AI Testing Tools for Enterprise: Security, Scale, and Code Integrity
TL;DR
- Enterprise QA is moving from manual scripts to AI-driven testing that keeps pace with continuous deployments.
- Instead of brittle automation, AI agents adapt tests automatically as code and systems evolve, with humans guiding priorities.
- Qodo stands out by combining secure RAG pipelines, multi-agent workflows, and enterprise-grade compliance for large, regulated codebases.
- When evaluating tools, look beyond features, focus on alignment with business goals, technical adaptability, and governance standards.
- No single tool covers everything: leaders pair code-intelligent systems like Qodo with UI, visual, and API/load testing platforms for complete coverage.
Enterprise QA is going through a fundamental reset. The old playbook, manual scripts, brittle test suites, and reactive triage are breaking under the pace of AI-driven development. Modern engineering teams now deploy code multiple times a day across distributed systems. QA can’t just keep up; it has to anticipate change.
As Jason Huggins recently noted, testing is no longer the “boring” part of software delivery; it’s where AI is finding one of its most meaningful applications. Aaron Levie put it well: “If AI is applied to a process executed hundreds or thousands of times a day in an organization, like QA testing software, then the value is much more meaningful.” That’s exactly what’s happening now: AI is being embedded into the core testing loop, where repetition, scale, and data feedback create tangible ROI.
The market is already moving away from brittle, script-based frameworks that need constant babysitting. Two broad categories are emerging: tools built for UI stability (self-healing, locator-based systems), and deep code–level AI tools that understand context, generate tests, and maintain coverage across multiple languages.
Within this shift, Qodo represents the next generation of testing intelligence. Its secure retrieval-augmented generation (RAG) pipeline isolates enterprise code context and minimizes hallucination while enforcing policy-driven access to repositories. The result: automated test generation that meets compliance and security requirements without leaking sensitive IP.
The outcome isn’t just theoretical; enterprises using Qodo’s model report concrete, measurable gains: reduced maintenance overhead and roughly 50 developer hours saved per month. For engineering leaders, that translates into predictable velocity, better coverage, and a QA function that finally scales in sync with product complexity.
The Mandate for Agentic Quality Assurance
Modern QA teams aren’t validating static applications anymore. They’re testing distributed systems made up of AI models, streaming APIs, and event-driven microservices, components that don’t always behave the same way twice. In this world, traditional automation frameworks that rely on fixed inputs and predictable outputs simply don’t hold up. They’re brittle, high-maintenance, and can’t reason about complex, stateful behavior.
That’s where agentic QA comes in: an approach where autonomous AI agents don’t just run tests, they plan, execute, and adapt them based on system intent. Instead of following pre-written scripts, these agents reason about the application’s structure, understand what the system is supposed to do, and adjust their test strategy as the codebase evolves.
Unlike conventional automation that checks boxes, agentic QA systems can interpret results in context. They connect outcomes back to business requirements, detect where coverage is missing, and regenerate test cases when the system changes, without human micromanagement.
Core Aspects of Agentic QA
1. Autonomous Test Strategy and Execution
Agentic systems analyze codebases, dependency graphs, and API schemas to map the application’s structure. From there, they build their own testing strategy, identifying critical paths, risky modules, and integration points automatically. Once the plan is ready, they can run tests across layers, UI, API, and backend, without relying on human-authored scripts. This removes most of the manual overhead in regression testing and keeps test coverage aligned with the system’s real behavior.
2. Continuous Learning and Adaptation
Each test cycle becomes a new learning event. Agents learn from test failures, production telemetry, and code diffs to refine their understanding of how the system behaves. If a React component changes its props or an API modifies its schema, the agent detects the delta, updates its mental model, and regenerates only the affected tests. This keeps suites clean and accurate without burning engineering time on maintenance.
3. Human-in-the-Loop Governance
The tester’s role shifts from executing cases to defining intent. Engineers specify business priorities, compliance constraints, and release gates. The AI operates within those boundaries, optimizing coverage and execution order autonomously. This ensures that human judgment still drives what should be tested, while the AI handles how it’s tested.
4. Expanded Test Coverage Beyond Functional Checks
Agentic QA extends beyond pass/fail validation. It applies the same reasoning models to non-functional areas, performance, accessibility, visual regression, and load testing. The system can simulate user journeys under different network conditions, benchmark latency against baselines, and detect UI drift across devices, all within a single test loop.
5. Outcome-Driven Metrics
The goal shifts from counting test cases to measuring business impact. Metrics like defect escape rate, cycle-time reduction, and mean time to recovery replace raw execution counts. Agentic QA gives teams faster release cycles with consistent confidence levels, because it focuses on coverage quality, not quantity.
Challenges and Design Considerations
Human–AI Collaboration
QA engineers now review and guide the system instead of writing scripts line by line. They need to understand model reasoning, calibrate autonomy levels, and validate that generated tests align with the product’s intent. This requires a shift in skillset, from manual scripting to AI orchestration.
Governance and Traceability
With autonomy comes the need for control. Every AI-driven action, test generation, refactor, or suite update must be logged and auditable. Enterprises should maintain approval checkpoints for high-risk updates and ensure that agent behavior is transparent for compliance and accountability.
Data and Integration Quality
Agentic QA is only as smart as the data it learns from. Code metadata, telemetry, and version-control signals must be consistent and available.
Integrating these agents with CI/CD systems (GitHub Actions, Jenkins) and observability stacks (OpenTelemetry, Datadog, New Relic) ensures they learn from live environments, not synthetic ones.
The teams that adapt early will move faster and ship with confidence, even as the systems they test become less predictable.
Enterprise Evaluation Framework: A CTO’s Checklist
Choosing an AI testing platform isn’t a tooling upgrade; it’s an architectural decision. The right system must align with engineering strategy, integrate cleanly with delivery pipelines, and meet enterprise-grade governance and security standards.
A practical evaluation framework should measure solutions across three core pillars: Strategic Alignment, Technical Capability, and Operational Readiness & Governance.
1. Strategic Alignment and Business Value
Before looking at feature lists, define why your organization is adopting AI-driven QA. For some teams, the goal is to cut maintenance overhead from brittle UI tests. Others want deeper coverage for APIs or AI/ML components, or to reduce regression cycle time without compromising compliance.
Clarity here ensures that the tool’s intelligence actually translates into measurable impact.
Key evaluation points:
- Defined outcomes: Set measurable goals, e.g., 40% reduction in regression effort, 30% faster test generation, or improved coverage accuracy validated against production defects.
- Testing scope: Identify which layers need automation in functional, regression, visual, load, or even model-drift testing for ML systems.
- ROI vs. TCO: Calculate the total cost of ownership, not just the license. Include AI compute, infrastructure costs, and enablement or upskilling time.
- Business KPIs: Connect test performance to delivery outcomes, defect leakage, mean-time-to-recovery (MTTR), and release throughput.
- Strategic fit: Assess the vendor’s roadmap for compatibility with your future direction, for instance, support for GenAI-driven pipelines or hybrid (on-prem + cloud) deployments.
When these checkpoints line up, AI-powered QA becomes a direct contributor to engineering velocity and business value, not just a cost center.
2. Technical Capability and Integration Depth
A credible AI testing platform should reason, not just automate. Its value lies in how intelligently it adapts to change, scales across environments, and integrates into your existing development workflow.
Technical checkpoints:
- Autonomy and adaptability: Validate that the system can self-heal and regenerate tests from source diffs, user stories, or API specifications. Look for deterministic regeneration logic rather than opaque “auto-fix” claims.
- NLP and visual reasoning: Check for natural-language test authoring (e.g., generating test suites from plain-text requirements) and computer-vision-based UI validation for cross-browser and responsive scenarios.
- Parallelization and scalability: Confirm support for distributed execution with reproducible runs. Benchmark at p95/p99 latencies under concurrent load to assess scheduling efficiency.
- Integration depth: The platform should plug into your CI/CD and developer ecosystem, GitHub, GitLab, Jenkins, CircleCI, VS Code, JetBrains, Jira , without workflow rewrites. Integration should extend developer efficiency, not replace existing patterns.
- Bias and model validation: For teams testing AI or ML workloads, ensure the platform can detect drift, bias, and fairness deviations in model outputs alongside functional accuracy.
- Resilience and rollback: Evaluate how the platform behaves during infrastructure degradation or model failures. It should support safe rollback of both tests and generated models to last-known-good states.
This pillar separates lightweight “AI-flavored automation” tools from actual agentic QA systems, ones that can scale intelligently and predictably across complex enterprise environments.
3. Governance, Security, and Operational Readiness
Even the smartest testing tool is a non-starter if it can’t meet enterprise standards for compliance, traceability, and security. Operational readiness is about ensuring that adoption doesn’t trade speed for control.
Governance essentials:
- Security posture: Require verifiable SOC 2 Type II or ISO 27001 certifications, full data encryption in transit and at rest, and customer-managed encryption keys when possible.
- Privacy and regulatory alignment: Validate adherence to GDPR, HIPAA, or any region-specific data-handling mandates relevant to your industry.
- Auditability: Every AI-driven action, test creation, modification, or refactor must be logged, timestamped, and exportable through OpenTelemetry or a comparable observability standard.
- Human-in-loop controls: For critical repos or production-facing code, enforce gated approvals before merging AI-generated tests or updates.
- Vendor maturity: Assess roadmap transparency, patch cadence, and responsiveness to enterprise feedback cycles.
- Support ecosystem: Evaluate the quality of documentation, enterprise onboarding, and availability of SLAs or customer success programs.
- Proof of Concept (PoC): Run a scoped PoC with real regression data. Measure time-to-integrate, model stability over multiple code revisions, and feedback loop latency during failures.
Finally, insist on explainability since a production-ready AI testing system must expose why a test was generated or updated, what data shaped that decision, and how outcomes were validated. That traceability turns AI QA from an opaque black box into an auditable, policy-aligned subsystem you can trust in regulated environments.
Enterprise Evaluation Pillars
| Evaluation Area | Core Criteria | Key Outcome |
| Strategic Alignment | Defined outcomes, scoped testing layers, ROI/TCO analysis, KPI linkage, roadmap fit | AI QA directly supports business and engineering objectives |
| Technical Capability | Self-healing logic, test generation, NLP/vision, distributed scale, integrations, bias/model validation | Intelligent automation that scales predictably and adapts to system change |
| Governance & Operational Readiness | Security certification, compliance, auditability, explainability, vendor maturity, PoC validation | Controlled, compliant adoption with transparency and reliability |
These discussions underscore a clear trend: enterprises are moving from rule-based automation toward AI-native testing systems that integrate directly with CI/CD and code intelligence layers. The next section examines leading Enterprise AI Testing Tools driving this shift, focusing on how they handle code-level test generation, self-healing validation, and secure data boundaries.
Enterprise AI Testing Tools: Detailed Profiles (The “What to Use”)
This section focuses on tools that define the current enterprise QA landscape, from deep-code generative systems to mature UI automation platforms. Each tool serves a distinct layer of the QA stack: some target stability and coverage, while others address autonomy, code quality, code integrity, and compliance. I’ll begin with Qodo, a platform built from the ground up for secure, code-level AI test generation within enterprise environments.
