AI-Powered GitHub Code Review: 5 AI Agents That Transform PR Quality and Speed
TL;DR
- GitHub code review became the quality bottleneck in 2026: AI-assisted coding pushed PR volume up 29% YoY, but manual review can’t keep pace. Teams need AI agents that understand system impact, not just diffs.
- Context is what separates useful agents from noise generators: Shared libraries change independently, services depend on each other in non-obvious ways, and AI-generated code passes tests while breaking assumptions elsewhere.
- We tested the top 5 AI agents: Qodo, GitHub Copilot, CodeRabbit, Bito AI, and Amazon Q Developer. Each has different strengths, but only one is built for enterprise-scale GitHub estates.
- Qodo stands out for multi-repo awareness and governance: It maintains a persistent context window across repositories, enforces internal standards consistently, and creates defensible review decisions rather than generic suggestions.
Your code is the foundation of your enterprise software and everything else you built. As AI code creation has increased, traditional manual reviews are unable to keep pace, especially when AI-generated code introduces hidden, hard-to-detect defects.
While GitHub (which hosts more than 100 million developers) remains a central control plane for enterprise code collaboration, teams now need structured, scalable code review systems that match AI development velocity today. This is especially visible in large GitHub estates where teams work across hundreds or thousands of repositories and service boundaries.
Studies such as Capers Jones’ analysis of over 12,000 software projects show that even formal code reviews detect only 60-65% of hidden defects, with informal reviews catching less than 50%. This gap makes a strong case for AI-powered code review agents that can augment human reviewers, cut risk, and improve software quality at scale.
According to the 2025 GitHub Octoverse report, the volume of merged pull requests increased by 29% year-over-year, driven largely by the widespread adoption of AI coding assistants. While developers are moving faster, the verification bottleneck remains, making review the critical constraint in the delivery pipeline.
What AI Agents Are and How They Help in GitHub Code Reviews
AI agents extend automated code review by scanning pull requests, reviewing related files across the codebase, applying defined rules (such as security, retry logic, or rate limits), and identifying production risks without waiting for manual prompts.
These systems hold context across repositories, correlate behavior across services, and apply organization-wide rules to every pull request. This is a fundamental shift from static analysis or isolated LLM suggestions, which operate in short bursts and do not understand how a change fits into the broader architecture.
Why Context Is the Deciding Factor
However, for enterprise teams, a lack of context turns AI tools into noise generators. Data from the Qodo AI Code Quality Report 2025 shows that among those who say AI degrades quality, 44% blame missing context. Even among AI champions, 53% still want better contextual understanding. Without this depth, agents cannot see downstream impact or provide reliable verification.
In a recent talk, “The State of AI Code Quality: Hype vs Reality,” Itamar Friedman, CEO of Qodo, shared results from analyzing one million pull requests scanned by Qodo. 17% of those pull requests contained high-severity issues (scoring 9 or 10), meaning defects with a high likelihood of causing production impact. These were issues that would have passed manual review under time pressure and reached production without an AI agent enforcing review depth.
The Growing Pressure on Review Systems
Gartner has already signaled how this shift is growing. In the Emerging Tech Impact Radar 2025, the firm noted:
“By 2026, AI-assisted development will account for over half of new enterprise code, placing unprecedented pressure on review and validation practices.”
This pressure is visible across GitHub organizations that now manage higher output, denser diffs, and an expanding volume of AI-generated changes that require deeper scrutiny.
What Effective AI Agents Actually Do
In that environment, agentic AI tools function as constantly available reviewers. They provide:
- Architectural context rebuilt across repositories
- Dependency movement tracking
- Test behavior validation
- Change the linkage to GitHub issues
- Risk identification difficult to detect from isolated diffs
For large GitHub estates with hundreds of developers and thousands of repositories, AI agents have become the verification layer that human-only review processes can no longer sustain. They provide the depth, consistency, and governance required to keep quality at the velocity at which engineering teams now operate.
