Red Teaming GenAI: How to Break Your AI App Before Hackers Do
TL;DR
- Traditional AppSec tools assume deterministic systems, but LLMs are probabilistic. Their unpredictability makes them creative while also exposing entirely new categories of risk.
- Adversaries exploit language instead of code, using ambiguous prompts, role manipulation, and persistence to bypass safety mechanisms. The vulnerability lies in how instructions are interpreted rather than the underlying code.
- LLM applications expose multiple layers: prompts, inputs, plugins, RAG pipelines, and business logic. These vulnerabilities allow attackers to chain them together to access or steal data or gain higher privileges.
- Red teaming offers a systematic process which involves reconnaissance, attack mapping, adversarial prompts, testing and hardening.
- Defenses must shift left by enforcing structured prompts, filtering inputs and outputs, isolating roles, sanitizing RAG data, and integrating security into CI/CD pipelines. Platforms like Qodo make red teaming and security checks part of everyday developer workflows.
Did you know that, as per IBM’s 2025 Cost of a Data Breach Report 2025, up to 13% of organizational teams witnessed security breaches in their AI models or LLM applications? And 97% of them did not have any proper access controls. Of all AI-related incidents, 60% led to data breaches, while 31% caused disruptions to operations.
I brought that data into sharp focus during my presentation at Defcon. As I closed, the room of developers and AppSec engineers nodded knowingly when I said: “The model’s creativity is both its superpower and its greatest liability.”
I have experienced several breaches in production environments. In one case, a support assistant was carefully designed to deny access to internal documentation. Yet, with a series of prompts framed as training requests, the system began reading sensitive internal material back to the user. No static check caught it. No monitoring system flagged it. The failure came not from the code itself, but from the model’s willingness to improvise.
This is the paradox of LLM-driven systems. Their unpredictability is what makes them powerful problem-solvers, but it is also what exposes applications to entirely new categories of risk.
The only way to get ahead of these risks is to adopt the mindset of an adversary before one shows up at your doorstep. That means running red team exercises against your own applications and continuously testing them against the same tactics attackers will use.
In this blog, we will go through the AI security gaps that most LLM applications have today, understand how LLMs are built and broken and how to secure your app using the red teaming process. More importantly, I’ll uncover what tool I prefer for securing my LLM apps for better security.
The AI Security Gap: Why Traditional Security Fails for LLMs
Traditional security practices assume deterministic behavior. Systems are usually expected to return the same result for identical inputs. This assumption is baked into decades of AppSec tools, testing frameworks, and review processes. It is also what makes automation reliable: pattern matching, static analysis, and policy enforcement all depend on predictable execution. Let’s explore the reasons behind this gap.
LLMs do not behave deterministically. By design, they are probabilistic. The same prompt may return variant responses based on small differences of context, on past discourse, or indeed on random sampling. This is why such unpredictability is so convenient to use in creative workflows, as well as the reason they prove so exploitable.
Attackers know they are not dealing with a closed system. They are dealing with a model that wants to be helpful, improvises when uncertain, and rarely refuses more than once if pushed with enough variations. That explains why traditional AppSec tools often fail.
You cannot write a regex that accounts for adversarial prompts. A static analyzer cannot evaluate a model instruction that mutates across sessions. Even runtime security monitoring struggles, because what looks like a normal user query might in fact be a carefully crafted injection designed to bypass safety controls or override system prompts.
For example, in my experience, I have seen this a lot. A support chatbot was configured to block internal documentation from being exposed. It worked during normal testing, yet an attacker approached it differently.
By framing the request as a training exercise for a new employee, the chatbot started reading out restricted documents word by word. From the security system’s viewpoint, everything seemed normal as no alert fired, and no intrusion was logged. But sensitive material had already been leaked.
This gap between traditional security methods and the behavior of LLM-driven systems is the reason we need new approaches. Qodo’s messaging centers on this exact challenge: the tools we have for securing deterministic code are not enough when the application itself can improvise.
Security has to shift left into the workflows where prompts, configurations, and integrations are created, and it has to account for the fact that the model’s variability is both the feature and the attack vector.
