How to Catch Code Duplication Across 100 Repositories
TL;DR
- Code duplication at scale is a system problem, not just copy-paste: Across large codebases, duplication appears as exact, near, and semantic duplication, often hidden in service integrations, validation logic, and shared utilities across repositories.
- AI-assisted development quietly increases duplication risk: AI-generated code often recreates existing internal logic without awareness of shared libraries or contracts, while CI/CD pipelines and repo-level reviews fail to detect overlap across repositories.
- Duplication must be caught during pull request review: Once duplicated logic is merged and reused, it becomes risky to refactor and turns into long-term technical and operational debt that spreads across services.
- Qodo detects duplication across repositories during code review: By analyzing changes with cross-repository context, Qodo surfaces existing implementations, highlights semantic duplication, and helps teams reuse or consolidate logic before duplication becomes a production risk.
Duplication in large codebases rarely begins as copy-paste. It starts when shared logic becomes too risky to change. Teams avoid refactoring critical functions and instead reimplement similar logic locally to move faster.
These small decisions accumulate. Multiple versions of the same behavior spread across repositories, each slightly different but all “working.” The problem surfaces during incidents, when teams realize a bug was fixed in one place but still exists elsewhere. More than 70% of security issues come from repeated or inconsistent implementations rather than entirely new vulnerabilities.
AI-assisted development has made this harder to control. I regularly review AI-generated changes where the logic is correct, CI is green, yet the same behavior already exists in another repository under a different name. Reviews and pipelines operate at the repo level, so this duplication rarely triggers any signal.
This is why duplication has to be caught during pull request review, before it spreads. Human reviewers cannot track overlap across hundreds of repositories. AI code review tools like Qodo help by surfacing existing implementations and semantic duplication at review time, when it is still cheap to fix and before it becomes systemic.
Where Duplication Shows Up in Large Codebases?
If you are trying to catch duplication across hundreds or thousands of repositories, the first mistake is looking for obvious copy-paste. In my experience, duplication almost never looks that clean. It hides in places where teams interact with each other’s systems and where speed matters more than reuse.
Service-to-service integration logic: This is the first place I look during reviews. Auth headers, retry loops, timeout handling, pagination, and error mapping are constantly reimplemented instead of reused from shared clients.
I have reviewed pull requests where multiple services each had their own “temporary” way of adding an Authorization header; all of them worked locally, but none behaved consistently in production. Because each implementation looks reasonable in isolation, this duplication rarely gets flagged.
All of them worked locally. None of them behaved the same in production. This kind of duplication rarely gets flagged because every implementation looks reasonable in isolation.
Validation and business rules: Input validation, permission checks, and domain rules frequently get duplicated across APIs, background jobs, and internal tools. I have seen the same “is the user allowed to do X” logic implemented across several services with slightly different behavior. When bugs are fixed, they are fixed once instead of everywhere, and incidents expose inconsistencies that teams assumed did not exist.
Configuration and infrastructure helpers: Duplication also creeps into configuration and infrastructure helpers. Feature flags, logging setup, and rate limiting are copied between repositories to move fast, but compliance or configuration changes then require synchronized updates that are easy to miss.
Semantic duplication across services: And lastly, the most costly duplication is semantic. Code looks different, but does the same thing. Traditional tools rarely catch this, and fixes must be repeated across services. AI-generated code speeds up the problem by recreating existing logic without awareness of internal libraries or patterns.
How to Catch Code Duplication Across Multiple Repos
When you move past a few hundred repositories, duplication is no longer something you “notice.” It is something you either control deliberately or lose entirely. I learned this the hard way after too many incidents where the fix already existed somewhere else, just not everywhere it needed to.
This is the approach I use today, and it is made to work when review volume is high, teams are distributed, and AI-generated code is part of the workflow.
