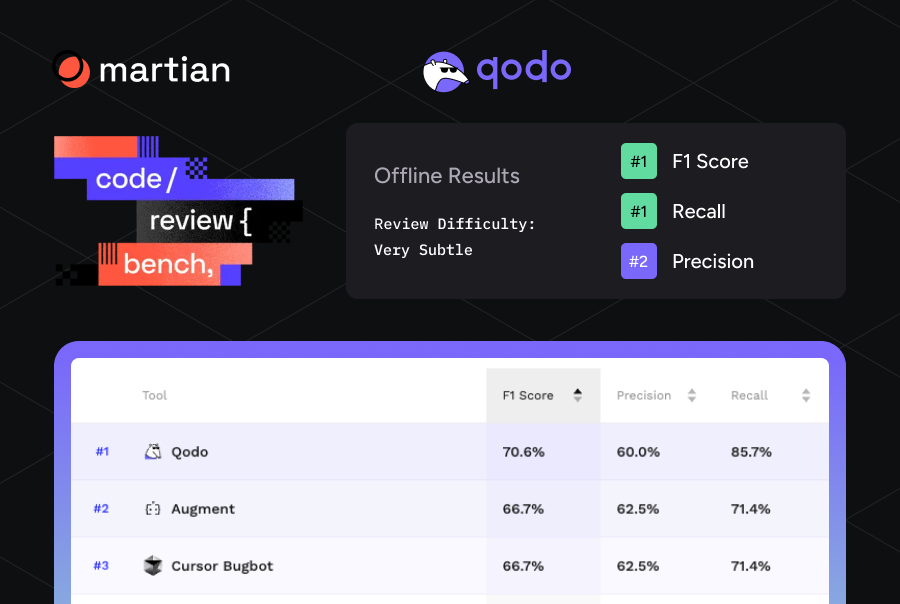
RAG as a Service: What It Means and Why It Matters for Engineering Team
TL;DR
- RAG as a Service simplifies building and maintaining RAG pipelines by managing embedding, retrieval, re-ranking, and generation in a unified workflow. This lets teams focus on solving real problems instead of managing infrastructure.
- These tools offer built-in observability, versioning, and validation tools, which help maintain consistency and detect context drift with minimal manual effort.
- RAG as a service platform eliminates common production bottlenecks like prompt bloating and retrieval latency, while providing stable APIs for integration.
- For lean teams or strict SLAs, managed RAG tools speed up delivery and lower maintenance by abstracting complex tasks like chunking and indexing.
- Choose a RAG tool based on your team’s technical skill level (no-code to code-first), the modularity you need, integration support with databases and LLMs, and your goals.
- Tools like Qodo Cover and Qodo Merge offer insight into answer generation, integrated monitoring, and metadata tracking to simplify updates and build trust in results.
As a Lead AI Engineer, I have seen my team heavily rely on LLM APIs that often fall short when accuracy and code context are important. Shifting to Retrieval-Augmented Generation (RAG) has been a great decision for me, as injecting relevant context into the prompt at runtime gave me much more control over the quality and accuracy of responses.
What truly drew me to RAG was more than just its performance. It was the need for precision. Building reliable pipelines around retrieval, indexing, and prompt construction is tough. I’ve spent countless hours testing different embedding models, experimenting with chunking strategies, and tuning query logic to get useful results.
At some point, I realized that creating a production-ready custom RAG from scratch was a drain on engineering time. Setting up the vector store, managing retriever logic, tuning prompt templates, and ensuring stable LLM responses involved constant maintenance and debugging.
That’s when I started exploring managed RAG as a service tool. These tools took care of the orchestration, monitoring, and infrastructure. This allowed me to plug in my domain-specific data and focus entirely on improving answer quality, setting up evaluation workflows, and refining the user experience.
Recently, I came across a Reddit post where someone teaching local business owners to automate workflows with LLMs shared a familiar struggle: getting RAG set up correctly.
