Single-Agent vs. Multi-Agent Code Review: Why One AI Isn’t Enough
TL;DR
- Code review breaks at scale the same way everywhere: Senior engineers spend 20-40% of their time reviewing PRs. Queue times stretch for days. Standards drift between teams. Merges depend on who’s online, not what’s safe to ship.
- AI-assisted development made it worse: Atlassian measured an 89% jump in PRs per engineer after AI adoption. But approval still requires human judgment. You’re shipping code faster than you can validate it.
- AI IDE suggestions don’t solve the bottleneck: Tools leave comments, flag issues, and run checks. But every merge still waits for manual approval. The constraint hasn’t moved.
- Single-agent code review checks everything in one pass. Multi-agent code review checks bugs, security, and system impact in separate steps before merge.
- Qodo closes that gap: As an AI Code Review Platform, it orchestrates review agents backed by cross-repo context, enforces standards at merge time, and works inside your existing CI/CD pipeline without replacing the human judgment that matters.
At Microsoft Build 2025, the message was direct: 2026 will be the year of AI Agents. Not IDE helpers or chat interfaces, but platform-owned enforcement with agentic review capabilities embedded directly into CI/CD workflows.
That framing aligns with what large engineering organizations are dealing with today. The main constraints are no longer tooling gaps or compute limits. They are the human-centric blockers where context, policy, and merge decisions are still handled manually. Code review is one of the most expensive of those blockers.
The change came from how code review operated, as in larger organizations, review is an unstructured coordination problem. Because PRs queue behind a small group of senior engineers who have a deeper understanding of the whole system. Each review requires reconstructing intent across services, shared libraries, and prior decisions. Standards often drift across repos, and merge outcomes depend more on who reviews the code than on what actually changed.
We removed that variability. Review stopped being a best-effort coordination step and became a defined part of the delivery system. Ownership was explicit. Checks were automated and applied consistently across repositories. Merge decisions were enforced by the workflow, not negotiated in comment threads. Context lived in the system instead of only in senior engineers’ heads.
How AI-Assisted Development Increased Review Load
Teams are writing and submitting code more often than before. Pull requests arrive earlier, in parallel, and there are more contributors than ever before. Yet code reviews are still handled by the same small group of engineers who understand system behavior, dependencies, and risk.
Industry context: Microsoft’s 2025 Work Trend Index found that 41% of leaders plan to train AI agents, 36% plan to manage them, and 83% expect employees to take on more complex work earlier in their careers.
This changes where delivery slows down. Code gets written quickly. Pull requests wait. Merges are delayed because the people who can approve changes safely are already overloaded.
Pull Request Frequency Increased, But Reviewer Time Did Not
Engineers now use AI-assisted coding during feature work, refactoring, and test creation. As a result, they open pull requests more often and work on multiple changes at once. But developers still have a fixed number of hours, and each review still requires careful reasoning about behavior, dependencies, and failure cases.
Changes Now Span Multiple Repositories
Most changes no longer live in a single repository. A typical pull request could touch a service implementation, a shared library, or an internal SDK, infrastructure, or configuration, and CI or deployment logic.
Most review tools show only the local diff. Understanding downstream impact (compatibility, rollout order, and dependency breakage) requires stitching together context across repositories. That work is slow and usually falls on engineers with long-term system knowledge.
Review Must Generate Audit Evidence
Security and compliance requirements have increased. Teams must document who approved a change, which rules applied, and the evidence supporting the decision. Manual review workflows were never built for this. Evidence is scattered across comments, CI logs, and personal judgment.
Why Single-Agent Review Fails at Enterprise Scale
Most AI code review tools rely on a single model to analyze a pull request and generate feedback. That choice becomes a limiting factor as soon as reviews involve more than local code changes.
At a production level, code review requires answering multiple questions simultaneously:
- Does the change behave correctly?
- Does it introduce security or reliability risk?
- Does it affect other services?
- Does it follow ownership rules and deployment expectations?
A single AI reviewer has to check all of this in one pass. As pull requests grow in scope, that reasoning gets compressed. The model tends to focus on what is easiest to infer from the diff and gives general feedback. System-level concerns are harder to check and are often left implicit.
