The AI Code Quality Gap: What 100 Engineering Leaders Told Us

Based on original research conducted by Gatepoint Research, May-June 2026
AI coding tools are no longer experimental. Across the 100 engineering directors and VPs we surveyed, spanning financial services, healthcare, technology, and telecommunications, 94% report using AI coding tools in their organizations. Nearly 4 in 10 have fully standardized on them.
The adoption story is largely written; what isn’t written yet is the quality story.
Speed is the mandate. Quality is the constraint.
When asked to name their top engineering priorities this year, 59% of leaders cited accelerating delivery without sacrificing quality. Another 50% named improving developer productivity. Those two responses dominated every other option; reliability, technical debt, security, and standards enforcement all trailed significantly.
These leaders aren’t choosing speed over quality. They’re asking for both simultaneously. The mandate isn’t “ship faster.” It’s “ship faster without breaking things.”

Adoption is ahead of trust.
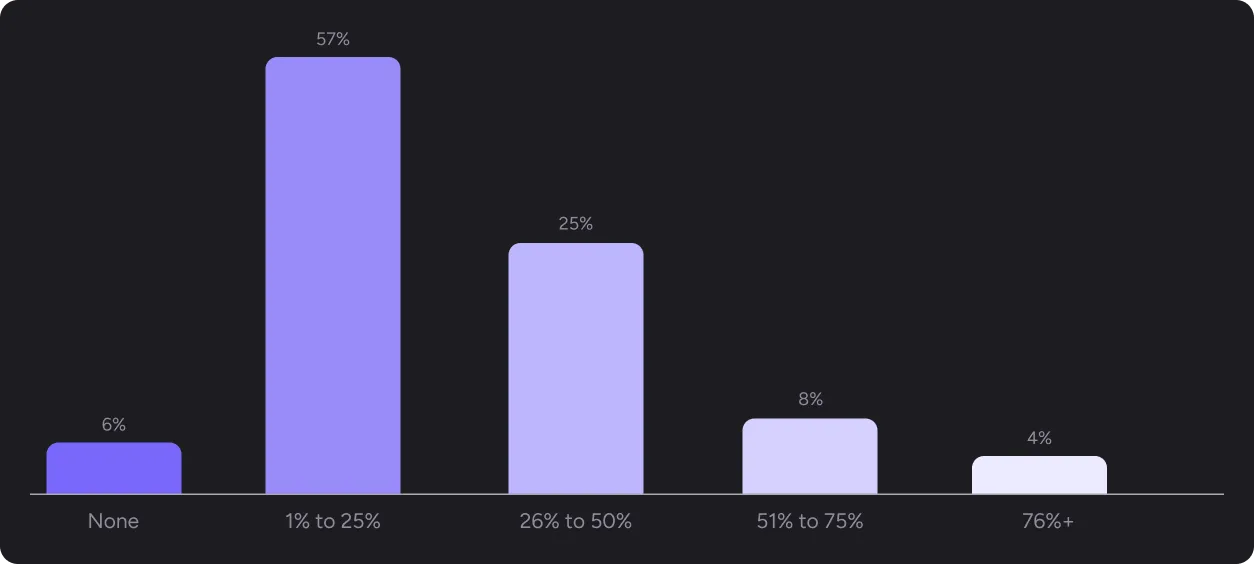
AI is generating a meaningful share of new code. 57% of respondents report that up to 25% of new code comes from AI tools. Another 37% are already past that threshold, with AI generating more than a quarter of their codebase.
