The Business Case for AI Code Review: Costs, ROI, and How to Measure Impact
This chapter covers why the productivity numbers from AI coding tools don’t tell the full story, where the hidden costs of AI-generated code actually land, and how to build a business case for AI code review with metrics that hold up in budget conversations. It closes with what good looks like 90 days after rollout — and how to measure it.

Key Takeaway
AI coding tools have increased development output by 25–35%. The cost of that velocity shows up later — in production incidents, rework cycles, and senior engineers debugging code they didn’t write. AI code review is how engineering leaders close that gap without slowing teams down.
What You’ll Learn
- Why the productivity numbers from AI coding tools don’t tell the full story
- Where the hidden costs of AI-generated code actually land
- How to build a business case for AI code review — with metrics that hold up in budget conversations
- What good looks like 90 days after rollout, and how to measure it
The Productivity Gain Is Real. So Is the Bill That Comes With It.
The pitch for AI coding tools is clean: developers ship 25–35% more code, cycle times compress, and teams get more output without adding headcount. The numbers are real and the adoption curves back them up.
What those decks don’t show is what happens three months later.
A shared utility gets modified by an AI agent with no visibility into the six other services depending on it. The change passes tests, the PR gets approved, and two days later a downstream service starts behaving incorrectly in production. A senior engineer spends a day and a half tracing the failure back to its source — a merge that looked clean and wasn’t.
AI coding tools solved the generation problem. Most engineering teams now have more code moving faster than ever before. The verification problem — ensuring that code is safe to ship before it reaches production — remains largely unsolved, and that gap is where costs compound.
What Engineering Leaders Get Wrong About AI Velocity
The instinct when AI coding tools ship more code is to measure output. Lines of code. Features shipped. PRs merged per week. Those numbers go up. Leadership is happy.
The problem is that output metrics measure the top of the funnel. They don’t measure what happens to that code downstream.
Scott Hanselman, VP at Microsoft and a veteran of three decades in software engineering, put it plainly in a recent conversation: “You can have a good, fast, or cheap. Pick two.” The promise that AI coding tools eliminate that trade-off isn’t wrong — but it is incomplete. The trade-off doesn’t disappear. It moves. It shifts from “how fast can we write code” to “how much does it cost us when that code fails.”
The data reflects this. According to the State of Code report:
- 42% of developer time is spent fixing bugs and tech debt — not writing new features
- 35% of projects miss deadlines because of quality-related rework
- 67% of teams report increased difficulty maintaining code quality since AI adoption scaled
Velocity without verification isn’t a productivity win. It’s deferred cost.
Where the Costs of Unverified AI Code Actually Land
Engineering leaders building a business case need to know where to look. The costs of unverified AI-generated code aren’t distributed evenly — they concentrate in specific, measurable places.

Review bottlenecks
Review time increases 91% at high AI adoption teams without any corresponding increase in review capacity (Faros AI Engineering Report). Developers can generate in an afternoon what used to take a week. The PR queue grows. Reviewers context-switch across a dozen open reviews. Feedback arrives days after the PR opened, when the developer has already moved on.
This isn’t a people problem. It’s a structural mismatch between generation velocity and review capacity. The math doesn’t work — and the result isn’t slower review, it’s shallower review.
Security vulnerabilities
AI-generated code reuses patterns from training data, including insecure ones. Reports show a 3x increase in security vulnerabilities in AI-assisted codebases. Those vulnerabilities don’t surface until they’re exploited — or until a security audit finds them after the fact, when remediation is significantly more expensive.
“It’s basically almost free to generate terrible code that won’t be usable in three months. It’s much harder to defend against it.” — Dex Horthy, CEO, HumanLayer
Standards drift
Every AI coding tool makes its own assumptions about how code should look. Different developers prompt differently. Without a centralized enforcement layer, every AI-generated PR introduces its own interpretation of your standards. The codebase drifts — not through negligence, but through accumulated variance that nobody explicitly approved.
The senior engineer tax
The hidden cost that never makes it into a budget conversation: what senior engineers spend their time on. When AI-generated code ships without proper verification, it’s your most expensive engineers who debug it in production, trace breaking changes across services, and untangle the technical debt that accumulates quietly until it becomes urgent.
