AI-Generated Code in Enterprise Engineering
AI-generated code fails in specific, structural ways — logic errors, duplicated logic, breaking changes, security vulnerabilities, standards drift. These failures are why a dedicated verification layer between AI code generation and production is non-negotiable at enterprise scale. This chapter explains what those failures look like and where they come from.

Key Takeaway
AI-generated code fails in specific, structural ways — logic errors, duplicated logic, breaking changes, security vulnerabilities, standards drift. These failures are why a dedicated verification layer between AI code generation and production is non-negotiable at enterprise scale. This chapter explains what those failures look like and where they come from.
What You’ll Learn
- AI code generation strengths and limitations
- How the development lifecycle has shifted, and what that breaks
- The specific risks AI-generated code introduces at enterprise scale
- Why the current AI development stack creates a verification problem
- Where AI code review fits, and why it’s become a required layer
What Is AI Code Generation?
AI code generation is the use of large language models to produce source code from natural language prompts or existing code context. Tools like GitHub Copilot, Cursor, Claude, and Codex are the most common examples.
What matters more for engineering leaders is how those models work — because the mechanism explains the failure modes. LLMs are token-prediction systems. They complete patterns based on training data. That makes them genuinely useful for boilerplate, standard algorithms, and routine functions. It makes them structurally unreliable for tasks that require understanding your system: your architecture, your dependencies, the conventions your team has built over years.
AI code generation doesn’t natively reason about your codebase. It generates plausible-looking code that fits the local context it can see. At the snippet level, that’s often good enough. At the PR level, in a complex enterprise codebase, “plausible-looking” is where production incidents start.
The Shift: AI Is Now Writing Code at Scale
The adoption curve is no longer a trend to watch — it’s the current baseline. According to Qodo’s State of AI Code Quality Report, 82% of developers use AI coding tools daily or weekly. At enterprise scale, AI-generated code isn’t an edge case. It’s a constant, high-volume input.

The volume is increasing, but the question that matters for engineering leaders is “What does this volume do to the systems that were built around human-written code?”
Review processes, quality gates, and standards enforcement were designed for a different input rate. They haven’t scaled. That gap is structural — and it widens every quarter.
What Changes in the Development Lifecycle in 2026
The SDLC assumption for most of software engineering history was that the developers understood the the relevant context to perform the role and move software pieces through the SDLC accordingly. Code reviews existed to catch what they missed. The reviewer’s job was to check a colleague’s work — someone who also has shared context, shared history, shared standards.
AI changes that assumption fundamentally.
When a significant portion of a code change is generated by a tool with no knowledge of your architecture, no memory of prior engineering decisions, and no understanding of your team’s standards — the review task is different. You’re not checking a colleague’s judgment. You’re validating output from a system that optimizes for syntactic correctness, not organizational intent.
Three things break when reviewers shift from checking colleagues to validating AI output at scale:

1. Review volume outpaces review capacity.
AI generates code faster than humans can review it. Review time has increased 91% at high AI adoption teams (Faros AI Engineering Report), while headcount has not. Teams aren’t approving code carelessly — the volume makes thorough review operationally impossible.
2. Context drops out.
AI coding tools operate at diff level. They don’t know that a utility function three repos away will break when this change ships. That missing context doesn’t produce an error — it produces code that looks correct and behaves incorrectly downstream.
Matt Makai — founder of developer intelligence platform Plushcap and creator of Full Stack Python — shared this example: he’d built the Plushcap codebase by hand over three years before introducing AI coding tools. One variable was named is_public — meaning, in his domain, “is this company publicly traded.” The tools read it as a visibility flag and began modifying logic to hide companies from users.
The code compiled. It would have passed a casual review. It was wrong not because the model hallucinated a function or invented an API, but because it pattern-matched against the general meaning of a name rather than the codebase-specific intent behind it.
“I never, building this software, would have thought about that.” — Matt Makai
That is what plausible-looking failure looks like at the snippet level. Multiply it across hundreds of PRs and dozens of repos, and the cost compounds quietly — until it surfaces in production.
3. Standards diverge silently.
Different AI tools apply different assumptions. Different developers prompt differently. Without a centralized enforcement layer, every AI-generated PR introduces its own interpretation of how code should look. The codebase drifts — not through negligence, but through accumulated variance.
The Core Risks of AI-Generated Code
These risks aren’t theoretical. They’re the failure modes that show up after AI-generated code has been in production long enough to cause incidents
Risk
What It Looks Like in Practice
Logic errors
Code that passes tests but fails in edge cases the model didn’t anticipate — because the model was pattern-matching, not reasoning
Duplicated logic
The same functionality implemented independently across files or repos — the model had no visibility into what already existed
Architectural drift
Changes that violate the system’s established boundaries — bypassing abstraction layers, leaking responsibilities across modules, introducing tight coupling where the architecture called for separation. The model produced a working local solution without visibility into the structural patterns the team designed around.