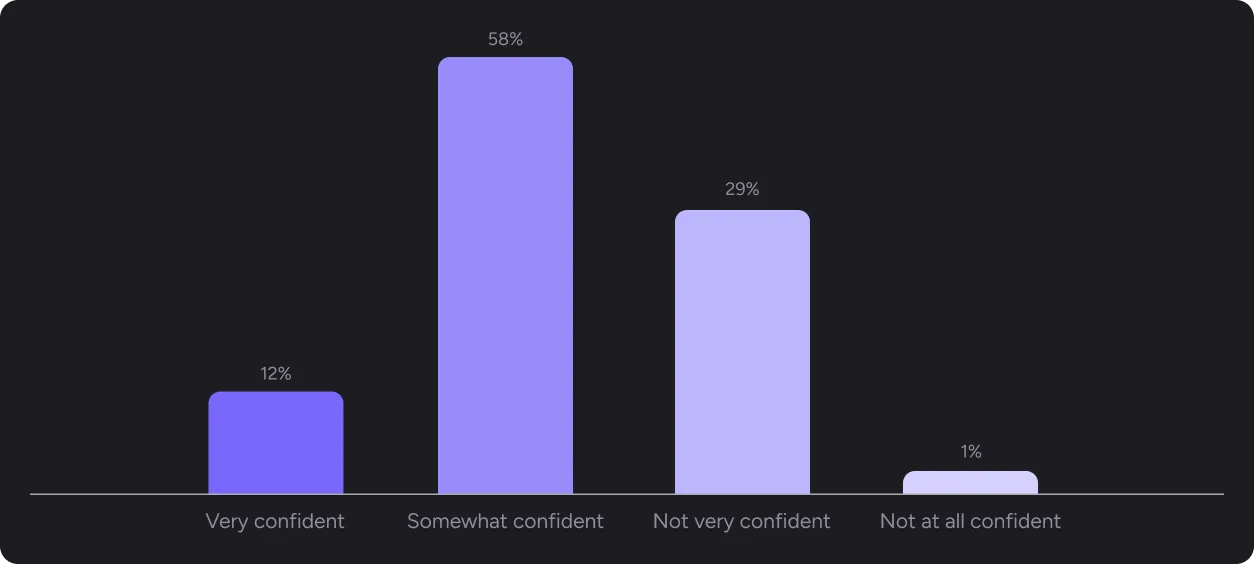
Yet only 12% of respondents are “very confident” in the quality of that code before it reaches production. 58% are “somewhat confident.” Nearly 30% are not very confident or not at all confident.
A substantial and growing portion of new code is AI-generated, but the people responsible for shipping it don’t fully trust it. That tension runs through the rest of the survey.
The problems compound as adoption deepens.
The confidence gap doesn’t stay flat as adoption deepens. It grows.
Among teams where AI code volume accounts for 26–50% of new output, the share of leaders who lack confidence in that code rises to 32%. At 51–75% AI-generated code, it hits 38%. The trust gap widens as volume grows, which is exactly the opposite of what you’d hope to see as teams mature their AI practices.
The specific challenges that surface are consistent across adoption stages, but the emphasis shifts:
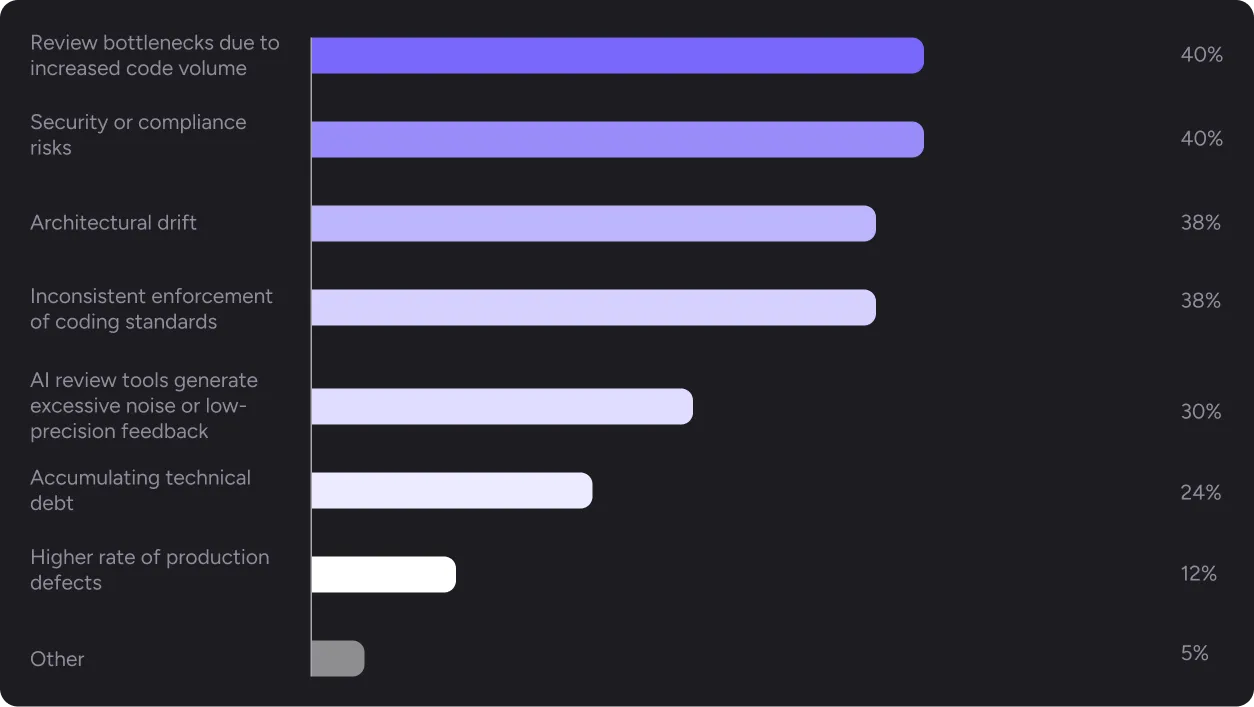
Teams using AI informally (no standardized adoption, just individual developers and small groups) cite inconsistent enforcement of coding standards at 54%. When AI usage isn’t coordinated, standards fragment. Different developers, using different tools and prompts, produce code that looks different, behaves differently, and violates standards in different ways.