Step 1: Classify duplication before you try to eliminate it
If you treat all duplication the same, you will either block too much or miss what actually matters. In my experience, I classify duplication during review into 3 categories:
- Exact duplication
- Near duplication
- Semantic duplication
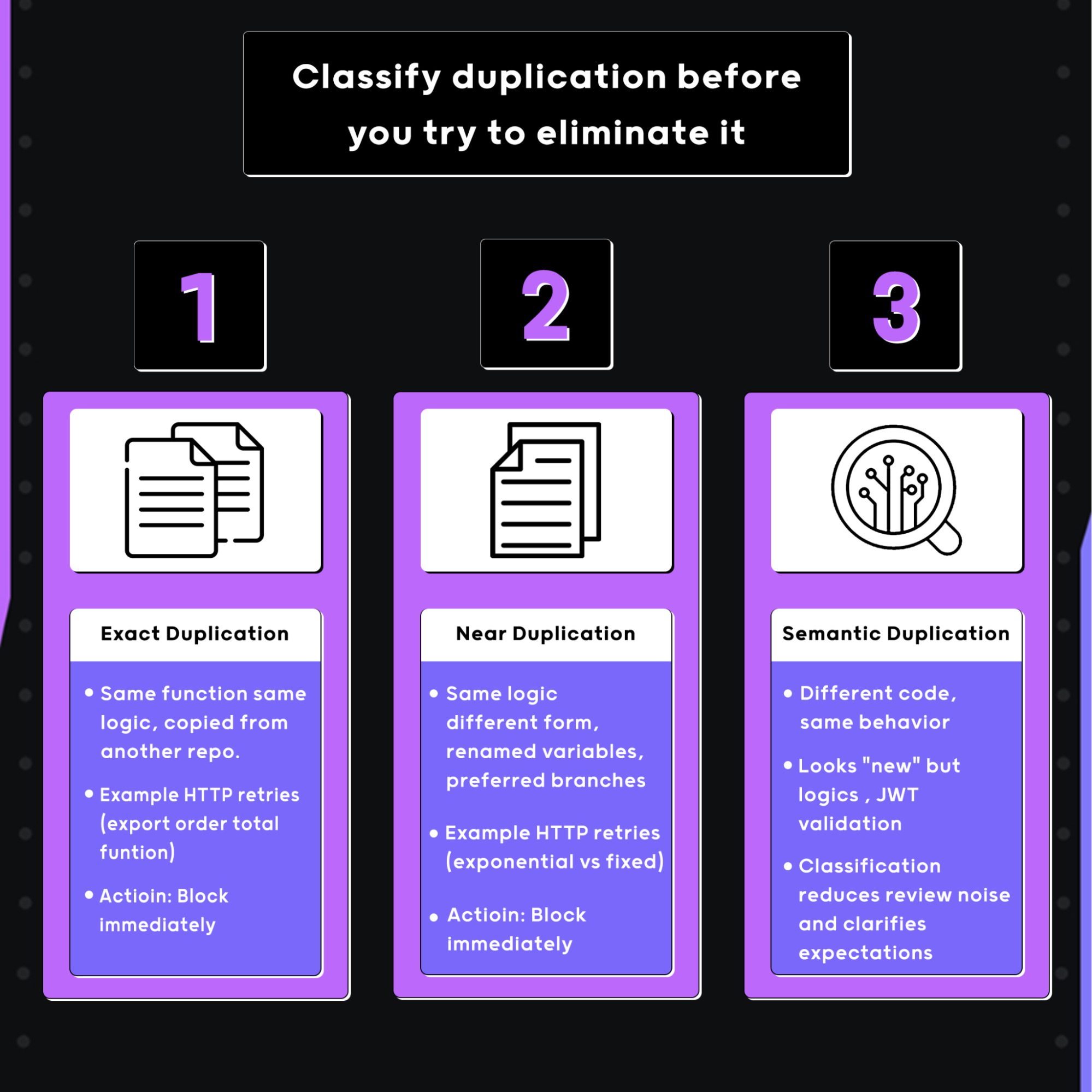
Exact duplication is simple. Like, it’s the same function, same logic, copied from another repo or shared utility. For example, a validateOrderTotal function reimplemented line-for-line instead of imported. I block these immediately. There is no upside to allowing them.
Near duplication is where teams usually get into trouble. Same logic with renamed variables, reordered branches, or a slightly different signature.
Example:
For example, one service retries HTTP calls with exponential backoff, another retries with fixed delays, both copied from the same original implementation. Early on, I allow one instance but call it out explicitly. Once the pattern repeats, I start blocking, because this is how behavior diverges silently.