Top 5 AI Agents For Github Code Review 2026
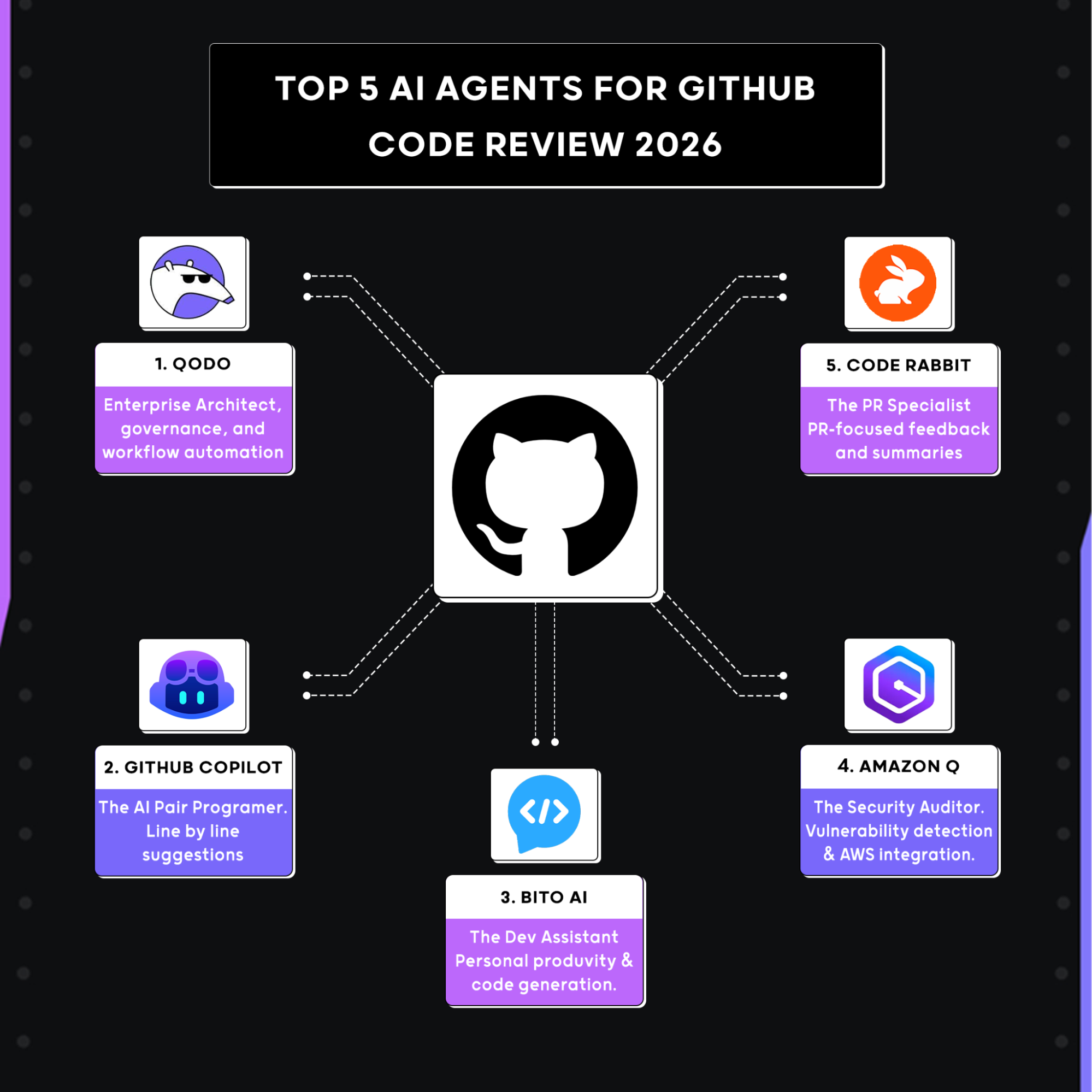
Let’s start with the top 5 AI agents. Here’s a comparison table for easier understanding:
| Criteria | Qodo | GitHub Copilot | CodeRabbit | Bito AI | Amazon Q |
| Context Depth Across Codebase | Yes | No, diff-only | No, PR-only | No, isolated | No, workspace-level only |
| Review Accuracy Under Load | Yes | No, varies with PR size | No, degrades on large diffs | No, medium-signal heavy | No, security-focused only |
| Multi-Repo Awareness | Yes | No, single repo | No, single repo | No, single repo | No, dependencies only |
| Workflow Automation | Yes | No, comments only | No, comments only | No, no enforcement | No, outside PR flow |
| Test Intelligence | Yes | No, opportunistic | No, limited | No, checklist-level | No, not covered |
| Governance and Audit | Yes | No | No | No | No, security-only |
| Organizational Knowledge | Yes | No | No | No | No |
1. Qodo AI Agent
Qodo is the best AI code review platform for enterprises, treating review as a system-level verification problem rather than comment generation. It actively enforces code quality, consistency, and architectural alignment across the SDLC.
Most defects from AI-generated code come from missed edge cases, unfollowed practices, or cross-repository misalignment. Qodo operates with a persistent organizational context, rebuilding it across repositories, shared libraries, historical decisions, and internal standards. This allows it to reason about downstream impact, architectural drift, and policy violations invisible in a single diff.
Qodo pushes verification earlier in the SDLC by enforcing architectural, security, and quality checks at the PR stage, before defects spread. It’s one-click remediation closes the loop between detection and resolution, applying verified fixes directly for faster remediation without slowing delivery.