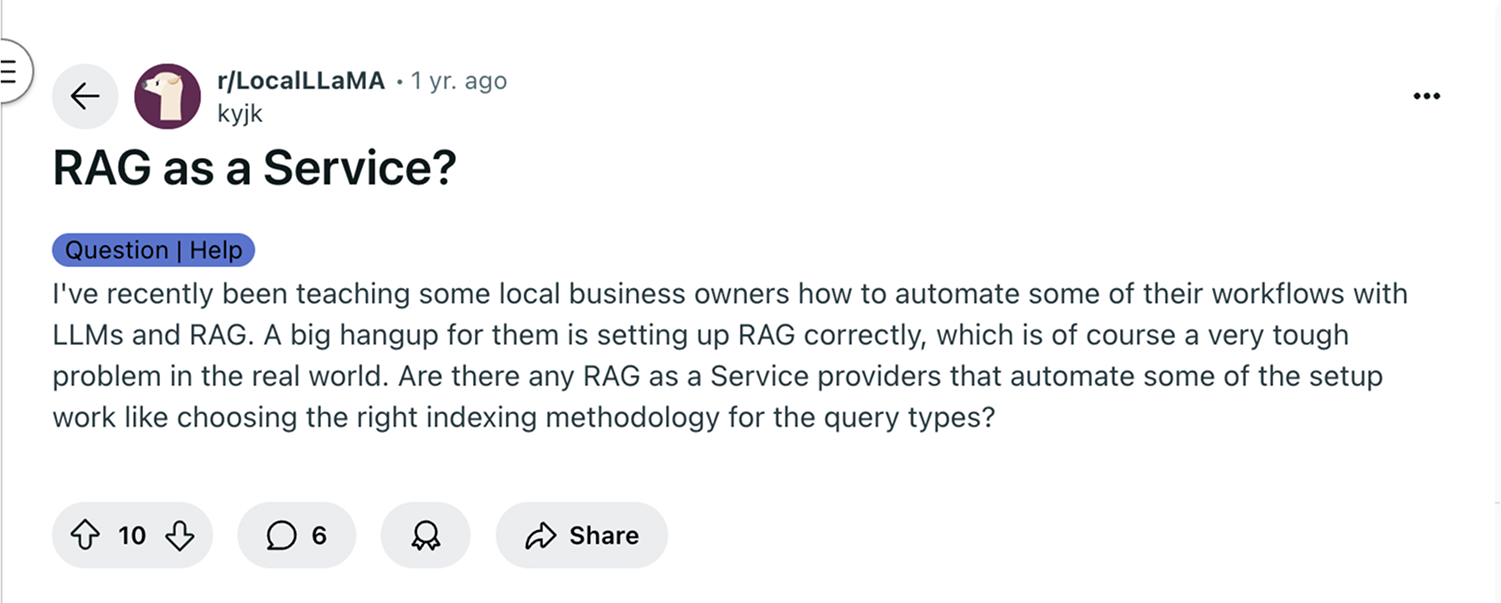
They were looking for providers who could handle indexing decisions based on query types. That post summed up what I’ve experienced firsthand. RAG works, but setting it up properly takes a lot of effort. I’d rather use specialized tools than build everything from scratch every time, like setting up document pipelines, generating embeddings, or configuring the retriever. So, in this blog, we are going to discuss RAG as a service, also known as RAGaaS, and how it can be useful for engineering teams like mine.
Understanding RAG
RAG model, or Retrieval Augmented Generation, is a system architecture that combines a large language model (LLM) with an external information retrieval component to generate more accurate, grounded, and context-aware responses.
Instead of asking an LLM to answer a question purely from memory (its training data), RAG retrieves relevant information from a trusted source, like your internal knowledge base, product manuals, or databases. Then it feeds that information into the prompt so the LLM can generate a more accurate and contextual response.
Evolution of RAG
When I first started working with RAG implementation, they were relatively simple, usually built around a single LLM that handled everything. These setups were easy to control but couldn’t keep up with demands for fresh, context-specific responses.
The turning point came with vector databases, like Pinecone and Qdrant. These databases allowed me to extend the model’s reach using external knowledge sources, adding contextual relevance to answers. But this shift also meant that I now had to manage not just the LLM but also vector search infrastructure and pipelines to keep the data fresh and accurate. That brought a whole new layer of operational overhead.
Things became even more complex once we added structured sources, like relational databases and knowledge graphs, into the pipeline. This was powerful; now the system could reason across both structured and unstructured content, but it also meant juggling different APIs, query syntaxes, and data formats. Each new data source came with its own learning curve and integration effort.