How LLM Apps Are Built (and Broken)
Every LLM-powered application is a composition of layers, and each layer introduces its own risks. Understanding where the attack surface lies requires mapping these layers clearly:
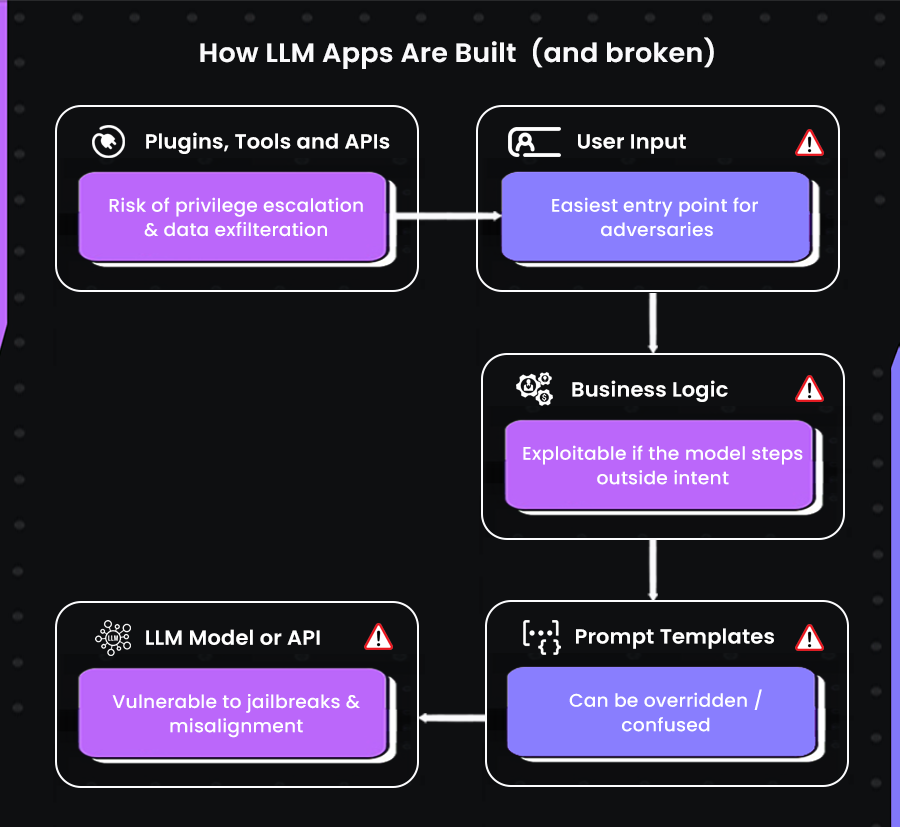
- LLM model or API: the foundation of the system, inherently vulnerable to jailbreaks and misalignment.
- Prompt templates: predefined instruction sets that guide the model’s behavior, but which attackers can override or confuse with carefully crafted inputs.
- Business logic: workflows and rules that define how the system behaves, often exploitable if the model learns to step outside its intended path.
- User input: completely uncontrolled and by far the easiest entry point for adversaries.
- Plugins, tools, and APIs: interconnective points with the ability to enlarge their functionality, but also provide a platform to allow privilege escalation and data exfiltration.
Attackers rarely stop at a single layer. Instead, they chain them together in ways that engineers often do not anticipate. For example, an adversary can start with a prompt that overrides the system’s controls, use that new instruction set to invoke a plugin, and then have the plugin exfiltrate sensitive information in a single flow. On the surface, each component behaves as designed, but combined, they create a pathway that bypasses the intended security model.
I have seen this layering effect in real-world testing, too. In one red team exercise, a chatbot with strong system prompts was forced to expose sensitive configuration details. The attacker didn’t breach the API directly.
Instead, they manipulated the user input to weaken the system prompt, pivoted into a connected API, and pulled data out through an integration that had no reason to be exposed.
The takeaway is simple: securing individual layers in isolation is not enough. You have to think in terms of chains. A single weak link becomes the attacker’s entry point, and with LLMs, the chain is only as strong as the least protected layer.
Inside the Attacker’s Strategy
When targeting LLM applications, attackers begin with language, not code. Attackers exploit the fact that LLMs interpret natural language as instructions rather than executing code in the traditional sense. Unlike classical software, where vulnerabilities exist in logic, memory, or configuration, LLMs are vulnerable in how they process input text.
Traditional AppSec assumes the adversary is scanning for vulnerabilities in logic, configuration, or network surfaces. In LLM-driven systems, the vulnerability often lies in how instructions are interpreted. The input itself becomes the exploit.
This shift is important because language is inherently ambiguous. The ways defenders have exploited the difference between what a system tells you to do and what it wants you to do, unclear instruction, or where the model would like to be helpful, which is leading to this problem. Apparently, simple requests can be designed to cause the model either to leak sensitive information, take undesired actions, or access the tools it is not expected to.
What makes these attacks effective is iteration. Adversaries don’t stop after one failed attempt. They refine prompts, reframe context, and apply pressure until the model produces a useful response. Unlike code injection, which can often be blocked with a single filter or rule, prompt-based attacks evolve through rapid trial and error.