From a leadership perspective, Qodo works as a review layer that enforces consistency when human attention becomes the limiting factor, creates evidence for why changes are risky or acceptable, and integrates directly into GitHub PR workflows.
Key Features
- Organization-wide context across repositories and services
- Multi-repository dependency and shared library awareness
- Review logic informed by historical decisions
- Enforcement of internal engineering and security standards
- Native GitHub integration with merge controls
- Deployment options: on-premises, VPC, zero data retention
Hands-On Example: Cross-Repository Dependency Risk
I tested Qodo in a GitHub system with multiple repositories sharing internal utilities. The PR modified the application logic relying on formatCurrency from shared-utils as shown in the snapshot below:
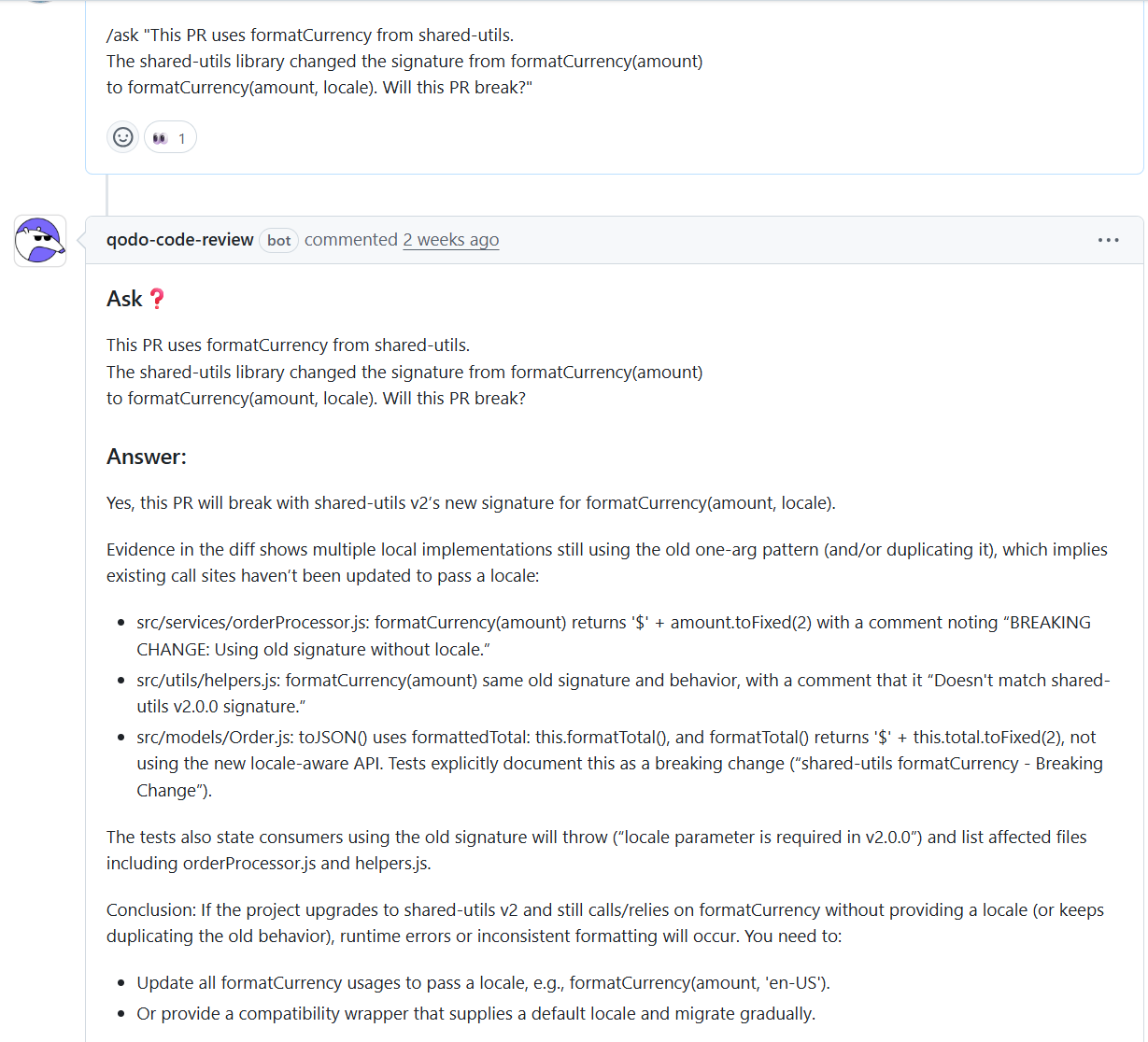
The shared library had changed the signature from formatCurrency(amount) to formatCurrency(amount, locale), but the PR didn’t introduce this change. The diff looked safe, tests passed.