Matt MacKay, a veteran developer relations leader and founder of Plushcap, made this point from the other direction:
“The companies that were doing things to a high level of technical standards before AI tools are probably best equipped to take advantage of a lot of these tools without seeing a lot of the downsides.”
The inverse is equally true — teams with weak verification processes before AI tools will feel those weaknesses more acutely after.
What AI Code Review Actually Costs You Not to Have
The business case for AI code review isn’t just about the risks it prevents. It’s about what the absence of it costs on a per-PR basis.
Cost category
Without AI code review
With AI code review
Bug found in production
10–100x more expensive to fix than at PR stage
Caught at PR stage or earlier
Review time per PR
Increases 91% at high AI adoption
80% of PRs require no human review comments
Security vulnerability remediation
Post-merge, post-incident
Detected before merge
Standards enforcement
Depends on who reviewed the PR
Codified rules applied consistently, every PR
Senior engineer time
Debugging AI-generated code failures
Architecture, design, high-judgment decisions
Developer feedback loop
Days after PR opened
Minutes after PR opened
The last row matters more than it looks. A developer who gets review feedback within minutes of opening a PR acts on it. A developer who gets it three days later is already somewhere else mentally — and the cognitive cost of context-switching back is real.
How to Build the ROI Case for AI Code Review Toolset
Engineering leaders building a budget justification need three numbers: the cost of the problem, the cost of the solution, and the measurable improvement. Here’s how to structure that conversation.
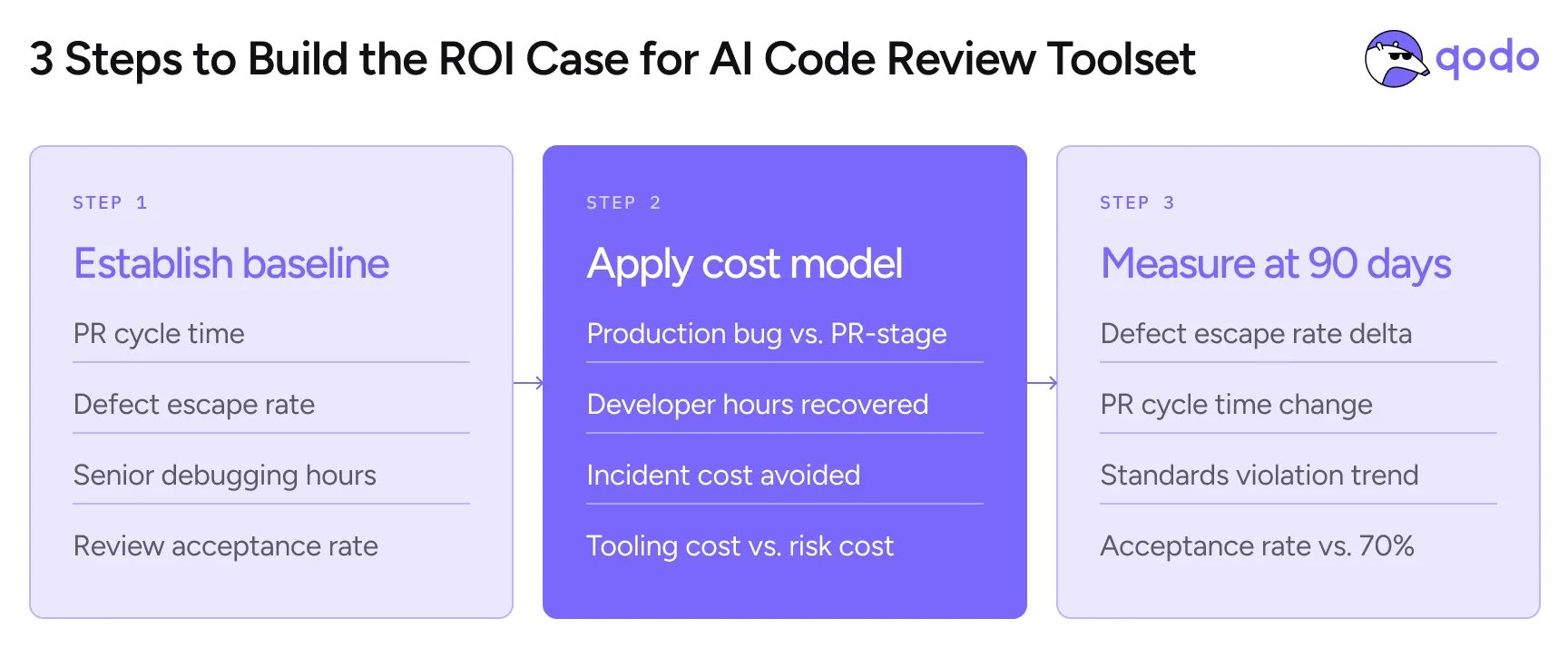
Step 1: Establish the baseline cost
Start with what you can measure today:
- PR cycle time — from open to merge. High AI adoption teams with no review layer see this increase as the queue backs up.