Semantic duplication is the hardest and most dangerous. Different code, same behavior. Auth header handling, JWT validation, pagination helpers, currency formatting, error normalization.
These look “new” in a diff but implement behavior that already exists elsewhere. I flag these for review discussion, because they usually show a missing abstraction rather than a bad change. This classification alone reduces review noise and makes expectations clear.
Step 2: Anchor reviews around integration boundaries, not helpers
Most duplications do not live in utility folders. It lives where systems touch. When reviewing a PR, I scan service-to-service calls first. Anywhere a service calls another service is a duplication hotspot. Auth headers, retries, timeouts, circuit breaking, error mapping. I have seen the same payment call wrapped ten different ways across an organization.
Example:
For example, one service adds an Authorization header manually, another relies on a middleware, and a third hardcodes localhost during development. All “work,” all pass CI, and all break differently when enforcement changes.
If I see custom logic around an outbound call, I immediately ask: “Do we already have a client or wrapper for this service?” If the answer exists but is not used, that is duplication in progress.
Step 3: Treat validation logic as production-risk duplication
Validation is where duplication causes real incidents. I slow down any review that introduces input validation, permission checks, or domain rules. These are rarely isolated concerns. The same checks often exist in API layers, background workers, and event consumers.
I have seen bugs fixed in one service only to reappear weeks later because another service had a slightly different copy of the same validation logic. One version rejects an edge case, another allows it. Tests pass in both places. Production disagrees.
Similarly. Veracode reports that over 70% of security issues come from repeated or inconsistent implementations, not new vulnerabilities. That aligns with what I see in incident reviews: the problem is almost never “we didn’t know how to do this,” it is “we fixed it somewhere else already.”
Step 4: Make the source of truth explicit or duplication will win
Duplication spreads fastest when the canonical version is unclear. During review, I force myself to answer three questions quickly:
Where does this logic live today?
Which repo or package owns it?
Which version should downstream services depend on?
If I cannot answer that confidently, I do not blame the author. I treat it as a system failure. Teams copy logic because finding the right abstraction takes longer than rewriting it.
This is also where AI tools struggle. Qodo’s 2025 State of Code Quality report shows that 65% of developers say AI tools frequently miss relevant context during refactoring and review. That missing context is exactly why AI-generated changes recreate existing logic instead of reusing it.
Step 5: Catch duplication at review time or accept long-term drift
Once duplicated code is merged, it gets referenced. Once it is referenced, changing it becomes risky. That is the point where duplication hardens into long-term debt. Human reviewers cannot track overlap across hundreds of repositories. This is not a skill issue; it is a scale issue.
This is why review-time, cross-repository detection matters. When a tool surfaces existing implementations, shows where the same behavior already lives, and explains the impact, reviewers can make a real decision while the change is still easy to adjust.
Either reuse the existing abstraction, refactor toward a shared utility, or consciously accept the duplication with eyes open. That is the difference between governance that exists on paper and governance that actually holds when you are shipping hundreds of changes a week.



How Qodo Detects Duplication Across 1000 Repositories
Qodo approaches duplication as a system-level code quality problem, not a repository hygiene issue. In large enterprises, duplication rarely looks like copied files. It shows up as reimplemented logic, drifting contracts, and parallel abstractions created under delivery pressure. Qodo is built to solve code duplication where it matters: inside pull request review, before it hardens into long-term debt.
At this scale, which is common in large product organizations and well-documented in engineering at companies like Netflix, Uber, and Shopify, shared behavior rarely lives in a single place. Authentication helpers, retry logic, validation rules, and client wrappers are spread across internal libraries and service repositories owned by different teams.
Instead of analyzing a pull request in isolation, Qodo reasons about how the proposed change compares to existing logic across the organization. This includes internal packages, common utilities, and service contracts that may live in completely separate repositories.
As our CEO, Itamar Friedman, puts it,
“Code generation is quickly becoming table stakes, but code integrity is where real enterprise value and trust are won.”
That idea sits at the heart of how Qodo approaches duplication at scale. Instead of treating duplicated logic as something to clean up after an incident or audit, Qodo brings quality signals into everyday code review, where teams can make better decisions while changes are still easy to adjust.