Qodo traced formatCurrency usage across the repository, finding multiple local implementations still using the old signature. It flagged that consumers calling formatCurrency without a locale would throw errors after the utility upgrade. The review also caught API calls to payments-service missing required authorization headers.
Pros
- Identifies cross-repository and architectural risks that diff-based tools miss
- Maintains review quality as PR volume and AI-generated code increase
- Creates high-signal feedback that developers trust and act on
- Encodes institutional knowledge from senior reviewers
- Supports governance and audit needs without manual overhead
Cons
- Requires initial setup to index repositories and define standards
- Best for mature organizations with complex GitHub estates
- May feel heavy for teams wanting only style suggestions
Pricing
- Free: $0/month, limited credits
- Teams: ~$30/user/month, collaboration features, private support
- Enterprise: Custom pricing, SSO, analytics, multi-repo context, on-prem
2. GitHub Copilot (Pull Request Review)
GitHub Copilot’s PR review extends Copilot into the review phase. Its primary value is proximity: built into GitHub, minimal setup, fast inline feedback without a separate system.
Copilot operates at the diff and file level, useful for catching low-effort issues early in repositories with informal standards or where teams want quick feedback before human review.
Where Copilot shows limits: scale and context. Limited understanding of how repositories relate, how internal libraries are consumed downstream, or how architectural decisions are being made. Best treated as an assistant to individual developers, not a system enforcing organization-wide review quality.
Key Features
- Native PR review inside GitHub
- Inline comments on diffs and changed files
- Detection of common bugs and logic errors
- Suggestions for test improvements
- Tight integration with Copilot code generation
Hands-On Example: Single-Repository API Review
I tested Copilot on a Node.js API PR, adding an endpoint that returns a random game record. Copilot immediately flagged that the database connection object was being returned in the response, explaining that it leaks internal details and could expose sensitive information.
It also identified a runtime issue: the code throws an error if the games array is empty (Math.random() * 0 attempts to access a non-existent element):
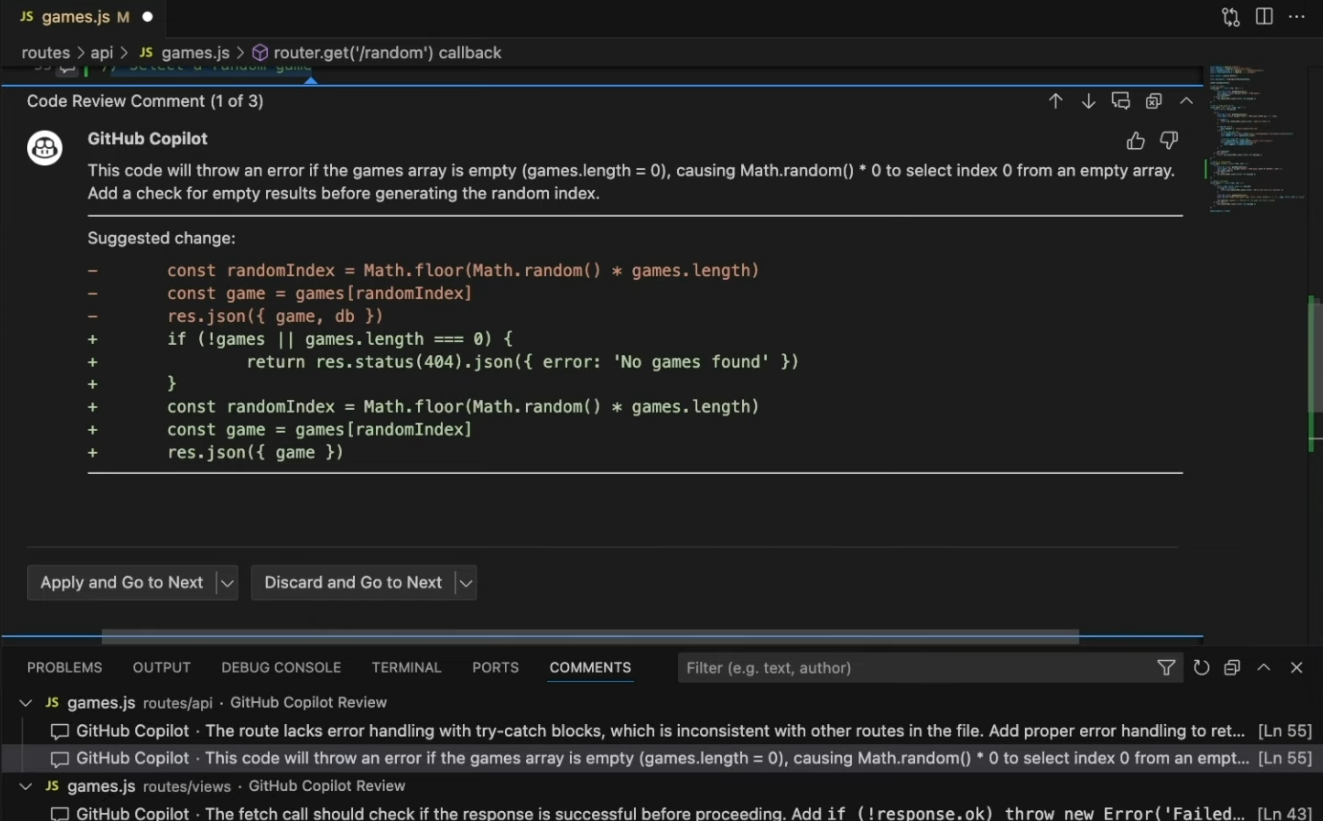
Additionally, it noted an inconsistency in error handling patterns compared to other routes in the file. The example shows Copilot operates as a local reviewer improving individual PRs, not enforcing correctness across a broader codebase.