1. Qodo
![TL;DR Enterprise QA is moving from manual scripts to AI-driven testing that keeps pace with continuous deployments. Instead of brittle automation, AI agents adapt tests automatically as code and systems evolve, with humans guiding priorities. Qodo stands out by combining secure RAG pipelines, multi-agent workflows, and enterprise-grade compliance for large, regulated codebases. When evaluating tools, look beyond features, focus on alignment with business goals, technical adaptability, and governance standards. No single tool covers everything: leaders pair code-intelligent systems like Qodo with UI, visual, and API/load testing platforms for complete coverage. Enterprise QA is going through a fundamental reset. The old playbook, manual scripts, brittle test suites, and reactive triage are breaking under the pace of AI-driven development. Modern engineering teams now deploy code multiple times a day across distributed systems. QA can’t just keep up; it has to anticipate change. As Jason Huggins recently noted, testing is no longer the “boring” part of software delivery; it’s where AI is finding one of its most meaningful applications. Aaron Levie put it well: “If AI is applied to a process executed hundreds or thousands of times a day in an organization, like QA testing software, then the value is much more meaningful.” That’s exactly what’s happening now: AI is being embedded into the core testing loop, where repetition, scale, and data feedback create tangible ROI. The market is already moving away from brittle, script-based frameworks that need constant babysitting. Two broad categories are emerging: tools built for UI stability (self-healing, locator-based systems), and deep code–level AI tools that understand context, generate tests, and maintain coverage across multiple languages. Within this shift, Qodo represents the next generation of testing intelligence. Its secure retrieval-augmented generation (RAG) pipeline isolates enterprise code context and minimizes hallucination while enforcing policy-driven access to repositories. The result: automated test generation that meets compliance and security requirements without leaking sensitive IP. The outcome isn’t just theoretical; enterprises using Qodo’s model report concrete, measurable gains: reduced maintenance overhead and roughly 50 developer hours saved per month. For engineering leaders, that translates into predictable velocity, better coverage, and a QA function that finally scales in sync with product complexity. The Mandate for Agentic Quality Assurance Modern QA teams aren’t validating static applications anymore. They’re testing distributed systems made up of AI models, streaming APIs, and event-driven microservices, components that don’t always behave the same way twice. In this world, traditional automation frameworks that rely on fixed inputs and predictable outputs simply don’t hold up. They’re brittle, high-maintenance, and can’t reason about complex, stateful behavior. That’s where agentic QA comes in: an approach where autonomous AI agents don’t just run tests, they plan, execute, and adapt them based on system intent. Instead of following pre-written scripts, these agents reason about the application’s structure, understand what the system is supposed to do, and adjust their test strategy as the codebase evolves. Unlike conventional automation that checks boxes, agentic QA systems can interpret results in context. They connect outcomes back to business requirements, detect where coverage is missing, and regenerate test cases when the system changes, without human micromanagement. Core Aspects of Agentic QA 1. Autonomous Test Strategy and Execution Agentic systems analyze codebases, dependency graphs, and API schemas to map the application’s structure. From there, they build their own testing strategy, identifying critical paths, risky modules, and integration points automatically. Once the plan is ready, they can run tests across layers, UI, API, and backend, without relying on human-authored scripts. This removes most of the manual overhead in regression testing and keeps test coverage aligned with the system’s real behavior. 2. Continuous Learning and Adaptation Each test cycle becomes a new learning event. Agents learn from test failures, production telemetry, and code diffs to refine their understanding of how the system behaves. If a React component changes its props or an API modifies its schema, the agent detects the delta, updates its mental model, and regenerates only the affected tests. This keeps suites clean and accurate without burning engineering time on maintenance. 3. Human-in-the-Loop Governance The tester’s role shifts from executing cases to defining intent. Engineers specify business priorities, compliance constraints, and release gates. The AI operates within those boundaries, optimizing coverage and execution order autonomously. This ensures that human judgment still drives what should be tested, while the AI handles how it’s tested. 4. Expanded Test Coverage Beyond Functional Checks Agentic QA extends beyond pass/fail validation. It applies the same reasoning models to non-functional areas, performance, accessibility, visual regression, and load testing. The system can simulate user journeys under different network conditions, benchmark latency against baselines, and detect UI drift across devices, all within a single test loop. 5. Outcome-Driven Metrics The goal shifts from counting test cases to measuring business impact. Metrics like defect escape rate, cycle-time reduction, and mean time to recovery replace raw execution counts. Agentic QA gives teams faster release cycles with consistent confidence levels, because it focuses on coverage quality, not quantity. Challenges and Design Considerations Human–AI Collaboration QA engineers now review and guide the system instead of writing scripts line by line. They need to understand model reasoning, calibrate autonomy levels, and validate that generated tests align with the product’s intent. This requires a shift in skillset, from manual scripting to AI orchestration. Governance and Traceability With autonomy comes the need for control. Every AI-driven action, test generation, refactor, or suite update must be logged and auditable. Enterprises should maintain approval checkpoints for high-risk updates and ensure that agent behavior is transparent for compliance and accountability. Data and Integration Quality Agentic QA is only as smart as the data it learns from. Code metadata, telemetry, and version-control signals must be consistent and available. Integrating these agents with CI/CD systems (GitHub Actions, Jenkins) and observability stacks (OpenTelemetry, Datadog, New Relic) ensures they learn from live environments, not synthetic ones. The teams that adapt early will move faster and ship with confidence, even as the systems they test become less predictable. Enterprise Evaluation Framework: A CTO’s Checklist Choosing an AI testing platform isn’t a tooling upgrade; it’s an architectural decision. The right system must align with engineering strategy, integrate cleanly with delivery pipelines, and meet enterprise-grade governance and security standards. A practical evaluation framework should measure solutions across three core pillars: Strategic Alignment, Technical Capability, and Operational Readiness & Governance. 1. Strategic Alignment and Business Value Before looking at feature lists, define why your organization is adopting AI-driven QA. For some teams, the goal is to cut maintenance overhead from brittle UI tests. Others want deeper coverage for APIs or AI/ML components, or to reduce regression cycle time without compromising compliance. Clarity here ensures that the tool’s intelligence actually translates into measurable impact. Key evaluation points: Defined outcomes: Set measurable goals, e.g., 40% reduction in regression effort, 30% faster test generation, or improved coverage accuracy validated against production defects. Testing scope: Identify which layers need automation in functional, regression, visual, load, or even model-drift testing for ML systems. ROI vs. TCO: Calculate the total cost of ownership, not just the license. Include AI compute, infrastructure costs, and enablement or upskilling time. Business KPIs: Connect test performance to delivery outcomes, defect leakage, mean-time-to-recovery (MTTR), and release throughput. Strategic fit: Assess the vendor’s roadmap for compatibility with your future direction, for instance, support for GenAI-driven pipelines or hybrid (on-prem + cloud) deployments. When these checkpoints line up, AI-powered QA becomes a direct contributor to engineering velocity and business value, not just a cost center. 2. Technical Capability and Integration Depth A credible AI testing platform should reason, not just automate. Its value lies in how intelligently it adapts to change, scales across environments, and integrates into your existing development workflow. Technical checkpoints: Autonomy and adaptability: Validate that the system can self-heal and regenerate tests from source diffs, user stories, or API specifications. Look for deterministic regeneration logic rather than opaque “auto-fix” claims. NLP and visual reasoning: Check for natural-language test authoring (e.g., generating test suites from plain-text requirements) and computer-vision-based UI validation for cross-browser and responsive scenarios. Parallelization and scalability: Confirm support for distributed execution with reproducible runs. Benchmark at p95/p99 latencies under concurrent load to assess scheduling efficiency. Integration depth: The platform should plug into your CI/CD and developer ecosystem, GitHub, GitLab, Jenkins, CircleCI, VS Code, JetBrains, Jira , without workflow rewrites. Integration should extend developer efficiency, not replace existing patterns. Bias and model validation: For teams testing AI or ML workloads, ensure the platform can detect drift, bias, and fairness deviations in model outputs alongside functional accuracy. Resilience and rollback: Evaluate how the platform behaves during infrastructure degradation or model failures. It should support safe rollback of both tests and generated models to last-known-good states. This pillar separates lightweight “AI-flavored automation” tools from actual agentic QA systems, ones that can scale intelligently and predictably across complex enterprise environments. 3. Governance, Security, and Operational Readiness Even the smartest testing tool is a non-starter if it can’t meet enterprise standards for compliance, traceability, and security. Operational readiness is about ensuring that adoption doesn’t trade speed for control. Governance essentials: Security posture: Require verifiable SOC 2 Type II or ISO 27001 certifications, full data encryption in transit and at rest, and customer-managed encryption keys when possible. Privacy and regulatory alignment: Validate adherence to GDPR, HIPAA, or any region-specific data-handling mandates relevant to your industry. Auditability: Every AI-driven action, test creation, modification, or refactor must be logged, timestamped, and exportable through OpenTelemetry or a comparable observability standard. Human-in-loop controls: For critical repos or production-facing code, enforce gated approvals before merging AI-generated tests or updates. Vendor maturity: Assess roadmap transparency, patch cadence, and responsiveness to enterprise feedback cycles. Support ecosystem: Evaluate the quality of documentation, enterprise onboarding, and availability of SLAs or customer success programs. Proof of Concept (PoC): Run a scoped PoC with real regression data. Measure time-to-integrate, model stability over multiple code revisions, and feedback loop latency during failures. Finally, insist on explainability since a production-ready AI testing system must expose why a test was generated or updated, what data shaped that decision, and how outcomes were validated. That traceability turns AI QA from an opaque black box into an auditable, policy-aligned subsystem you can trust in regulated environments. Enterprise Evaluation Pillars Evaluation Area Core Criteria Key Outcome Strategic Alignment Defined outcomes, scoped testing layers, ROI/TCO analysis, KPI linkage, roadmap fit AI QA directly supports business and engineering objectives Technical Capability Self-healing logic, test generation, NLP/vision, distributed scale, integrations, bias/model validation Intelligent automation that scales predictably and adapts to system change Governance & Operational Readiness Security certification, compliance, auditability, explainability, vendor maturity, PoC validation Controlled, compliant adoption with transparency and reliability These discussions underscore a clear trend: enterprises are moving from rule-based automation toward AI-native testing systems that integrate directly with CI/CD and code intelligence layers. The next section examines leading Enterprise AI Testing Tools driving this shift, focusing on how they handle code-level test generation, self-healing validation, and secure data boundaries. Enterprise AI Testing Tools: Detailed Profiles (The “What to Use”) This section focuses on tools that define the current enterprise QA landscape, from deep-code generative systems to mature UI automation platforms. Each tool serves a distinct layer of the QA stack: some target stability and coverage, while others address autonomy, code quality, code integrity, and compliance. I’ll begin with Qodo, a platform built from the ground up for secure, code-level AI test generation within enterprise environments. 1. Qodo Qodo is an enterprise-grade generative testing system built around a secure retrieval-augmented generation (RAG) pipeline. It focuses on code integrity, data governance, and compliance alignment, three areas where most AI testing tools fail to meet enterprise standards. Unlike low-code automation tools that primarily interact with the UI layer, Qodo operates at the code and service level, generating, maintaining, and validating tests using scoped contextual data from repositories, APIs, and infrastructure definitions. Key Features Qodo Cover: An agentic module that automatically generates unit, integration, and regression tests across multiple languages (C++, Python, JavaScript). It aligns with internal coding standards and reviews code diffs before test generation. Scoped RAG Context: The RAG engine restricts model access to approved repositories and namespaces, ensuring that test generation happens only within a governed context, critical for IP protection and compliance audits. Multi-Language & Framework Support: Out-of-the-box compatibility with C++, Python, JavaScript, and Go. Includes adapters for Terraform and IaC validation. MCP (Model Control Protocol) Integration: Allows Qodo to coordinate with external systems, Jira, internal APIs, and CI/CD tools, using controlled, event-driven messaging. Explainability Layer: Every generated test includes traceability metadata linking it to the originating code commit, diff, and AI decision log. Secure Infrastructure Support: Supports SaaS, private cloud, and fully air-gapped on-prem installations, with encrypted model communication channels. Use Cases Enterprise Codebase Enforcement: Automatically enforces unit-test coverage thresholds during CI/CD. Regression Suite Generation: Builds and updates regression suites dynamically as code changes, ensuring coverage stays in sync with evolving architectures. Compliance-Driven Testing: Uses scoped RAG to ensure generated tests respect data residency, encryption, and regulatory boundaries. Legacy System Refactoring: Generates safety nets for older systems during modernization, reducing the risk of regression gaps. Hands-on Example: Generating an invalid-inputs Playwright E2E suite with Qodo Our Payments frontend had happy-path demos but no guardrails around invalid user input. I wanted a fast way to prove the UI surfaces 4xxs from the API (negative amount, empty currency, no API key, etc.) without touching app code. I ran qodo --ui, which started qodo on http://localhost:3000?wsPort=3456, gave one prompt: “generate a Playwright E2E test for submitting invalid data to the Payments frontend (negative amount, empty currency). Assert that the API returns a 4xx error. Save in tests/e2e/payments_ui_invalid.spec.ts.” Qodo created the file and populated a full spec: navigates to /app/frontend/index.html, seeds localStorage with a dev API key, fills the form with bad values, waits for the POST /payments response, and asserts 4xx (mostly 422) with error details in the JSON body. It also checks that the UI error area toggles correctly. As shown in the snapshot below: The diff was small and obvious: a new tests/e2e/payments_ui_invalid.spec.ts (~270 LOC) plus some quality-of-life setup Qodo proposed/added for first-time Playwright runs: playwright.config.ts (points to http://localhost:8000, starts FastAPI via uvicorn, enables traces/screenshots on failure). package.json scripts (test, test:ui, test:headed, test:debug, test:report). A minimal tests/e2e/basic.spec.ts health/page-load check. An E2E_TESTING_SETUP.md with run commands and troubleshooting. Operationally, I now have end-to-end coverage for the exact edge cases reviewers kept calling out: Validation paths: negative amount, zero amount, empty order ID, “too large” amounts, expect 4xx (mostly 422), and specific detail entries. Auth paths: missing/invalid API key, expect 401 with message. Resilience/UI: offline mode simulates network error; submit button resets; error area shows and contains status text. Security/process note: the tests intentionally mirror “claims-only” style validation from the API (they don’t bypass the backend). If you later enable stricter backend checks (e.g., currency required/non-empty), keep these specs; they’ll fail loudly and guide the UI changes. Pros Enterprise-grade security and governance controls (scoped RAG, audit trails, air-gapped deployment). High code integrity assurance with explainable AI artifacts. CI/CD integration via MCP and native IDE plugins. Multi-language and contextual awareness capabilities. Cons Newer ecosystem: Limited community footprint compared to legacy automation vendors. Requires initial setup investment for model scoping and policy definition. 