Hands-on: How I Catch Code Duplication Across Hundreds of Repositories With Qodo
When I reviewed this pull request, I treated duplication as a system problem, not a local refactor issue.
I asked Qodo whether the validation logic being introduced already exists elsewhere in the organization and whether the PR adds logic that behaves the same as existing retry or error-handling code.
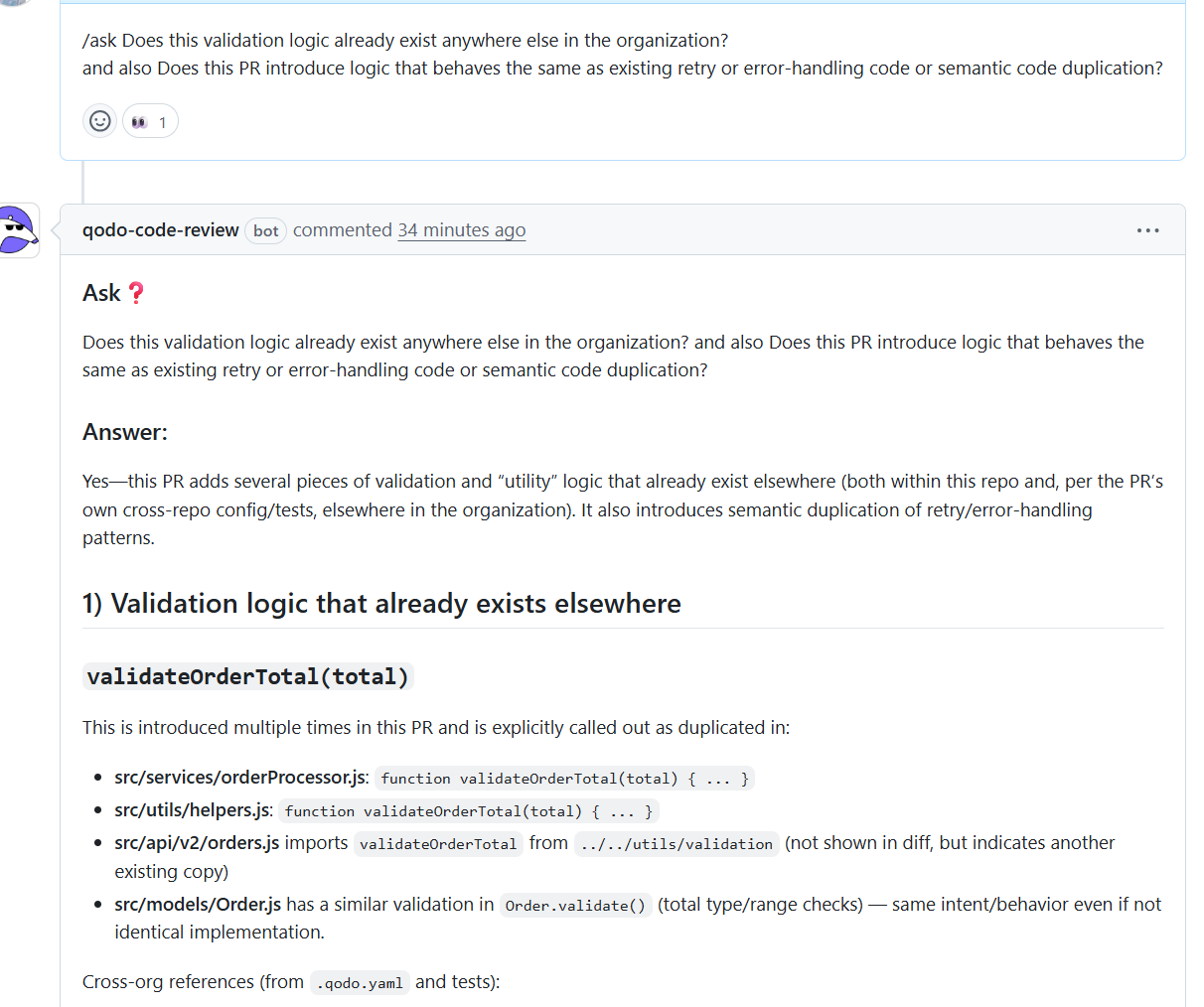
Cross-repository validation duplication surfaced immediately: Qodo confirmed that the PR was reintroducing validation logic that already exists in multiple places. The clearest example was validateOrderTotal(total), which Qodo located in src/services/orderProcessor.js, src/utils/helpers.js, and indirectly through imports in src/api/v2/orders.js. It also showed that src/models/Order.js performs similar validation inside Order.validate(). While the implementations differed slightly, the behavior and intent were the same.
