State-of-the-Art Code Retrieval With Efficient Code Embedding Models
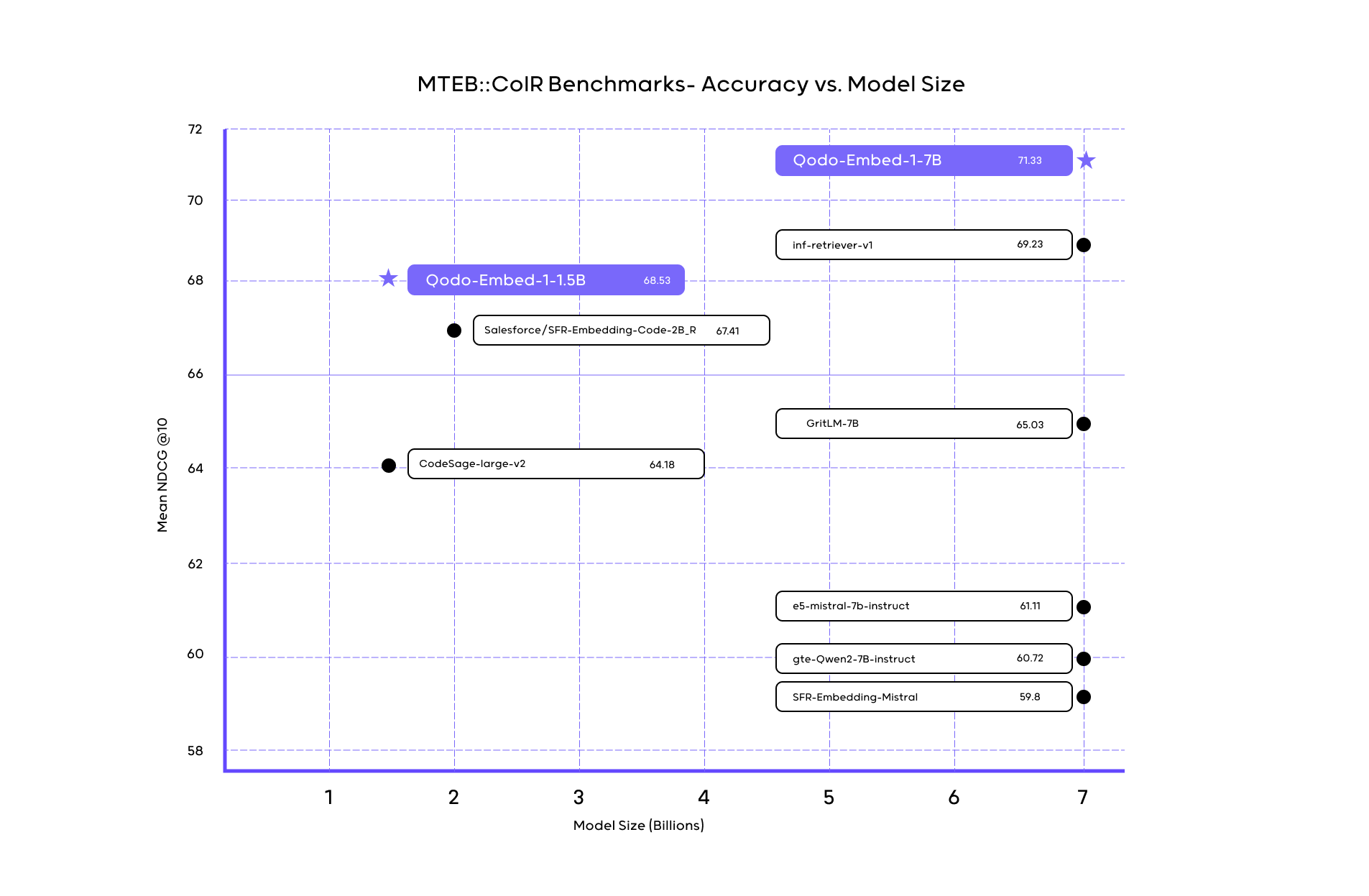
Today, we’re excited to announce Qodo-Embed-1, a new code embedding model family that achieves state-of-the-art performance while maintaining a significantly smaller footprint than existing models. On the CoIR benchmark—which measures the model’s proficiency in retrieving context—our 1.5B model scored 68.53 surpassing larger 7B models. Qodo-Embed-1-7B, Qodo’s larger model, also outperforms models of the same size, scoring 71.5. In this blog, we’ll share our approach to training code embedding models using synthetic data generation.
The challenge with code embedding models
The main challenge with existing code embedding models is their difficulty in accurately retrieving relevant code snippets based on natural language queries. Many general-purpose embedding models like OpenAI’s text-embedding-3-large focus on language patterns rather than code-specific elements like syntax, variable dependencies, control flow and API usage. This gap leads to irrelevant or imprecise search results and code retrieval, critical for enabling AI coding agents.