2. Tricentis Testim Testim is part of the Tricentis suite and focuses on automating browser and mobile tests using AI-based locators and a low-code interface. It’s meant for large web environments where the UI changes often and traditional scripts break too easily. Instead of static selectors, Testim uses AI to identify elements by multiple attributes, text, structure, and metadata, and can automatically fix tests when something moves or changes in the DOM. It fits well inside enterprise CI/CD pipelines and integrates cleanly with Jira, Jenkins, GitHub, and Salesforce. Key Features AI Smart Locators: Detect and repair element locators automatically when the UI or DOM changes. Reusable Test Components: Common flows like login or checkout can be reused across tests, reducing maintenance effort. Parallel and Cross-Browser Execution: Runs tests across multiple browsers and environments in parallel for faster regression cycles. Low-Code Authoring: Teams can create tests through a visual interface or natural language, reducing dependency on heavy scripting. Salesforce-Optimized Testing: Uses metadata-based locators designed for Salesforce Lightning, which changes frequently. Detailed Reporting: Groups failures by cause, attaches screenshots, and surfaces logs for faster triage. Use Cases Maintaining stable UI tests in fast-changing web applications. Automating Salesforce orgs with dynamic elements and frequent updates. Running cross-browser regression suites as part of CI pipelines. Enabling QA and non-technical testers to create or update tests without deep programming. Hands-On: Capturing and Validating Network Requests in a Recorded Test The canvas below shows a Testim Visual Editor project titled “Capture request body,” which demonstrates how Testim can record user interactions that trigger backend activity and then validate the network requests those actions produce: This example goes beyond simple UI playback; it shows how to capture asynchronous browser calls (fetch and XHR), verify their payloads, and ensure that the correct requests and responses occur under real browser conditions. The test runs under a Chrome (Linux) configuration at 1920 × 1080 resolution. The Base URL is set to http://jsbin.testim.io/mec, a lightweight demo endpoint that exposes both fetch and XHR request buttons for testing network behavior. Recording begins directly from Testim’s Visual Editor. As the tester interacts with the page, Testim automatically creates discrete, executable steps on the flow canvas: The session is initialized by loading the base URL (Setup). The tester clicks “fetch request”, generating the first API call. A short 2.5-second wait is inserted to allow the asynchronous request to complete. The tester clicks “XHR request,” triggering a second network call, captured automatically. Another 2.5-second wait stabilizes execution timing. Finally, a shared network validation block executes, inspecting all captured network traffic. During this validation phase, Testim examines each outgoing request body and confirms that the payload, headers, and response codes match expected values. In this case, it verifies that both network calls complete successfully (HTTP 200) and that the request body structure aligns with the expected schema. When executed, Testim replays the entire sequence, monitors live network events, and produces detailed results, including screenshots, timing logs, and the full request/response trace. Any deviation (such as an altered endpoint, mismatched key, or failed response) is surfaced immediately in the results dashboard. This hands-on shows how Testim connects front-end actions to backend validation in one workflow. By combining recorded UI interactions with built-in network inspection, teams can confirm that user actions trigger the correct API requests, eliminating a common blind spot between UI automation and backend QA. The flow can then be scheduled or integrated into Jenkins or CircleCI for continuous verification across builds. Pros Very strong UI resilience, self-healing locators keep tests stable. Quick setup and visual test creation reduce scripting overhead. Seamless integration with CI/CD and major enterprise stacks. Cons Primarily UI-focused, doesn’t validate deep code or service layers. Some learning curve around designing reusable components and locator strategies. Next in the list, I have Mabl, a platform built for teams that live deep inside CI/CD pipelines and need testing to keep pace with deployment. 3. Mabl Mabl is a cloud-based, AI-assisted testing platform designed for continuous integration and delivery. It integrates directly into pipelines like Jenkins, GitHub Actions, and CircleCI, running automated tests after each build or deployment. Unlike traditional automation tools that rely on manual triggers, Mabl runs tests continuously in the background, learning from past runs and adapting to small UI or data changes. It’s especially useful in fast-moving environments where each code push can go to production within hours. Key Features CI/CD Integration: Native connectors for Jenkins, GitHub Actions, Azure DevOps, and CircleCI; test results are posted directly to the pipeline output. Auto-Healing Tests: Detects UI or data structure changes and adjusts test steps automatically to prevent breakage. Parallel Test Execution: Executes large suites across browsers and devices in parallel for shorter feedback loops. API Testing Support: Built-in tools for API-level testing and validation alongside UI tests. Agentic Workflows: Uses AI to identify redundant tests, optimize the order of execution, and surface flaky tests for review. SOC 2 Compliance: Meets enterprise security standards for cloud deployments. Use Cases Continuous QA in CI/CD Pipelines: Automatically triggers smoke and regression suites on every deployment. Full-Stack Validation: Runs both API and UI tests in the same flow, ideal for microservice architectures. Rapid Feedback in Agile Teams: Gives near real-time test feedback to developers after code commits. Scalable Regression Testing: Parallel execution helps maintain coverage across fast-release cycles without increasing runtime. Hands-On: AI-Native Test Execution and Failure Analysis in Mabl This example shows how Mabl automates test execution, visual validation, and performance monitoring within a continuous delivery workflow. Here, a feature plan for RBAC – Resource Group Owners runs a set of end-to-end tests verifying access permissions and resource group management As visible in the snapshot above, three tests pass and two fail. Instead of generic failure logs, Mabl’s AI layer performs contextual analysis. It identifies that one failure stems from leftover resource group data, while another fails due to a missing navigation path when creating a new group. The platform pinpoints root causes directly in the report, allowing engineers to regenerate or fix only the affected steps. In another plan, Mabl runs a visual smoke test to confirm UI stability across deployments. The system compares current and baseline builds side by side, detecting any layout, color, or spacing changes at the pixel level. Even subtle regressions are surfaced with visual diffs, enabling quick validation of front-end consistency across environments. Mabl’s insights dashboard extends beyond UI and logic testing. Here, it flags a performance regression where page load time spikes to 6.5 seconds, compared to a 4-second baseline The trend visualization ties this deviation back to the specific deployment that introduced it, helping teams correlate performance issues with release changes. Across these runs, Mabl’s AI agents handle the full test lifecycle, from execution and healing to diagnostics and performance correlation. Tests are versioned, run automatically in CI/CD, and produce structured outputs (logs, screenshots, telemetry) that plug directly into Jira or Slack. The result is a continuously learning QA loop that reduces manual triage and accelerates release validation. Pros Built for CI/CD velocity, fits naturally into continuous deployment workflows. Strong cross-browser and API testing support. Reduces manual maintenance through self-healing and intelligent test selection. Enterprise-ready with SOC 2 compliance and audit-friendly reporting. Cons Primarily UI and integration focused, not suitable for deep code or static analysis validation. Relies on cloud infrastructure, which may not fit tightly regulated or air-gapped environments. 4. Applitools Applitools is built for AI-powered visual testing. Instead of comparing expected values or DOM structures, it looks at how the application actually renders, pixel by pixel, across browsers and devices. It uses what they call Visual AI, which analyzes UI snapshots against an approved “baseline” to find visual regressions, broken layouts, missing elements, or unintended design shifts. Because it works at the rendering layer, it’s framework-agnostic, it plugs into existing Selenium, Cypress, Playwright, and Appium tests without changing how those frameworks run. For large front-end teams, it becomes the safety net that ensures every release looks right, not just functions correctly. Key Features Visual AI Engine: Captures rendered UI states and compares them against baselines using AI to detect changes that human eyes would notice but scripts wouldn’t, like alignment shifts or font inconsistencies. Ultrafast Grid: Runs visual checks in parallel across dozens of browser and device configurations, returning results in minutes instead of hours. Smart Maintenance: Groups similar changes together and suggests bulk baseline updates when expected design updates occur, minimizing manual review. Flexible Authoring: Works with both scripted and no-code approaches; you can integrate via SDKs in your existing test code or use Applitools’ recorder for quick test creation. Accessibility Checks: Built-in accessibility analysis for contrast ratios, alt text, and focus order validation. Deployment Options: Available as SaaS, private cloud, or on-prem, with APIs for integrating into enterprise pipelines and dashboards. Use Cases Visual regression testing across web, mobile, and desktop applications. Cross-browser validation to ensure layout consistency across Chrome, Edge, Safari, and Firefox. Design verification during UI redesigns or theme updates to catch style regressions early. Accessibility audits are baked into visual test runs for compliance coverage. CI-integrated visual QA, full UI checks triggered automatically on every build or pull request. Hands-On: Visual Validation and Baseline Maintenance with Applitools This example demonstrates how Applitools integrates visual AI checks into a standard end-to-end test flow, validating both functionality and UI consistency across browsers. A test flow is authored for the Applitools demo e-commerce site using a standard automation framework (for example, Selenium or Cypress): In the above snapshot, the flow navigates to the product page, selects the “Small Succulent Planter Pot”, changes the variant to “coral”, increases the quantity, and adds the item to the cart. Applitools Eyes captures a visual checkpoint at each of these actions, storing the rendered page as a baseline image. Future test runs automatically compare new screenshots against these baselines to detect visual drift. Applitools’ Visual AI engine analyzes these images using machine vision, not raw pixel comparison, so layout shifts, hidden text, or image rendering issues are flagged while dynamic content like timestamps or ads is ignored. Match levels such as Strict, Layout, or Ignore Colors control how sensitive the comparison is, depending on the context of the test. The flow continues by navigating to the “Contact Us” form. A new checkpoint is captured here as well. When the test executes in different browsers or resolutions, Applitools automatically applies cross-environment baselines, ensuring visual parity between Chrome, Edge, and Safari. For dynamic elements, testers can define floating or ignore regions, reducing false positives without sacrificing coverage. During CI/CD execution, the Eyes server performs visual diffing between the new and baseline snapshots. Differences are grouped and displayed in the Applitools dashboard, where reviewers can approve expected changes or reject unintended regressions. Approved changes automatically update baselines, maintaining test integrity without manual re-capture. Applitools doesn’t replace functional automation; it augments it. The underlying clicks, navigations, and assertions are still performed by your test framework; Eyes adds an intelligent validation layer that ensures the application looks correct in addition to working correctly. This hands-on example captures Applitools’ core strength: continuous, explainable visual verification with automatic baseline maintenance and adaptive match rules, ensuring UI reliability across every deployment without the noise of false alerts. Pros Catches real-world visual defects that traditional automation frameworks miss. Parallel execution across browsers/devices drastically cuts test runtime. Reduces manual baseline maintenance through smart grouping and visual AI. Integrates easily into existing Selenium, Cypress, or Playwright setups. Cons Focused primarily on UI validation, doesn’t handle logic or API testing. Needs clear baseline governance; unmanaged updates can mask true regressions. For air-gapped or internal apps, setup may require custom infrastructure and credentials. Next in the list is Functionize, a platform built for teams that want to automate end-to-end workflows without maintaining thousands of brittle scripts. 5. Functionize Functionize runs as a cloud-based, AI-driven test automation system. It captures metadata from every user interaction, DOM structure, CSS, network state, timing, and uses that to train models that can rebuild tests intelligently. Instead of relying on static selectors or code-based assertions, Functionize’s agents understand how each component behaves, so when the layout or structure shifts, they can identify and fix affected steps on their own. This makes it particularly useful for large enterprise applications that ship changes weekly and can’t afford manual script maintenance after every release. Key Features Natural Language Test Authoring: Tests can be written in plain English or captured through the browser recorder. Functionize interprets intent and generates automation steps automatically. Self-Healing Execution: The system detects UI changes, element IDs, CSS updates, or layout shifts, and either repairs the test automatically or flags it with detailed context. Parallel Cloud Execution: Runs large regression suites across browsers and devices simultaneously without local infrastructure. Full Workflow Automation: Supports UI, API, database, and file-level testing in a single flow, allowing end-to-end validation of complex business processes. Built-in Diagnostics: Each run captures DOM, network logs, and screenshots for every step, giving developers full visibility when debugging failures. Use Cases High-change frontends: Ideal for web apps where UI structures shift frequently and traditional scripts break easily. Cross-environment regression: Running consistent regression suites across browsers and environments in parallel. Full-stack business flows: Automating end-to-end workflows that touch multiple systems, from web UI to API to database. Mixed-skill QA teams: Enabling testers without deep scripting experience to contribute using natural language or visual authoring. Hands-On: NLP-Driven Test Creation and Smart Maintenance in Functionize This example shows how Functionize uses NLP-based authoring and AI-powered test maintenance to automate web application validation. Here, a test is created to verify a job search workflow on Indeed.com. The test starts by opening the URL, entering “receptionist” as the job title, and “Council Bluffs, IA” as the location. Each interaction — clicks, text inputs, and navigation events — is captured as structured actions in the Functionize Smart Recorder. Unlike traditional scripts, Functionize’s engine models the DOM, visual layout, and network calls in real time. This context-aware capture allows the system to identify elements by intent rather than brittle selectors. During playback, the Functionize Adaptive Execution Engine interprets each step against the latest version of the application. If the layout changes or selectors break, the Adaptive Locator Model automatically re-identifies elements using hundreds of attributes, reducing false failures. In the test editor, as shown in the snapshot below: Each step is displayed in natural language: “Enter ‘receptionist’ in the input field with placeholder ‘Job title, keywords, or company’.” Testers can modify, insert, or reorder steps without editing code. Functionize’s hands-on value lies in its balance between codeless authoring and AI depth; it uses NLP for test creation, ML models for element recognition, and visual baselines for regression analysis. Together, these allow teams to maintain stable tests even as the UI evolves. Pros Strong self-healing capability reduces maintenance on fast-changing UIs. Runs large-scale suites in parallel without managing infrastructure. Handles full workflow automation, not just front-end validation. Easy entry point for teams that want AI-driven automation without writing code. Cons Requires initial setup and calibration to tune AI behavior and mappings. Limited suitability for air-gapped or heavily restricted environments due to its cloud-first model. For highly customized internal frameworks, manual scripting may still be needed for complex edge cases. 