AI Code Review: If AI Writes the Code, How Do We Review It at Scale?
AI code review is a dedicated verification discipline — not a feature of your generation tool. Understanding what it analyzes, where it fits in your SDLC, and how to evaluate tools on rigorous benchmarks is what separates teams that ship confidently from teams that ship fast and fix later.

Key Takeaway
AI code review is a dedicated verification discipline — not a feature of your generation tool. Understanding what it analyzes, where it fits in your SDLC, and how to evaluate tools on rigorous benchmarks is what separates teams that ship confidently from teams that ship fast and fix later.
What You’ll Learn
- What AI code review actually is — and what it isn’t
- How the job of code review changed when AI started writing the code
- What AI code review tools actually analyze, and why context is the dividing line
- The types of tools in the category and what each one is built for
- How to read benchmark claims without being misled
- Where AI code review fits in your SDLC
What Is AI Code Review?
AI code review is the automated analysis of code changes using AI models to detect issues, enforce standards, and validate quality before code merges into production.
Not all AI code review tools are the same — some analyze only the diff in a pull request (CodeRabbit, Greptile), some review code locally in the IDE as it’s written (Qodo IDE Plugin, Copilot), some focus exclusively on security vulnerabilities (Snyk, SonarQube), and others operate across the full SDLC with full codebase context (Qodo). The category label is the same; where a tool operates in your SDLC and what it’s built to do are not.
AI code review is the system that does the job your generation tool was never designed to do. Code generation tools are optimized for fluency and speed — producing code from prompts and local context, with no knowledge of your architecture, prior decisions, or team standards.
AI code review starts where generation stops: analyzing what was produced against your codebase, your rules, and your organizational intent. The goal isn’t to write code faster. The goal is to know whether what was written is safe to ship.
Typing code is dying, but sculpting and crafting large systems isn’t. Getting to a working prototype is the easy part. Code review, correctness, and regression prevention — the last 20% — is where the real engineering happens
Scott Hanselman, VP, Microsoft, on The Agentic Review
How AI Code Review Differs from Traditional Code Review
Traditional code review was designed around one assumption: a developer who understood the codebase wrote the code, and a peer checked it.
That assumption no longer holds when a significant portion of a PR is AI-generated. The “author” had no knowledge of your architecture, no memory of past decisions, and no understanding of your team’s conventions. The review task is fundamentally different — and tools designed for the old assumption aren’t equipped for the new one.
Traditional Code Review
AI Code Review
Who reviews
Human peer reviewer
Specialized AI agents
What triggers review
PR opened, human assigned
Automated, every PR, every commit
Context available
Reviewer’s memory and codebase familiarity
Full codebase indexing, PR history, dependency graphs
Standards enforcement
Depends on reviewer knowledge and attention
Codified rules applied consistently, every time
Scales with AI output
Yes — operates at generation speed
Catches cross-repo issues
Rarely — reviewers see what’s in front of them
Yes — with multi-repo context
Feedback loop
Varies by reviewer
Structured, actionable, prioritized by severity
Learning over time
Individual reviewer knowledge
PR memory — learns from prior decisions
The shift isn’t that AI replaces human reviewers. It’s that AI handles the review layer that human reviewers were never realistically able to cover — at the volume, speed, and depth that AI-generated code now demands.
Where AI Code Review Fits in the SDLC
AI code review isn’t a single touchpoint. It operates across the SDLC — and where it runs determines what it can catch.
