What makes a good code review benchmark for AI tools?

As AI coding tools become more common, the amount of code being produced is increasing. Teams can generate changes faster than ever, but the capacity for human review has not grown at the same pace. This creates a widening code review gap.
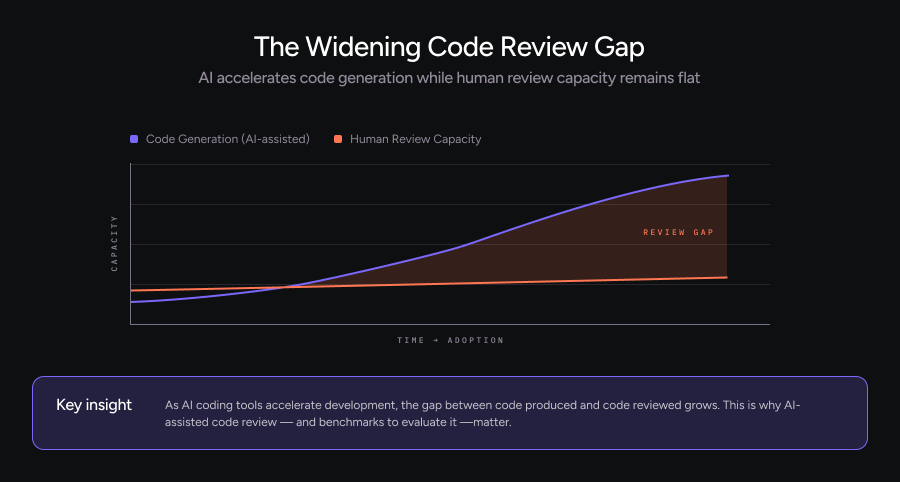
Qodo was built to address this problem and help developers catch issues early, reduce reviewer load, and keep quality high as development speeds up. As more teams adopt AI, the question is no longer whether to use AI for code review, but how well it actually works.
Benchmarks are critical in this context. They provide a way to evaluate whether an AI code review system can handle real pull requests, understand context, and provide useful feedback. Without benchmarks, it is difficult to measure efficacy or compare tools beyond surface claims.
For AI-based systems, this challenge is even greater. Behavior can vary widely based on data, models, and configuration. Benchmarks help expose these differences in a consistent and repeatable way.
What exists in code review benchmarks today
Despite the growing need, there is no widely accepted benchmark for AI code review.
Most existing evaluations focus on adjacent tasks, such as bug detection or code generation. These do not capture the full scope of code review, which involves reasoning across files, understanding developer intent, and suggesting actionable fixes.
Some recent efforts claim to benchmark pull request–level performance, often using manually collected data. In many cases, the datasets and scoring methods are not fully published or are hard to reproduce. This limits their usefulness as shared standards.
As a result, teams building or adopting AI code review tools lack a clear way to test and compare them. This gap is why defining strong benchmarks, and using them to evaluate real-world efficacy, has become increasingly important. A strong benchmark reflects real development work and measures what actually matters to developers.
Below are the core principles that Qodo uses to define a code review benchmark and evaluate our own code review solutions in solving real-world coding problems.
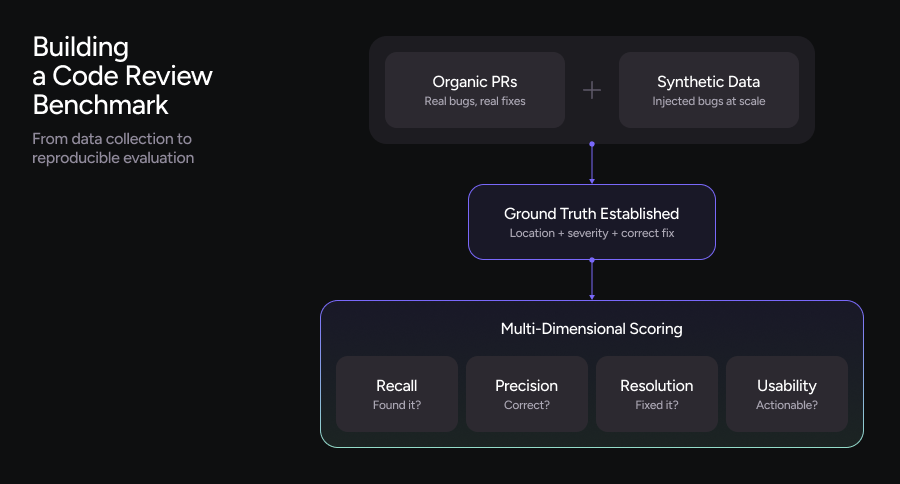
Building a Meaningful Dataset
The foundation of any benchmark is its dataset, and for code review, this means carefully curated pull requests that reflect real development challenges.
Real PRs, real complexity with organic data
The highest-value benchmark data comes from organic sources: pull requests created to address actual issues in active codebases. Open source repositories provide a rich collection ground, where you can trace a bug’s full lifecycle from issue creation through resolution and merge. These PRs carry context that reflect real development pressure, real architectural constraints, and real tradeoffs made under deadline.
But not all organic data is equally useful. Minor issues like missing docstrings or formatting inconsistencies add little signal. The bugs that actually take down production systems are often systematic. They span multiple files, break architectural patterns, or emerge from subtle interactions between components. A deprecated API used inconsistently across a codebase. A security flaw in how authentication tokens propagate through services. A race condition that only manifests under specific load patterns. These categories mirror what code review is actually meant to catch in production environments.
These bugs are harder to detect, harder to include in benchmarks, and far more valuable to catch. A benchmark that includes a meaningful percentage of cross-cutting, architectural issues better reflects the real-world value of code review tools. Any tool can flag a missing null check. Finding architectural drift or systemic vulnerabilities is where differentiation happens.
Coverage at scale using synthetic data
However, organic data collection does not scale. Manually curating PRs across dozens of programming languages, multiple frameworks, and varied domains (backend services, frontend applications, data pipelines, infrastructure code) would require a dedicated team working indefinitely without reaching comprehensive coverage.
Synthetic data addresses this limitation. By programmatically injecting known bugs into clean codebases, you can systematically cover language-specific edge cases, framework-particular anti-patterns, and domain-specific failure modes. The injection point becomes ground truth, enabling automated evaluation at scale.
The most rigorous benchmarks combine both approaches. The balance between these two sources determines whether a benchmark is both realistic and comprehensive.
Establishing ground truth
Ground truth is what makes a benchmark measurable. Without it, you have no basis for scoring. For code review benchmarks, ground truth must be explicit, unambiguous, and include both the defect and its resolution.
Synthetic ground truth is straightforward to establish. When you inject a bug, you control every variable: the exact location, the failure mode, the severity classification, and the correct fix. Inject a use-after-free in a C++ function, and ground truth is the line number, the memory access pattern, and the patch that eliminates the dangling pointer. This precision enables automated evaluation with high confidence.
Organic ground truth is harder. Real bugs do not come with labels. Establishing ground truth requires reconstructing intent from multiple sources: the original issue report, review comments, commit messages, and the final merged diff. Sometimes the evidence is clear. A reviewer flags a null pointer dereference, the author adds a guard clause, and the fix is merged. Other times, ground truth must be inferred. A performance regression might be resolved by introducing a cache, even if no reviewer explicitly identified the root cause as redundant computation.
This reconstruction process demands either significant manual effort or agentic tooling that can parse issue threads, correlate review feedback with code changes, and validate that the merged state actually resolves the identified problem. Neither approach is trivial, and both introduce potential for error.
The investment is necessary. Ambiguous ground truth produces ambiguous scores. If your benchmark cannot clearly define what “correct” looks like for each example, evaluation results become meaningless.
Resolution, not just detection
A common mistake in code review benchmarks is focusing solely on bug detection. Can the tool find the issue? That’s only half the story.
Effective code review tools don’t just flag problems; they help developers fix them. Can the tool suggest a fix? Is that fix correct? Does it follow the patterns and conventions of the codebase? Including resolution quality in ground truth transforms a detection A benchmark should evaluate whether tools provide actionable remediation guidance, not just whether they can identify that something is wrong.

