5 AI Code Review Pattern Predictions in 2026

Agentic AI is about to change code review. But not in the way most people expect.
I’m not talking about auto-approval and faster throughput. That mindset treats review as friction to eliminate. It’s the same mistake the industry keeps making: optimizing for speed while ignoring what review actually exists to protect.
What I’m seeing instead is something more interesting. Teams are starting to admit that their current code review process was never designed for the velocity that AI code generation has introduced. The old workflow assumed humans wrote code at human speed. That assumption is now broken.
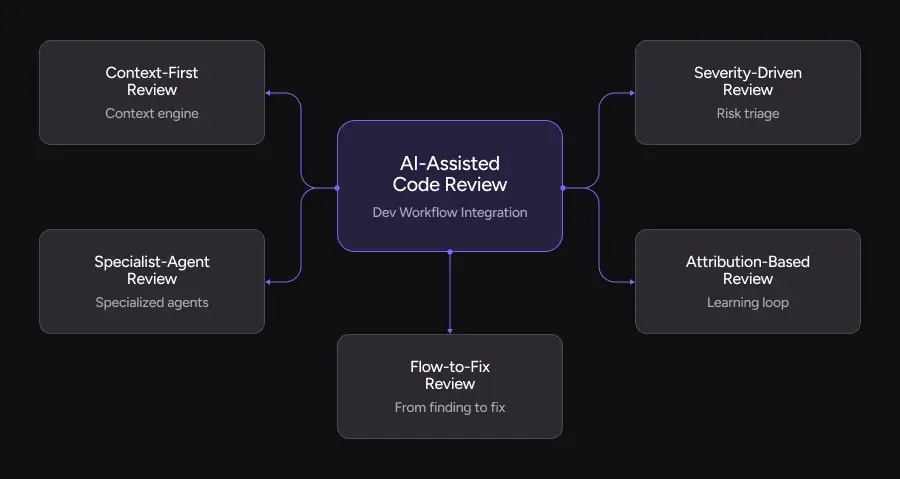
In 2026, the teams that pull ahead won’t be the ones who “add AI to review.” They’ll be the ones who adopt patterns that assume three things:
- AI can see more of the codebase than any single human reviewer
- Context is a first-class artifact
- Review is a system with feedback loops, not a one-off checkpoint
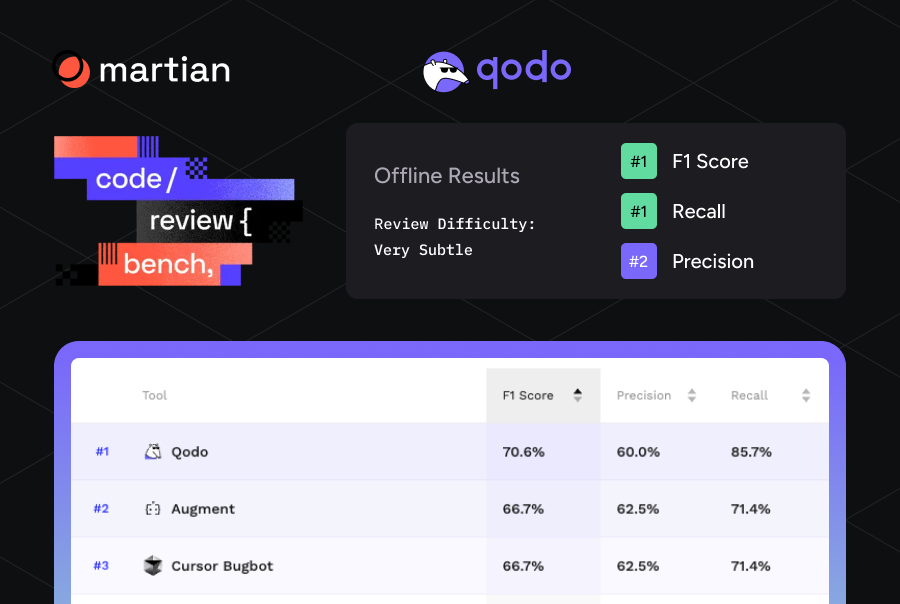
This post introduces five patterns for AI-assisted code review I’m predicting as tools like Qodo narrow down real developer workflow pain points in this AI development paradigm. Take this as potential ways of working that context-aware, agentic systems will finally make possible.