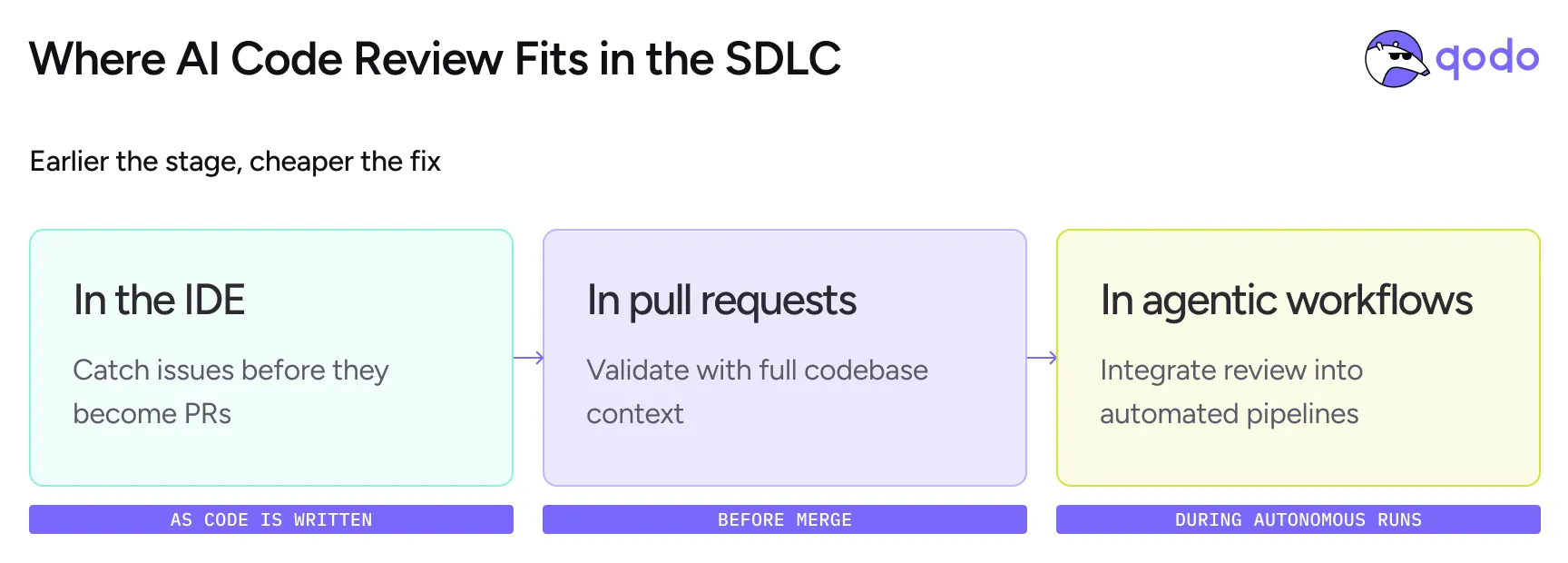
In the IDE — catch issues before they become PRs
Review agents analyze code locally as developers write — flagging security risks, logic gaps, and non-compliant patterns before anything reaches a repository. This is shift-left in practice: the earlier an issue is caught, the cheaper it is to fix. Issues found at the IDE stage cost a fraction of what they cost to fix after merge.
In pull requests — validate with full codebase context
The PR is where most review happens today, and where the context gap is most expensive. AI code review at the PR level operates with full codebase awareness — detecting breaking changes across dependencies, identifying duplicated logic, validating against team rules, and checking ticket compliance. This is the layer that diff-only tools miss entirely.
In agentic workflows — integrate review into automated pipelines
As coding agents generate code autonomously — opening PRs, running multi-step tasks, executing across the SDLC — quality gates can’t depend on a human opening a pull request. AI code review integrates directly into these agentic workflows through skills: callable review capabilities that coding agents invoke as part of their own loops. Review runs as a native step in the agent’s process, not as a separate human gate after the fact. Quality enforcement moves from reactive to continuous.
“Most teams have immature development lifecycles already. Adding AI to broken branching, missing code review, and no CI/CD just puts a Band-Aid on cancer.”
Scott Hanselman, VP, Microsoft, on The Agentic Review.
AI code review amplifies whatever SDLC you already have. Teams with strong branching, mature CI/CD, and a real review culture before AI tools are the ones best positioned to benefit. Teams without those foundations inherit faster chaos.
If your SDLC isn’t ready, AI code review won’t fix it. But once the foundations are in place, AI code review is the layer that lets quality scale with velocity instead of falling behind it.
What AI Code Review Tools Actually Analyze
This is the most important question to ask when evaluating any tool — and the one most vendors obscure in their marketing.
Diff-only analysis: fast, limited, and common
Most tools analyze the diff — the lines of code added or removed in a given PR. Diff-only review can catch syntax errors, obvious logic issues, and style violations.