- Defect escape rate — issues found in production vs. issues caught pre-merge. Track this for 90 days before and after.
- Review comment acceptance rate — if developers are dismissing most AI review comments as noise, the tool isn’t working.
- Senior engineer time on debugging — approximate the hours per week senior engineers spend on issues that originated in AI-generated code.
Step 2: Apply the cost model
The industry benchmark for the cost of a bug found in production vs. at the PR stage is a 10–100x multiplier — depending on the complexity of the system and how long the bug lived before discovery.
Monday.com saves developers approximately one hour per pull request and prevents 800+ potential issues from reaching production every month with Qodo active. For a team of 50 developers each opening 4 PRs per week, one hour per PR recovered translates to roughly 800 developer hours per month — at a senior engineer’s fully-loaded rate, that’s a number that belongs in a budget conversation.
Step 3: Know what success looks like at 90 days
The right metrics to track after rollout are the ones that tell you whether the verification gap is actually closing — not just whether the tool is active.
- Defect escape rate — the ratio of issues caught pre-merge vs. found in production. This is the primary signal. It should move within 60–90 days.
- PR cycle time — stable or decreasing, because human reviewers are spending time on fewer, higher-value decisions.
- Review comment acceptance rate — above 70% indicates the signal-to-noise ratio is working. Qodo’s current rate is 73.8%, meaning developers are acting on feedback rather than dismissing it.
- Standards violation trend — declining over time as rules are enforced consistently and developers internalize them.
- Senior engineer debugging hours — decreasing, because production incidents that originated in AI-generated code become less frequent.
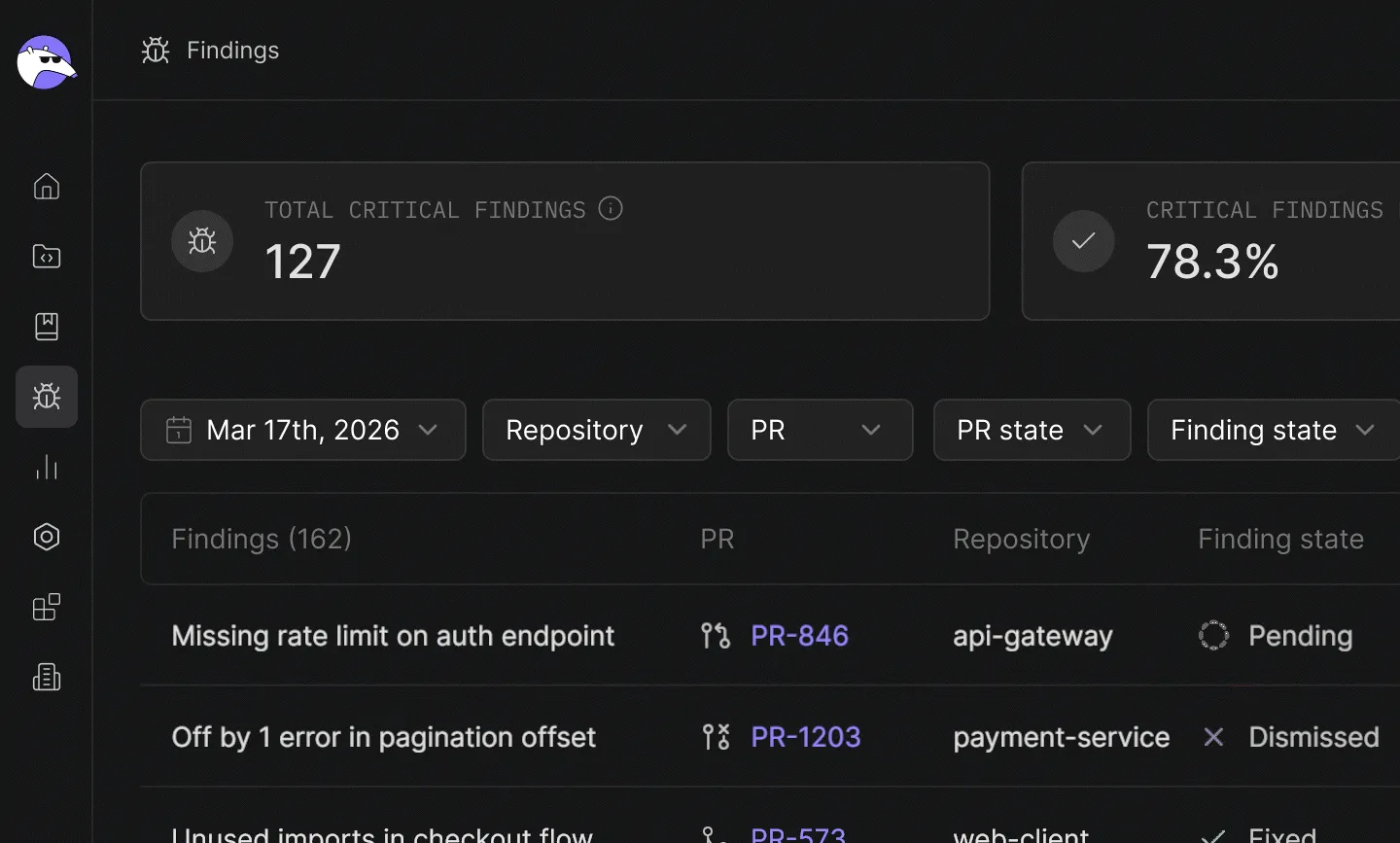
The challenge with these metrics has always been visibility. Engineering leaders can answer questions about individual pull requests, but answering the version of that question that spans the whole organization — which repos are accumulating the most risk, whether the same issues are being flagged repeatedly, whether resolution rates are improving — historically meant stitching together Slack threads and spreadsheets.
Qodo’s Findings Page consolidates every issue surfaced across reviewed pull requests into a single view, with filters by repo, owner, and issue type, and analytics showing total critical findings, resolution rates, and average findings per PR. It’s the difference between knowing a tool is running and knowing whether it’s working.