Teams in pilot or early experimentation feel the architectural pressure most acutely. Architectural drift hits 47% of this group, the highest of any adoption stage. AI-generated code that doesn’t understand your architecture slowly diverges from it.
Teams with standardized, widely adopted AI tools have moved past those early problems and hit a different wall. Review bottlenecks top their challenge list at 50%, with security and compliance risks close behind at 42%. They’ve gotten good at writing code with AI. They haven’t gotten good at reviewing it at scale.
Three stages, three distinct problem profiles, one underlying cause: AI accelerates code production without automatically accelerating the review infrastructure needed to validate it.
The review tooling doesn’t match the problem.
62% of respondents rely on manual peer review as their primary quality gate. Another 50% supplement with AI coding assistants (tools like GitHub Copilot, Cursor, or similar) that include built-in review capabilities. 42% use linters and static analysis.
Only 12% use a dedicated AI code review platform.
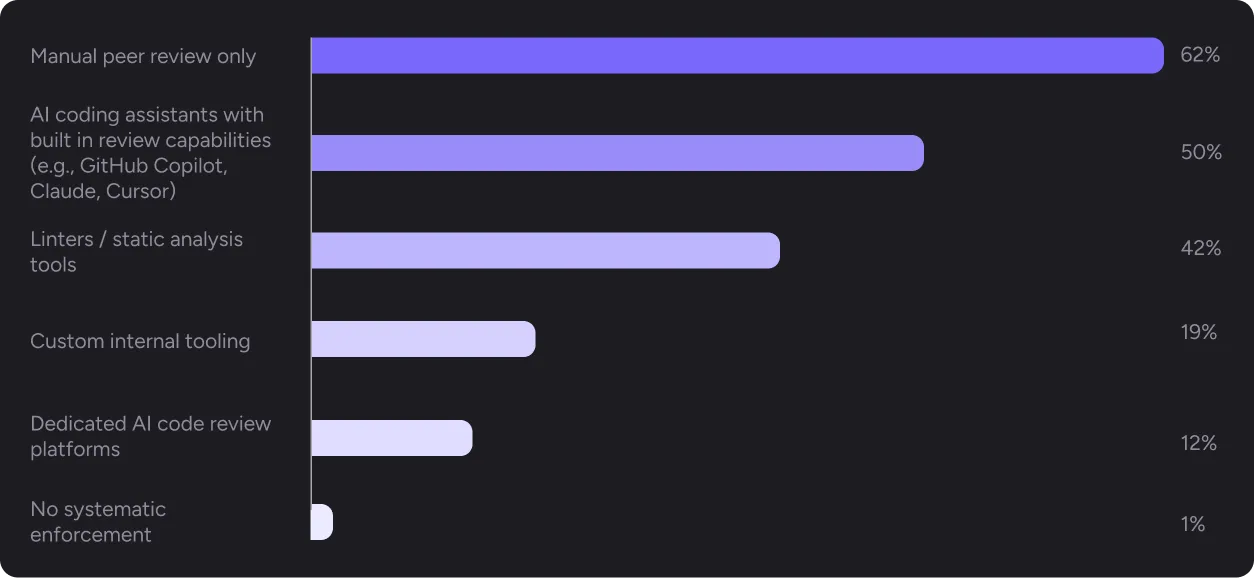
The distribution matters when you look at where the pain is concentrated.
Of the leaders who flagged “AI review tools generate excessive noise or low-precision feedback” as a challenge (30% of all respondents), 72% are still relying on manual peer review as their primary enforcement mechanism. They’ve identified the problem with existing AI review tools, and the solution they’re defaulting to is for humans to pick up the slack.