Multi-agent review solves this by separating responsibilities. Instead of one agent trying to reason about everything, each agent is responsible for a specific review concern and gives a clear signal. Those signals are then combined to determine whether a pull request can be merged.
| Dimension | Single-Agent Review | Multi-Agent Review |
| Review responsibility | One agent handles all checks | Each agent owns a specific concern |
| Output | Comments and suggestions | Explicit pass/fail signals |
| Cross-repo impact | Often inferred or missed | Evaluated directly |
| Consistency | Prompt and context-dependent | Policy-driven and repeatable |
| Behavior at scale | Degrades as scope grows | Remains predictable |
The difference becomes clear in common scenarios:
Shared library changes: When a pull request updates an internal SDK, the review must consider downstream consumers. In a multi-agent setup, one agent checks dependency impact, another checks test coverage across affected services, and another enforces ownership and compatibility rules.
Security-sensitive changes: When a PR tightens input validation or changes access rules, review is not just about correctness. A security-focused agent checks failure behavior, while a deployment-focused agent checks rollout safeguards.
These examples show that code review scales when responsibilities are explicit and enforced by the system, not when one reviewer (human or AI) is asked to reason about everything at once.
Code Review Agents: From Advisory Tools to Merge-Time Enforcement
On most developer teams, deciding whether a pull request can be merged is still a human responsibility. Reviewers read the code, leave comments, and then decide whether the change is safe enough to ship. A code review agent is built to take over that process as a first-pass reviewer.
It runs automatically when a pull request is opened or updated and checks the change against rules teams already depend on: test coverage, dependency impact, and compliance policies.
Beyond leaving code suggestions, it provides a verdict on the PR. Either the change is allowed to merge, or it isn’t. That one shift (moving the merge decision into the system) changes how review behaves.
How Agent-Owned Code Review Changes the Flow
Engineers still read code, debate design choices, and suggest improvements. The difference is that they no longer have to decide whether a pull request can ship. That decision is made consistently by the system, using rules the team has agreed on.
| Dimension | Traditional Manual Review | Comment-Only AI Tools | Agent-Owned Review (Qodo) |
| Primary role | Human judgment and coordination | Generate suggestions and review signals | Own merge-time review decisions |
| Context depth | Individual reviewer’s mental model | Pull request diff or file-level | System-level, cross-repo, historical context |
| Decision ownership | Senior engineers | Humans interpret AI comments | Agent gives deterministic allow/block |
| Merge enforcement | Manual approval | Optional via CI or humans | Enforced via required status checks |
| Cross-repository reasoning | Manual and error-prone | Not supported | Built-in |
| Policy enforcement | Implicit and informal | Advisory only | Explicit, versioned, and auditable |
| Scalability (1,000+ devs) | Breaks down under load | Redistributes work | Built for multiple teams with multiple repositories |
Agent-owned code reviews don’t replace human judgment. Engineers still read code, debate tradeoffs, and give feedback. The difference is that the system determines an initial merge verdict based on whether a pull request meets the organization’s requirements.
What Does a Code Review Agent Check?
A review agent checks the same criteria as experienced reviewers, but far more consistently over time. It looks at what changed, which services or libraries are affected, whether tests cover the new behavior, and whether the change aligns with ownership rules and documented intent.
Owning Outcomes Instead of Leaving Suggestions
Most AI review tools stop at commentary. They point out potential issues and leave it to humans to decide what matters. A review agent doesn’t do that. It owns the outcome.
If a required condition isn’t met, the merge is blocked automatically. If an exception is needed, it’s explicit, role-based, and recorded. There’s no ambiguity about why a change didn’t merge or who allowed it through.
Why IDE Tools, Linters, and PR Bots Are Not Code Review Agents
Engineering teams use a range of tools to assist with code quality and code review. These tools improve visibility, flag issues earlier, and reduce manual effort in specific workflow steps. They are built for different scopes of responsibility than a code review agent.
GitHub Copilot Code Review Operates at the PR Diff Level
GitHub Copilot includes a code review capability that can analyze pull requests and provide feedback based on the changes introduced. Its analysis is scoped to the pull request content and is intended to assist reviewers by highlighting potential issues or improvements. Copilot’s review output is advisory. Decisions about whether a pull request satisfies organizational requirements and can be merged remain with human reviewers or with a separate CI configuration.