1. Context-First Review
Most teams still review code like this:
Open diff. Skim quickly. Guess at context. Hope you’re not breaking production.
Context gets treated as “whatever the reviewer remembers” plus maybe a Jira link that nobody reads. That might work when the system is small and all contributors share tribal knowledge. It falls apart completely at enterprise scale.
Context-First Review treats context as a required input to code review, not a nice-to-have.
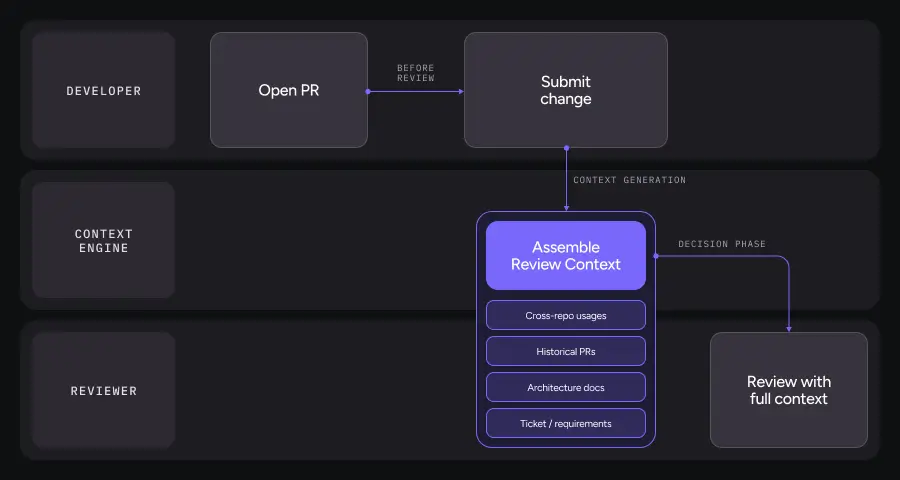
What This Looks Like in Practice
Before any human or AI starts reviewing, a context engine assembles a minimal, high-signal set of artifacts:
- Cross-repo usages of the functions and classes being touched
- Historical PRs that modified the same modules, including what broke
- Comment history from senior engineers documenting past decisions
- Relevant architecture and convention documentation
- Ticket or requirement text explaining why this change exists
The result is a review context report that answers three questions:
- What does this change touch beyond this one file?
- What decisions did we already make about this area of the system?
- What are the non-negotiable requirements and constraints?
Only after that do humans and AI review the diff.
Why Context-First Review Matters
Context-First Review moves the bottleneck from “figuring out what’s going on” to “deciding if this is a good change.”
Authors spend less time over-explaining PRs because the context engine surfaces what matters. Reviewers ask deeper questions (“Is this the right abstraction?”) instead of basic ones (“Where is this called from?”). AI reviewers stop hallucinating advice that ignores how the system actually works.
Review becomes investigation, not guesswork.
2. Severity-Driven Review
If you’ve ever watched a bot flood a PR with 37 comments about spacing while missing the one null-check that takes production down, you already understand why Severity-Driven Review needs to exist.
AI makes it trivial to generate findings. The real challenge is triage.