Here’s an example of a typical case where general purpose embedding models fall short:
Query: Make operations more reliable when they might occasionally fail
Ideally, we’d expect a code snippet implementing a retry or fail-safe mechanism. However, a general-purpose embedding model (like OpenAI’s text-embedding-3-large) returns the following code:
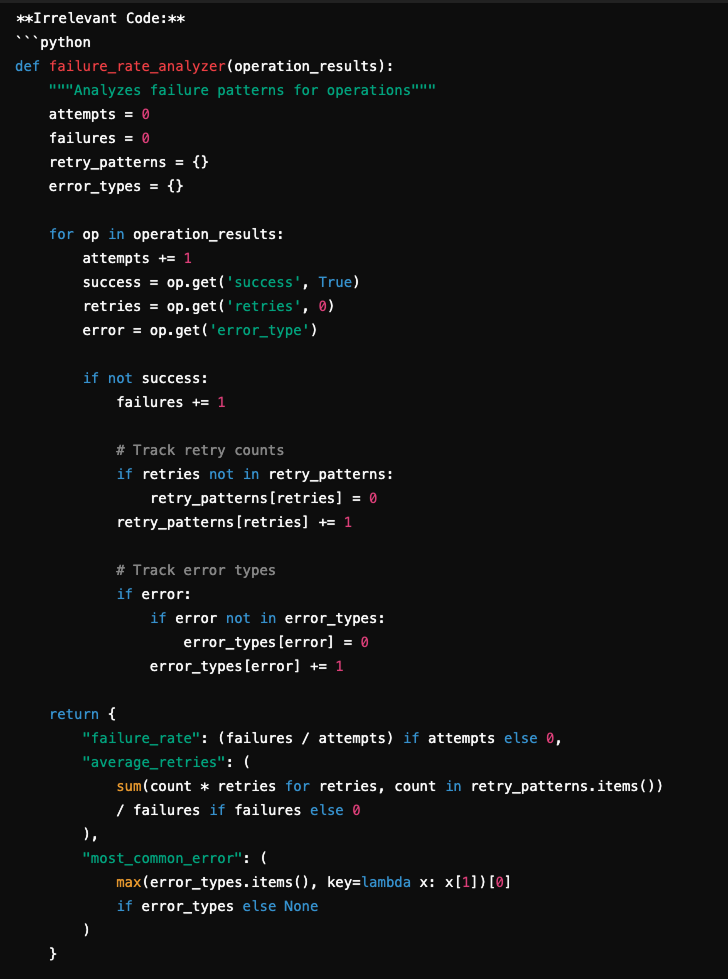
Although this snippet is correctly associated with ‘failures’ and ‘operations’, it doesn’t actually implement functionality to ensure reliability or handle operational failures — it just reports on them after the fact. General embedding models tend to latch onto shared keywords (“failure,” “operations”), and miss nuanced but critical differences in the intended functionality. Without training specifically on code functionality and semantics, embedding models fail at distinguishing between things like analyzing failures (post-event analysis) and proactively handling or mitigating failures.
Initially, we addressed the semantic mismatch by generating natural-language descriptions for our code snippets using LLMs, and indexing snippets using these descriptions in addition to the raw code. This dual-indexing approach allowed our retrieval system to better align natural-language queries with relevant code snippets, significantly improving search accuracy. However, generating these descriptions introduced substantial computational overhead, increased indexing complexity, and added latency.
By using a code embedding dedicated model, we can skip the description-generation step without sacrificing performance. This simplifies the system and reduces costs.
Synthetic Data Generation
We fine-tuned two embedding models, based on Qwen2-1.5b and Qwen2-7b respectively, but encountered a significant challenge in acquiring the training data needed to give the model an understanding of both programming languages and natural language. Synthetic data helped here by generating natural language descriptions for existing code to fill in the gaps.
For Qodo-Embed-1, we built a pipeline that automatically scrapes open-source code from GitHub, applies multiple filtering steps for quality, and then injects the data with synthetic function descriptions and docstrings.
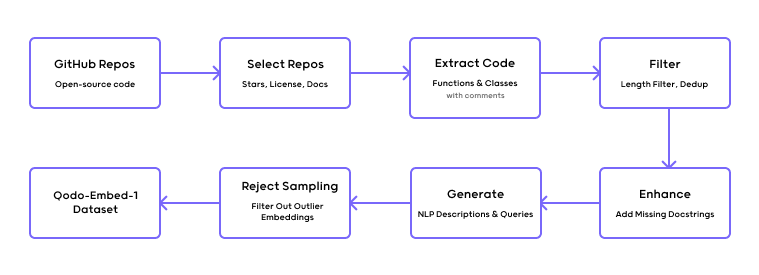
Docstring Generation
For functions lacking documentation, we generate multiple synthetic docstrings that vary in style, from formatted documentation to concise natural language summaries.
The prompt we use for generating synthetic docstrings:
Input: A Python function or method without a docstring.
Output: A concise and informative doc-string describing the function’s purpose, in-puts, and outputs.