CodeRabbit Focuses on Contextual Review Feedback
CodeRabbit provides PR summaries, contextual comments, and analysis intended to help reviewers understand changes more quickly. The tool’s role is to generate a review signal. Whether and how that signal is enforced depends on how teams integrate it with their existing CI pipelines and branch-protection rules.
SonarQube Enforces Static Quality Rules
SonarQube performs static analysis to detect bugs, vulnerabilities, and code quality issues based on defined rules. When integrated with CI, it can fail builds if quality thresholds are not met. SonarQube’s analysis is rule-based and file-scoped. It does not check higher-level system behavior, such as cross-repository compatibility or alignment with work-item intent.
How These Tools Differ from a Code Review Agent
Rather than giving feedback for humans to interpret, Qodo orchestrates review agents as part of a merge-time assessment. It checks pull requests using repository context, cross-repository indexing, CI artifacts, and explicit review policies, then reports deterministic outcomes back to the Git platform.
| Aspect | IDE assistants / PR bots / static analysis | Qodo |
| Primary role | Generate a review signal | Participate in the merge-time assessment |
| Scope of analysis | PR diff or file-level rules | System-level, cross-repo context |
| Enforcement | Via humans or CI configuration | Actionable CI/check results consumed by platform enforcement |
| Policy ownership | Implicit or distributed | Explicit and versioned configuration |
| Audit output | Derived from comments and CI logs | Traceable, audit-ready review artifacts |
What Must a Code Review Agent Reliably Handle at Scale?
Once a code review agent is configured as a required status check in the pull-request merge path, it directly controls whether code can be merged. At enterprise scale, that responsibility requires capabilities to work reliably and predictably across many repositories and teams.
| Required behavior at merge time | What it solves |
| Cross-repo impact analysis | Stops changes in shared libraries or SDKs from breaking downstream services |
| Ticket-aware validation | Confirms the code implements what the linked work item describes |
| System-level behavior checks | Catches issues that only appear when services, libraries, or infra interact |
| Test relevance assessment | Ensures new or changed behavior is actually exercised by tests |
| Deterministic allow/block decision | Makes merge outcomes consistent across repositories |
| Explicit, versioned policy enforcement | Applies the same standards everywhere and supports audits |
Why Pull-Request Reviews Fail in Multi-Repo Organizations
Many large organizations already use AI assistants, PR bots, and static analysis. These tools work well when pull requests are infrequent and changes are mostly isolated. However, problems appear when many pull requests are open at the same time across multiple repositories.
The limitation isn’t the quality of their code analysis. It’s how pull request merge decisions are made and enforced.
IDE assistants stop at code generation
GitHub Copilot speeds up code generation and can provide feedback on pull request diffs. That scope ends at the individual pull request. Merge eligibility is still determined by human reviewers or separate CI checks.
Static analysis is rule-based and high-noise at scale
In large codebases, rule-based analysis often generates many findings that require manual triage. These tools do not check intent, service interactions, or behavioral changes across components.
Basic AI bots comment but don’t decide
AI review bots generate summaries and suggestions. The decision on whether a change can be merged still rests with senior engineers.
This gap is solved by AI Code Review Platforms that move repeatable, policy-driven review decisions into the delivery system. Qodo is one platform applying deep codebase context and agentic review workflows to create enforceable, merge-time outcomes integrated directly into existing Git and CI controls.
Qodo was named a Visionary in the September 2025 Gartner® Magic Quadrant™ for AI Coding Assistants, reflecting its focus on system-level review and merge-time enforcement rather than code generation.
How Qodo Integrates into Software Delivery Workflows
Qodo is built to integrate at the same control points teams already use to control pull requests: CI pipelines, Git provider apps/webhooks, and command-line tooling (CLI).
CI-based execution: Qodo runs as part of the pull request within the CI/CD pipeline (for example, as a GitHub Action or equivalent CI step). A typical flow: PR is opened, CI checks out code, existing build and test steps run, Qodo executes as a CI step and checks the change, Qodo reports review feedback back to the Git platform.
App/webhook-based execution: For larger organizations, Qodo also supports running as a Git provider app or webhook-driven service.