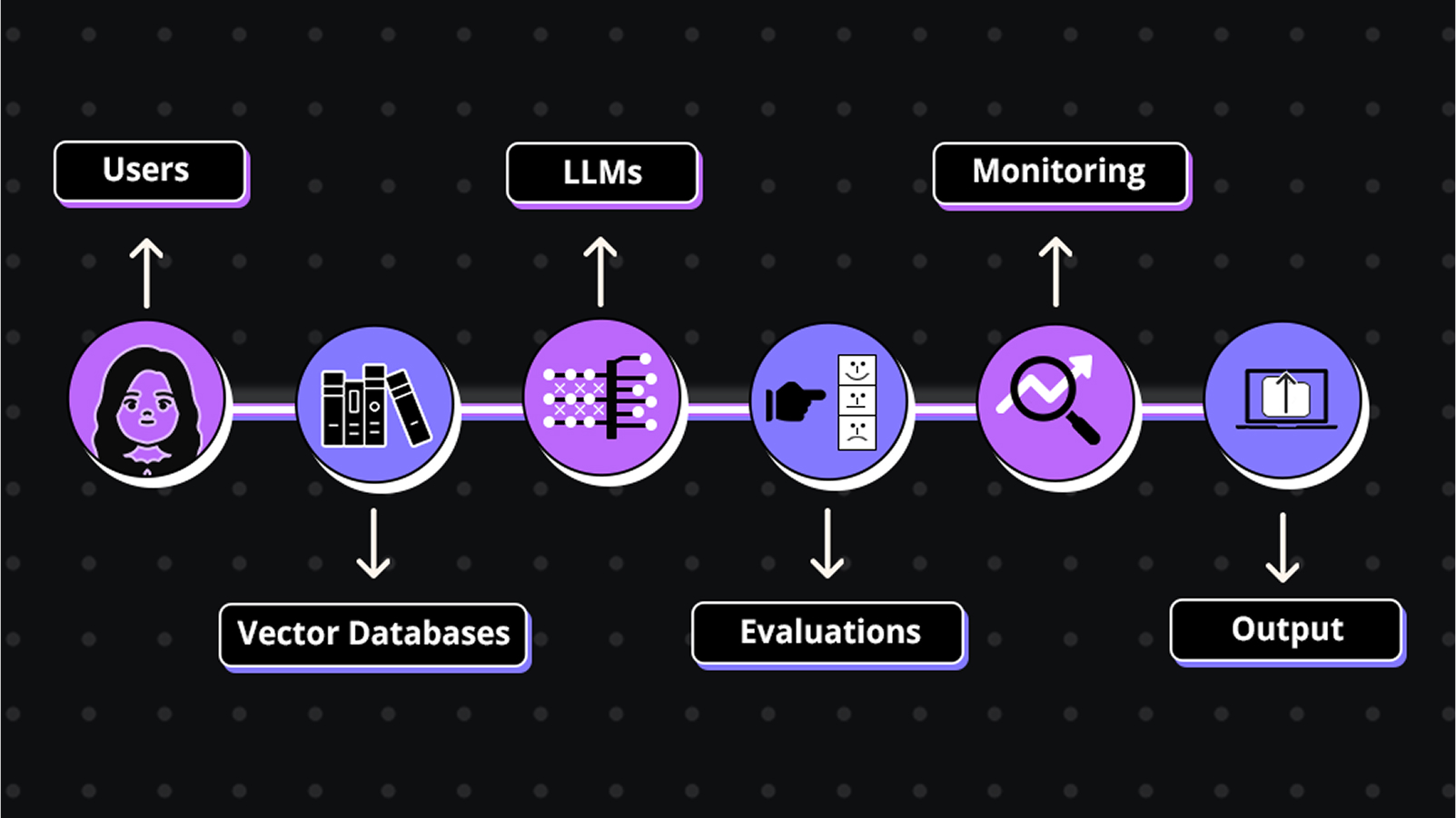
In production today, a RAG setup is rarely a single system. It’s a mesh of components, each potentially running on different platforms or maintained by different teams. Combining these parts means dealing with dozens of APIs and handling edge cases across systems.
Every component adds complexity, more time to develop, higher risk of failure, and significantly more maintenance work. So, modern RAG pipelines demand more than clever prompts; they need deliberate engineering and a well-thought-out system architecture.
What is RAG as a Service (RAGaaS)?
Building a RAG system from the ground up takes a lot of time, effort, and technical expertise. Most teams can’t afford to spend months integrating different tools and fine-tuning the setup, especially while managing their core product and business priorities.
That’s why we’re seeing a shift toward something new: RAG as a Service (RAGaaS). These platforms provide fully managed RAG solutions, handling the complexity behind the scenes. Instead of dealing with infrastructure, teams can focus on building features and delivering real user value.