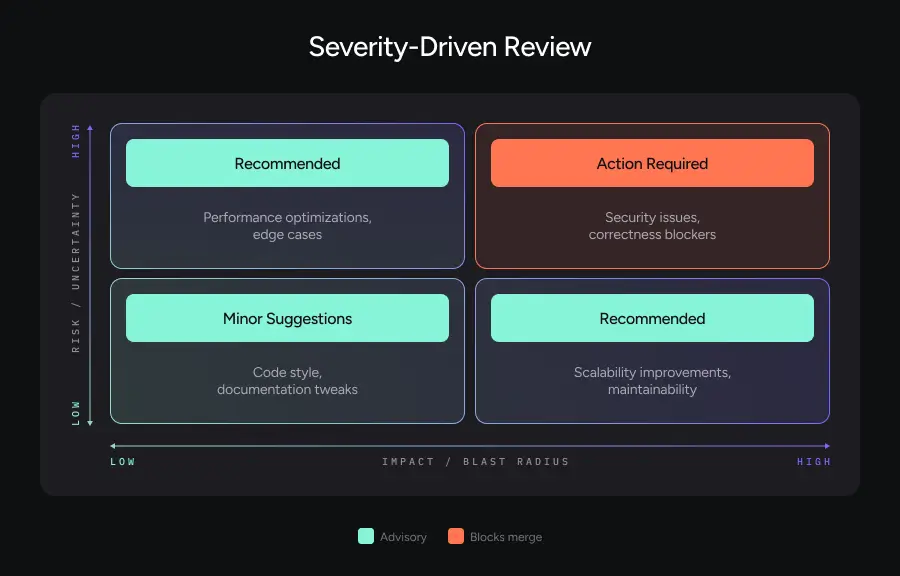
What This Looks Like in Practice
Every finding that comes out of your review system gets assigned a severity level:
Action Required blocks merge. Must be resolved.
Recommended should be addressed, but merge might still proceed with explicit acknowledgment.
Minor Suggestions cover nits, style, future refactors, and “if you touch this again, consider…” notes.
Instead of dumping comments inline with no structure, the review output gets organized as:
- A high-level summary
- A small set of Action Required items (ideally countable on one hand)
- Grouped Recommended items
- Collapsed Minor suggestions that developers can expand if they want
Reviewer feedback (“this was overkill; lower severity” or “this should have blocked the PR”) feeds back into the system so triage improves over time.
Why Severity-Driven Review Matters
Attention is finite. Without severity-driven triage, critical issues get buried under cosmetic noise. Developers start ignoring AI comments altogether. The perceived quality of AI review drops, even if it’s technically accurate.
With Severity-Driven Review, the experience changes. Developers know what they must address versus what’s optional. Teams can create clear policies (“no Action Required findings in security or correctness categories at merge time”). Review time gets spent where it actually protects the business.
Review becomes risk management, not comment quantity as a proxy for quality.
3. Specialist-Agent Review
Right now, most AI code review feels like asking one generalist model to be your security engineer, performance expert, staff SWE, architect, and product-minded reviewer all in a single prompt.
That’s how you get generic advice.
Specialist-Agent Review assumes that review should look more like a panel than a monologue.
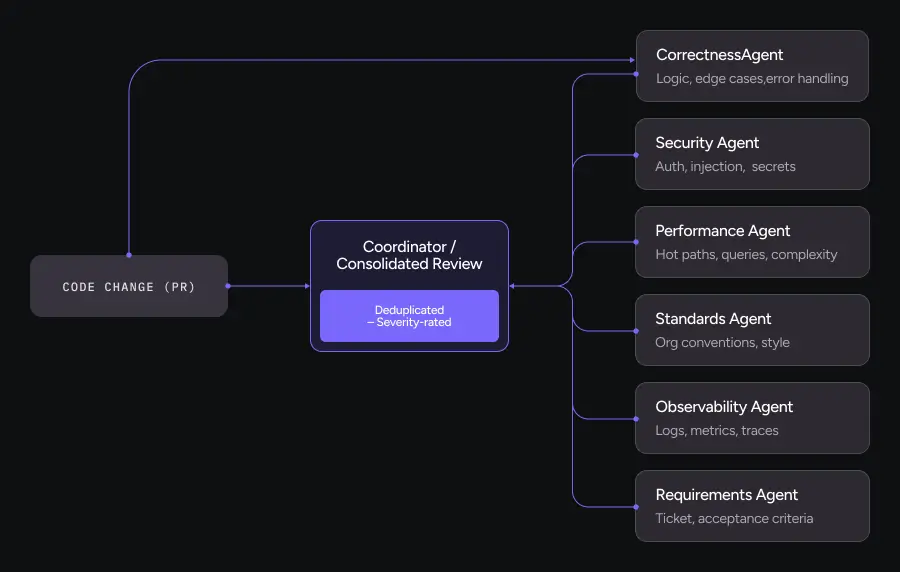
What This Looks Like in Practice
Instead of a single “review” step, the system spins up specialized agents, each with a focused objective and evaluation rubric:
Correctness agent looks for logic bugs, edge cases, error handling, and invariants.