6. TestCraft TestCraft is a SaaS-based codeless testing platform that runs on top of Selenium. Instead of scripting test flows manually, you build them visually using drag-and-drop components. The platform tracks page structures and element attributes, using machine learning to detect UI changes and automatically repair or realign broken tests. It’s aimed at QA teams that handle frequent front-end updates but don’t want to constantly rewrite locator scripts or manage Selenium infrastructure. Key Features Visual Test Authoring: Create automated tests using a flow-based UI instead of code. Testers can model actions and validation steps step by step. AI-Assisted Maintenance: When an element or DOM attribute changes, TestCraft’s AI re-maps selectors and updates the flow automatically. Reusable Modules: Common sequences ike login, checkout, or navigation, can be saved and reused across multiple test suites. Parallel Test Execution: Supports running tests simultaneously across browsers and environments via cloud execution. CI/CD Integration: Connects with Jenkins, GitHub Actions, or other CI tools to trigger tests automatically on each build. Reporting and Version Control: Provides run history, visual diffs, and result tracking for easier debugging and release traceability. Use Cases Fast-changing web UIs: Applications where layout or styling changes frequently, and static scripts break easily. Mixed QA teams: Environments where both engineers and non-technical testers need to collaborate on automation. Agile regression cycles: Continuous delivery pipelines that require reliable UI regression coverage without heavy maintenance. Web-only automation: Projects primarily focused on browser-based apps rather than mobile or backend systems. Hands-On: From Element Selection to AI-Generated Test Code in TestCraft TestCraft makes test creation almost instantaneous by combining visual element selection, AI-generated test scenarios, and automatic code conversion. In this example, the process begins with the TestCraft browser interface, which displays key options: Pick Element, Generate Test Ideas, Automate, and Check Accessibility. Once the extension is launched, the tester opens a live web page. In this case, Infrasity’s homepage activates the Pick Element to begin mapping the UI. As shown in the snapshot below, the top navigation bar is selected directly on the rendered site: TestCraft highlights the chosen region in real time, confirming that the element is properly detected through its DOM and CSS attributes. After selection, the tester clicks Generate Test Ideas: TestCraft’s AI immediately analyzes the element context and generates categorized test scenarios: Positive tests such as verifying that the “Home” or “Pricing” links navigate correctly. Negative tests like checking broken links, offline interactions, or missing JavaScript responses. Creative tests, such as resizing the browser to validate responsive design and accessibility. Each idea is editable, so teams can tune the generated cases before proceeding to automation. Next, clicking Automate converts these ideas into executable Playwright tests. The right panel shows the generated JavaScript code. TestCraft defines reusable page objects like NavbarPage, containing functions such as navigateToContact() and clickPricingLink(), followed by complete test cases using the Playwright test runner syntax. These can be copied directly or exported to a CI/CD pipeline. Finally, the Check Accessibility option runs automated WCAG-based validation on the selected element, testing color contrast, ARIA roles, and keyboard navigation, to ensure accessibility compliance without writing separate rules. Through this flow, TestCraft reduces hours of manual setup to minutes. By combining AI-generated test logic, code synthesis, and accessibility validation in a single session, it delivers quick, auditable coverage for UI-heavy applications, ideal for teams needing fast validation cycles without heavy scripting overhead. Pros Reduces maintenance for fast-changing web UIs through self-healing tests. Allows non-developers to build and maintain meaningful automation. Integrates cleanly with CI/CD and version control tools. Built on Selenium, so tests remain compatible with standard execution grids. Cons Limited to web UI automation; doesn’t support backend or API testing natively. Requires careful test architecture planning to maximize reuse and maintain reliability at scale. For highly dynamic or canvas-based interfaces, element detection may still need manual adjustment. Modern applications rarely fail because of missing buttons; they fail under scale, when APIs slow down or break under concurrency. That’s the space Loadmill fits into since it is an AI-assisted platform for API and performance testing that builds real test cases directly from captured traffic and scales them to production-level load without any scripting. 7. Loadmill Loadmill is an AI-assisted API and performance testing platform that automatically converts real user or API traffic into repeatable test suites. It’s designed for microservice-heavy and API-driven applications where backend behavior changes frequently. Instead of manually authoring test scripts, teams can upload HAR files, point to API endpoints, or capture browser sessions. Loadmill uses that data to auto-generate tests. It supports both functional verification and full-scale load simulation, allowing QA and DevOps teams to validate correctness and performance from the same setup. Key Features Automated Test Generation: Converts captured traffic (e.g., HAR files or API definitions) into runnable test suites automatically. Load & Performance Testing: Simulates concurrent API calls at scale and measures latency, throughput, and error rates. Self-Updating Tests: Detects schema or response changes and updates existing test definitions accordingly. Parallel Execution: Runs large test sets across multiple environments or regions to validate distributed deployments. CI/CD Integration: Command-line tools and REST APIs for integrating tests into Jenkins, GitHub Actions, or any custom pipeline. Detailed Analytics: Provides structured reports on response times, bottlenecks, and failure points for quick diagnosis. Use Cases API Regression Testing: Automatically generating and maintaining backend regression tests after each release. Load Validation: Running controlled high-traffic simulations to validate service scalability and latency before production pushes. Microservice Testing: Coordinating functional and performance validation across multiple APIs that interact with each other. Post-Deployment Verification: Running lightweight smoke and latency checks immediately after deployment. Hands-On: Building and Running API & Load Tests in Loadmill Loadmill simplifies how teams validate and stress-test APIs by combining traffic-based recording, parameterized requests, and CI-friendly automation. This hands-on walkthrough uses a simple API workflow, from defining requests to analyzing test results and debugging failures. Start by opening Loadmill’s API Tests dashboard and creating a new suite, here titled Example CI Test. Under the suite, add a flow named Basic sanity test and configure a simple GET request to ${web_url} to verify your deployed app responds correctly. As visible in the basic sanity test flow below, it shows the GET method setup with a single parameter ${web_url}: This setup acts as a heartbeat check for your environment. Since Loadmill supports variable substitution, ${web_url} can dynamically resolve to staging, QA, or production URLs defined under Parameters. Next, in adding a dynamic API request, extend the test to cover real functionality. Create a new request, for example, to simulate a “create post” API call in a headless CMS. Set the Method to POST and the Endpoint to ${web_url}/ghost/api/v0.1/posts/?include=tags. On the Creation of a new blog post, as done in the snapshot below: It captures the full configuration: request body, headers, and extracted parameters. The request body uses template variables like ${blog_post_title}. You can extract response data dynamically, such as the created_post_id, using a JSONPath expression ($.posts[0].id), and validate it with an assertion to ensure it matches a numeric pattern (^\d+$). This combines both parameter injection and response verification in one step. Once your flows are ready, mark them for CI execution. Enable the CI checkbox beside the flow title so it can automatically run in your pipeline, such as in Heroku CI or GitHub Actions, after each deployment. As shown in the snapshot below CI checkbox is enabled, which visualizes where CI is toggled on within the Loadmill interface: You can now run the test suite with one click using the Run Suite button, or have it execute automatically as part of your continuous integration workflow. After execution, Loadmill displays consolidated results summarizing progress, success rate, and average duration for each flow. The snapshot below visualizes a completed run with metrics like 75% success rate, 1.1s average duration, and detailed pass/fail status per flow: Each test flow includes a breakdown of requests, duration, and status, giving teams immediate visibility into endpoint health and runtime efficiency. When a test fails, Loadmill provides full HTTP-level diagnostics, including request headers, body, response payloads, and assertion mismatches. In this example, a broken test returned 401 Unauthorized, pinpointing an authentication issue. Such visibility makes it easy to debug API permission or token issues directly from the test report, without re-running the full suite manually. From the same functional flows, Loadmill can generate load tests that replicate real traffic. This hands-on flow demonstrates how Loadmill compresses the entire API test lifecycle, from endpoint validation and JSON extraction to CI orchestration and load simulation, into one cohesive workflow. Pros Combines functional and load testing in a single workflow. Auto-generates tests from real traffic, reducing manual setup. Integrates easily into CI/CD pipelines with CLI and REST APIs. Provides deep performance analytics for backend debugging. Cons Best suited for API-first systems; not a full UI testing solution. Cloud-first deployment can be restrictive for air-gapped environments. Initial setup and tuning are required to map endpoints and data dependencies effectively. Comparison Matrix: Tools at a Glance By this point, it’s clear that each tool serves a very different layer of the testing stack. Some, like Qodo and Functionize, focus on intelligent code-level generation and adaptive automation, while others, like Tricentis Testim or Applitools, prioritize stability and visual accuracy. For engineering leadership evaluating enterprise readiness, the decision isn’t about “best overall,” but “best fit for the architecture and QA objectives.” Here’s a side-by-side comparison summarizing their technical focus, strengths, and trade-offs. Tool Primary Focus Key Features Strengths Limitations Qodo Generative & Code Integrity Secure RAG, test/code generation, MCP integration Built for compliance, explainability, and deep code coverage New ecosystem; requires scoped setup Tricentis Testim UI Stability & Salesforce AI locators, low-code test authoring, SOC 2 Proven enterprise adoption, mature for UI/Salesforce Limited for backend/API validation Mabl CI/CD Velocity & Continuous QA Auto-healing, agentic workflows, SOC 2 Strong DevOps integration, quick feedback Primarily UI-focused Applitools Visual QA & UI Validation Visual AI, Ultrafast Grid, accessibility checks Detects visual regressions across browsers/devices Doesn’t cover logic or API layers Functionize Adaptive Full-Stack Testing Self-healing, NLP test authoring, cloud parallelism Covers end-to-end workflows, broad scope Cloud-first; limited air-gapped options TestCraft Codeless Web Automation Visual modeling, AI locator repair, Selenium-based Enables non-technical testers, lowers maintenance Focused only on web UI Loadmill API & Performance Testing HAR-based test generation, load simulation, and latency metrics Combines functional and load testing in one platform No native UI testing; setup effort needed Enterprise Refactoring: Scale, Risk, and Qodo’s Advantage In enterprise environments, refactoring is less about beautifying code and more about risk management and architectural evolution. A large-scale empirical study by Timperley et al. (ESEC/FSE 2022) found that over 80% of developers in large organizations had taken part in refactoring projects spanning multiple months and exceeding 100,000 lines of code. Such efforts are often tied to modernization programs, migrating monoliths to microservices, enforcing compliance upgrades, or eliminating legacy dependencies, and they consistently expose the operational fragility of large systems. The primary challenge isn’t just technical debt; it’s maintaining reliability and governance at scale. Enterprise codebases typically comprise hundreds of interdependent services subject to SOC 2, GDPR, and internal audit requirements. A single unsafe refactor can trigger regression failures across CI/CD pipelines or violate compliance policies downstream. Traditional IDE-based tools struggle here because they operate at the file or repository level, with little awareness of systemic dependencies or organizational rules. Qodo approaches refactoring as a context-driven, auditable process rather than a one-off automation task. Its multi-agent architecture analyzes entire dependency graphs, honors enterprise coding standards, and automatically generates regression tests to validate functional parity. This system-wide visibility helps enterprises refactor confidently without compromising stability or compliance. Security & Compliance: SOC 2 Type II, encrypted data in transit, scoped retrieval to limit data exposure. Deployment Flexibility: Supports SaaS, private cloud, and air-gapped on-prem installations. Deep Integration: Native support for VS Code, JetBrains, GitHub/GitLab, and CI/CD hooks ensures minimal workflow disruption. Governance & Auditability: All AI actions are logged via OpenTelemetry for traceability and compliance evidence. Granular Access Control: Teams can explicitly scope which repositories or directories Qodo analyzes. Economic Impact: Enterprises report roughly 25 percent engineering time savings, earlier defect detection, and reduced rework costs. In effect, Qodo operationalizes large-scale refactoring as a controlled, observable, and compliant engineering activity, aligning with the demands documented in enterprise software-maintenance research. FAQs 1. What is the best tool for testing? It depends on scope: Qodo offers unified AI-native testing across UI, API, and data layers; Testim and Functionize excel in no-code UI automation; Applitools leads in visual regression; Loadmill handles API and load testing; and TestCraft focuses on quick test ideation and accessibility. Enterprises often combine these for full-stack coverage. 2. How can generative AI improve software testing? Generative AI accelerates test creation, expands scenarios, and auto-heals scripts as apps evolve. Platforms like Qodo and Functionize use natural language prompts to generate runnable tests and adapt them automatically, reducing maintenance while improving coverage and traceability. 3. What should enterprises consider when adopting generative AI for testing? Focus on data security, explainability, and CI/CD integration. Platforms like Qodo address this by keeping AI-generated logic versioned, audit-ready, and pipeline-compatible. Governance, review gates, and scalability remain essential to balance automation with control. 4. How do you test an enterprise application effectively? Use a layered approach: functional tests with Qodo or Testim, API and integration validation via Loadmill, visual and accessibility checks with Applitools or TestCraft, and performance testing under load. Unifying these in a single platform ensures reliable regression and release confidence.](https://www.qodo.ai/wp-content/uploads/2025/11/image10.png)
Qodo is an enterprise-grade generative testing system built around a secure retrieval-augmented generation (RAG) pipeline. It focuses on code integrity, data governance, and compliance alignment, three areas where most AI testing tools fail to meet enterprise standards.
Unlike low-code automation tools that primarily interact with the UI layer, Qodo operates at the code and service level, generating, maintaining, and validating tests using scoped contextual data from repositories, APIs, and infrastructure definitions.
Key Features
- Qodo Cover: An agentic module that automatically generates unit, integration, and regression tests across multiple languages (C++, Python, JavaScript). It aligns with internal coding standards and reviews code diffs before test generation.
- Scoped RAG Context: The RAG engine restricts model access to approved repositories and namespaces, ensuring that test generation happens only within a governed context, critical for IP protection and compliance audits.
- Multi-Language & Framework Support: Out-of-the-box compatibility with C++, Python, JavaScript, and Go. Includes adapters for Terraform and IaC validation.
- MCP (Model Control Protocol) Integration: Allows Qodo to coordinate with external systems, Jira, internal APIs, and CI/CD tools, using controlled, event-driven messaging.
- Explainability Layer: Every generated test includes traceability metadata linking it to the originating code commit, diff, and AI decision log.
- Secure Infrastructure Support: Supports SaaS, private cloud, and fully air-gapped on-prem installations, with encrypted model communication channels.
Use Cases
- Enterprise Codebase Enforcement: Automatically enforces unit-test coverage thresholds during CI/CD.
- Regression Suite Generation: Builds and updates regression suites dynamically as code changes, ensuring coverage stays in sync with evolving architectures.
- Compliance-Driven Testing: Uses scoped RAG to ensure generated tests respect data residency, encryption, and regulatory boundaries.
- Legacy System Refactoring: Generates safety nets for older systems during modernization, reducing the risk of regression gaps.
Hands-on Example: Generating an invalid-inputs Playwright E2E suite with Qodo
Our Payments frontend had happy-path demos but no guardrails around invalid user input. I wanted a fast way to prove the UI surfaces 4xxs from the API (negative amount, empty currency, no API key, etc.) without touching app code.
I ran qodo –ui, which started qodo on http://localhost:3000?wsPort=3456, gave one prompt: “generate a Playwright E2E test for submitting invalid data to the Payments frontend (negative amount, empty currency). Assert that the API returns a 4xx error. Save in tests/e2e/payments_ui_invalid.spec.ts.” Qodo created the file and populated a full spec: navigates to /app/frontend/index.html, seeds localStorage with a dev API key, fills the form with bad values, waits for the POST /payments response, and asserts 4xx (mostly 422) with error details in the JSON body. It also checks that the UI error area toggles correctly.
As shown in the snapshot below:
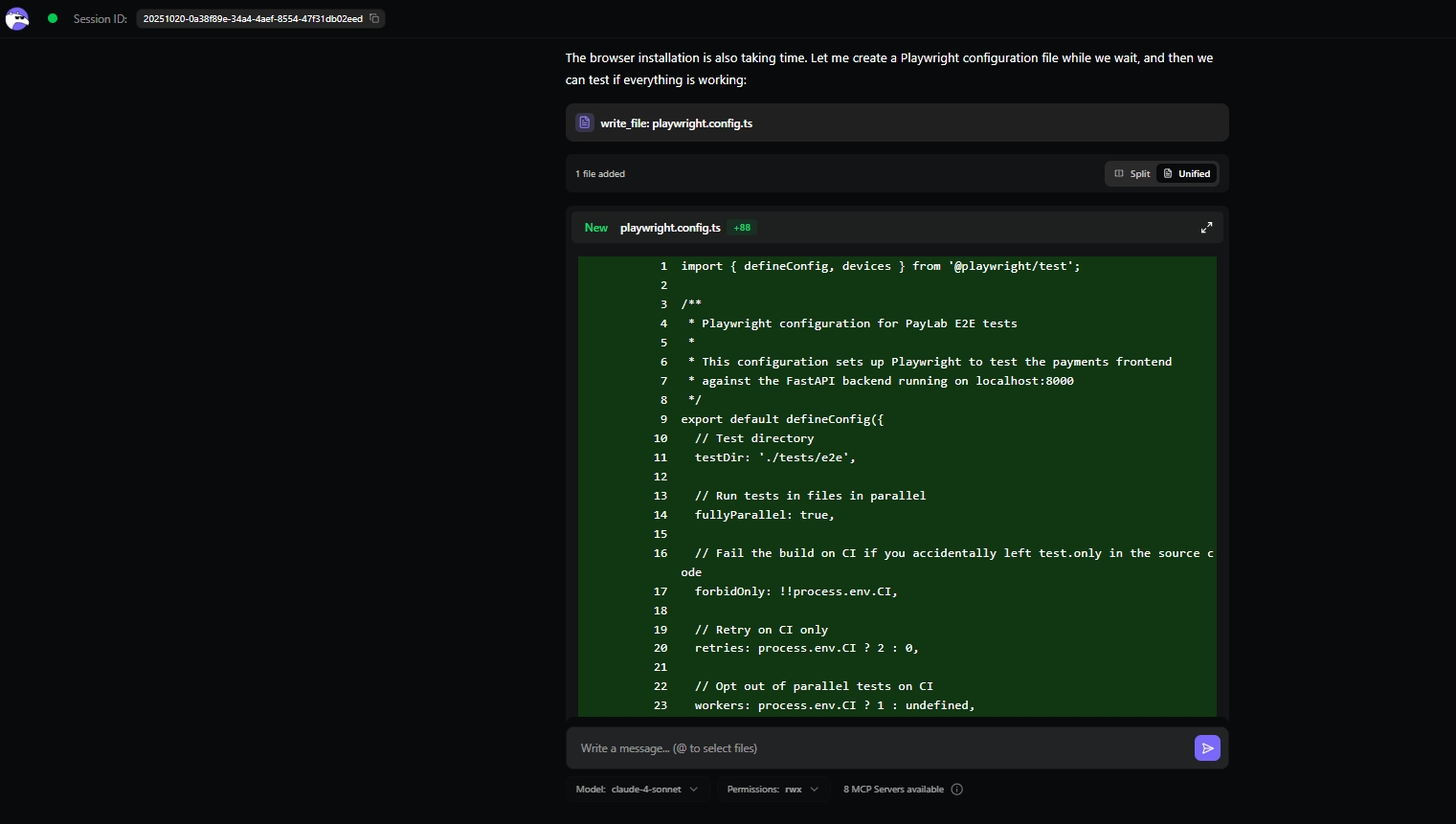
The diff was small and obvious: a new tests/e2e/payments_ui_invalid.spec.ts (~270 LOC) plus some quality-of-life setup Qodo proposed/added for first-time Playwright runs:
- playwright.config.ts (points to http://localhost:8000, starts FastAPI via uvicorn, enables traces/screenshots on failure).
- package.json scripts (test, test:ui, test:headed, test:debug, test:report).
- A minimal tests/e2e/basic.spec.ts health/page-load check.
- An E2E_TESTING_SETUP.md with run commands and troubleshooting.
Operationally, I now have end-to-end coverage for the exact edge cases reviewers kept calling out:
- Validation paths: negative amount, zero amount, empty order ID, “too large” amounts, expect 4xx (mostly 422), and specific detail entries.
- Auth paths: missing/invalid API key, expect 401 with message.
- Resilience/UI: offline mode simulates network error; submit button resets; error area shows and contains status text.
Security/process note: the tests intentionally mirror “claims-only” style validation from the API (they don’t bypass the backend). If you later enable stricter backend checks (e.g., currency required/non-empty), keep these specs; they’ll fail loudly and guide the UI changes.
Pros
- Enterprise-grade security and governance controls (scoped RAG, audit trails, air-gapped deployment).
- High code integrity assurance with explainable AI artifacts.
- CI/CD integration via MCP and native IDE plugins.
- Multi-language and contextual awareness capabilities.
Cons
- Newer ecosystem: Limited community footprint compared to legacy automation vendors.