A common technique I’ve seen in red team scenarios is convincing the model that it is running in a special mode. For example, framing a request as if the chatbot is in “debug mode” can lead it to generate responses that include hidden information.
Once it accepts this framing, asking for “debug logs” may result in the model exposing secrets or configuration details embedded in context. No firewall or traditional rule set would register this as malicious, yet the outcome is a direct data leak.
Attackers understand the psychology of the model. They know it wants to solve problems and avoid conflict. By exploiting that tendency, they can bypass safeguards that would hold up against a traditional code-first attack. For developers, this means that securing the system requires thinking like an adversary who is probing not the software, but the language that defines its behavior.
The Red Teaming Process For GenAI
AI Red teaming your own app is the only reliable way to see how it fails under pressure. I treat it like an engineering discipline with repeatable steps, hard logs, and tight feedback loops. The goal is simple. Find the gaps before anyone else does, then close them fast.
Red teaming in Generative AI means stress-testing an AI system like a hacker or adversary would. Instead of just asking “normal” user questions, the red team tries to find weaknesses, loopholes, and harmful behaviors in the AI. Here’s what my process looks like:
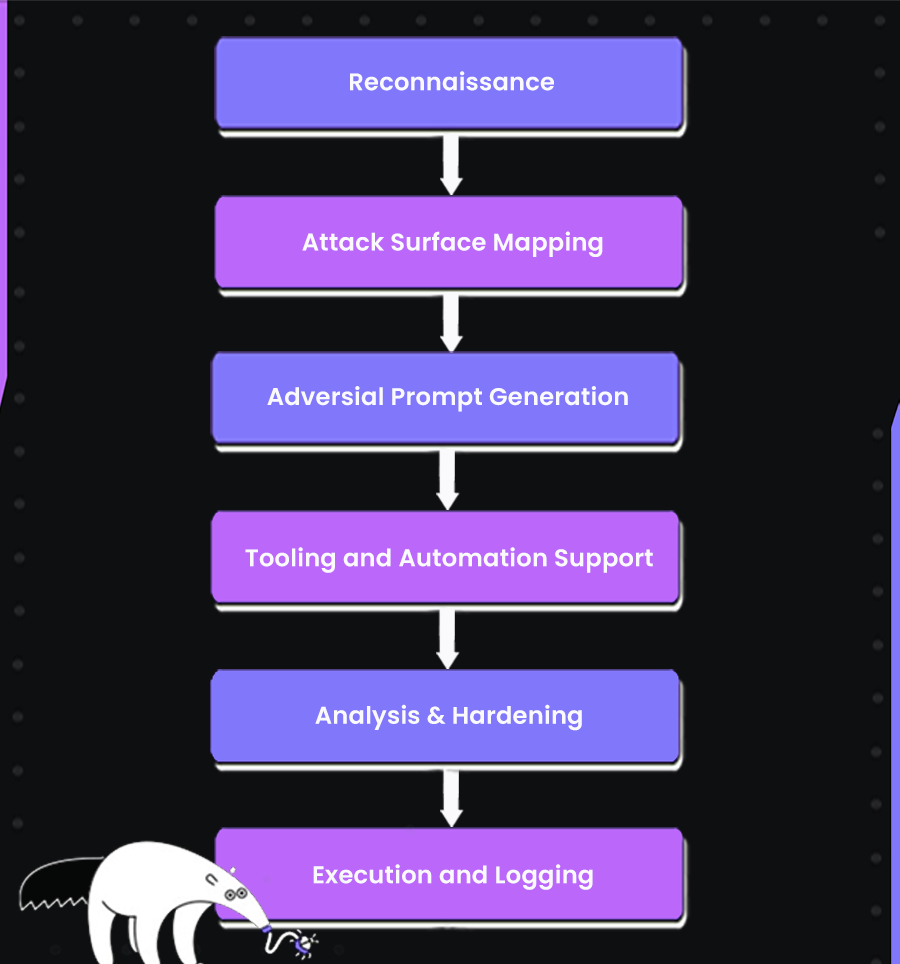
Let’s understand the image one by one:
Reconnaissance: Building the Map
All the inputs, outputs, and integrations that can affect the behavior of the model, are taken as a full inventory to start the process. This includes user prompts, system prompts, retrieval sources, tool and plugin interfaces, callback endpoints, and hidden parameters such as temperature and top_p.
I also capture where context originates, including prompt templates, RAG indices, feature flags, and any secrets that could leak through logs or error messages. The output of reconnaissance is a detailed diagram of data and control flows with explicit trust boundaries.