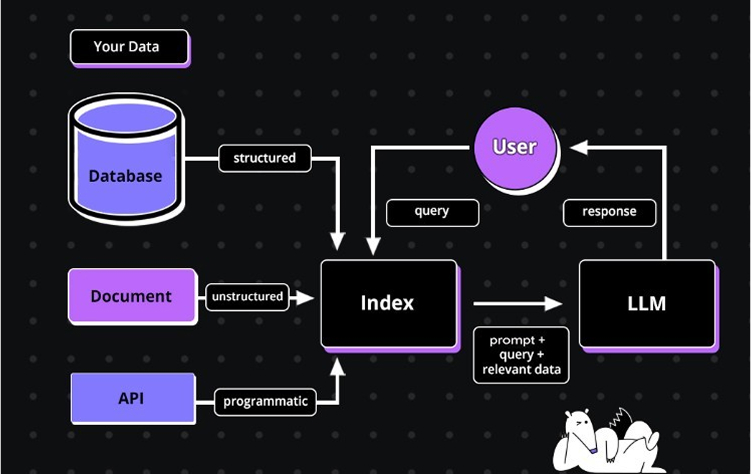
RAG as a Service handles how content is chunked, which embedding model to use, how results are retrieved and ranked, and how the final prompt is constructed for the LLM application. Below is a diagram that explains how RAGs work as a service for users:
Why Engineering Teams Should Care?
Engineering teams face growing pressure to deliver intelligent, context-aware applications that can handle complex queries. RAG as a Service directly addresses these challenges by simplifying the integration of RAG into products. Here are the key reasons engineering teams should pay attention to RAGaaS and consider adopting it for their projects:
Faster Time-to-Market
RAG as a Service removes the need to build complex retrieval and generation pipelines from scratch. Engineering teams can deploy intelligent, context-aware applications much quicker, reducing development cycles significantly.
Reduced Infrastructure Management
These platforms handle the heavy lifting of scaling, caching, and fault tolerance. Engineers no longer need to manage vector databases, indexing systems, or orchestration layers, freeing them to focus on product improvements.
Lower MLOps Overhead
Maintaining embeddings, updating indexes, and monitoring model performance can be resource-intensive. RAGaaS providers offer automated maintenance and monitoring tools, reducing the need for specialized ML operations teams.
Better Focus on Core Engineering Tasks
With RAG pipelines managed by the service, engineers can invest their time refining prompts, improving user experience, and building unique features instead of backend maintenance.
Engineering Implications: What RAG as a Service Changes
Moving from custom RAG pipelines to a managed RAG as a Service platform shifts how we engineer, test, and operate these systems. The abstraction saves time, but it also demands a more disciplined approach to evaluation, traceability, and lifecycle management.
Let’s understand now what Rag as a Service changes for engineering teams and why it matters:
Query Observability Is Not Optional
When I first put our custom RAG pipeline into production, I quickly realized that getting the “right” answer once wasn’t enough. The real challenge was ensuring the answer stayed consistent, especially when we updated embeddings, tweaked retrieval logic, or introduced new documents. I needed a way to track what changed, when, and why.
That’s when I realized the importance of wrapping each query with metadata, allowing me to track what changed, when, and why. Managed RAG tools offer better support, but using the right observability layer is key.
Expert Tip: Use Qodo Cover to Make Queries Observable and Traceable
Qodo Cover helps me to track shifts in generated answers and flags meaningful divergence.
- Tracks which queries changed and why, especially after retriever or embedding updates
- Highlights confidence drops or unexpected changes in CI pipelines
- Automatically logs context shifts for each query, making root-cause analysis easier
Visibility into Data-Answer Dependencies
Understanding which documents contributed to a generated answer isn’t just a debugging convenience; it’s essential for enforcing compliance, maintaining data lineage, and ensuring answer trustworthiness. With hosted RAG platforms, this metadata is often exposed, but without structured tooling, it’s hard to use effectively.
Expert Tip: Qodo Merge for PR-Level Retrieval Explainability
Qodo Merge helps me attach structured metadata to each retrieval. It enforces better discipline during updates.
- Embedding diffs and document ID changes are logged in PRs
- I can validate index update paths through CI hooks
- It ensures reviewers know which content changes might affect downstream answers
This has saved me hours when trying to trace flaky retrieval behavior or validate risky data pushes.
Example
For one update involving our policy documents, Qodo Merge logged exactly which document IDs were added, modified, or removed. This metadata was automatically attached to the PR, along with diffs of embedding changes.