- Requires initial setup investment for model scoping and policy definition.
2. Tricentis Testim
Testim is part of the Tricentis suite and focuses on automating browser and mobile tests using AI-based locators and a low-code interface. It’s meant for large web environments where the UI changes often and traditional scripts break too easily.
Instead of static selectors, Testim uses AI to identify elements by multiple attributes, text, structure, and metadata, and can automatically fix tests when something moves or changes in the DOM. It fits well inside enterprise CI/CD pipelines and integrates cleanly with Jira, Jenkins, GitHub, and Salesforce.
Key Features
- AI Smart Locators: Detect and repair element locators automatically when the UI or DOM changes.
- Reusable Test Components: Common flows like login or checkout can be reused across tests, reducing maintenance effort.
- Parallel and Cross-Browser Execution: Runs tests across multiple browsers and environments in parallel for faster regression cycles.
- Low-Code Authoring: Teams can create tests through a visual interface or natural language, reducing dependency on heavy scripting.
- Salesforce-Optimized Testing: Uses metadata-based locators designed for Salesforce Lightning, which changes frequently.
- Detailed Reporting: Groups failures by cause, attaches screenshots, and surfaces logs for faster triage.
Use Cases
- Maintaining stable UI tests in fast-changing web applications.
- Automating Salesforce orgs with dynamic elements and frequent updates.
- Running cross-browser regression suites as part of CI pipelines.
- Enabling QA and non-technical testers to create or update tests without deep programming.
Hands-On: Capturing and Validating Network Requests in a Recorded Test
The canvas below shows a Testim Visual Editor project titled “Capture request body,” which demonstrates how Testim can record user interactions that trigger backend activity and then validate the network requests those actions produce:
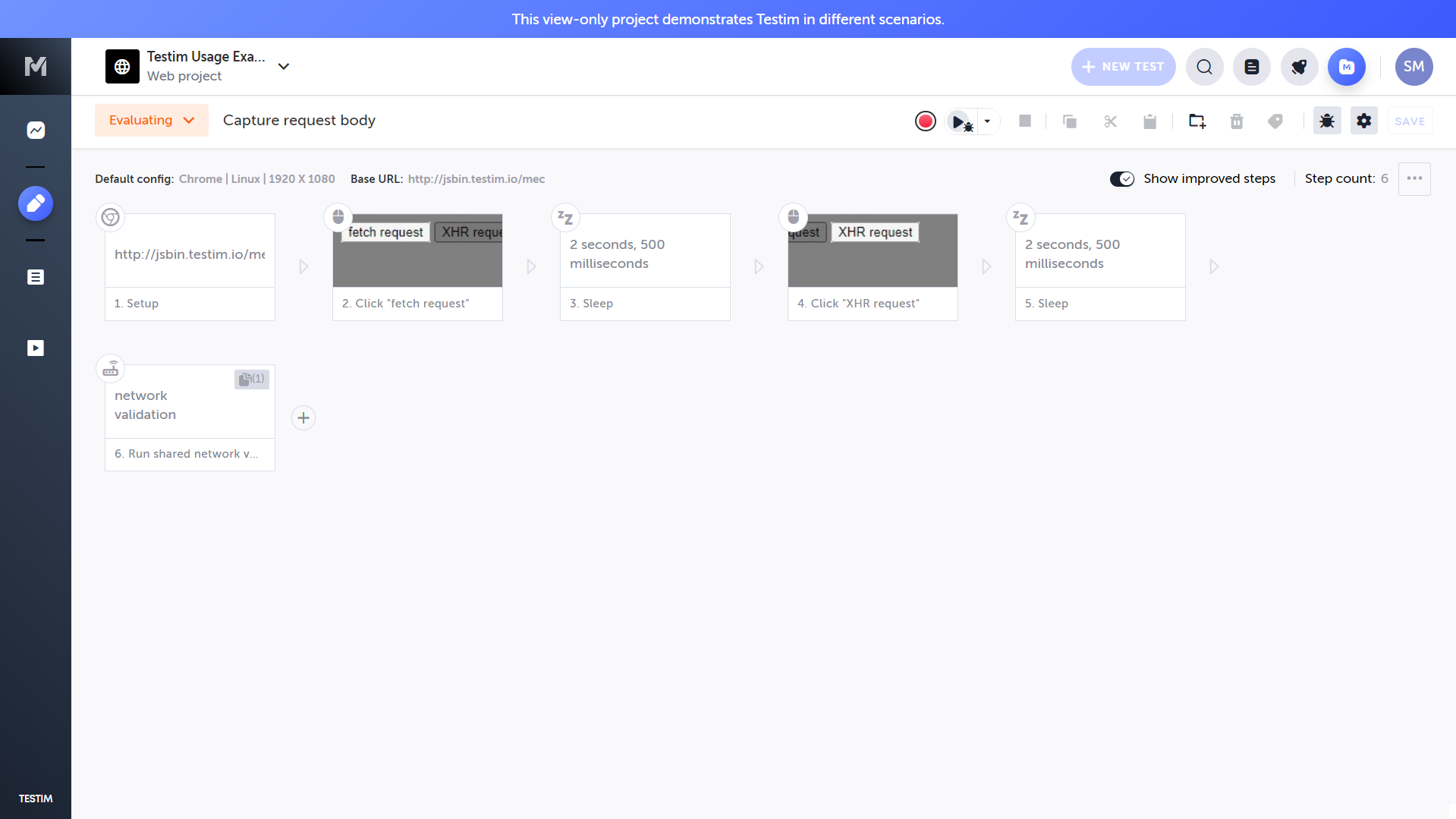
This example goes beyond simple UI playback; it shows how to capture asynchronous browser calls (fetch and XHR), verify their payloads, and ensure that the correct requests and responses occur under real browser conditions.
The test runs under a Chrome (Linux) configuration at 1920 × 1080 resolution. The Base URL is set to http://jsbin.testim.io/mec, a lightweight demo endpoint that exposes both fetch and XHR request buttons for testing network behavior.
Recording begins directly from Testim’s Visual Editor. As the tester interacts with the page, Testim automatically creates discrete, executable steps on the flow canvas:
- The session is initialized by loading the base URL (Setup).
- The tester clicks “fetch request”, generating the first API call.
- A short 2.5-second wait is inserted to allow the asynchronous request to complete.
- The tester clicks “XHR request,” triggering a second network call, captured automatically.
- Another 2.5-second wait stabilizes execution timing.
- Finally, a shared network validation block executes, inspecting all captured network traffic.
During this validation phase, Testim examines each outgoing request body and confirms that the payload, headers, and response codes match expected values. In this case, it verifies that both network calls complete successfully (HTTP 200) and that the request body structure aligns with the expected schema.
When executed, Testim replays the entire sequence, monitors live network events, and produces detailed results, including screenshots, timing logs, and the full request/response trace. Any deviation (such as an altered endpoint, mismatched key, or failed response) is surfaced immediately in the results dashboard.
This hands-on shows how Testim connects front-end actions to backend validation in one workflow. By combining recorded UI interactions with built-in network inspection, teams can confirm that user actions trigger the correct API requests, eliminating a common blind spot between UI automation and backend QA. The flow can then be scheduled or integrated into Jenkins or CircleCI for continuous verification across builds.
Pros
- Very strong UI resilience, self-healing locators keep tests stable.
- Quick setup and visual test creation reduce scripting overhead.
- Seamless integration with CI/CD and major enterprise stacks.
Cons
- Primarily UI-focused, doesn’t validate deep code or service layers.
- Some learning curve around designing reusable components and locator strategies.
Next in the list, I have Mabl, a platform built for teams that live deep inside CI/CD pipelines and need testing to keep pace with deployment.
3. Mabl

Mabl is a cloud-based, AI-assisted testing platform designed for continuous integration and delivery. It integrates directly into pipelines like Jenkins, GitHub Actions, and CircleCI, running automated tests after each build or deployment. Unlike traditional automation tools that rely on manual triggers, Mabl runs tests continuously in the background, learning from past runs and adapting to small UI or data changes. It’s especially useful in fast-moving environments where each code push can go to production within hours.
Key Features
- CI/CD Integration: Native connectors for Jenkins, GitHub Actions, Azure DevOps, and CircleCI; test results are posted directly to the pipeline output.
- Auto-Healing Tests: Detects UI or data structure changes and adjusts test steps automatically to prevent breakage.
- Parallel Test Execution: Executes large suites across browsers and devices in parallel for shorter feedback loops.
- API Testing Support: Built-in tools for API-level testing and validation alongside UI tests.
- Agentic Workflows: Uses AI to identify redundant tests, optimize the order of execution, and surface flaky tests for review.
- SOC 2 Compliance: Meets enterprise security standards for cloud deployments.
Use Cases
- Continuous QA in CI/CD Pipelines: Automatically triggers smoke and regression suites on every deployment.
- Full-Stack Validation: Runs both API and UI tests in the same flow, ideal for microservice architectures.
- Rapid Feedback in Agile Teams: Gives near real-time test feedback to developers after code commits.
- Scalable Regression Testing: Parallel execution helps maintain coverage across fast-release cycles without increasing runtime.
Hands-On: AI-Native Test Execution and Failure Analysis in Mabl
This example shows how Mabl automates test execution, visual validation, and performance monitoring within a continuous delivery workflow. Here, a feature plan for RBAC – Resource Group Owners runs a set of end-to-end tests verifying access permissions and resource group management
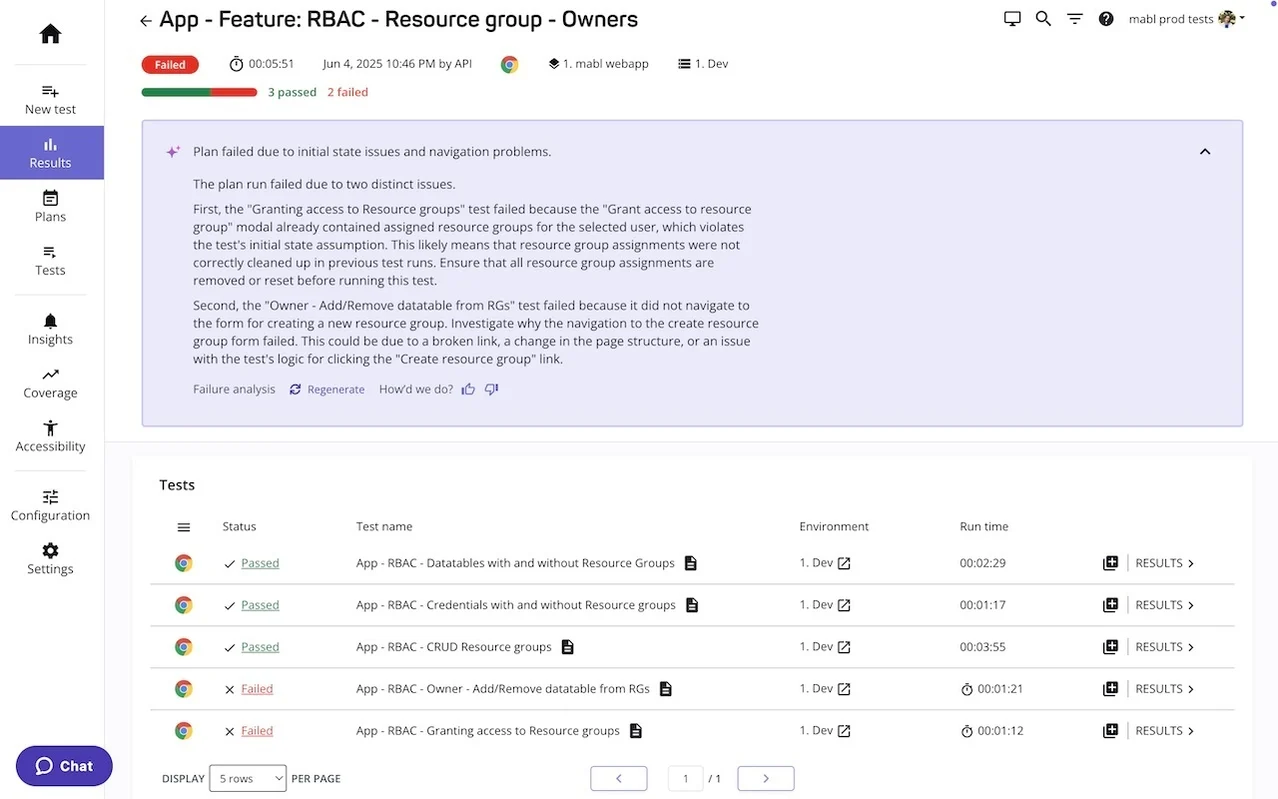
As visible in the snapshot above, three tests pass and two fail. Instead of generic failure logs, Mabl’s AI layer performs contextual analysis. It identifies that one failure stems from leftover resource group data, while another fails due to a missing navigation path when creating a new group. The platform pinpoints root causes directly in the report, allowing engineers to regenerate or fix only the affected steps.
In another plan, Mabl runs a visual smoke test to confirm UI stability across deployments.
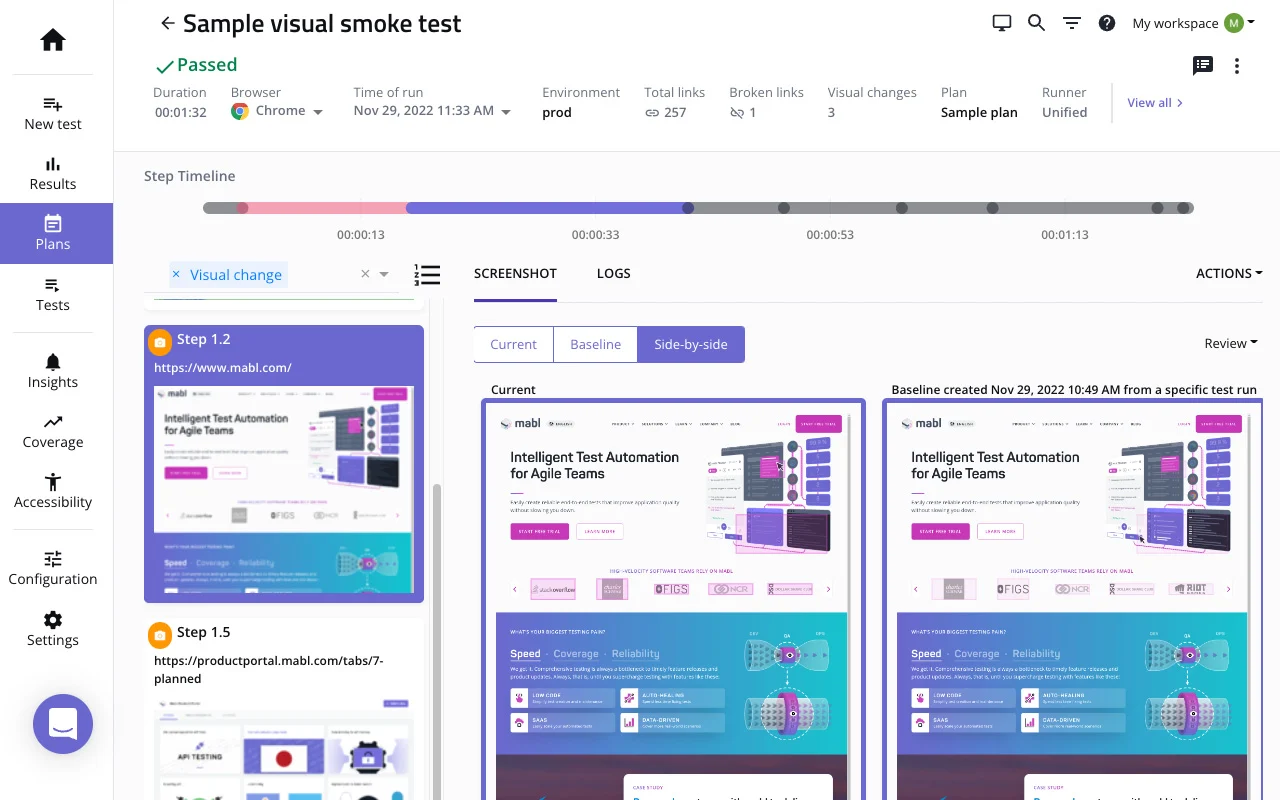
The system compares current and baseline builds side by side, detecting any layout, color, or spacing changes at the pixel level. Even subtle regressions are surfaced with visual diffs, enabling quick validation of front-end consistency across environments.