Security agent examines authz/authn, injection risks, secrets exposure, and insecure patterns.
Performance agent evaluates hot paths, N+1 queries, unnecessary allocations, and algorithmic complexity.
Observability agent checks logs, metrics, traces, and debuggability under failure.
Requirements agent validates whether the code actually satisfies the linked ticket or acceptance criteria.
Standards agent enforces organization rules, style guides, naming conventions, and framework-specific patterns.
Each agent gets a tailored prompt and context. Each outputs findings scoped to its domain. Each uses domain-specific categories (“Injection Risk” versus “General Bug”).
Then a coordinator consolidates everything into one coherent review: deduplicated and severity-rated.
Why Specialist-Agent Review Matters
You get the best of both worlds: depth of specialized review and a single, digestible experience for the developer.
You also gain explainability. “This came from the security agent based on rule X and historical PR Y” is far easier to trust than “the model said so.”
Review becomes a multi-disciplinary practice, not one reviewer trying to do everything.
4. Attribution-Based Review
Here’s a problem nobody talks about: most review and lint tooling has no feedback loop.
You might be running dozens of checks that everyone ignores, and you’ll never know because the feedback stops at “comment posted.” There’s no signal about which suggestions are actually helpful over time.
Attribution-Based Review changes that by asking one simple question for every finding: “What happened next?”
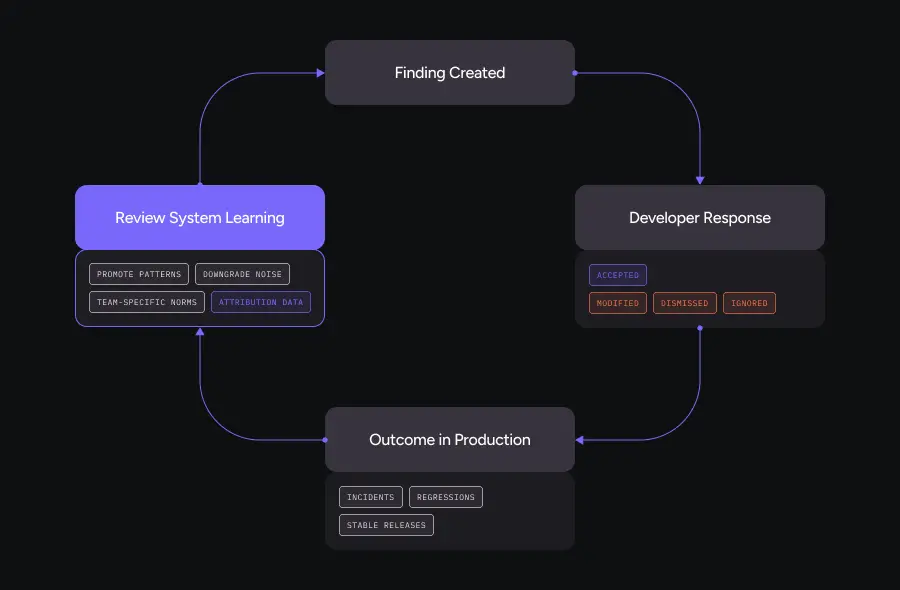
What This Looks Like in Practice
Every AI or automated suggestion carries an ID and gets tracked through its lifecycle:
- Was it accepted as-is?
- Was it modified and then accepted?
- Was it explicitly dismissed?
- Was it ignored but the PR merged anyway?
That attribution data powers three capabilities:
Organic standard discovery. If the team repeatedly accepts a certain pattern of suggestion (“add structured logging around external calls”), the system can treat it as an emerging best practice.