Pros
- Extremely easy to adopt for existing Copilot users
- Fast feedback during early review
- No additional tooling or workflow changes
- Works well for individual contributors and small teams
Cons
- Limited understanding beyond the current repository
- No organizational or historical context
- Feedback varies with prompt and usage patterns
Pricing
- Free: $0/month, limited usage
- Pro: $10/month or $100/year
- Pro+: $39/month or $390/year
3. CodeRabbit
CodeRabbit positions itself as an automated reviewer focusing on conversational feedback inside pull requests. It aims to replicate detailed comments on a diff, emphasizing readability, maintainability, and common correctness issues.
CodeRabbit operates at the PR level. The limitation appears when the review needs to scale beyond a single repository or service boundary. It doesn’t maintain a durable model of how repositories interact, how shared components are consumed downstream, or how architectural constraints change over time.
Key Features
- Automated PR reviews with conversational comments
- Inline explanations focused on readability and maintainability
- Detection of common logic errors and edge cases
- GitHub integration with threaded discussions
- Configurable review tone
Hands-On Example: Frontend Component Review
I tested CodeRabbit on a frontend change with React components, including custom wrappers around react-big-calendar. CodeRabbit explicitly lists files and hunks selected for processing, providing transparency. As visible in the snapshot below:
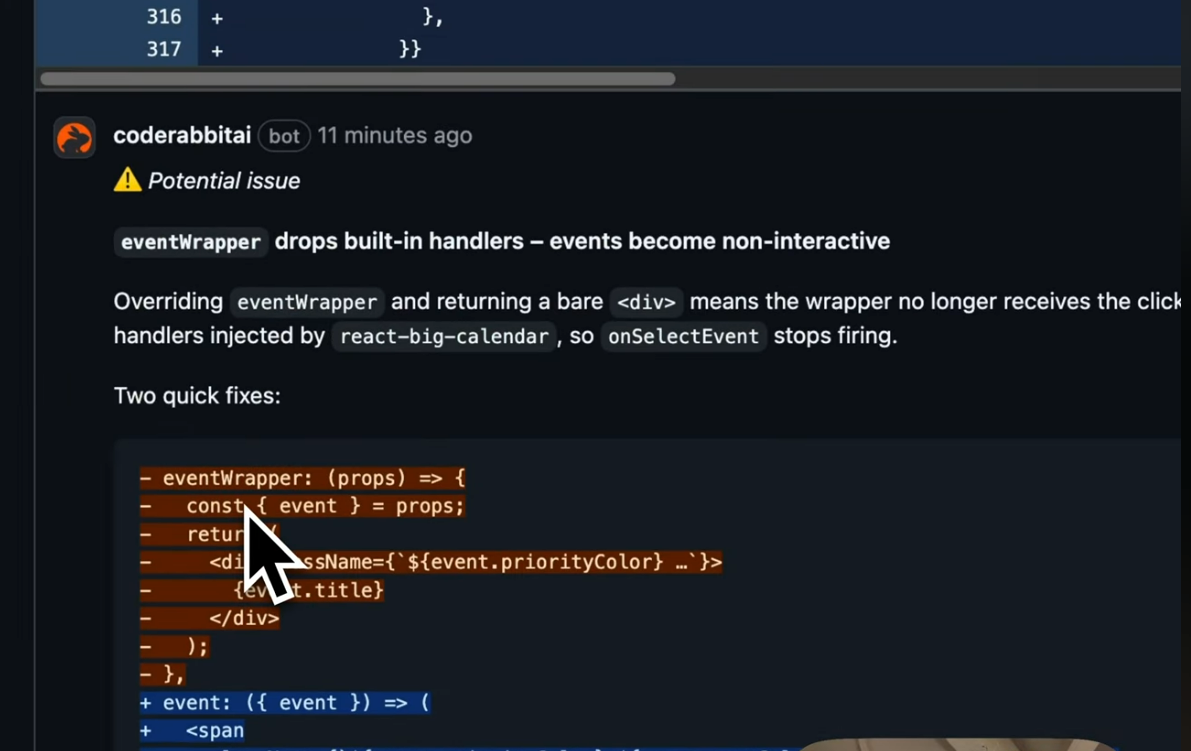
It flagged that overriding eventWrapper with a bare <div> drops built-in click handlers from react-big-calendar, causing onSelectEvent to stop firing. This is a behavioral regression appearing only at runtime. The explanation was specific and actionable, proposing fixes to preserve injected props.