Multiple copies of the same rule became visible in one view: This is the kind of duplication that usually slips through review because each implementation looks reasonable in isolation. Qodo surfaced all known locations together, making it clear that the PR was expanding existing duplication rather than introducing new behavior.
I asked another question: whether the logic introduced in this change already exists anywhere else across the organization.
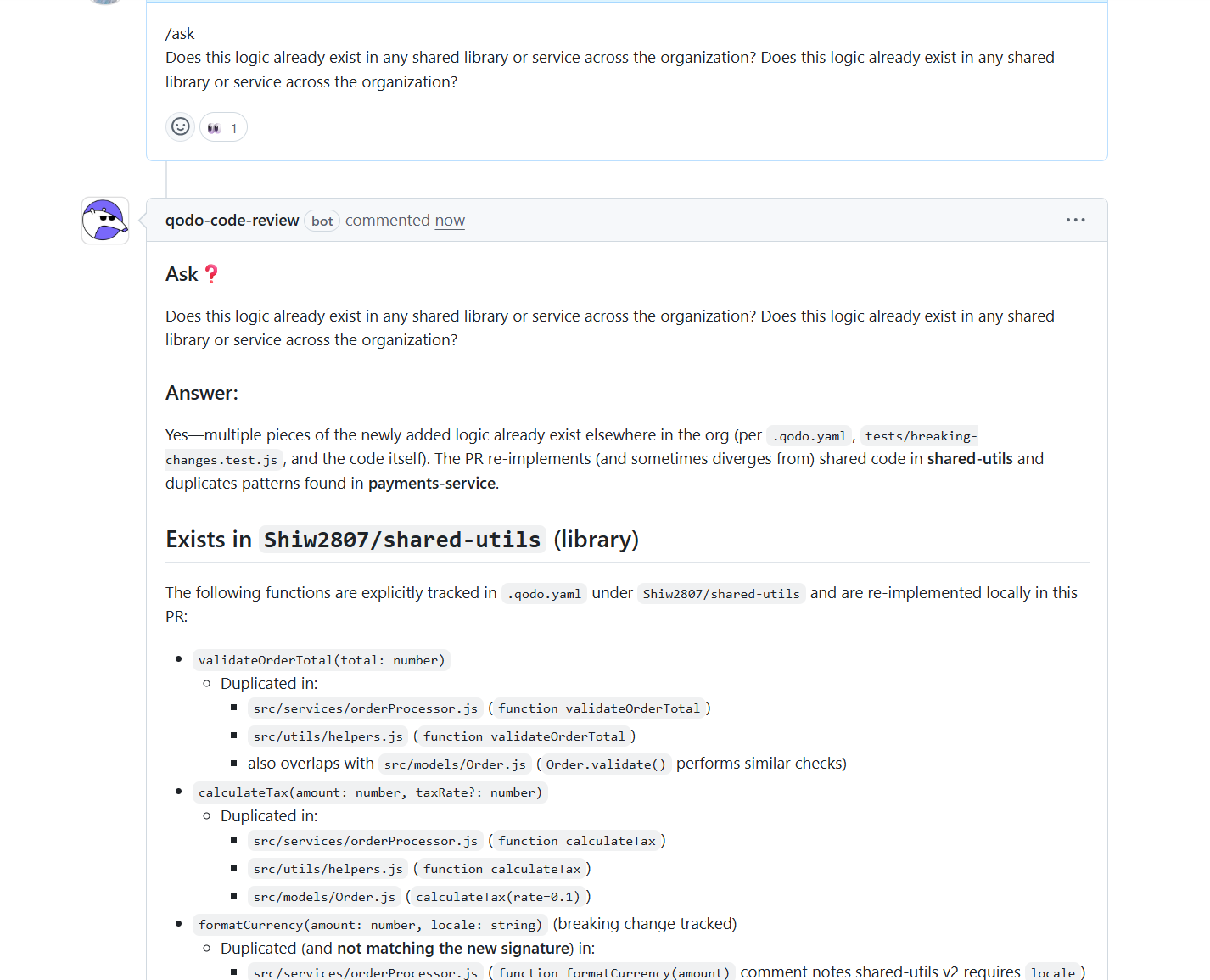
Shared-utils duplication confirmed across services: I asked whether the logic introduced in the change already existed elsewhere in the organization. Qodo showed that multiple functions being added in the PR already exist in shared-utils, and that the same logic was being reimplemented across services and helpers. It mapped each duplicated function to its original location and listed every file where it had been recreated.