Noise reduction. If a category of suggestion is consistently dismissed, it can be downgraded in severity or disabled entirely.
Calibration between teams. Different services or domains may converge on different norms, and the system learns those distinctions automatically.
Why Attribution-Based Review Matters
Attribution turns review from a static gate into a learning system.
Developers feel less “nagged” because low-value findings fade over time. Teams don’t have to periodically herd cats in a config file. Leadership can see which findings correlate with real quality improvements: fewer incidents, fewer regressions.
Review becomes reinforcement learning from humans, not just from models.
5. Flow-to-Fix Review
Most workflows still treat review as a disconnected process. Someone leaves comments. Someone else reads them. They tab over to their IDE and manually fix things. Everyone hopes the reviewer is still around to re-check.
This is especially painful in an AI-assisted world where code is partly generated. There’s a mountain of small issues that are easy to fix but annoying to chase.
Flow-to-Fix Review assumes that as soon as a finding exists, it should be one step away from a candidate fix, without destroying the developer’s flow.
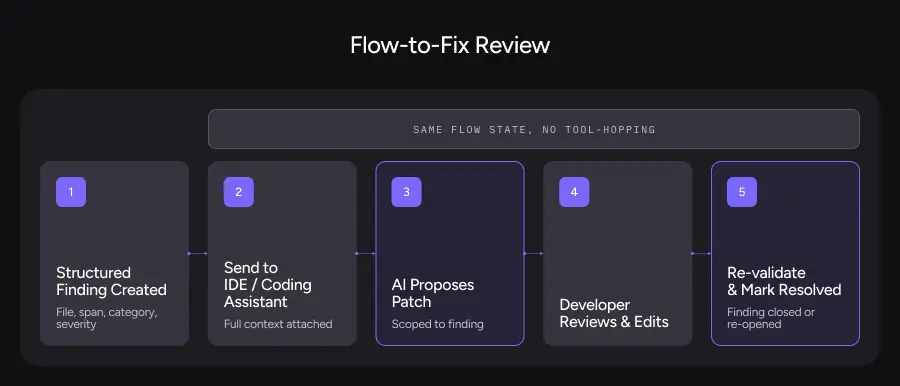
What This Looks Like in Practice
Under Flow-to-Fix, every structured finding is designed to be:
Machine-consumable. Clear metadata: file, span, category, severity, reasoning.
Agent-friendly. Can be used as a prompt to an IDE agent or code generation tool.
Round-trip aware. The system can see whether the suggested fix actually resolved the issue.
The workflow looks like this:
- Review system surfaces structured findings with severity and rationale
- Developer chooses a finding and sends it directly to an AI coding assistant
- Assistant proposes a patch scoped to that finding
- Developer reviews, edits, and applies the patch
- Review system recognizes the change, re-validates, and marks the finding as resolved (or not)
All of this happens without losing flow state. You’re not bouncing between ten tools. You’re in a tight loop from finding to suggestion to candidate fix to validation.
Why Flow-to-Fix Review Matters
Flow-to-Fix closes the gap between “knowing what’s wrong” and “actually fixing it.”
It reduces the cognitive tax of addressing a long list of findings. It encourages developers to fix more “Recommended” and “Minor” items because the effort is low. It keeps review and remediation in the same mental space instead of turning fixes into a separate mini-project.
Review becomes a continuous, assisted editing loop, not a static judgment.
How This Changes the Development Lifecycle
Taken together, these five patterns reshape the journey from code generation to review to production-ready:
During coding: Developers know that Context-First Review and Specialist-Agent Review will inspect their work with realistic context and specialized lenses. They can rely less on “hope someone catches this later” and more on intentional design.
At PR time: Severity-Driven Review ensures that if something is truly dangerous, it bubbles to the top. You’re not wading through nits to find the one security landmine.
Across releases: Attribution-Based Review and Flow-to-Fix Review tighten the feedback loop. Every review becomes a training signal, and every finding is one click away from a concrete fix.