The analysis doesn’t extend to other repositories, shared design systems, or historical patterns. Feedback is accurate within the local context but doesn’t reason about broader architectural consistency.
Pros
- Human-like review comments, easy to read
- Helpful for improving code clarity and local correctness
- Faster feedback than a manual-only review
- Low setup effort
- Suitable for teams valuing narrative feedback
Cons
- Limited to PR and repository-level context
- No cross-repository awareness
- Review accuracy depends on the local context only
Pricing
- Free: $0/month, 14-day Pro trial, free for open-source
- Pro: $24/month (annual) or $30/month per developer
- Enterprise: Custom pricing, self-hosting, multi-org support
4. Bito AI Code Review Agent
Bito’s code review agent provides fast, assistive feedback inside pull requests, focusing on common issues like logic errors, missing validations, and basic security concerns. Emphasis on speed and accessibility.
Bito operates at the PR and file level, analyzing diffs and applying general reasoning patterns to improve correctness and clarity. Works well for catching obvious problems early, where manual review bandwidth is limited.
Constraints appear in environments with complex dependency graphs or strict organizational standards. It doesn’t maintain persistent context across repositories or learn organization-specific system structures.
Key Features
- Automated PR review inside GitHub
- Detection of common bugs and logic issues
- Suggestions for code clarity and structure
- Basic security and best-practice checks
- Lightweight setup
Hands-On Example: Documentation Change Review
I tested Bito on a documentation PR, replacing Mermaid.js with Code2Flow for flowcharts. Bito creates structured analysis rather than inline comments: summarizes the theme, classifies as an enhancement, assigns a score (85/100), and estimates review effort as shown in the comment below:
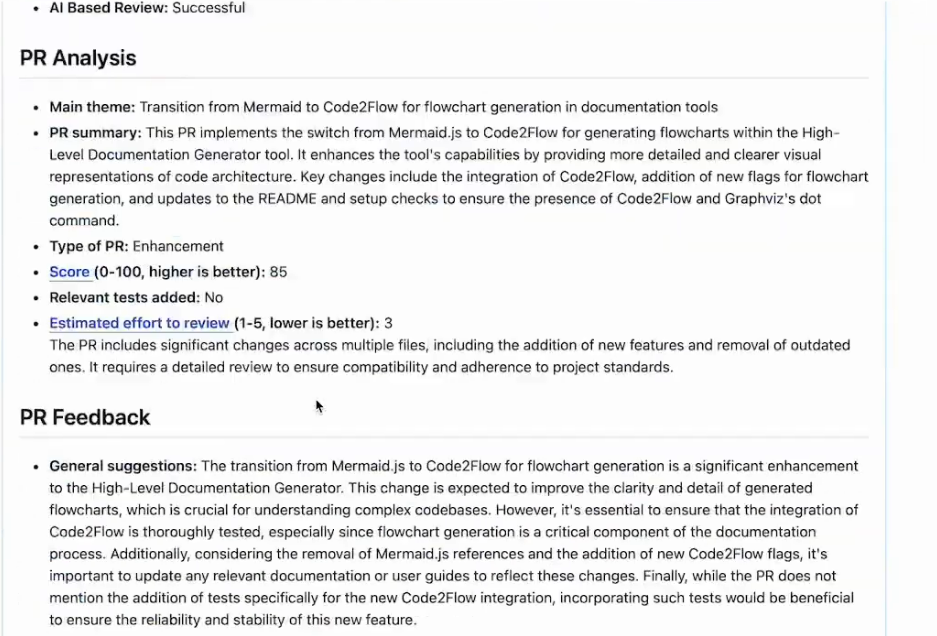
It explicitly notes no relevant tests were added, framing this as a review signal rather than a failure. Suggests that since flowchart generation is key, adding tests for Code2Flow integration would improve reliability.