CLI and service-level usage: Qodo also provides CLI and service-level interfaces that platform teams can use to invoke analysis programmatically.
At an Enterprise Level
Qodo persists codebase intelligence instead of treating each PR as an isolated diff. That includes awareness of shared libraries, internal SDKs, and dependency relationships that span repositories. Policies are explicit and versioned. Enforcement is deterministic.
QODO ENTERPRISE: MEASURED IMPACT
- 800+ production issues stopped (Monday.com)
- 450,000 engineering hours saved (Fortune 100 retailer)
- Consistent enforcement across 1,000+ devs
In multi-service platform changes, reviews catch compatibility and rollout issues before code lands. In regulated environments, review decisions remain traceable months later. During PR spikes, the agent absorbs predictable review load so human reviewers are not overwhelmed.
Example: Reviewing a PR with a Qodo’s code review agent in the loop
Now, let’s walk through an example where a pull request is raised from an internal Notification Delivery API.
The service started as a simple synchronous API for sending transaction notifications. The PR introduced a meaningful architectural shift:
The API no longer sends notifications inline. Instead, requests queue up notifications, a background worker processes them asynchronously, and a policy layer enforces which templates are allowed to be delivered. Template management has moved from read-only to full CRUD, backed by file system storage and policy configuration. Tests were added to cover the new behavior. This is the kind of PR that looks reasonable at a glance but carries risk.
What changed, at a system level
The diff wasn’t just adding features. It changed how work flows through the system.
- A synchronous request path became an asynchronous pipeline.
- Notification delivery moved behind a queue and worker loop.
- Policy enforcement became file-based and configurable.
- Template operations now mutate state on disk.
- The server process now owns a long-running background worker.
That combination crosses API behavior, durability assumptions, security boundaries, and operational characteristics. This is where reviews usually slow down, because validating all of that manually takes time and deep context.
How the agent approached the code review
The code review agent didn’t just scan files. It grouped the PR into three distinct themes: queue/worker changes, policy enforcement, and template CRUD. This lets the human reviewer understand intent before exploring line-level details.
From there, it focused on three questions a senior engineer would ask anyway:
- Does this design behave correctly under load?
- Does it fail safely?
- Does it introduce new security or operational risk?
Issues that surfaced immediately
As visible in the PR below:
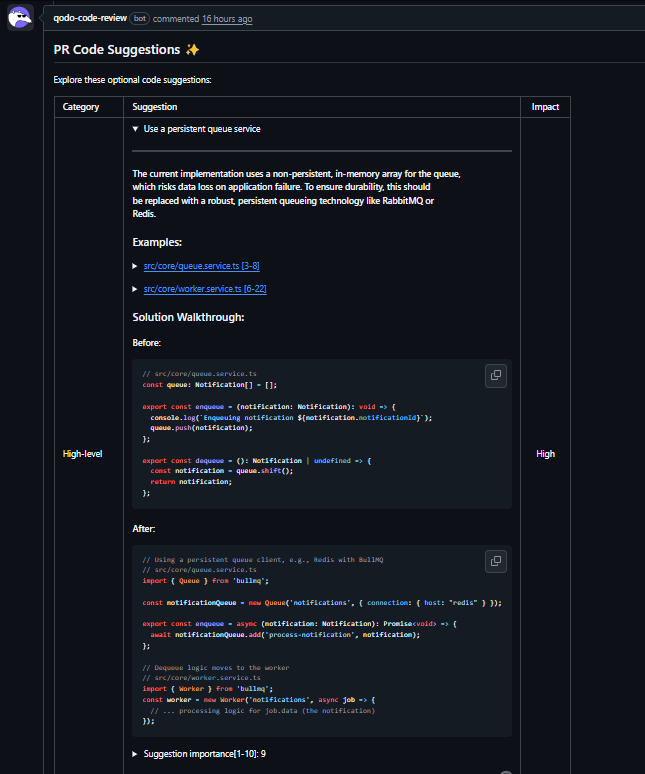
The first red flag was the queue implementation. The PR introduced an in-memory array with shift() inside a setInterval loop. The agent flagged this as inefficient and unsafe under load: O(n) dequeues, unbounded growth, polling even when idle, and no durability if the process crashes.