Define scoring beyond bug detection
Recall and precision are table stakes. Yes, you need to know whether a tool catches bugs (recall) and whether its suggestions are accurate (precision). But these metrics alone miss critical aspects of the developer experience.

Conciseness: If Tool A explains an issue in 100 words and Tool B takes 500 words to say the same thing, developers will prefer Tool A. Comment length and clarity directly impact whether feedback gets read and acted upon.
Speed: A tool that takes 30 minutes to review a PR might achieve marginally better accuracy, but it’s not practical for real workflows. Benchmarks should account for the tradeoff between thoroughness and turnaround time.
Signal-to-noise ratio: Finding every possible issue isn’t helpful if developers are buried in low-value comments. The best tools surface meaningful problems without drowning teams in trivial suggestions. How many comments are unique, correct, and actionable versus spammy or redundant. They should also capture temporal behavior such as time-to-first-useful comment and whether the reviewer updates or withdraws advice as new commits arrive.

Meaningful suggestion: Optimal code review tools should optimize for precision, such that the suggestions will be correct for the team or repo level to provide meaningful suggestions over volume, this put much more complexity on the data set as now there is data that is not grounded directly in what we call “issues” there are user comments / patterns from past PR’s etc. Having the ability to score the agent according to these metrics is hard but something a good benchmark should measure as this represents real value for users in production.
Reproducibility
A benchmark only has value if others can verify the results. This means publishing not just scores but the methodology, dataset (where licensing permits), and evaluation criteria.
Some vendors have announced benchmark efforts with impressive methodology descriptions but without releasing the actual data or evaluation scripts. These efforts may represent genuine progress, but their value as shared standards is limited until the community can inspect and build on them.
Ideally, if a tool claims strong benchmark performance, others should be able to run the same tests and confirm the results. Without that level of transparency, it is harder to distinguish rigorous evaluation from selective reporting
What We’re Building Toward
We believe the industry needs shared standards for evaluating AI code review. That belief is shaping how we approach benchmarking at Qodo.
We are working toward a benchmark that combines organic PRs from real open source projects with synthetic data for broad language and domain coverage. We are developing methods to establish ground truth through both manual validation and agentic reconstruction. And we are designing scoring that goes beyond detection to measure remediation quality, conciseness, and practical usability.
As this work matures, we intend to publish our methodology, release evaluation scripts, and share results in a way that others can reproduce and build on. The goal is not just to measure our own tools, but to contribute to an industry-wide foundation for meaningful evaluation.


