. It connects three key dimensions of information:
- Semantic context: understands what the code does, not just what it’s named. For example, it recognizes that refresh_token() and invalidate_cache() may operate within the same logical flow.
- Architectural context: identifies how files, classes, and services depend on one another across the codebase. This helps surface logic that spans multiple repositories or microservices.
- Temporal context: adds awareness of when something changed. It brings in related commits, changelogs, and PR discussions to explain how the code reached its current state.
Together, these layers create a structured understanding of the system. Instead of showing isolated search results, deep retrieval produces a coherent context map around the developer’s question. This is what enables tools like Qodo (the AI coding assistant I usually prefer) to deliver precise, context-aware answers rather than keyword-based guesses.



Why Context Retrieval Is Important for Development Teams
For most teams, the real challenge isn’t writing code, it’s understanding the context behind it. As projects scale and teams grow, codebases expand across multiple repositories, and knowledge gets scattered among pull requests, documentation, and historical commits. This fragmentation slows down reviews, debugging, and onboarding because developers spend more time searching than reasoning.
Contextual retrieval directly addresses this problem by building a unified understanding of code, configuration, and intent. Instead of treating files as isolated text, it connects dependencies, commit patterns, and developer discussions into a single reasoning layer.
Real Example 1: Smarter Pull Request Reviews
During a PR review, contextual retrieval allows the AI assistant to fetch dependency trees, function call traces, and historical discussions. Instead of offering superficial suggestions like “rename variable,” it can surface meaningful insights such as:
- Highlighting how a refactor changes function dependencies across services
- Detecting that a new utility overlaps with an existing internal method
- Explaining why a specific change might affect load balancing or data caching behavior
This helps reviewers focus on architectural implications rather than stylistic fixes, making the review process far more productive. I will give a proper hands on in the upcoming sections how I performed contextual retrieval on my codebase using tools like Qodo.
Real Example 2: Debugging a Memory Leak
When debugging a production memory leak in a service cluster, traditional search might lead to hundreds of scattered references to cache or configuration. A retrieval system, however, can pull together:
- The caching logic tied to the affected module
- Environment configuration impacting resource limits
- Historical bug reports or commits referencing similar leaks
This example highlights the power of contextual retrieval in real-world debugging. By automatically connecting code logic, configuration, and historical changes, developers can pinpoint the root cause of issues like memory leaks far more efficiently than with traditional search. It not only saves time but also decrease the risk of overlooking subtle regressions, providing a clearer and more confident path to resolution
Why Is It Important for Large Teams
In large organizations, knowledge silos are common. One engineer might know why a particular patch exists, another may understand how a configuration interacts with an API, and a third maintains the test suite. Contextual retrieval bridges this gap by linking tribal knowledge, connecting docstrings, code comments, and committing intent into a searchable, context-rich workspace.
The result is not just faster problem-solving, but also more consistent decision-making across teams. Contextual retrieval transforms fragmented information into a shared, continuously accessible knowledge layer for every developer involved in the project.
Features I Look For While Choosing Context Retrieval Tools
When evaluating any contextual retrieval system, I focus on how effectively it can understand, deliver, and act on the retrieved information. A tool should not only find relevant context but also integrate it into the daily workflow in a way that supports faster, better-informed decisions.
Deep Code Understanding
Effective retrieval systems go beyond text parsing. They should semantically interpret dependencies, class hierarchies, and architectural intent, essentially reading code like a senior engineer would. This means recognizing relationships between services, detecting when logic overlaps, and interpreting changes in context rather than isolation.
For example, Qodo’s MCP (Model Context Protocol) agents such as deep-issue connect PR changes to related service contracts, identifying how a seemingly local edit may impact upstream APIs or shared modules. This helps prevent subtle regressions that a traditional linter or static analyzer might overlook.
In my experience, this kind of deep semantic mapping is what separates retrieval systems that assist from those that truly understand the codebase.
Shift-Left Context Delivery
The shift-left principle means surfacing insights earlier in the development cycle, ideally, while coding, instead of waiting for reviews or production feedback. A strong retrieval system should bring relevant historical, architectural, or test-related context directly into the IDE.
With Qodo Gen, for example, I can see test case patterns, reusable code blocks, and best-practice hints while writing code. This early guidance decreases later review churn and encourages developers to make informed design choices upfront. It’s a smoother way to keep knowledge flow active without breaking focus or switching tools.
One-Click Remediation
Retrieval is only useful when it leads to action. Once a tool surfaces relevant insights, it should also support one-click remediation, enabling developers to fix or refactor with guided AI suggestions.