Mabl’s insights dashboard extends beyond UI and logic testing. Here, it flags a performance regression where page load time spikes to 6.5 seconds, compared to a 4-second baseline
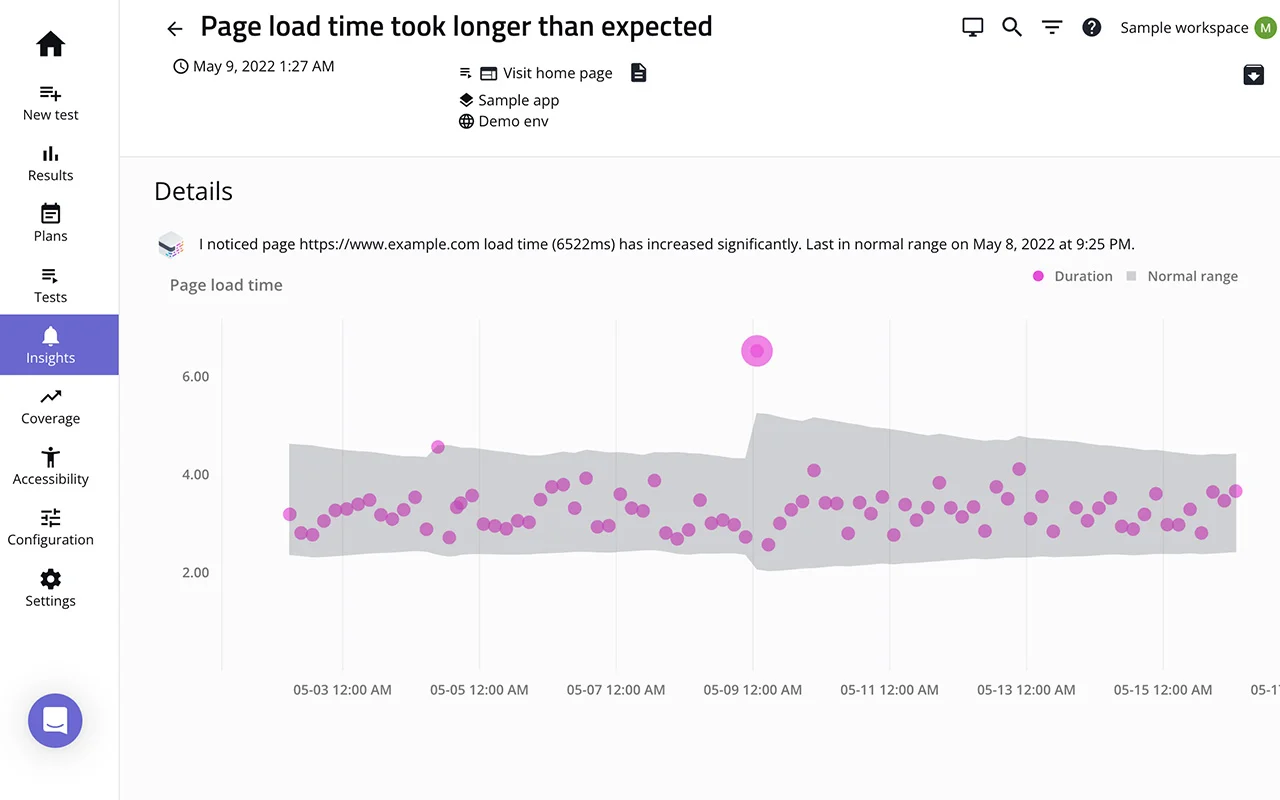
The trend visualization ties this deviation back to the specific deployment that introduced it, helping teams correlate performance issues with release changes.
Across these runs, Mabl’s AI agents handle the full test lifecycle, from execution and healing to diagnostics and performance correlation. Tests are versioned, run automatically in CI/CD, and produce structured outputs (logs, screenshots, telemetry) that plug directly into Jira or Slack. The result is a continuously learning QA loop that reduces manual triage and accelerates release validation.
Pros
- Built for CI/CD velocity, fits naturally into continuous deployment workflows.
- Strong cross-browser and API testing support.
- Reduces manual maintenance through self-healing and intelligent test selection.
- Enterprise-ready with SOC 2 compliance and audit-friendly reporting.
Cons
- Primarily UI and integration focused, not suitable for deep code or static analysis validation.
- Relies on cloud infrastructure, which may not fit tightly regulated or air-gapped environments.
4. Applitools

Applitools is built for AI-powered visual testing. Instead of comparing expected values or DOM structures, it looks at how the application actually renders, pixel by pixel, across browsers and devices. It uses what they call Visual AI, which analyzes UI snapshots against an approved “baseline” to find visual regressions, broken layouts, missing elements, or unintended design shifts. Because it works at the rendering layer, it’s framework-agnostic, it plugs into existing Selenium, Cypress, Playwright, and Appium tests without changing how those frameworks run. For large front-end teams, it becomes the safety net that ensures every release looks right, not just functions correctly.
Key Features
- Visual AI Engine: Captures rendered UI states and compares them against baselines using AI to detect changes that human eyes would notice but scripts wouldn’t, like alignment shifts or font inconsistencies.
- Ultrafast Grid: Runs visual checks in parallel across dozens of browser and device configurations, returning results in minutes instead of hours.
- Smart Maintenance: Groups similar changes together and suggests bulk baseline updates when expected design updates occur, minimizing manual review.
- Flexible Authoring: Works with both scripted and no-code approaches; you can integrate via SDKs in your existing test code or use Applitools’ recorder for quick test creation.
- Accessibility Checks: Built-in accessibility analysis for contrast ratios, alt text, and focus order validation.
- Deployment Options: Available as SaaS, private cloud, or on-prem, with APIs for integrating into enterprise pipelines and dashboards.
Use Cases
- Visual regression testing across web, mobile, and desktop applications.
- Cross-browser validation to ensure layout consistency across Chrome, Edge, Safari, and Firefox.
- Design verification during UI redesigns or theme updates to catch style regressions early.
- Accessibility audits are baked into visual test runs for compliance coverage.
- CI-integrated visual QA, full UI checks triggered automatically on every build or pull request.
Hands-On: Visual Validation and Baseline Maintenance with Applitools
This example demonstrates how Applitools integrates visual AI checks into a standard end-to-end test flow, validating both functionality and UI consistency across browsers.
A test flow is authored for the Applitools demo e-commerce site using a standard automation framework (for example, Selenium or Cypress):
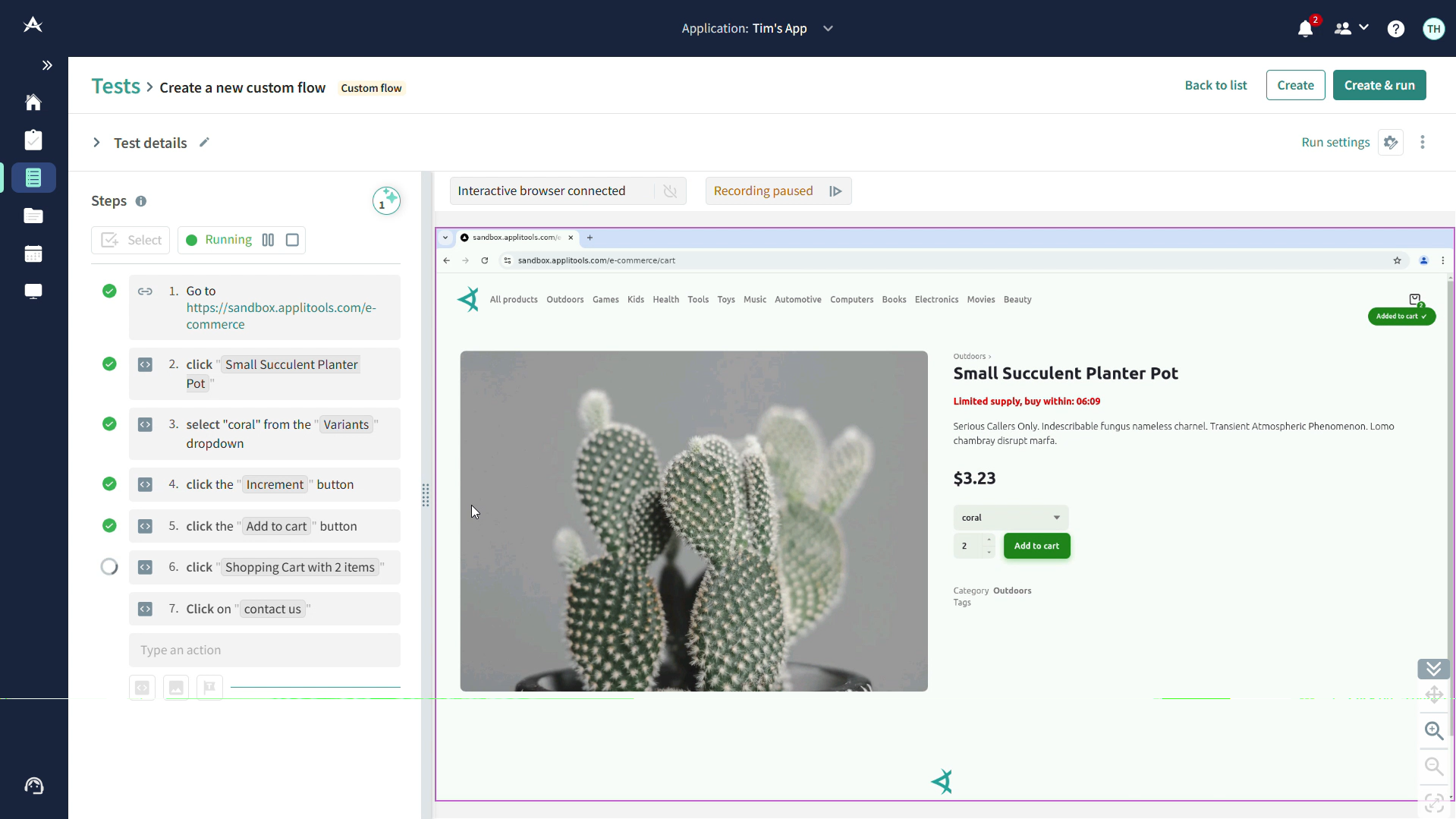
In the above snapshot, the flow navigates to the product page, selects the “Small Succulent Planter Pot”, changes the variant to “coral”, increases the quantity, and adds the item to the cart. Applitools Eyes captures a visual checkpoint at each of these actions, storing the rendered page as a baseline image. Future test runs automatically compare new screenshots against these baselines to detect visual drift.
Applitools’ Visual AI engine analyzes these images using machine vision, not raw pixel comparison, so layout shifts, hidden text, or image rendering issues are flagged while dynamic content like timestamps or ads is ignored. Match levels such as Strict, Layout, or Ignore Colors control how sensitive the comparison is, depending on the context of the test.
The flow continues by navigating to the “Contact Us” form. A new checkpoint is captured here as well.

When the test executes in different browsers or resolutions, Applitools automatically applies cross-environment baselines, ensuring visual parity between Chrome, Edge, and Safari. For dynamic elements, testers can define floating or ignore regions, reducing false positives without sacrificing coverage.
During CI/CD execution, the Eyes server performs visual diffing between the new and baseline snapshots. Differences are grouped and displayed in the Applitools dashboard, where reviewers can approve expected changes or reject unintended regressions. Approved changes automatically update baselines, maintaining test integrity without manual re-capture.
Applitools doesn’t replace functional automation; it augments it. The underlying clicks, navigations, and assertions are still performed by your test framework; Eyes adds an intelligent validation layer that ensures the application looks correct in addition to working correctly.
This hands-on example captures Applitools’ core strength: continuous, explainable visual verification with automatic baseline maintenance and adaptive match rules, ensuring UI reliability across every deployment without the noise of false alerts.
Pros
- Catches real-world visual defects that traditional automation frameworks miss.
- Parallel execution across browsers/devices drastically cuts test runtime.
- Reduces manual baseline maintenance through smart grouping and visual AI.
- Integrates easily into existing Selenium, Cypress, or Playwright setups.
Cons
- Focused primarily on UI validation, doesn’t handle logic or API testing.
- Needs clear baseline governance; unmanaged updates can mask true regressions.
- For air-gapped or internal apps, setup may require custom infrastructure and credentials.
Next in the list is Functionize, a platform built for teams that want to automate end-to-end workflows without maintaining thousands of brittle scripts.
5. Functionize
Functionize runs as a cloud-based, AI-driven test automation system. It captures metadata from every user interaction, DOM structure, CSS, network state, timing, and uses that to train models that can rebuild tests intelligently. Instead of relying on static selectors or code-based assertions, Functionize’s agents understand how each component behaves, so when the layout or structure shifts, they can identify and fix affected steps on their own. This makes it particularly useful for large enterprise applications that ship changes weekly and can’t afford manual script maintenance after every release.
Key Features
- Natural Language Test Authoring: Tests can be written in plain English or captured through the browser recorder. Functionize interprets intent and generates automation steps automatically.
- Self-Healing Execution: The system detects UI changes, element IDs, CSS updates, or layout shifts, and either repairs the test automatically or flags it with detailed context.
- Parallel Cloud Execution: Runs large regression suites across browsers and devices simultaneously without local infrastructure.
- Full Workflow Automation: Supports UI, API, database, and file-level testing in a single flow, allowing end-to-end validation of complex business processes.
- Built-in Diagnostics: Each run captures DOM, network logs, and screenshots for every step, giving developers full visibility when debugging failures.
Use Cases
- High-change frontends: Ideal for web apps where UI structures shift frequently and traditional scripts break easily.
- Cross-environment regression: Running consistent regression suites across browsers and environments in parallel.
- Full-stack business flows: Automating end-to-end workflows that touch multiple systems, from web UI to API to database.
- Mixed-skill QA teams: Enabling testers without deep scripting experience to contribute using natural language or visual authoring.
Hands-On: NLP-Driven Test Creation and Smart Maintenance in Functionize
This example shows how Functionize uses NLP-based authoring and AI-powered test maintenance to automate web application validation. Here, a test is created to verify a job search workflow on Indeed.com.