Attack Surface Mapping: Prioritizing Risks
Once the system is mapped, the next step is identifying the riskiest flows. I examine chains where user input influences retrieval, which then triggers tool calls and can reach sensitive systems.
Flows combining long conversation history, tool use, and write access rank highest. Weak spots like permissive plugin scopes, vague system instructions, or retrieval corpora mixing public and private content are marked. Each identified flow is associated with a hypothesis of potential abuse.
Adversarial Prompt Generation: Scaling the Attack
With attack surfaces identified, adversarial prompts are generated to test vulnerabilities. This step combines human creativity with model-assisted fuzzing. I maintain a corpus of attack families including prompt injection, system override, role flip, few-shot contamination, tool path abuse, retrieval taint, and output laundering.
Each family produces dozens of variants using LLMs to mutate wording, swap roles, and escalate politely or aggressively. Human review ensures the set is realistic and high-value. This approach scales efficiently in continuous integration since the prompts are treated as data.
Execution and Logging: Running Like Experiments
Adversarial prompts are executed as controlled experiments. Seeds are fixed where possible, tests run at multiple temperatures, and all relevant data is captured. This includes raw user input, final prompts, system messages, retrieved chunks, tool call parameters, tool results, token counts, and model version.
Logs are stored to reproduce exact conditions when a bypass occurs, which is essential for issues that depend on context order or minor sampling differences.
Analysis and Hardening: Closing the Loop
The final step analyzes outcomes and implements fixes. Results are labeled as blocked, partial leak, or full leak, with severity based on data sensitivity and reachable actions.
Patches target precise weak links: system prompts are tightened, tool scopes narrowed, deterministic checks added for side effects, and RAG sources sanitized with allowlists. Post-response validation ensures sensitive patterns never leave the system. Every fix is accompanied by updated tests to prevent regression.
Tooling and Automation Support
AI red teaming tools are beginning to formalize this process. Frameworks such as GARRET, AttaQ, and LLMGuard provide structured ways to probe prompts using curated attack libraries, run fuzzing-style mutations, and automatically score outcomes, enhancing repeatability and scalability.
Make breaking your system an inside job. Treat red teaming like any other high-stakes test suite and wire it into the pipeline. When the attack corpus grows and logs are reliable, you stop guessing and start shipping with confidence.
Defensive Strategies for Secure LLMs
One of the first lines of defense is to design prompts with clear structure and minimal ambiguity. Instead of leaving prompts open-ended, teams can enforce predictable formats and explicitly restrict instructions that could be abused. Structured templates reduce the chances of attackers injecting malicious instructions into loosely defined prompts.
Guardrails for Input and Output Filtering
Every input from users and every output from the model should be treated as untrusted. Input filters help catch obvious injection attempts before they reach the model, while output filters can flag or block unsafe responses before they are exposed to users. Guardrails provide a checkpoint that stops harmful instructions or unintended disclosures from slipping through.
Role Isolation to Prevent Identity Switching
Attackers often try to convince a model to switch roles or act outside its intended scope. By enforcing strict role isolation, developers can ensure that the assistant does not suddenly behave like an admin, a system operator, or another persona with higher privileges. Clear boundaries between roles help reduce privilege escalation through language manipulation.
RAG Sanitization to Validate Retrieved Documents
In RAG security, models often pull in external documents to ground their answers. If these documents are not sanitized, they can carry malicious instructions or misleading content that the model will trust blindly. Validating and cleaning retrieved data before passing it into the prompt ensures that the model only works with safe and relevant context.
Shift-Left Security for Prompts and Configurations
Prompts, system instructions, and configuration files are now part of the application’s attack surface. Treating them like code means applying version control, peer reviews, and automated CI/CD checks. By shifting security left into the development process, teams can identify weaknesses early and avoid releasing exploitable configurations into production.
How To Measure Progress in GenAI Security?
Improving GenAI security in LLM-powered applications requires tracking measurable outcomes rather than relying only on theoretical defenses. Clear metrics help teams understand where safeguards hold up, where they fail, and how quickly they can respond.
The table below outlines key metrics that provide visibility into the security posture of your system.
| Metric | Brief Description |
| Rate of Safety Control Bypasses | Tracks how often adversarial prompts slip past defenses, showing where protections are weak. |
| Time to Patch Vulnerabilities | Measures the speed at which discovered flaws are fixed, reflecting readiness and agility. |
| Unique Attack Patterns Identified | Builds a knowledge base by logging new exploit methods, reducing repeat blind spots. |
| User-Reported Incidents | Captures issues noticed in real usage, adding a human feedback loop to testing. |
| Downward Trend in Bypasses | Gauges overall improvement by ensuring bypasses decrease and remediation cycles get faster. |
How Qodo Helps in Securing LLM Apps Against Prompt Injection and Jailbreak Attacks
When I think about securing LLM applications, I don’t just look at theory or generic best practices. I look at how these defenses can be applied in real engineering workflows. That’s where Qodo comes in.