That was a direct challenge to the architectural intent of introducing a queue in the first place. The suggestion to move to a persistent queue was then ranked to be of high importance because, without it, the new architecture isn’t reliable.
The worker loop raised a second concern. Using setInterval with async processing can cause overlapping executions if processing time exceeds the interval. The agent suggested a recursive setTimeout pattern to ensure only one worker executes at a time. This is the kind of concurrency issue that’s easy to miss in manual review and painful to debug later.
Security and correctness gaps
The policy service review identified a simple but important issue. When the policy file fails to load, the fallback behavior effectively allows all templates. That’s a fail-open security posture, even though the comments suggest ambiguity. The agent recommended making the policy fail-closed instead, so that undefined configurations don’t silently widen access.
Template handling surfaced another class of issues. Template IDs were interpolated directly into file paths without validation. The agent flagged the potential for path traversal and pointed out that error handling was masking real filesystem failures by converting everything into “not found” errors. Both are small details individually, but together they create security and operability risk.
Why this mattered for the review outcome
What’s important here is that it surfaced issues tied directly to system behavior: durability, concurrency safety, security posture, and correctness under failure.
A human reviewer still decides how far to take the changes. Maybe this PR doesn’t introduce Redis yet. Maybe the team accepts the in-memory queue temporarily. But those decisions are now explicit and informed, not by chance.
The review also made it clear that this PR could be split. Queue mechanics, policy enforcement semantics, and template CRUD could land independently. That alone can cut review time and reduce blast radius.
What changed for the human reviewer
Instead of spending time scanning every file and reconstructing intent, the reviewer starts with a structured view of risk areas. Senior engineers focus on tradeoffs: whether persistence is required now, how strict policy enforcement should be, and what operational guarantees the service needs.
That’s the shift review agents make possible. They don’t replace judgment. They remove the need for senior engineers to rediscover the same classes of issues in every architectural PR.
2026: Code Review Becomes Owned Infrastructure
In large engineering organizations today, pull request volume routinely outpaces review capacity. More engineers own production code earlier in their careers. Changes span multiple repositories, shared libraries, and infrastructure layers. Code review, however, is still handled largely through manual coordination and individual judgment.
By 2026, code review in enterprise environments will need to function as a first-class capability in the delivery stack. Standards enforcement, test expectations, compatibility checks, and governance rules will be applied consistently by systems integrated into CI/CD and pull request workflows.
Qodo fits into this model by treating code reviews as infrastructure. It integrates into merge workflows, applies explicit policies, and creates code review decisions that are enforceable, measurable, and auditable. The result is a delivery system where review scales with code volume, senior engineers are not consumed by triage, and merge decisions remain consistent as complexity increases.
FAQ
1. What are the best code review tools for developers?
For most teams, the foundation of code review is the pull request tooling provided by platforms like GitHub and GitLab. Where teams see limits is at scale. As PR volume increases, review quality and consistency depend heavily on reviewer availability and individual judgment. Qodo operates alongside GitHub and GitLab rather than replacing them. Developers continue to open and review pull requests using the native platform UI. Qodo runs at the pull request and CI/CD level, checking changes using repository context, CI results, and configured review policies.
2. Which AI code review tools provide the fastest turnaround time?
Turnaround time is primarily influenced by where the review runs and how much context is checked. Qodo can execute within CI pipelines as part of the PR workflow or as a centralized service triggered by pull request events. Lightweight checks complete quickly, while deeper analysis that includes repository history, CI artifacts, or cross-repo context may take longer. Because Qodo maintains persistent context between runs, it avoids full reanalysis on each PR.
3. How should Qodo be evaluated for context-aware AI code review?
Assessment should focus on how review decisions are generated and enforced rather than on the volume of comments generated. Relevant criteria include whether review logic incorporates repository history and shared components, how CI results and test failures affect outcomes, whether review rules are explicit and version-controlled, whether results can be enforced through branch protection, and whether review decisions remain traceable after the merge.
4. What CI tools work best for embedded AI code reviews?
Qodo does not depend on a specific CI product. Any CI system that supports custom execution steps, artifact access, and status reporting to the Git platform can host embedded AI review. Typical integration patterns include running Qodo directly in the PR pipeline, triggering assessment via webhooks, or invoking agents as internal services for higher-risk branches or releases.