The problem is structural. A diff has no memory and no context. Diff cannot know that a function being modified is called by six other services, or that this pattern was deprecated three months ago, or that the same logic already exists in a different repository.
Diff-only review can tell you the code looks correct. It cannot tell you whether the code is safe.
Example:
A developer updates getUserPermissions() to return permissions as a Set instead of an Array — same function name, same arguments, more efficient lookups. The PR shows a clean refactor. The auth service compiles. Tests pass.What the diff doesn’t see: three downstream services iterate over the return value with .map() or index into it with [0]. They live in different repos. The auth service’s type changed, but nothing in this PR surfaces who depends on the old shape. The next morning, staging breaks for billing, notifications, and the admin portal.
Full context analysis: what separates serious code review tools from lightweight ones
Full context analysis goes beyond the diff to understand the code change within the broader system. This requires:
- Multi-repo codebase indexing — understanding how components relate across repositories, not just within the current one
- Dependency graph awareness — knowing what breaks when a shared component changes
- PR history and memory — learning from prior review decisions so the same mistakes don’t require the same corrections repeatedly
- Semantic analysis — understanding what the code is trying to do, not just what it says
- Rules and standards context — knowing what “correct” means for this specific organization, not just in general
The difference between diff-only and full context isn’t a feature comparison. It’s the difference between a review that catches surface issues and one that catches the issues that cause production incidents.
Example: a “hallucination” that wasn’t
A Qodo customer once messaged in convinced the tool was hallucinating. He’d made a small change to one function. Qodo flagged a high-priority bug in code he hadn’t touched. He opened the evidence and saw the flagged code was outside his diff. The tool, in his read, was wrong.
The evidence link pointed somewhere he hadn’t looked: another function in the repo that called the code he’d changed. His edit had broken that downstream function. The bug was real. It was only visible because the review was reading the change against the full codebase — not the diff in isolation.
This is the difference full context makes. A diff-only review would have shown the customer exactly what he expected: a clean change to one function. Nothing flagged. Nothing to fix. The breakage would have surfaced later — in tests if he was lucky, in production if he wasn’t.
Types of AI Code Review Tools
Not every tool in this category solves the same problem. Understanding the types helps engineering teams evaluate fit before getting into demos.
PR-level review tools — automated feedback on every pull request
The most common category. These tools integrate with your Git provider and analyze PRs automatically (CodeRabbit, Greptile, Copilot code review). Quality varies significantly: the key dividing line is whether analysis is diff-only or full-context. PR-level tools that operate on the diff alone will miss cross-repo issues, breaking changes, and standards violations that require codebase awareness.
Right fit when: You need automated coverage on every PR and want to reduce manual reviewer load. Evaluate carefully on context depth — most tools in this category don’t disclose how much of the codebase they actually analyze.
Security-focused tools — vulnerability detection as the primary job
SAST (Static Application Security Testing) scanners fall into this category (Snyk, SonarQube, Semgrep). They are purpose-built to detect security vulnerabilities: OWASP compliance, secrets detection, dependency scanning, injection risks. They are not designed to review logic quality, enforce engineering standards, or understand architectural intent. Security-focused tools complement AI code review — they don’t replace it. The two layers address different failure modes.
Right fit when: You have a dedicated AppSec requirement and need systematic vulnerability scanning. Use alongside, not instead of, AI code review.
IDE-integrated review tools — shift-left feedback as developers write code
These tools run locally in the developer’s environment, providing real-time feedback before code leaves the machine (Qodo IDE Plugin, Copilot, Cursor). The advantage is early detection. The limitation is context: IDE tools typically operate with local context only, without the full codebase awareness available at the PR level.
Right fit when: Developer experience is the primary goal and you want issues caught before they reach review. Most effective when paired with a PR-level layer that has broader context.
Full SDLC platforms — review agents across IDE, Git, and CLI
The most comprehensive category. These platforms provide review capability across the entire development lifecycle — local review in the IDE, automated PR review with full codebase context, and agentic quality workflows in the CLI.