Breaking changes
A change to a shared component that breaks downstream services not visible in the diff — common in multi-repo environments
Security vulnerabilities and risk
AI-generated code reusing insecure patterns from training data — 3x increase in security vulnerabilities in AI-assisted codebases (SonarSource State of Code)
Developer confidence data reflects awareness of these risks: only 28% of developers are confident in their AI-generated code, and 88% cite hallucinations as their primary concern when shipping AI-assisted changes (Qodo State of AI Code Quality Report).
Developers already know the output is unreliable. The problem is that existing review processes weren’t designed to catch this class of issue at this volume.
The New AI-Native Development Stack
Enterprise engineering teams are running multiple AI tools simultaneously. A typical AI-native stack in 2026:
Generation layer — Copilot, Cursor, Windsurf, Amazon Q. Write code in the IDE from prompts and local context. Optimized for speed and fluency.
Agentic layer — AI agents handling larger autonomous tasks: creating branches, writing full PRs, executing multi-step workflows.
This now spans three patterns:
- spec-first harnesses (Spec Kit, OpenSpec) that drive generation from a written spec;
- SDLC-enforcement harnesses (agent skills, Superpowers) that gate each phase of the lifecycle;
- long-arch harnesses (BMAD, GSD) that maintain state across multi-phase autonomous work.
Each pattern has a distinct failure mode — incomplete specs producing code that matches them anyway, gated pipelines that cover procedure but not problem, multi-phase chains that compose into the wrong architecture.
Verification layer — The system that validates what the generation and agentic layers produced before it merges. This is where most teams have the largest gap.
Investment has concentrated in the first two layers. The third — independent, context-aware verification — is what determines whether the speed gains in layers one and two are safe to ship.
Gartner is explicit on this: single AI tools hit a hard ceiling at enterprise scale. Large codebases with tens of thousands of lines spread across hundreds of files require specialized tools — not one system claiming to handle everything. (Gartner Emerging Tech: AI Developer Tools Must Span SDLC Phases to Deliver Value, January 2025.)
The architectural reason matters: the same system that generates code shares its own blind spots. A model optimized for fluency and completion will evaluate its own output through the same lens it used to produce it. Verification requires a different kind of reasoning — adversarial, context-aware, anchored in your specific codebase.
What’s different about an AI-native code review vs. existing static analysis?
Most enterprise teams already run SonarQube, Snyk, or Checkmarx. These tools match syntactic patterns against predefined rules — catching the SQL injection that fits a known signature, missing the logic error where the code looks fine but behaves wrong.
Human reviewers used to cover that gap. AI-generated code breaks that division of labor: it usually matches known patterns, and review volume has scaled past human capacity.
AI code review reasons about behavior — reading the diff in the context of the architecture, prior PRs, and your team’s conventions.
Both layers stay: static analysis stays in the pipeline for the work it does well, AI code review sits alongside it as the reasoning layer the modern stack now requires.
How the SDLC Changes as AI Generation and Review Are Added
AI generation alone changes how code is written. AI generation plus AI review changes the entire lifecycle around it. The comparison below shows the same SDLC under three conditions — no AI, generation only, generation plus review — and where each one closes or leaves open the verification gap.