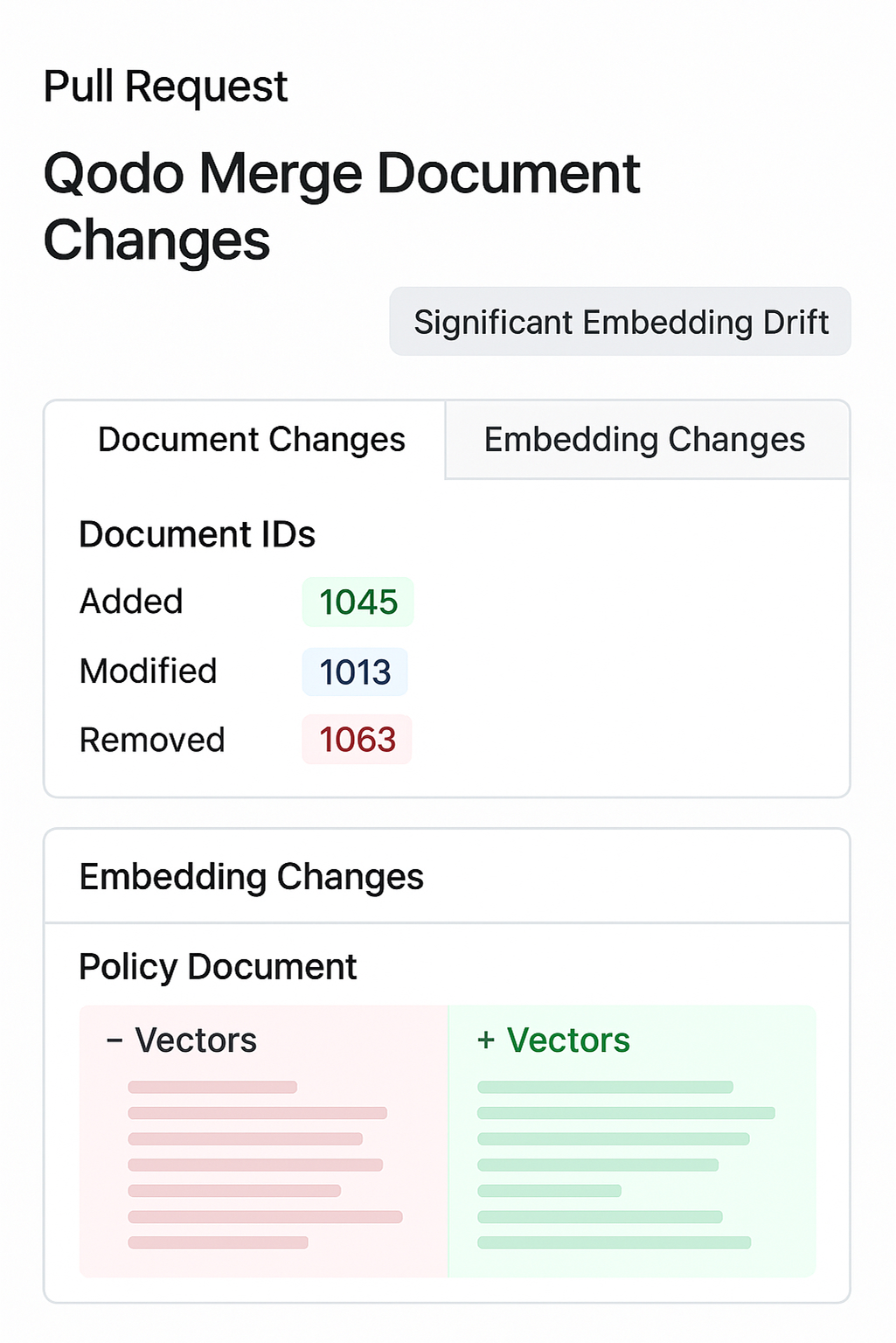
During the code review, the team could see which content chunks might affect downstream retrieval results. One PR flagged a significant embedding drift on a critical document, allowing us to pause deployment and investigate before releasing.
This visibility also helped me trace a flaky retrieval issue to a recent document update, reducing debugging time from hours to minutes.
CI/CD Discipline for RAG Updates
Updating a retriever, modifying ranking logic, or even adjusting prompt templates can trigger subtle yet impactful changes in RAG output. These changes often bypass traditional testing layers, so RAG components must be treated like software elements. That includes applying proven engineering practices, version control, semantic testing, baseline comparisons, and automated assertions, to validate behavior after every update.