That approach doesn’t scale. It couldn’t scale before AI coding tools accelerated velocity. It certainly can’t now.
What would actually justify the investment?
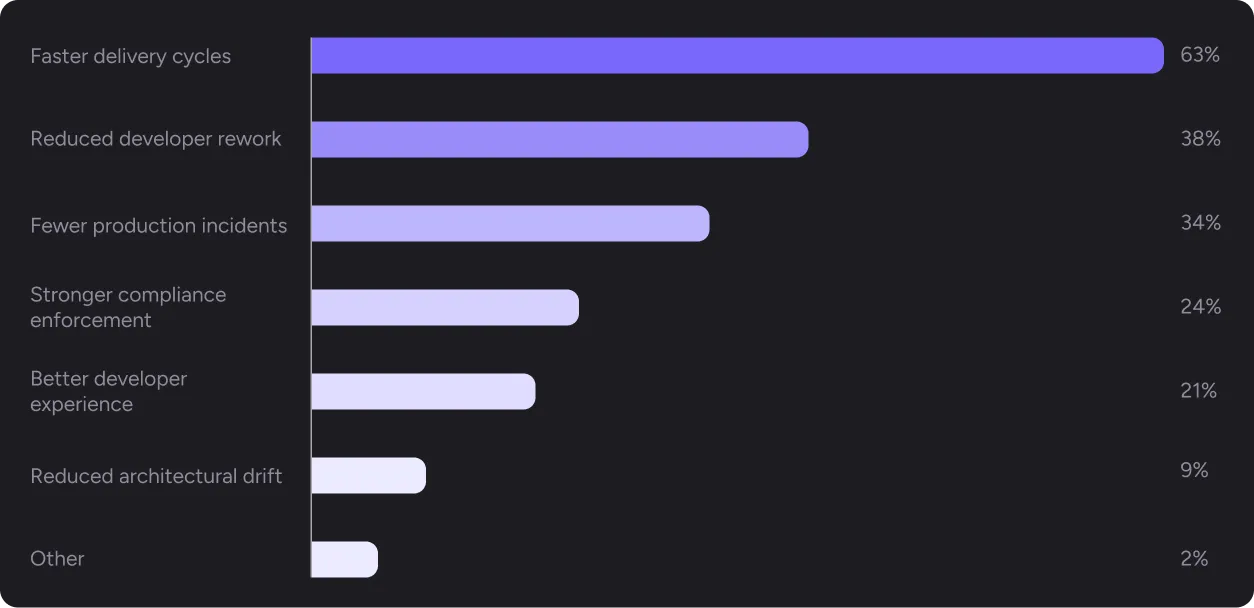
When asked what outcomes would justify investing in improved AI-assisted code review, 63% of leaders named faster delivery cycles. Reduced developer rework (38%) and fewer production incidents (34%) followed.
Speed comes first, but it’s not speed alone. The top three outcomes describe a system that ships faster, generates less rework, and produces fewer incidents. That’s not a speed story. That’s a quality story dressed as a speed story, because engineering leaders have learned they can’t separate the two.
Among leaders who ranked “accelerate delivery without sacrificing quality” as their top priority, 68% said faster delivery cycles would justify a code review investment, and 37% also required reduced rework. They want proof that a better review produces both outcomes simultaneously. Not a trade-off. Evidence.
The pattern across the data
AI coding tools generate code faster than review processes were designed to handle. The resulting problems (fragmented standards, architectural drift, review bottlenecks, security risk, low-signal feedback) don’t emerge from any single failure. They emerge from a structural gap: the quality infrastructure that teams rely on was built for a different development velocity.
Manual peer review can’t scale to keep up with the volume of AI-generated code. Linters and static analysis catch syntax and style, not context-dependent architectural issues. AI coding assistants with built-in review features have a built-in conflict of interest: the system that generated the code is also the one being asked to evaluate it.
Most teams haven’t closed that gap yet. What closes it is a dedicated governance layer; one that reviews code with the understanding of the full codebase, not just the diff. It should enforce standards consistently across every PR, regardless of which tool generated the code; and gets smarter over time rather than noisier.
That’s not a nice-to-have, given that AI coding velocity continues to increase. It’s the missing piece between “AI wrote it” and “production-ready.”
The full survey report, “Reviewing AI-Generated Code,” was conducted by Gatepoint Research between March and May 2026. 100 engineering directors and VPs from multiple industries participated.