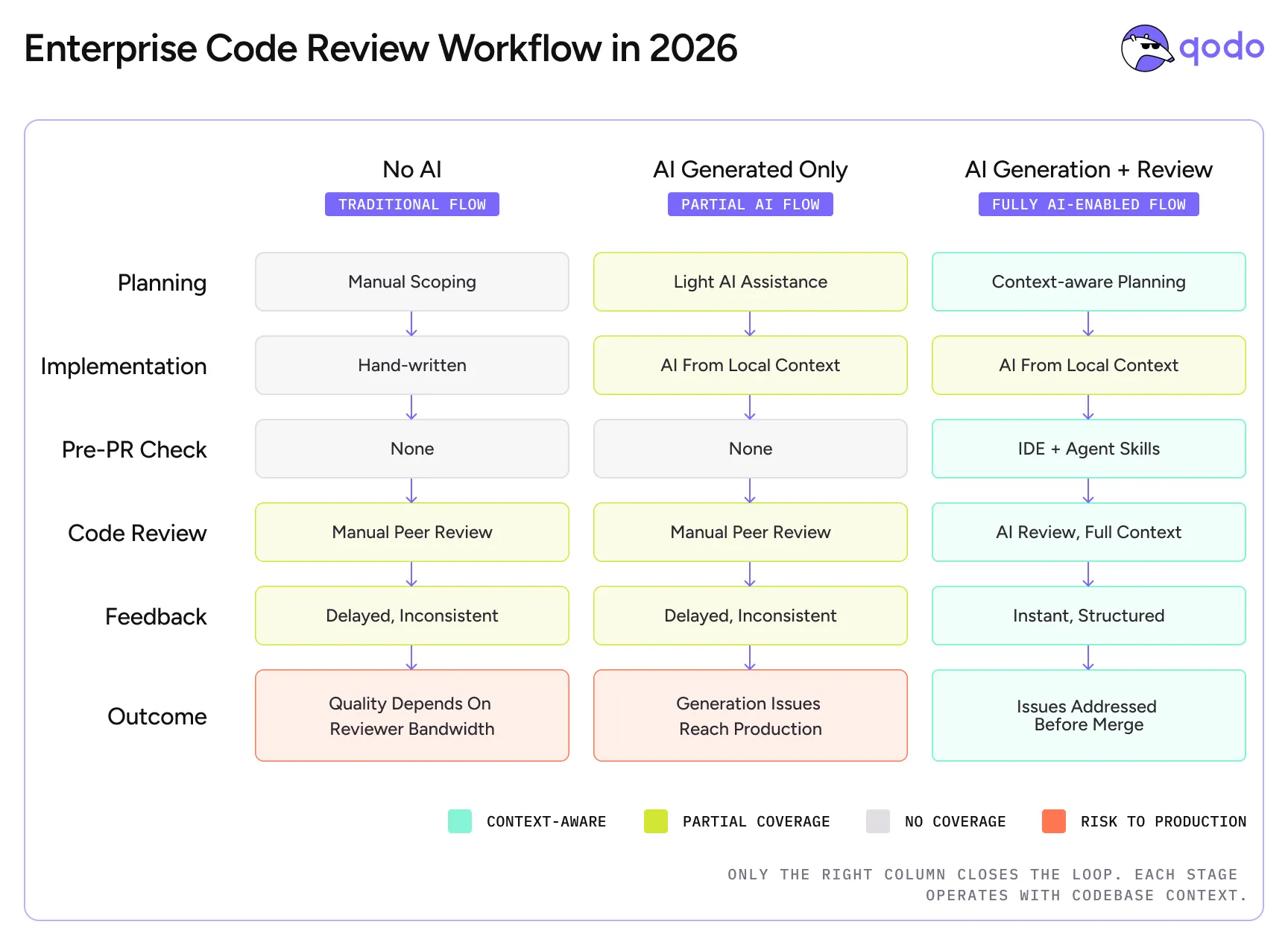
Stage
No AI — Traditional flow
AI generation only — Partial AI flow
AI generation + review — Fully AI-enabled flow
Step 1: Planning
Developer or tech lead defines the change manually — scoping the work, identifying affected systems, and surfacing dependencies based on their own knowledge of the codebase.
Developer drafts the plan, sometimes with light AI assistance for breakdown or scoping. AI has no real visibility into architecture, prior decisions, or affected systems beyond the immediate file.
Developer plans with AI tools that surface architectural context, prior PRs, and affected dependencies during the planning phase itself — narrowing the scope of what gets generated and reviewed downstream.
Step 2: Feature implementation
Developer writes code manually using their own knowledge of the codebase and dependencies.
Developer prompts an AI coding tool. The tool generates code from local context.
Developer prompts an AI coding tool. The tool generates code from local context.
Step 3: Pull request
Developer opens a PR. The diff is visible. Broader codebase impact is not surfaced automatically.
Developer opens a PR. The diff is visible. Broader codebase impact — dependencies, related services, prior decisions — is not.
Before opening the PR, the developer runs context-aware checks in the IDE or via agent skills — surfacing impact beyond the diff before review begins.
Step 4: Code review
Manual peer review. Depends on reviewer availability, expertise, and familiarity with affected areas. Slow and inconsistent.
Manual peer review, same as before. AI generation didn’t help with review; blind spots from generation remain undetected.
AI code review activates with full codebase context. Checks prior PRs, detects breaking changes across dependencies, validates team rules, and surfaces issues the generation tool couldn’t see.
Step 5: Feedback loop
Feedback comes from human reviewers — delayed, varies in depth and specificity. Back-and-forth cycles common.
Feedback still comes from human reviewers. No improvement in feedback speed or structure over the no-AI flow.
Developer receives instant structured feedback — specific issues with severity levels and, in many cases, a directly applicable fix.
Outcome
Issues may be caught in review or slip to production. Quality depends heavily on reviewer knowledge and bandwidth.