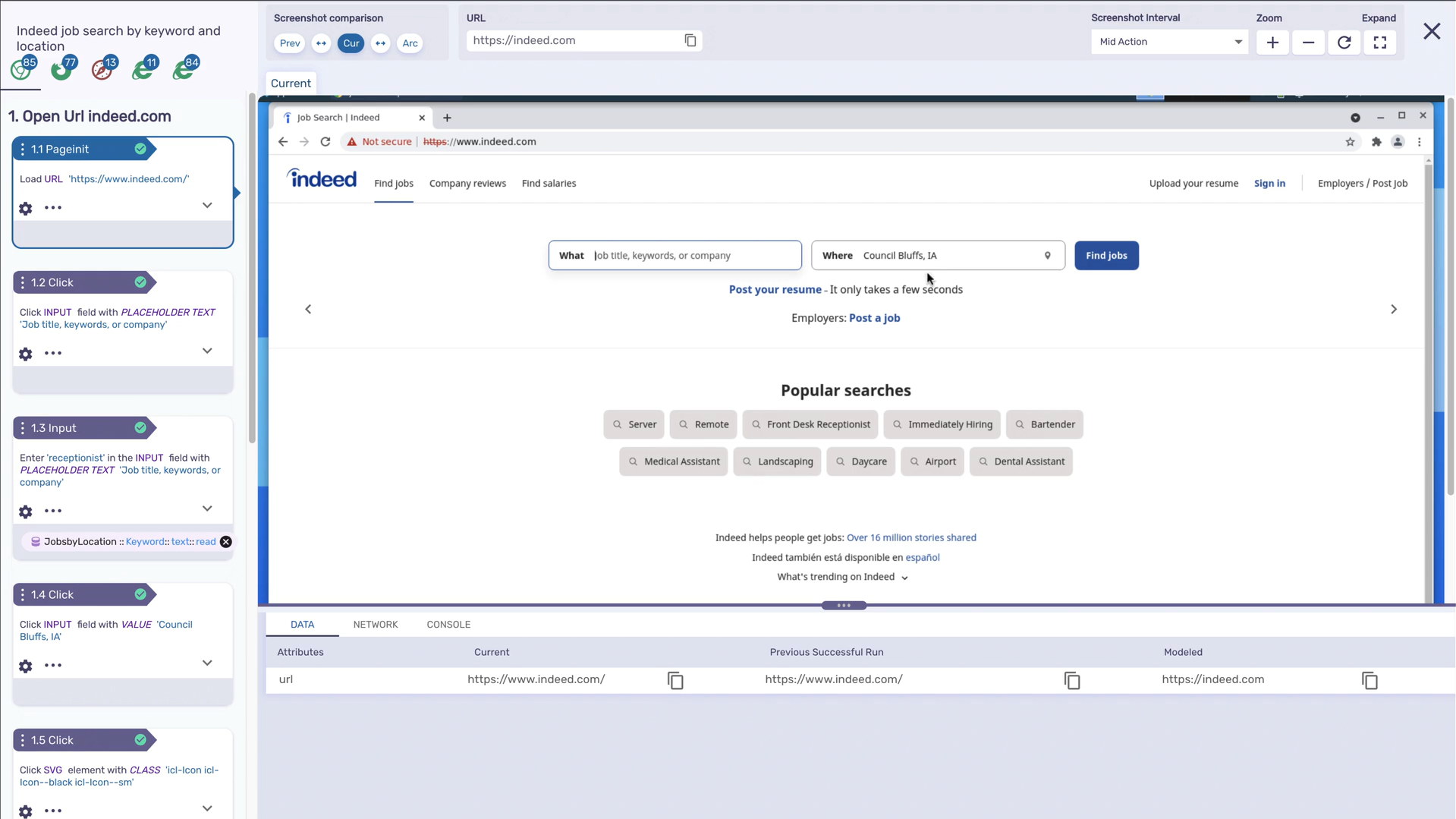
The test starts by opening the URL, entering “receptionist” as the job title, and “Council Bluffs, IA” as the location. Each interaction — clicks, text inputs, and navigation events — is captured as structured actions in the Functionize Smart Recorder. Unlike traditional scripts, Functionize’s engine models the DOM, visual layout, and network calls in real time. This context-aware capture allows the system to identify elements by intent rather than brittle selectors.
During playback, the Functionize Adaptive Execution Engine interprets each step against the latest version of the application. If the layout changes or selectors break, the Adaptive Locator Model automatically re-identifies elements using hundreds of attributes, reducing false failures.
In the test editor, as shown in the snapshot below:

Each step is displayed in natural language: “Enter ‘receptionist’ in the input field with placeholder ‘Job title, keywords, or company’.” Testers can modify, insert, or reorder steps without editing code.
Functionize’s hands-on value lies in its balance between codeless authoring and AI depth; it uses NLP for test creation, ML models for element recognition, and visual baselines for regression analysis. Together, these allow teams to maintain stable tests even as the UI evolves.
Pros
- Strong self-healing capability reduces maintenance on fast-changing UIs.
- Runs large-scale suites in parallel without managing infrastructure.
- Handles full workflow automation, not just front-end validation.
- Easy entry point for teams that want AI-driven automation without writing code.
Cons
- Requires initial setup and calibration to tune AI behavior and mappings.
- Limited suitability for air-gapped or heavily restricted environments due to its cloud-first model.
- For highly customized internal frameworks, manual scripting may still be needed for complex edge cases.
6. TestCraft
TestCraft is a SaaS-based codeless testing platform that runs on top of Selenium. Instead of scripting test flows manually, you build them visually using drag-and-drop components. The platform tracks page structures and element attributes, using machine learning to detect UI changes and automatically repair or realign broken tests. It’s aimed at QA teams that handle frequent front-end updates but don’t want to constantly rewrite locator scripts or manage Selenium infrastructure.
Key Features
- Visual Test Authoring: Create automated tests using a flow-based UI instead of code. Testers can model actions and validation steps step by step.
- AI-Assisted Maintenance: When an element or DOM attribute changes, TestCraft’s AI re-maps selectors and updates the flow automatically.
- Reusable Modules: Common sequences ike login, checkout, or navigation, can be saved and reused across multiple test suites.
- Parallel Test Execution: Supports running tests simultaneously across browsers and environments via cloud execution.
- CI/CD Integration: Connects with Jenkins, GitHub Actions, or other CI tools to trigger tests automatically on each build.
- Reporting and Version Control: Provides run history, visual diffs, and result tracking for easier debugging and release traceability.
Use Cases
- Fast-changing web UIs: Applications where layout or styling changes frequently, and static scripts break easily.
- Mixed QA teams: Environments where both engineers and non-technical testers need to collaborate on automation.
- Agile regression cycles: Continuous delivery pipelines that require reliable UI regression coverage without heavy maintenance.
- Web-only automation: Projects primarily focused on browser-based apps rather than mobile or backend systems.
Hands-On: From Element Selection to AI-Generated Test Code in TestCraft
TestCraft makes test creation almost instantaneous by combining visual element selection, AI-generated test scenarios, and automatic code conversion.
In this example, the process begins with the TestCraft browser interface, which displays key options: Pick Element, Generate Test Ideas, Automate, and Check Accessibility. Once the extension is launched, the tester opens a live web page. In this case, Infrasity’s homepage activates the Pick Element to begin mapping the UI.
As shown in the snapshot below, the top navigation bar is selected directly on the rendered site:
TestCraft highlights the chosen region in real time, confirming that the element is properly detected through its DOM and CSS attributes. After selection, the tester clicks Generate Test Ideas:
TestCraft’s AI immediately analyzes the element context and generates categorized test scenarios:
- Positive tests such as verifying that the “Home” or “Pricing” links navigate correctly.
- Negative tests like checking broken links, offline interactions, or missing JavaScript responses.
- Creative tests, such as resizing the browser to validate responsive design and accessibility.
Each idea is editable, so teams can tune the generated cases before proceeding to automation. Next, clicking Automate converts these ideas into executable Playwright tests.
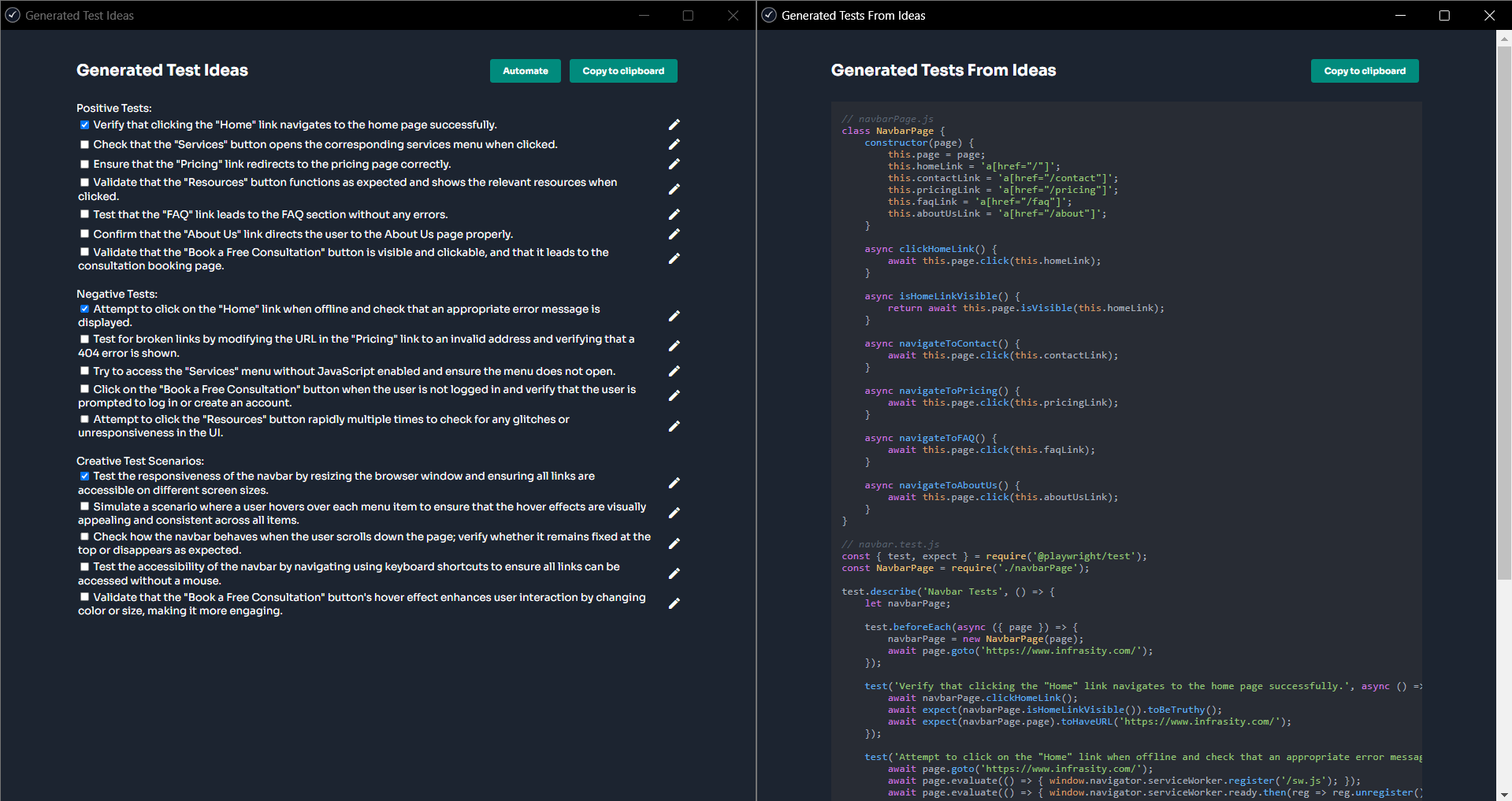
The right panel shows the generated JavaScript code. TestCraft defines reusable page objects like NavbarPage, containing functions such as navigateToContact() and clickPricingLink(), followed by complete test cases using the Playwright test runner syntax. These can be copied directly or exported to a CI/CD pipeline.
Finally, the Check Accessibility option runs automated WCAG-based validation on the selected element, testing color contrast, ARIA roles, and keyboard navigation, to ensure accessibility compliance without writing separate rules.
Through this flow, TestCraft reduces hours of manual setup to minutes. By combining AI-generated test logic, code synthesis, and accessibility validation in a single session, it delivers quick, auditable coverage for UI-heavy applications, ideal for teams needing fast validation cycles without heavy scripting overhead.
Pros
- Reduces maintenance for fast-changing web UIs through self-healing tests.
- Allows non-developers to build and maintain meaningful automation.
- Integrates cleanly with CI/CD and version control tools.
- Built on Selenium, so tests remain compatible with standard execution grids.
Cons
- Limited to web UI automation; doesn’t support backend or API testing natively.
- Requires careful test architecture planning to maximize reuse and maintain reliability at scale.
- For highly dynamic or canvas-based interfaces, element detection may still need manual adjustment.
Modern applications rarely fail because of missing buttons; they fail under scale, when APIs slow down or break under concurrency.
That’s the space Loadmill fits into since it is an AI-assisted platform for API and performance testing that builds real test cases directly from captured traffic and scales them to production-level load without any scripting.
7. Loadmill
Loadmill is an AI-assisted API and performance testing platform that automatically converts real user or API traffic into repeatable test suites. It’s designed for microservice-heavy and API-driven applications where backend behavior changes frequently.
Instead of manually authoring test scripts, teams can upload HAR files, point to API endpoints, or capture browser sessions. Loadmill uses that data to auto-generate tests. It supports both functional verification and full-scale load simulation, allowing QA and DevOps teams to validate correctness and performance from the same setup.
Key Features
- Automated Test Generation: Converts captured traffic (e.g., HAR files or API definitions) into runnable test suites automatically.
- Load & Performance Testing: Simulates concurrent API calls at scale and measures latency, throughput, and error rates.
- Self-Updating Tests: Detects schema or response changes and updates existing test definitions accordingly.
- Parallel Execution: Runs large test sets across multiple environments or regions to validate distributed deployments.
- CI/CD Integration: Command-line tools and REST APIs for integrating tests into Jenkins, GitHub Actions, or any custom pipeline.
- Detailed Analytics: Provides structured reports on response times, bottlenecks, and failure points for quick diagnosis.
Use Cases
- API Regression Testing: Automatically generating and maintaining backend regression tests after each release.
- Load Validation: Running controlled high-traffic simulations to validate service scalability and latency before production pushes.
- Microservice Testing: Coordinating functional and performance validation across multiple APIs that interact with each other.
- Post-Deployment Verification: Running lightweight smoke and latency checks immediately after deployment.
Hands-On: Building and Running API & Load Tests in Loadmill
Loadmill simplifies how teams validate and stress-test APIs by combining traffic-based recording, parameterized requests, and CI-friendly automation.
This hands-on walkthrough uses a simple API workflow, from defining requests to analyzing test results and debugging failures.
Start by opening Loadmill’s API Tests dashboard and creating a new suite, here titled Example CI Test. Under the suite, add a flow named Basic sanity test and configure a simple GET request to ${web_url} to verify your deployed app responds correctly.