Duplication patterns extended beyond the repository: I then asked whether duplication extended outside the repository. Qodo traced the same patterns into payments-service, even though it was not part of the PR. It highlighted duplicated JWT validation, rate limiting, currency formatting, and Slack notification logic already documented in .qodo.yaml and breaking-change tests.
This made it clear that the organization already knows about these overlaps, but the PR was adding another copy instead of consolidating the logic.
Internal duplication within the PR was detected: To go deeper, I asked Qodo to check duplication inside the PR itself. It identified repeated validation functions, near-duplicate helpers with different signatures, and duplicated priority and calculation logic split across models and services. These were not lint issues, but maintainability risks that accumulate over time.
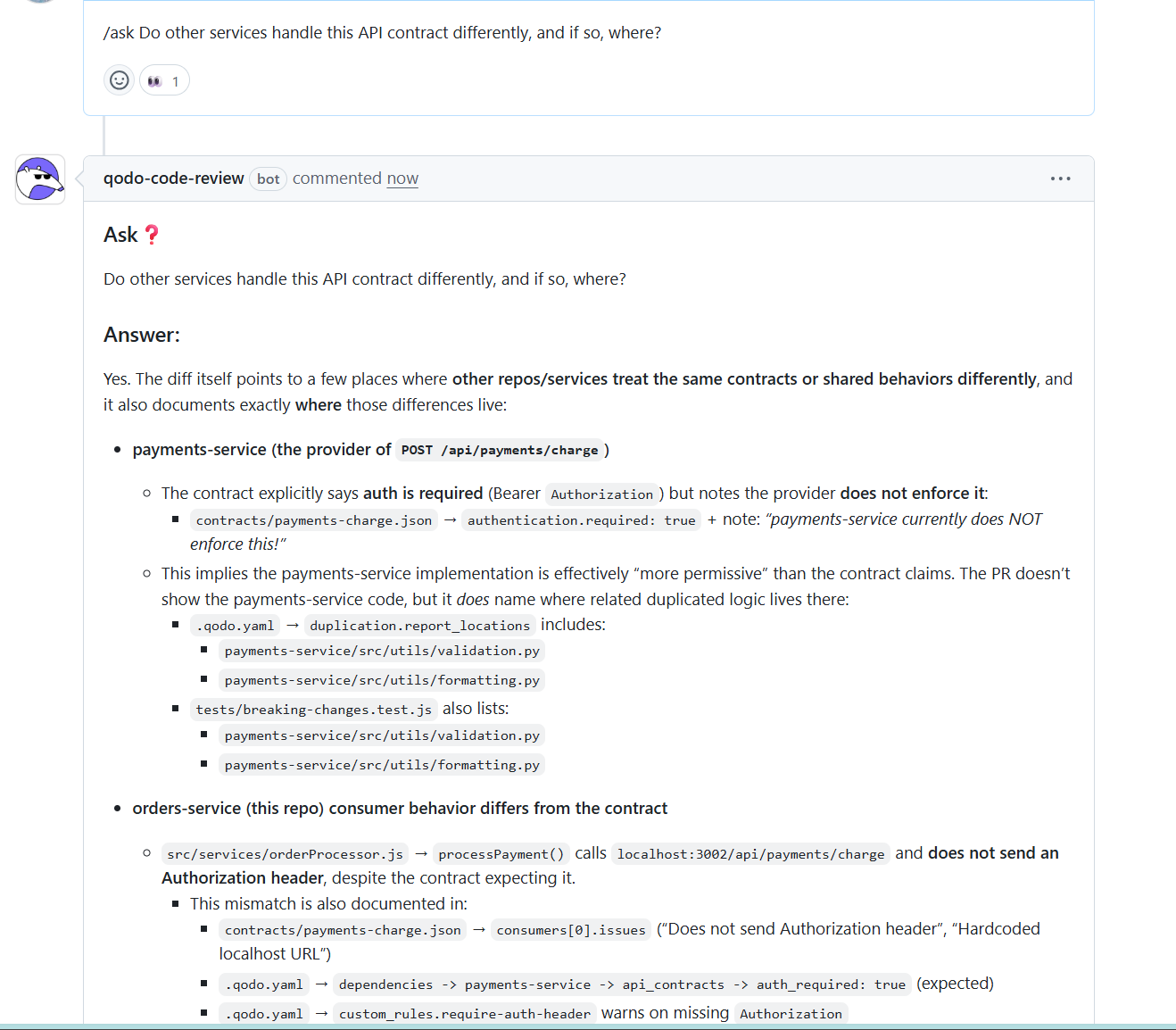
Contract mismatches across services were identified: I asked whether other services handled the same API contract differently. Qodo compared the consumer behavior in this repository with the documented contract and provider implementation.

It showed that the contract requires authorization, the consumer does not send it, and the provider currently does not enforce it. It also pointed to the exact contract files and configuration entries where this mismatch is recorded. This explains how incompatible assumptions can quietly coexist across services until enforcement changes trigger production failures.
AI-generated duplication signals were detected: Finally, I asked whether the code appeared AI-generated and whether it duplicated internal patterns.
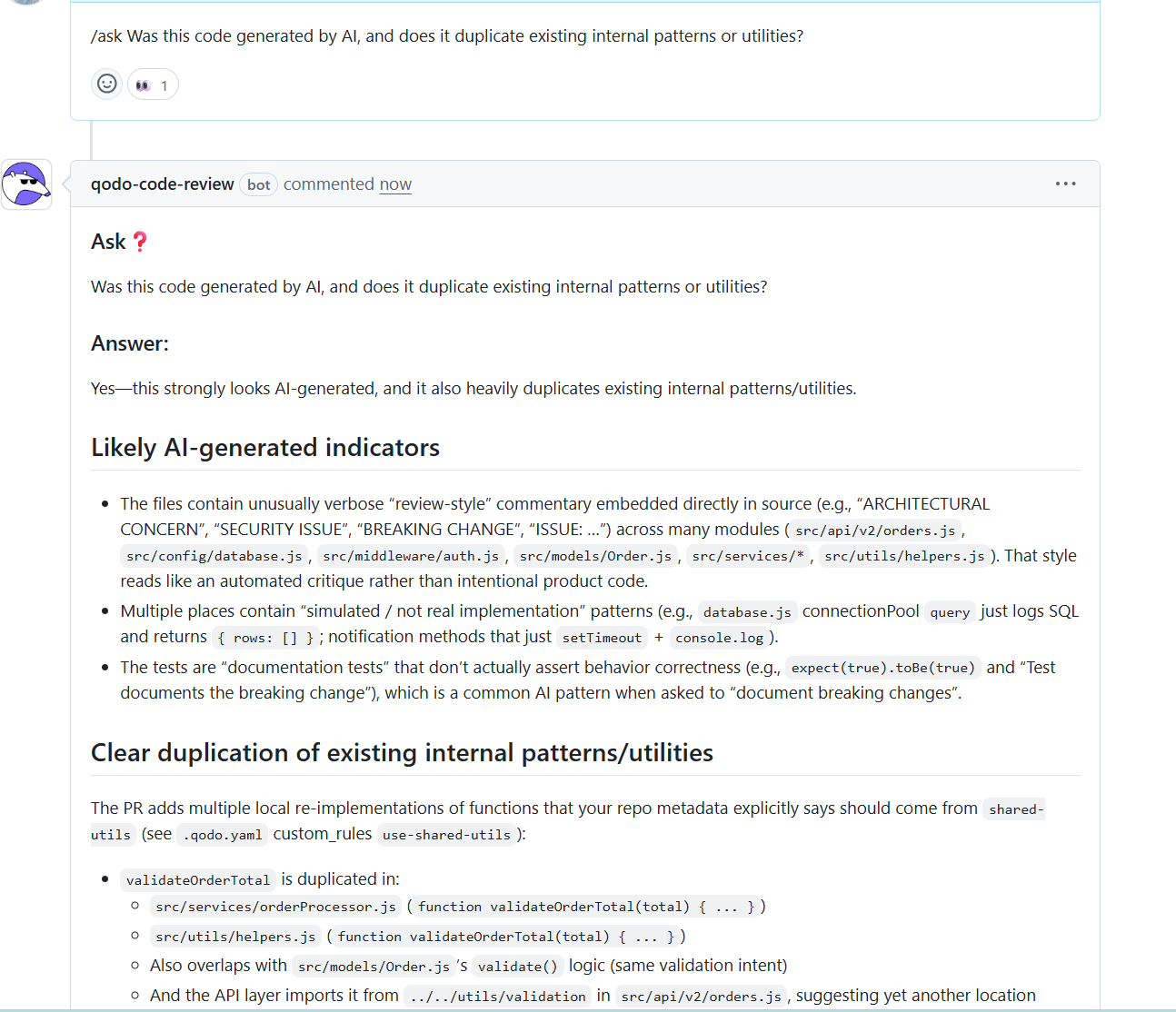