In a real pull request, Qodo does exactly this. If it detects inconsistent error handling across a set of files, it adds a comment with a suggestion to align patterns. Developers can review and apply it directly from the PR interface, cutting down the cycle time from detection to resolution. This integration of context and action creates a faster, feedback-driven loop.
Messaging and Traceability
Contextual retrieval becomes truly powerful when reasoning is shared across agents and reviewers. Qodo’s messaging layer enables this by maintaining a unified reasoning trail across its agents: ask, deep-research, and pr-memory.
This means if one agent identifies a dependency conflict or documents a fixed rationale, others automatically inherit that context. Every team member operates from the same information, ensuring transparency and consistency in how issues are understood and resolved.
For large, distributed teams, this kind of context traceability is invaluable. It keeps everyone aligned, minimizes duplicate investigation, and preserves institutional knowledge that often gets lost between commits and reviews.
How I Use Contextual Retrieval Using Qodo on My Codebase
For this hands-on demo, my codebase consists of a modular payment service for an e-commerce platform. The service includes multiple modules: PaymentService for handling payment requests through Stripe, Razorpay, and PayPal; RefundService for processing refunds and logging transactions; TransactionRepository to store all transaction details; and NotificationService to send email or webhook updates based on transaction outcomes.
Test cases were also included for failed payments, duplicate transactions, and partial refunds to create realistic scenarios that Qodo could analyze.
The codebase incorporates several Model Context Protocols (MCPs). MCPs are structured definitions that guide the AI to focus on relevant parts of the repository, link method definitions, map dependencies, and reference commit history. This enables deeper, contextual understanding of the code and helps explain why certain behaviors occur. Using custom MCPs allows for targeted analysis of specific modules or workflows, ensuring that contextual retrieval is accurate and relevant.
In this project, the key MCPs include:
- Payment Gateway MCP: Provides a unified interface for multiple payment gateways, includes gateway-specific error handling, and supports mock responses for testing. This MCP allows Qodo to trace payment request flows, identify failures, and understand validation logic.