The advantage is consistency: the same standards, the same context, and the same quality bar applied at every stage rather than just at one gate. When one team establishes a best practice that works, it surfaces across the org — turning what used to live in one engineer’s head into standards that scale.
Right fit when: You’re operating at enterprise scale, managing multiple repos and teams, and need consistent enforcement that doesn’t depend on which tool a developer happens to be using.
Qodo is the AI Code Review Platform built for this category — full codebase context, review agents across the IDE, Git, and CLI, and a rules system that evolves with the codebase. Chapter 3 covers how it compares against the rest of the landscape.
The Benefits of Getting AI Code Review Right
When AI code review operates with full context, runs across the SDLC, and is evaluated on rigorous benchmarks — the outcomes are measurable.
Review scales with generation velocity. 80% of PRs require no human review comments when AI review is active (Qodo). Human reviewers focus on architectural decisions and edge cases — not on catching issues a system should have caught automatically.
Issues are caught earlier, when they cost less. Bugs found at the IDE stage cost a fraction of bugs found in production. Shift-left isn’t a philosophy — it’s a cost model.
Standards are enforced consistently, not selectively. Engineering standards that used to depend on reviewer knowledge and attention now apply regardless of who — or what — wrote the code. 73.8% of Qodo’s code review suggestions are accepted by developers, which means developers are acting on the feedback, not dismissing it as noise.
Security vulnerabilities are caught systematically, not by luck. 17% of PRs contain high-severity issues. Without automated review, these pass through on the quality of a single human reviewer’s attention on a given day.
Engineering leaders get visibility they didn’t have before. Not just into what issues were caught, but into whether standards are being followed, where quality is degrading, and which rules are working and which aren’t.
What this looks like in practice: Monday.com
Monday.com — work management platform with 250+ developers — rolled out Qodo as their AI code review layer alongside the AI coding tools their team was already using. The team had the generation layer. They needed the verification layer.
Six months in, the numbers held up to the framing above. Qodo now prevents an average of 800 potential issues from reaching production every month, while saving Monday.com developers approximately one hour per pull request. Issues are caught earlier, when they cost less. Standards are enforced consistently across the team. Engineering leadership has visibility into what’s being caught, where, and by which review agent.
The change isn’t about reviewing more code. It’s about reviewing it at the right layer, with the right context, before it reaches production
What Good AI Code Review Implementation Looks Like
The best way to understand what you’re buying is to know what changes when it’s working.
Developers stop finding surprises in production. Issues that used to surface after merge — a breaking change in a downstream service, a duplicated function, a security vulnerability that passed human review — get caught at the PR stage or earlier. The feedback arrives before the cost compounds.
Review comments are acted on, not dismissed. When a tool has low precision — flagging noise alongside real issues — developers learn to ignore it. When precision is high, developers read the comments and apply the fixes. The signal-to-noise ratio is what determines whether AI review actually changes behavior or just adds friction.
Human reviewers shift to higher-order decisions. Instead of spending review time on issues a system should catch automatically, senior engineers focus on architecture, design tradeoffs, and edge cases that genuinely require judgment. The review process gets faster without getting shallower.
Standards stop depending on who reviewed the PR. Consistency is the hardest thing to achieve in a human review process. With AI code review enforcing codified rules on every PR, the quality bar doesn’t vary by reviewer availability, seniority, or attention on a given day.
Engineering leaders can see what’s happening. Not just a count of issues flagged, but which rules are being violated, where quality is degrading across teams, and whether standards are actually being followed — not just documented.
If the tool you’re evaluating can’t demonstrate these outcomes, it’s operating at the surface. The next chapter covers how to tell the difference — across the major platforms, on the benchmarks that actually measure what matters.
The next chapter goes deeper into the AI code review tool landscape — how the major platforms compare, and a practical framework for evaluating and selecting the right AI code review tool for your organization
➔ Next: AI Code Review Tools: How to Evaluate, Compare, and Choose
Let’s see what you’ve learned!
How does AI code review change the role of human reviewers?
Select the correct answer
According to the chapter, what determines whether a team will benefit from adopting AI code review?
Select the correct answer
What’s the single most important question to ask when evaluating an AI code review tool?
Select the correct answer