The Objection Engineering Leaders Hear Most
“We can just ask developers to review more carefully.”
This conflates the problem with the solution. The problem isn’t developer attention. Review time is already increasing 91% with high AI adoption — developers are spending more time on review, not less. The issue is that the volume of AI-generated code has outpaced what any human review process built around human bandwidth can reliably handle.
The answer isn’t more careful review. It’s a review layer that scales with generation velocity.
“Can’t we use the same AI tool that generates the code to review it?”
No — and this is one of the most important architectural decisions in an AI-enabled development stack. The model that generated the code will evaluate it through the same lens it used to produce it. It shares the blind spots it created. Verification requires an independent system with a different purpose: not fluency and speed, but adversarial, context-aware analysis anchored in your specific codebase.
“We’ll address quality after we’ve shipped more features.”
This is how technical debt compounds quietly until it becomes a crisis. The moment to close the verification gap is before the codebase accumulates issues that are expensive to find and painful to untangle. As Hanselman put it: if you introduce AI into an immature SDLC without a verification layer, “you’re putting a band-aid on cancer.”
Summary
The business case for AI code review is a cost model. Review time increases 91% at high AI adoption without any corresponding increase in review capacity. Security vulnerabilities in AI-assisted codebases are up 3x. 42%of developer time goes to bugs and rework rather than new features. These costs are real, measurable, and addressable before they compound.
The ROI calculation is straightforward: establish a baseline on defect escape rate, PR cycle time, and senior engineer debugging hours, then measure the delta at 90 days. For a team of 50 developers each opening four PRs per week, recovering one hour per PR translates to roughly 800 developer hours per month — at a senior engineer’s fully-loaded rate, that number belongs in any budget conversation.
Engineering leaders who build the verification layer now are protecting the productivity gains the generation layer already delivered. Those who wait will find the cost of the gap in a production incident — when remediation is significantly more expensive than prevention would have been.
See what a verified AI code review workflow looks like in practice. Book a demo →