Prompt: Generate a detailed docstring for the following function. Include:
-
- A clear description of what the function does
- All parameters with their types and descriptions
- The return value(s) with type and description
- Any exceptions that may be raised
Here is the function: [INPUT FUNCTION HERE] Format the docstring using Google-style docstring format. Be specific about types and ensure the documentation is clear and comprehensive. Provide only the docstring and nothing more
Code Query Generation
To enable code search and retrieval tasks, we needed to improve semantic alignment between code and queries and augment docstrings with additional context. We used a prompt to generate natural language queries that correspond to the given code:
Input: A code snippet implementing a specific functionality.
Output: A natural language query that a developer might use to search for this functionality.
Prompt:
You are a query generator. Your task is to produce ONLY a brief and concise natural-language search query that developers could use to find similar code solutions. The code snippet to analyze will be provided below.
OUTPUT RULES:
– Generate ONLY the search query.
– No explanations or additional text.
– Length: 10-30 words.
– Use common programming terminology.
– Clearly capture the core functionality of the code.
GOOD EXAMPLES:
[Insert clear and concise examples of good code search queries here.]
BAD EXAMPLES:
[Insert examples of poor-quality queries here.]
INPUT FUNCTION:
[Insert function signature or definition here]
FUNCTION DOCSTRING:
[Insert existing or generated docstring here]
CODE SNIPPET:
[Insert the full code snippet here]
Benchmarking Qodo-Embed-1
The CoIR benchmark (Code-Oriented Information Retrieval) is a standardized evaluation framework designed to assess the performance of AI models in retrieving and understanding code. It measures a model’s ability to perform various code retrieval tasks across different programming languages.
Qodo-Embed-1-1.5B achieves an exceptional balance between efficiency and performance, outperforming significantly larger models despite its smaller size. On the CoIR benchmark it achieves a score of 68.53, surpassing much larger competitors like OpenAI’s text-embedding-3-large (65.17), as well as models of similar scale such as Salesforce’s SFR-Embedding-2_R (67.41). Meanwhile, Qodo-Embed-1-7B further raises the bar by scoring 71.5, outperforming similarly sized models. This efficiency allows teams to effectively search vast codebases without incurring high computational or infrastructure costs, enabling broader and more practical deployments.
Now, let’s revisit our earlier query:
Query: Make operations more reliable when they might occasionally fail
When using our specialized code embedding model, Qodo-Embed-1-7B, the retrieved result aligns better with the intention behind the query. Rather than simply analyzing past failures, the returned snippet implements a proactive retry mechanism to enhance reliability:
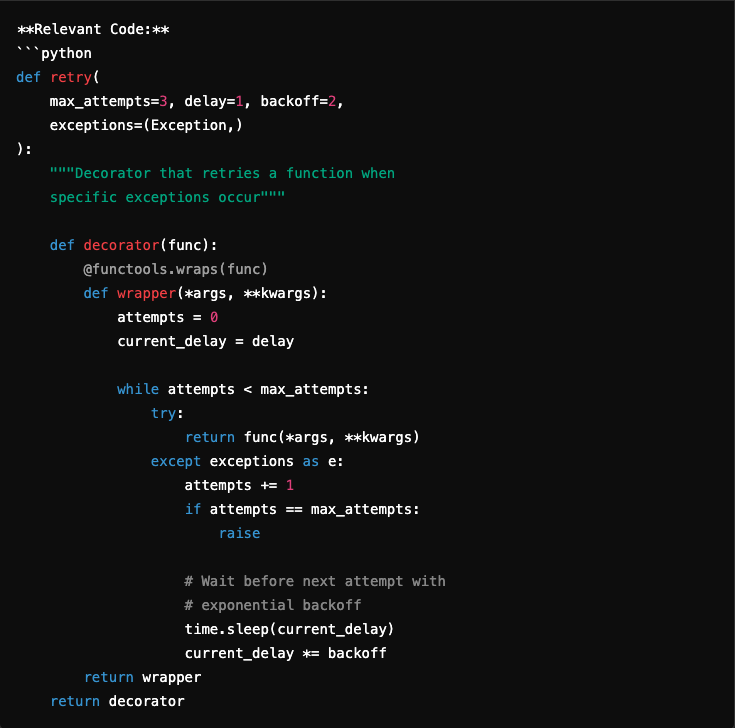
This snippet is a better fit because it directly addresses the user’s intent by actively handling operational failures through a simple retry mechanism. Instead of relying solely on matching keywords like “failure” or “operations,” the Qodo embedding model understands the underlying semantic meaning of the query, enabling it to return an example that meets the user’s practical needs.
Why model size matters
While large-scale models are powerful, their size can limit accessibility and deployment. Qodo-Embed-1 is designed to deliver top-tier performance with fewer parameters, making it more efficient and cost-effective for developers to integrate into their workflows. Smaller models are faster to deploy, require less computational resources, and are easier to fine-tune for specific use cases.
Conclusion
Ultimately, code embedding models serve as the engine behind RAG systems, particularly for coding agents. A more advanced code embedding model enables Qodo to build smarter and more efficient tools for code retrieval and analysis.
The Qodo-Embed-1 model family is available on Hugging Face. Qodo-Embed-1-1.5B is open weights under the Openrail++-M licensce, while Qodo-Embed-1-7B is available commercially.