At scale: Teams move from manual heroics to systematized review, with AI doing the heavy pattern-matching and humans doing the high-level judgment.
The net effect: code review becomes less about blocking and more about amplifying engineering judgment.
How to Evaluate AI Code Review Tools in 2026
If you’re evaluating AI code review solutions this year, the marketing will be noisy. Every vendor will claim intelligence, speed, and security. The differentiator is whether a tool actually solves the problems your team faces or just adds another layer of automation that people learn to ignore.
Here’s how to cut through the noise by matching tool capabilities to real pain points.
1. Start With Your Actual Bottlenecks
Before looking at features, diagnose where your review process breaks down:
“Reviews take forever because reviewers lack context.” You need Context-First Review capabilities. Ask vendors: How does your tool surface cross-repo dependencies? Can it pull in historical decisions and architecture docs automatically? If the answer is “you write better PR descriptions,” that’s not a solution.
“Critical issues get buried under style nits.” You need Severity-Driven Review. Ask: How does the tool prioritize findings? Can teams configure what blocks merge versus what’s advisory? If everything shows up as the same priority, your developers will tune it out within a month.
“Generic suggestions that ignore our codebase.” You need Specialist-Agent architecture. Ask: Does the tool use specialized analysis for security, performance, and correctness, or is it one general-purpose model? How does it learn your organization’s conventions? Generalist tools produce generalist advice.
“We have no idea which suggestions actually help.” You need Attribution-Based learning. Ask: Does the tool track what happens after a suggestion is made? Can it show which categories of findings correlate with fewer production incidents? If there’s no feedback loop, you’re flying blind.
“Developers ignore findings because fixing them is tedious.” You need Flow-to-Fix integration. Ask: Can findings be sent directly to coding assistants with full context? Does the tool verify that fixes actually resolve the issue? Disconnected workflows create disconnected outcomes.
2. Map Capabilities to Business Goals
Engineering leadership cares about different metrics than individual developers. When presenting tool options, translate pattern capabilities into business language:
Reducing time-to-merge without increasing incident rate. Context-First and Severity-Driven Review directly address this. Reviewers spend less time gathering context and more time on decisions that matter. Measure: average review cycle time, post-deploy rollback frequency.
Improving security posture before audit season. Specialist-Agent Review with a dedicated security agent catches vulnerabilities that generalist tools miss. Measure: security findings caught in review versus discovered in production or penetration testing.
Decreasing onboarding time for new engineers. Context-First Review reduces tribal knowledge dependency. New reviewers get the same context as tenured staff. Measure: time until new engineers can review PRs independently.
Demonstrating ROI on developer tooling investments. Attribution-Based Review provides the data. You can show which suggestions led to measurable quality improvements. Measure: correlation between accepted suggestions and incident reduction.
Maintaining velocity as the team scales. All five patterns address scale, but Flow-to-Fix has the most immediate impact on individual developer throughput. Measure: findings addressed per PR, time from finding to resolution.
Questions That Reveal Tool Maturity
Beyond feature checklists, these questions expose whether a vendor understands the problem space:
“How do you handle multi-repo codebases?” Context-awareness that stops at repo boundaries is table stakes for startups, inadequate for enterprises.
“What happens when your suggestions are consistently wrong for our codebase?” Tools without learning loops will keep making the same mistakes. Tools with attribution can adapt.
“Can we see the reasoning behind findings, or just the findings themselves?” Explainability builds trust. Black-box suggestions get ignored.
“How do you prevent alert fatigue?” If the answer is “we’re very accurate,” push harder. Accuracy without severity triage still overwhelms developers.
“What does integration with our existing workflow look like?” Tools that require wholesale process changes rarely get adopted. The best tools meet teams where they are.
The Real Evaluation Criteria
Strip away the marketing and ask three questions:
- Does this tool help my reviewers make better decisions, or just faster ones?
- Does this tool learn from how my team actually works, or does it impose generic standards?
- Does this tool make responsibility clearer, or does it diffuse accountability behind automation?
The tools that answer yes to all three are the ones worth piloting. Everything else is noise with better packaging.