Qodo flagged verbose review-style comments in production code, simulated implementations that log instead of executing logic, and tests that document behavior instead of asserting it. It tied these signals directly to duplicated utilities already present elsewhere in the organization.
System-level duplication risk became actionable during review: Taken together, this review shows why Qodo works at enterprise scale. It does not just say duplication exists; it shows where the source of truth lives, how duplication has already spread across repositories, and why merging the PR increases long-term risk.
All of this happens inside the pull request with concrete references to files, contracts, and configuration, making the review actionable, auditable, and scalable.
Controlling Duplication Before It Becomes Systemic
As organizations grow, duplicated code starts to spread across repositories as teams build on what already exists. The challenge shifts from messy code to losing visibility into how systems behave and why. With time, small copies grow into many slightly different versions of the same behavior, making fixes harder and confusion easier to spread.
Catching duplication early changes that. When teams can see repeated logic as it’s being introduced, they can decide whether to reuse it, consolidate it, or allow it intentionally. Qodo helps teams do this during everyday development, so duplication is managed when it first appears instead of being cleaned up later through incidents or audits. The result is software that stays understandable, consistent, and easier to maintain as teams and systems grow.
FAQs
How do we distinguish “bad duplication” from intentional duplication?
Not all duplication is a problem. Duplication is usually acceptable when it is intentional and documented, such as isolating logic for latency reasons, regulatory boundaries, or blast-radius control. The risk starts when duplication is accidental and untracked. Teams should record why duplication exists and where the source of truth lives so future changes do not silently drift.
Can duplication detection work across different programming languages?
Yes, but only at the semantic level. Language-specific clone detection fails when the same behavior is implemented in Python, Go, or Java using different constructs. Tools that reason about behavior instead of syntax can identify equivalent logic across languages, such as retry strategies, auth handling, or validation flows.
How do we avoidAI-generated code from reintroducing old patterns?
AI tools generate code without awareness of deprecated utilities or internal standards. Avoiding this requires review-time checks that compare new changes against existing internal libraries and known patterns. When duplication is surfaced during PR review, teams can redirect AI-generated code toward the approved abstraction instead of merging another copy.
What is the difference between clone detection and semantic duplication?
Clone detection looks for identical or near-identical code structures. Semantic duplication looks for code that behaves the same even when written differently. The most expensive duplication in large systems is semantic, because it survives refactors, renaming, and language changes, and is rarely caught by traditional scanners.
Should duplication detection block merges by default?
Not always. Exact duplication is usually safe to block immediately. Near and semantic duplication often requires context and discussion. Many teams start with advisory findings, then move to enforcement once shared abstractions and reuse patterns are clearly established.