- Cache Analysis MCP: Monitors cache usage, identifies stale entries, suggests invalidation points, and analyzes memory consumption. This MCP helps Qodo understand how caching influences interactions between modules and affects runtime behavior.
- Refund Validation MCP: Validates refund eligibility, checks for duplicates, calculates limits, and applies policy enforcement and risk scoring. It helps the model connect refund operations with business logic and transaction data.
Other MCPs, such as configuration, documentation, database schemas, test coverage, or dependency MCPs, add additional layers of semantic, architectural, or temporal context that Qodo can use.
The procedure for contextual retrieval involves defining relevant files, modules, and metadata in each MCP. When a query is made, Qodo uses these MCPs along with its internal tools to fetch, analyze, and link data. Key tools include:
- context: Retrieves relevant situational information across modules, such as linked methods or dependencies.
- list-dir / list-repos: Lists directories or repositories to identify where relevant code lives.
- read-file: Accesses file contents to extract method definitions, class structures, or logic.
- pr-memory: Pulls historical data from pull requests or previous commits to provide temporal context.
To test contextual retrieval in my codebase, I started with a simple query:
/qodo ask “Show me all methods in RefundService and how they interact with PaymentService”
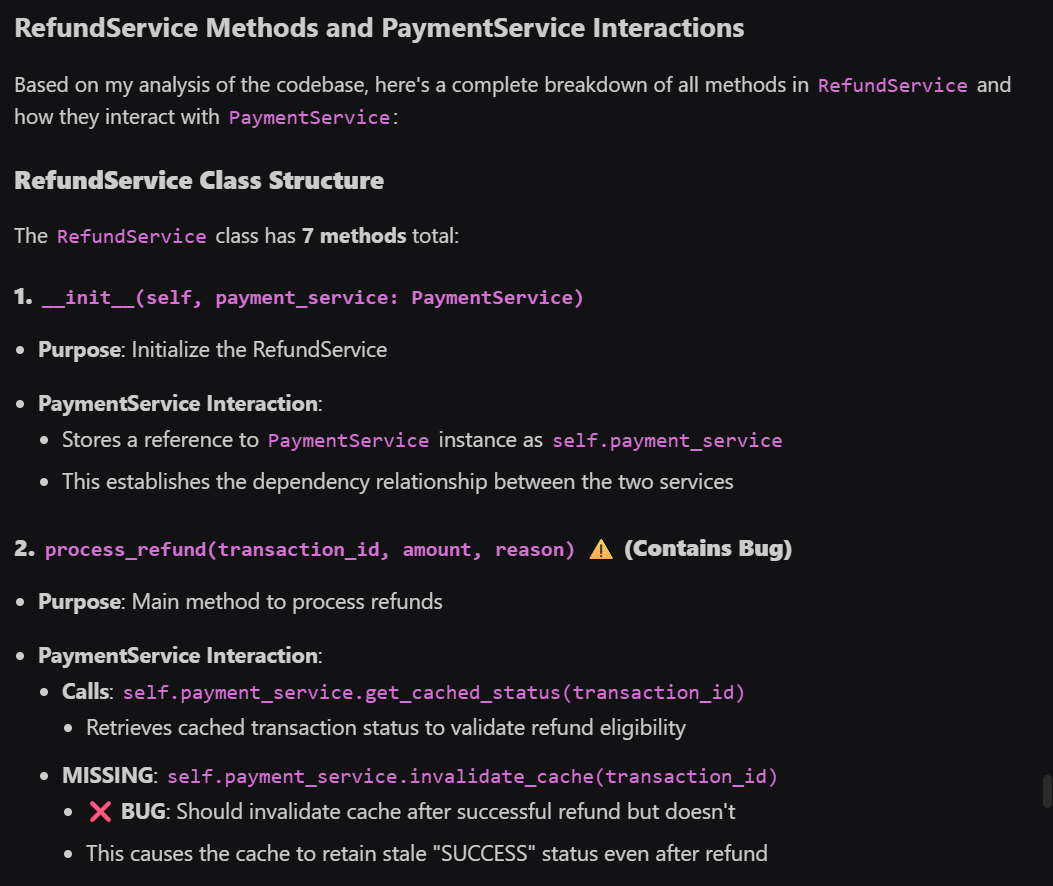
Qodo used the read-file and context tools to list all seven methods in RefundService and highlighted which ones interact with PaymentService.
For example, the process_refund(transaction_id, amount, reason) method calls payment_service.get_cached_status(transaction_id) to validate a refund, but it does not call invalidate_cache(transaction_id), leaving stale transaction data in the cache.
Qodo explained that this establishes a dependency relationship and flagged the missing cache invalidation as a potential issue. Other methods like _setup_logger() or get_refund_history() were correctly identified as having no PaymentService interactions, showing that Qodo can distinguish relevant from unrelated code.
Next, I asked a more targeted question about the actual failures:
/qodo ask “Why are some refunds failing due to cached transaction status?”
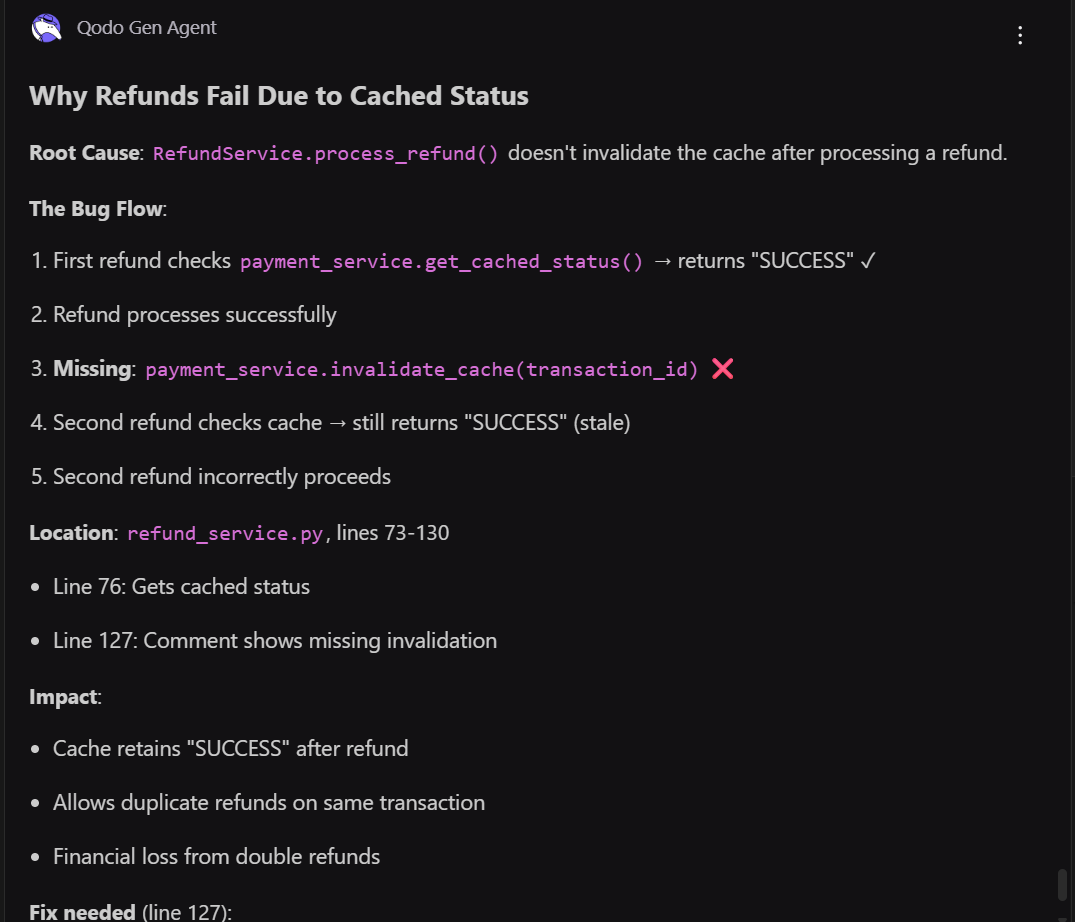
Qodo combined context, pr-memory, and MCP data to provide a multi-layered analysis:
- It traced the bug flow: the first refund succeeds, the cache still shows “SUCCESS”, and a subsequent refund incorrectly proceeds.