This shows Bito’s approach: summarization and risk-assessment. Helps reviewers understand what changed and what deserves attention, but doesn’t reason about hidden regressions, dependency interactions, or downstream impact.
Pros
- Quick adoption with minimal disruption
- Immediate feedback on common issues
- Useful for improving baseline coverage
- Works well for small to mid-sized teams
- Low operational overhead
Cons
- Feedback quality varies with prompt structure and repository cleanliness
- Many low-to-medium priority comments without a strong severity ranking
- Limited ability to distinguish style from correctness
Pricing
- Free: $0/month, basic reviews, limited suggestions
- Team: ~$15/user/month, unlimited suggestions, deep reviews
- Enterprise: Custom pricing, org-wide deployment, self-hosted
5. Amazon Q Developer
Amazon Q Developer approaches code review from a cloud and infrastructure-first perspective. Tightly coupled with AWS, most effective where application code, infrastructure definitions, and deployment workflows are intertwined with AWS services.
Amazon Q’s strength: awareness of AWS APIs, service limits, IAM patterns, and infrastructure-as-code conventions. When reviewing IAM policies, SDK usage, CloudFormation, or CDK, it catches issues that repository-only reviewers miss.
That specialization defines its boundary. Amazon Q doesn’t model an organization’s full architecture across repositories or learn from historical review decisions. Review output is strongest for cloud misuse or misconfiguration, weaker for architectural drift, cross-repo coupling, or internal conventions.
Key Features
- PR review focused on AWS-related code and infrastructure
- Detection of insecure or incorrect AWS API usage
- Analysis of IAM, permissions, and cloud access patterns
- Infrastructure-as-code review support
- Alignment with AWS security guidance
Hands-On Example: Dependency Vulnerability Detection
I tested Amazon Q on a backend service with Python and requirements.txt. No recent code changes, just dependencies. Amazon Q scanned and immediately flagged a high-severity vulnerability in Flask 2.0.1, categorized with multiple CWE identifiers.
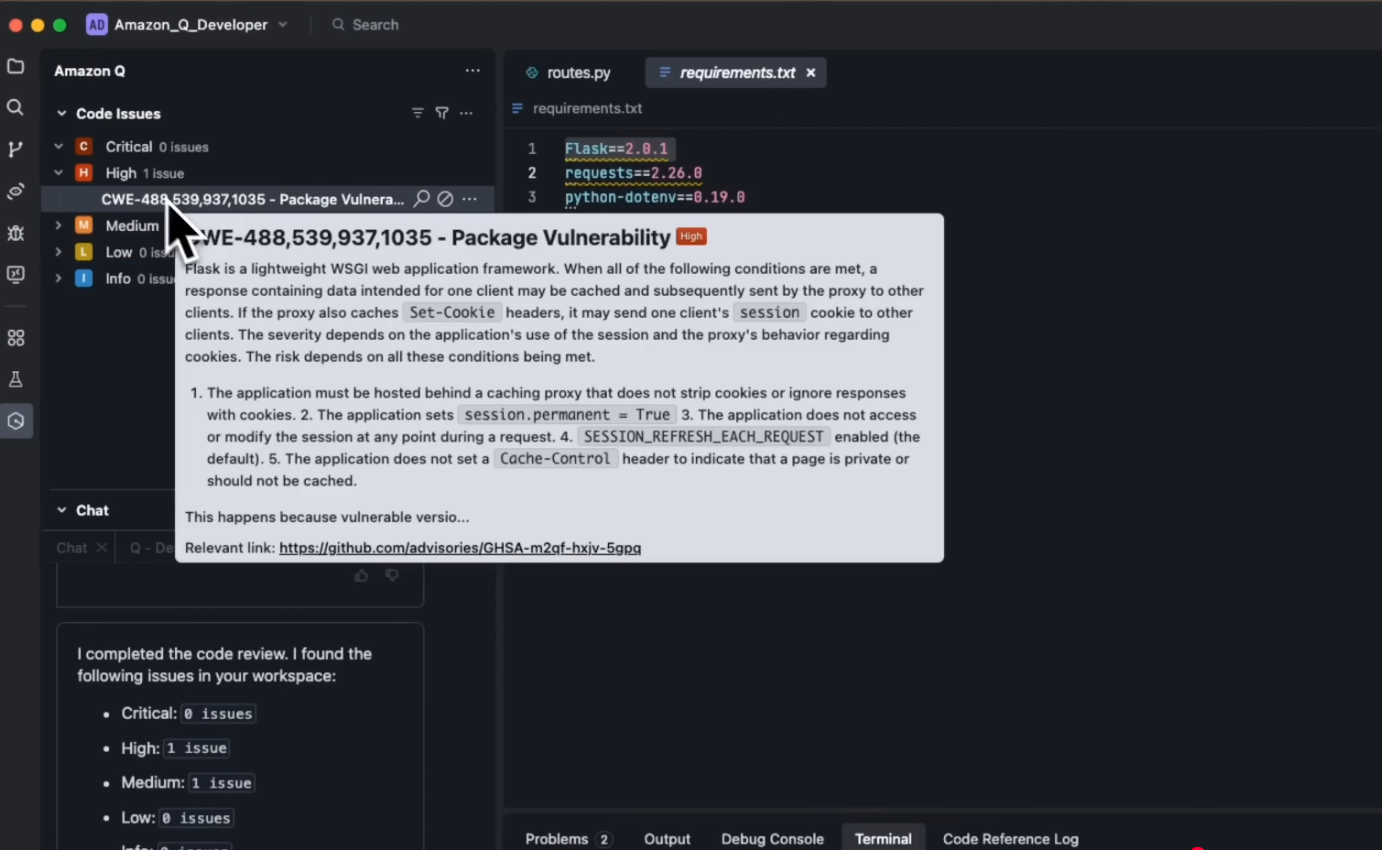
It explained precise conditions: how session cookies may be cached and replayed when behind a proxy, not stripping Set-Cookie headers.