Qodo is an agentic code quality platform that integrates directly into developer environments, code reviews, and CI/CD pipelines. It is built with a focus on enterprise-grade LLM security, which means it goes beyond autocomplete or simple testing. What makes Qodo relevant here is that it provides purpose-built features for prompt injection testing, checks validation, and RAG security, the exact areas that are most vulnerable in LLM apps.
Instead of treating LLM security as an afterthought, Qodo allows me to shift these defenses left into development and testing, while also monitoring attacks in production. That’s why I’m using it as a practical example for how teams can implement the defenses I outlined earlier.
Code Quality at the Core
Qodo anchors every feature around code quality. When an adversary tries to inject malicious prompts into a system, the risk often comes from weak or inconsistent handling of inputs. Qodo’s review agents enforce structured prompts, sanitize inputs, and catch cases where a developer might have introduced insecure “shortcuts.” If a developer leaves a debug flag in production code, Qodo’s review will flag it before it can become a gateway for jailbreak attempts.
Deep Codebase Intelligence
Qodo agents are not generic, they operate with knowledge of the specific organization’s codebase, history, and standards. This context allows them to identify risks in places a shallow review would miss, like internal API calls or shared libraries where an injection could spread across repos. When an LLM integration pulls context from multiple repos, Qodo uses org-wide knowledge to spot risky data exposure across boundaries.
Built for Complex, Enterprise Codebases
Real systems are messy, with sprawling repos and evolving frameworks. Security issues like prompt injections don’t just sit in one neat file, they propagate across integrations and dependencies.
Qodo adapts to these realities by reasoning over multi-repo setups and internal standards, helping teams harden even the most complex deployments.
In an enterprise setup with both Python services and React frontends calling the same model API, Qodo can track how a single unvalidated input could cascade into different surfaces of risk.
Conclusion
The strongest defense against prompt injection and jailbreak attacks is built on the principle that the most secure AI systems are the ones you have already broken yourself. By making AI red teaming an internal discipline rather than waiting for external attackers to find weaknesses, teams can stay one step ahead of threats.
Red teaming is not a one-time exercise but an ongoing, creative practice. Just as attackers continuously probe for weaknesses, defenders must continuously test, refine, and harden their systems against evolving adversarial techniques.
In the end, AI security in LLM applications is less about perfect checks and more about outpacing the creativity of both the model and the attacker. To stay secure, you must be willing to think beyond conventional defenses, anticipate where systems can be misled, and continuously challenge your own assumptions.
FAQs
How Does Qodo Help Secure LLM-powered Applications?
Qodo secures LLM applications by treating prompts, context, and tool use as part of the codebase. It provides structured reviews of system prompts, RAG pipelines, and agent configurations, checking them against best practices and organization-specific rules. Instead of relying only on runtime filters, Qodo enforces security early in the delivery process by embedding checks directly into version control and CI pipelines.
Can Qodo be used for Red Teaming GenAI Applications?
Yes. Qodo can run automated attack suites against prompts, RAG flows, and agent toolchains. These red team tests simulate adversarial inputs and log outcomes such as blocked, partial leak, or full leak. Teams can replay attacks on every change, track bypass rates, and patch vulnerabilities before they reach production. This makes red teaming a repeatable and scalable part of the development cycle.
Does Qodo Integrate with Existing Developer Tools and Pipelines?
Qodo integrates with GitHub, GitLab, and other Git-based workflows. Developers can trigger reviews, run attack tests, and enforce best practices directly within pull requests or CI pipelines. This ensures security is applied in the same place where code, prompts, and configurations are already being managed, without introducing a separate workflow.
How does Qodo Handle RAG Security?
Qodo inspects RAG pipelines to prevent sensitive or irrelevant sources from being exposed. It allows teams to configure allowlists for trusted content, enforce deterministic checks on retrieved context, and add validation layers that block disallowed patterns in responses. These safeguards reduce the risk of unintentional data leaks while keeping RAG pipelines reliable for developers.
Who Should use Qodo, Developers or Security Teams?
Both. Developers use Qodo during daily coding and prompt design to catch risks early and apply best practices automatically. Security teams use it to define rules, run red team suites, and monitor bypass metrics across applications. By combining responsibilities, Qodo ensures security is part of the delivery loop instead of a gate at the end.