- It included method-level details (process_refund), module interactions (with PaymentService), and temporal context (commit history lines where caching logic was added).
- It highlighted the impact of the bug, including duplicate refunds and financial risk.
- Qodo also suggested the fix, including the exact code snippet to invalidate the cache after a successful refund,
Through these queries, I could see how Qodo’s contextual retrieval works: it combines semantic knowledge (methods and their logic), architectural awareness (service dependencies), and historical information (commits and code changes) to explain why a problem occurs and where to fix it. This made it far easier to pinpoint the root cause of issues without manually tracing each module or reading through commit history.
Through this hands-on exploration, I was able to see how Qodo’s contextual retrieval streamlines understanding complex codebases. By usingMCPs and its internal tools, such as context, read-file, list-dir, list-repos, and pr-memory, Qodo connected method-level logic, module dependencies, and commit history to provide actionable insights.
This approach made it significantly easier to trace issues, understand interactions between services, and identify the root cause of bugs like stale cache handling in refunds. Overall, the experience demonstrates how contextual retrieval can enhance debugging, code comprehension, and informed decision-making within modular, multi-service applications.
Conclusion
Contextual retrieval changes how developers work with complex codebases. Tools like Qodo combine method-level logic, inter-module dependencies, and historical commit data to provide a complete, connected view of the system. This approach surfaces the root causes of issues, lowers the time spent tracing problems manually, and makes code comprehension faster and more reliable. For teams handling large, modular, or distributed applications, contextual retrieval streamlines debugging and code reviews while preserving institutional knowledge, enabling more efficient development and confident decision-making.
FAQs
What is contextual retrieval in software development?
Contextual retrieval is the process of gathering all relevant information surrounding a piece of code, such as method definitions, dependencies, commit history, and documentation. It helps developers see not just what the code does, but why it behaves a certain way. Instead of returning scattered search results, contextual retrieval presents a connected view that mirrors how developers think when debugging or exploring a system.
Why is contextual retrieval important for developer productivity?
Most developer time is spent understanding code rather than writing it. Contextual retrieval lowers that overhead by surfacing the exact details a developer needs, including dependencies, related files, or previous changes, without switching between tools or manually tracing logic. It shortens debugging time, speeds up reviews, and improves confidence in code changes.
How does Qodo use MCP for contextual retrieval?
Qodo uses the Model Context Protocol (MCP) to define how different parts of a codebase are related. Each MCP acts like a structured map that connects files, modules, and metadata so the AI can reason contextually. When a developer asks a question, Qodo uses these MCPs to pull the right fragments of logic, configuration, and history, giving a complete answer grounded in the project’s actual structure.
Can Qodo retrieve context across different Git repositories?
Yes. Qodo can reference multiple repositories in a connected workspace. It links related components, such as shared libraries, services, or CI/CD pipelines, across repos. This allows contextual retrieval to work seamlessly even in microservice architectures or monorepos where dependencies span multiple repositories.
How does Qodo help with context-aware remediation?
Qodo doesn’t just identify issues; it explains them within context. When analyzing a problem, it uses MCPs to trace the cause across code, dependencies, and commit history, then suggests fixes that align with the project’s logic. This ensures that remediation steps are not generic but specific to the code’s real structure and behavior, reducing regression risks and improving long-term code health.