Review scope remains bound to known vulnerabilities and package metadata. Can’t reason about how this service interacts with other repositories, whether internal standards are followed, or how similar risks are handled elsewhere.
Pros
- Strong signal for AWS service usage and permissions
- Catches cloud misconfigurations before production
- Useful for heavy infrastructure-as-code adoption
- Integrates naturally into AWS environments
- Cuts reliance on manual cloud security review
Cons
- Review quality drops outside AWS-focused paths
- Limited cross-repository understanding
- Doesn’t learn from organizational history
- Best used alongside, not instead of, system-level agents
Pricing
- Free: $0/month, basic AI coding help
- Pro: ~$19/user/month, higher limits, team controls
Choosing the Right AI Review Agent Is a Governance Decision
In 2026, GitHub code review has become the primary point where engineering teams manage quality and risk. Pull request volume is higher, changes are more interconnected, and AI-assisted code creation has increased the likelihood that issues slip through under time pressure.
Among the tools checked, Qodo stands out as the only agent built to operate as a true review layer for large GitHub estates. Its ability to maintain context across repositories, apply organization-wide standards, and create defensible review decisions makes it suited for teams that treat code review as a governance function rather than a convenience.
As review becomes the limiting factor in delivery pipelines, systems that preserve judgment under load will define how well organizations balance speed with reliability.
FAQ
1. Does Qodo require developers to change how they work in GitHub?
No. Qodo operates directly inside existing GitHub pull request workflows. Developers open pull requests as usual, and Qodo runs automatically in the background. There are no prompts to manage and no separate review interface to learn. Feedback, evidence, and remediation options appear where reviewers already work (inside the pull request itself).
2. How does Qodo reduce false positives compared to other AI review bots?
Qodo relies on a persistent codebase context rather than checking each pull request in isolation. It factors in shared libraries, historical review decisions, and internal standards when assessing risk. This allows it to prioritize issues that are likely to cause production impact and suppress repetitive or low-signal comments that typically lead to alert fatigue.
3. Can Qodo be used in organizations with hundreds of repositories?
Yes. Qodo is built for large GitHub estates where services and libraries change independently. It maintains context across repositories and checks downstream impact, which is important for catching breaking changes, duplicated logic, and architectural drift that single-repo tools cannot detect.
4. Are AI code review agents meant to replace human reviewers?
No. AI review agents augment human reviewers rather than replacing them. Their role is to maintain review depth and consistency as pull request volume increases. Human reviewers still make final decisions, but they do so with better context, clearer evidence, and reduced manual scanning effort.
5. When is a lighter AI review tool a better fit than an enterprise review layer?
Lighter tools work well for small teams, single-repository services, or early-stage projects where architectural complexity and governance requirements are limited. In these cases, catching obvious bugs and improving baseline quality is often sufficient. As systems grow and risk shifts to cross-repository interactions, stronger review layers become necessary.
6. How does Qodo compare to GitHub Copilot for enterprise code review?
GitHub Copilot PR review is best for individual developers and small teams working in single repositories. It catches local issues quickly but lacks cross-repository awareness, organizational context, and governance capabilities. Qodo is built for enterprise scale, making sure persistent context across hundreds of repositories, enforcing organization-wide standards, and creating audit-ready evidence. For large GitHub estates, Copilot works as a development assistant while Qodo functions as a review infrastructure layer.