Code is written faster, but review quality is unchanged. Generation-introduced issues — wrong assumptions, missed dependencies — may reach production.
The PR merges with known issues addressed, not discovered in production. The full loop is closed: planning, generation, and review all operate with codebase context.
Here is what a PR looks like in the fully AI-enabled flow — the right column above:
- The developer plans the change with AI assistance that surfaces architectural context and affected dependencies before any code is written.
- The developer prompts their AI coding tool to implement the feature. The tool generates code from local context.
- Before opening the PR, the developer runs context-aware checks in the IDE or via agent skills — surfacing impact on related services, prior PRs, and team conventions that the generation tool couldn’t see on its own.
- The developer opens the PR. AI code review activates with full codebase context, validates against the team’s rules, detects breaking changes across dependencies, and confirms what was caught in the IDE while surfacing anything earlier checks missed.
- The developer receives instant structured feedback — specific issues with severity levels and, in many cases, a fix they can apply directly.
- The PR merges with known issues addressed — not discovered in production.
The generation tool and the review system operate independently. That independence is intentional. One is optimized to create; the other is optimized to verify. Both are necessary, and neither substitutes for the other.
The Hidden Cost of AI Code Velocity
The productivity case for AI coding tools is real. Output is up. Cycle times are down. But measuring only the top of the funnel misses where the cost lands.
- 42% of developer time is spent fixing bugs and tech debt — not writing new features (SonarSource State of Code)
- 35% of projects miss deadlines because of quality-related rework (SonarSource State of Code)
- 67% of teams report increased difficulty maintaining code quality since AI adoption scaled (SonarSource State of Code)
The speed gain at commit time is real. The quality cost in production is also real. The gap between them is where technical debt accumulates, security vulnerabilities compound, and senior engineers spend their time debugging output they didn’t write and can’t easily reason about.
Velocity without verification isn’t a productivity win. It’s deferred risk. The review layer isn’t a slowdown — it’s what makes the speed sustainable.
AI Code Review: The Missing Verification Layer Your AI Stack Needs
Everything described above — the volume your team can’t absorb, the context that drops out, the standards that drift — points to the same structural gap: code generation scaled, but verification didn’t.
That’s the problem AI code review was built to solve.
AI code review is a dedicated verification layer that sits between AI-generated code and production. Not a smarter linter. Not a prompt added to your generation tool. A separate system, purpose-built to validate code at the speed and scale AI now produces it — with the full context your generation tool never had.
Here is how AI code review addresses the 4 breakdowns — volume, context,standards drift and feedback timing:
1. AI code review scales review capacity to match generation velocity
AI code review operates on every PR, automatically, at any scale. It doesn’t get slower as your team grows or as AI output increases. When AI review is active, 80% of PRs require no human review comments (Qodo) — not because review is being skipped, but because it’s happening at the right layer. Human reviewers spend their time on the decisions that actually need human judgment.
2. AI code review restores the codebase context generation tools never had
Where generation tools see the diff, AI code review sees the codebase — architecture, dependencies, prior PRs, team-specific patterns. That’s what catches a breaking change in a shared utility three repos away. That’s what flags duplicated logic that already exists elsewhere in the system. Context is what separates a review that finds the real risk from one that misses it entirely.
3. AI code review enforces standards consistently — regardless of who or what wrote the code
AI code review applies your organization’s specific rules — codified, versioned, enforced across every PR, every team, every AI agent writing code in your stack. Standards that used to depend on who happened to review the PR now apply regardless.
4. AI code review delivers feedback in minutes, not days
Review timing changes how developers work. When feedback arrives within minutes of opening a PR, developers act on it while the change is still in their head. When it arrives two days later, the cost compounds — context has to be reloaded, branches need rebasing against main, related work has moved on. This is PR rot: every additional day a PR sits in review adds cognitive overhead to pick it back up and technical overhead to bring it back in sync. AI code review collapses that window from days to minutes, which is what makes the feedback actionable instead of a backlog item.
The generation layer and the review layer are separate by design. One is optimized to create. The other is optimized to verify. Both are necessary — and neither substitutes for the other.
Velocity without verification is deferred risk. AI code review is what makes the speed sustainable — and what the next chapter examines in depth.
➔ Next: What Is AI Code Review? Definition, How It Works, and What It Actually Analyzes
Let’s see what you’ve learned!
Why does AI-generated code fail in enterprise codebases even when it compiles and passes tests?
Select the correct answer
Why isn’t traditional static analysis (SonarQube, Snyk, Checkmarx) enough to verify AI-generated code?
Select the correct answer
Why does the generation layer in an AI stack need to be separate from the verification layer?
Select the correct answer