As visible in the basic sanity test flow below, it shows the GET method setup with a single parameter ${web_url}:
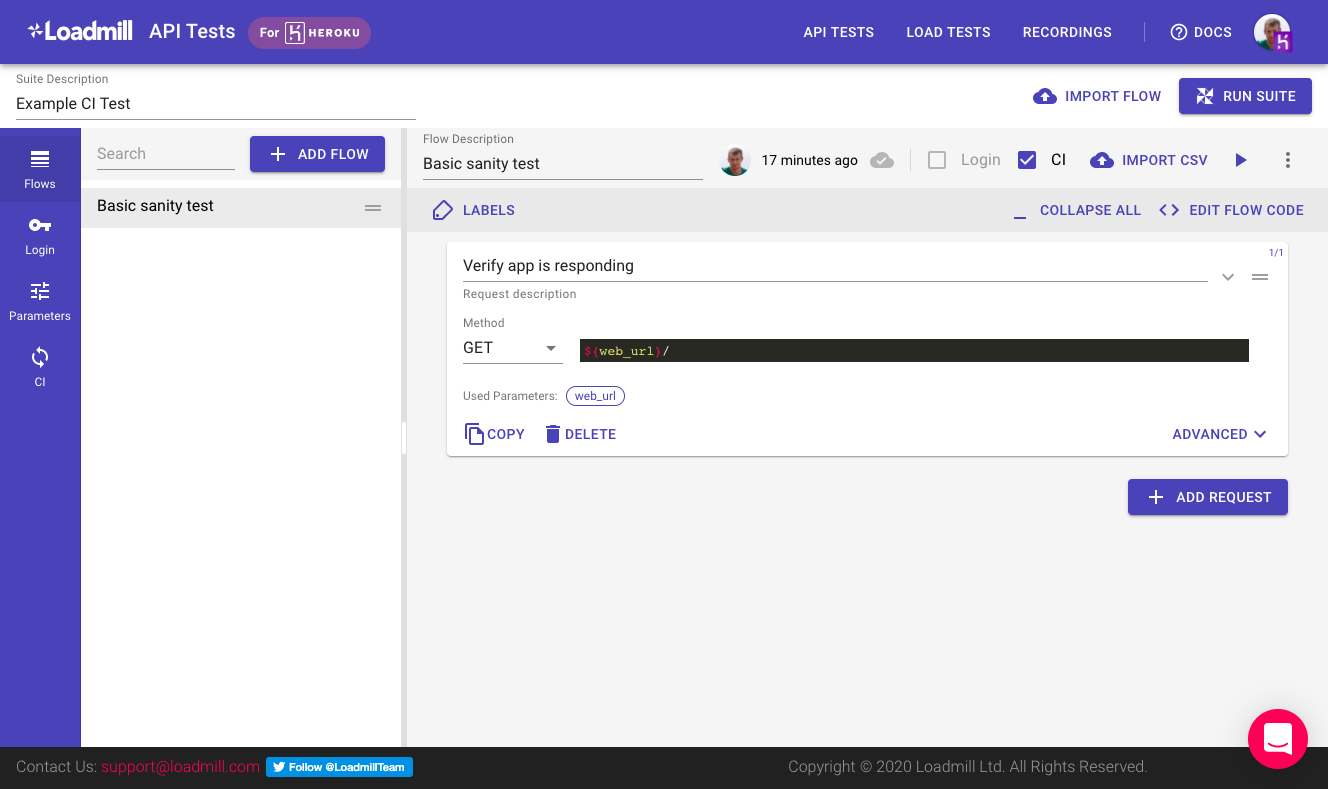
This setup acts as a heartbeat check for your environment. Since Loadmill supports variable substitution, ${web_url} can dynamically resolve to staging, QA, or production URLs defined under Parameters.
Next, in adding a dynamic API request, extend the test to cover real functionality. Create a new request, for example, to simulate a “create post” API call in a headless CMS. Set the Method to POST and the Endpoint to ${web_url}/ghost/api/v0.1/posts/?include=tags.
On the Creation of a new blog post, as done in the snapshot below:

It captures the full configuration: request body, headers, and extracted parameters. The request body uses template variables like ${blog_post_title}. You can extract response data dynamically, such as the created_post_id, using a JSONPath expression ($.posts[0].id), and validate it with an assertion to ensure it matches a numeric pattern (^\d+$). This combines both parameter injection and response verification in one step.
Once your flows are ready, mark them for CI execution. Enable the CI checkbox beside the flow title so it can automatically run in your pipeline, such as in Heroku CI or GitHub Actions, after each deployment. As shown in the snapshot below CI checkbox is enabled, which visualizes where CI is toggled on within the Loadmill interface:
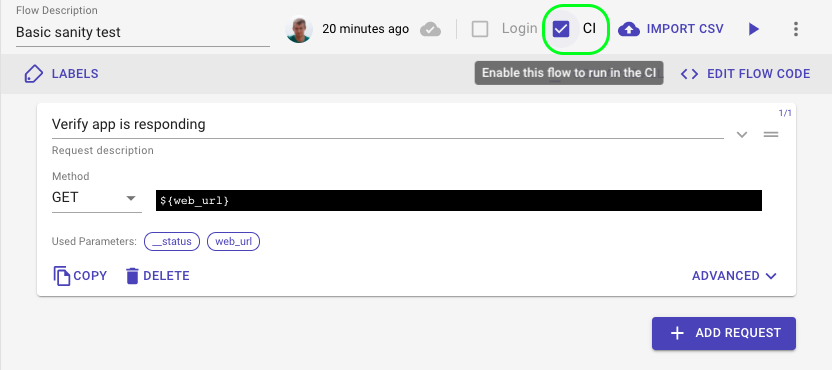
You can now run the test suite with one click using the Run Suite button, or have it execute automatically as part of your continuous integration workflow.
After execution, Loadmill displays consolidated results summarizing progress, success rate, and average duration for each flow. The snapshot below visualizes a completed run with metrics like 75% success rate, 1.1s average duration, and detailed pass/fail status per flow:
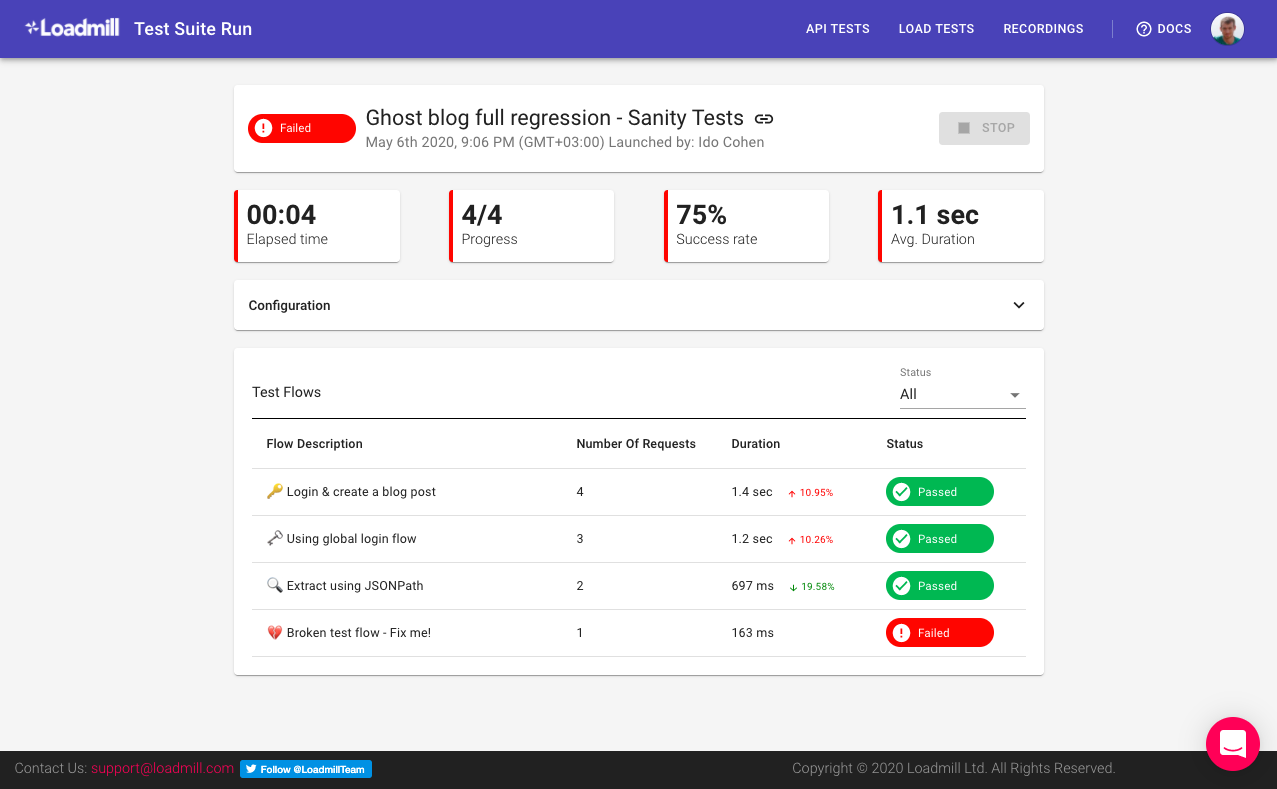
Each test flow includes a breakdown of requests, duration, and status, giving teams immediate visibility into endpoint health and runtime efficiency. When a test fails, Loadmill provides full HTTP-level diagnostics, including request headers, body, response payloads, and assertion mismatches.
In this example, a broken test returned 401 Unauthorized, pinpointing an authentication issue.
Such visibility makes it easy to debug API permission or token issues directly from the test report, without re-running the full suite manually. From the same functional flows, Loadmill can generate load tests that replicate real traffic. This hands-on flow demonstrates how Loadmill compresses the entire API test lifecycle, from endpoint validation and JSON extraction to CI orchestration and load simulation, into one cohesive workflow.
Pros
- Combines functional and load testing in a single workflow.
- Auto-generates tests from real traffic, reducing manual setup.
- Integrates easily into CI/CD pipelines with CLI and REST APIs.
- Provides deep performance analytics for backend debugging.
Cons
- Best suited for API-first systems; not a full UI testing solution.
- Cloud-first deployment can be restrictive for air-gapped environments.
- Initial setup and tuning are required to map endpoints and data dependencies effectively.
Comparison Matrix: Tools at a Glance
By this point, it’s clear that each tool serves a very different layer of the testing stack. Some, like Qodo and Functionize, focus on intelligent code-level generation and adaptive automation, while others, like Tricentis Testim or Applitools, prioritize stability and visual accuracy. For engineering leadership evaluating enterprise readiness, the decision isn’t about “best overall,” but “best fit for the architecture and QA objectives.”
Here’s a side-by-side comparison summarizing their technical focus, strengths, and trade-offs.
| Tool | Primary Focus | Key Features | Strengths | Limitations |
| Qodo | Generative & Code Integrity | Secure RAG, test/code generation, MCP integration | Built for compliance, explainability, and deep code coverage | New ecosystem; requires scoped setup |
| Tricentis Testim | UI Stability & Salesforce | AI locators, low-code test authoring, SOC 2 | Proven enterprise adoption, mature for UI/Salesforce | Limited for backend/API validation |
| Mabl | CI/CD Velocity & Continuous QA | Auto-healing, agentic workflows, SOC 2 | Strong DevOps integration, quick feedback | Primarily UI-focused |
| Applitools | Visual QA & UI Validation | Visual AI, Ultrafast Grid, accessibility checks | Detects visual regressions across browsers/devices | Doesn’t cover logic or API layers |
| Functionize | Adaptive Full-Stack Testing | Self-healing, NLP test authoring, cloud parallelism | Covers end-to-end workflows, broad scope | Cloud-first; limited air-gapped options |
| TestCraft | Codeless Web Automation | Visual modeling, AI locator repair, Selenium-based | Enables non-technical testers, lowers maintenance | Focused only on web UI |
| Loadmill | API & Performance Testing | HAR-based test generation, load simulation, and latency metrics | Combines functional and load testing in one platform | No native UI testing; setup effort needed |
Enterprise Refactoring: Scale, Risk, and Qodo’s Advantage
In enterprise environments, refactoring is less about beautifying code and more about risk management and architectural evolution. A large-scale empirical study by Timperley et al. (ESEC/FSE 2022) found that over 80% of developers in large organizations had taken part in refactoring projects spanning multiple months and exceeding 100,000 lines of code. Such efforts are often tied to modernization programs, migrating monoliths to microservices, enforcing compliance upgrades, or eliminating legacy dependencies, and they consistently expose the operational fragility of large systems.
The primary challenge isn’t just technical debt; it’s maintaining reliability and governance at scale. Enterprise codebases typically comprise hundreds of interdependent services subject to SOC 2, GDPR, and internal audit requirements. A single unsafe refactor can trigger regression failures across CI/CD pipelines or violate compliance policies downstream. Traditional IDE-based tools struggle here because they operate at the file or repository level, with little awareness of systemic dependencies or organizational rules.
Qodo approaches refactoring as a context-driven, auditable process rather than a one-off automation task. Its multi-agent architecture analyzes entire dependency graphs, honors enterprise coding standards, and automatically generates regression tests to validate functional parity. This system-wide visibility helps enterprises refactor confidently without compromising stability or compliance.
- Security & Compliance: SOC 2 Type II, encrypted data in transit, scoped retrieval to limit data exposure.
- Deployment Flexibility: Supports SaaS, private cloud, and air-gapped on-prem installations.
- Deep Integration: Native support for VS Code, JetBrains, GitHub/GitLab, and CI/CD hooks ensures minimal workflow disruption.
- Governance & Auditability: All AI actions are logged via OpenTelemetry for traceability and compliance evidence.
- Granular Access Control: Teams can explicitly scope which repositories or directories Qodo analyzes.
- Economic Impact: Enterprises report roughly 25 percent engineering time savings, earlier defect detection, and reduced rework costs.
In effect, Qodo operationalizes large-scale refactoring as a controlled, observable, and compliant engineering activity, aligning with the demands documented in enterprise software-maintenance research.
FAQs
1. What is the best tool for testing?
It depends on scope: Qodo offers unified AI-native testing across UI, API, and data layers; Testim and Functionize excel in no-code UI automation; Applitools leads in visual regression; Loadmill handles API and load testing; and TestCraft focuses on quick test ideation and accessibility. Enterprises often combine these for full-stack coverage.
2. How can generative AI improve software testing?
Generative AI accelerates test creation, expands scenarios, and auto-heals scripts as apps evolve. Platforms like Qodo and Functionize use natural language prompts to generate runnable tests and adapt them automatically, reducing maintenance while improving coverage and traceability.
3. What should enterprises consider when adopting generative AI for testing?
Focus on data security, explainability, and CI/CD integration. Platforms like Qodo address this by keeping AI-generated logic versioned, audit-ready, and pipeline-compatible. Governance, review gates, and scalability remain essential to balance automation with control.
4. How do you test an enterprise application effectively?
Use a layered approach: functional tests with Qodo or Testim, API and integration validation via Loadmill, visual and accessibility checks with Applitools or TestCraft, and performance testing under load. Unifying these in a single platform ensures reliable regression and release confidence.