This is where RAGaaS platforms offer a significant advantage. Instead of building all the tooling from scratch, RAGaaS solutions integrate observability and testing hooks directly into the workflow. They expose semantic differences and surface relevance regressions, allowing engineers to lock prompt behavior across retriever changes.
Expert Tip: Use Qodo Gen for Semantic Snapshot Testing
With Qodo Gen, I’ve added semantic regression tests to my CI pipeline. Instead of checking that a build completes, I can assert that the RAG system behaves as expected.
- Locked prompt suites run across old and new retrievers
- Relevance scoring highlights unintended shifts
- Output diffs are auto-commented on PRs for reviewer visibility
This gives my team traceability and confidence in every deploy, even as the underlying models evolve.
When to Use RAG as a Service (vs. Build It Yourself)
Deciding between adopting a RAG as a Service (RAGaaS) platform and building a custom Retrieval-Augmented Generation pipeline in-house depends on several factors related to your team’s resources, project requirements, and long-term goals. Here are scenarios that can help guide this decision:
Launching Internal Knowledge Assistants Quickly
If your team needs to deploy an internal tool that helps developers search across documentation, product specs, or ticket histories, RAGaaS platforms can deliver results fast. They handle indexing and retrieval seamlessly, letting engineers focus on integrating the assistant into existing workflows without spending months building infrastructure.
Prototyping AI Features for Enterprise Applications
For engineering teams working on enterprise banking software that demands semantic search, contextual Q&A, or intelligent document summarization, RAGaaS lets them test ideas quickly. The ability to A/B test prompt strategies and retrieval logic through built-in tools accelerates experimentation without heavy engineering overhead.
Managing Multi-Source, Multi-Format Data
If your application must combine information from databases, PDFs, knowledge bases, and multimedia files, like images or audio transcripts, as in the healthcare sector, RAGaaS platforms with multi-modal retrieval capabilities simplify this complexity. Handling multi-format embeddings and searches from scratch can be prohibitively difficult.
Handling Spikes in Query Volume Without Downtime
When your product sees unpredictable or seasonal spikes in user queries, such as a retail platform during holiday sales or a financial app at market open, RAGaaS’s autoscaling infrastructure ensures consistent performance. Therefore, you should choose RAG as a Service to avoid the challenge of manually provisioning and tuning backend resources.
When to Consider Building Your RAG Pipeline
RAGaaS tools are valuable assets that support engineering teams and streamline development. However, there are situations where relying on these tools may not be ideal, and building a custom RAG pipeline becomes a better choice. Let’s explore the scenarios when this approach makes more sense:
- You have deep in-house expertise and want full control over every pipeline component.
- Your use case requires highly customized retrieval logic or integration with proprietary systems that RAGaaS platforms don’t support.
- You want to avoid ongoing subscription costs and have the resources to maintain and scale infrastructure independently.
- You need to experiment with novel research ideas or cutting-edge retrieval and generation techniques not yet available in commercial services.
How to Choose a RAG Service Provider?
Selecting the right RAG as a service provider goes beyond checking if they support retrieval and generation. Based on what I’ve seen building and scaling these systems, here’s what I always validate before committing:
Support for hybrid retrieval with tunable weighting
In production use cases, pure vector search is rarely enough. The ability to combine vector similarity with keyword filters, metadata constraints, or BM25 scores is essential. I look for providers that allow hybrid retrieval strategies where I can explicitly adjust the weights.
For example, in compliance-heavy domains, I often dial up exact keyword matches and restrict semantic drift via re-rankers. If the provider treats retrieval like a black box, that’s a red flag.
Granularity of audit logs and tracebacks
RAG pipelines fail silently if you don’t have the right observability. I require fine-grained logs that include which documents were retrieved, their source versions, reranker scores, and final prompt composition.
More importantly, I expect the ability to trace any generated output back to its exact document lineage and embedding version. This is essential for debugging hallucinations, running post-mortems, and maintaining regulatory compliance.
CI/CD integration for output regression testing
When we update the retriever logic, change embedding models, or refresh the source corpus, outputs can shift. I don’t ship any RAG change unless it’s tested in CI. The best providers support snapshot testing via APIs or hooks that let me compare live generations against baselines. Some even offer semantic diffing tools to quantify how much an answer has changed, which is far more reliable than relying on static string comparisons.
Conclusion
Throughout this blog, I’ve shared my firsthand experience of the shift from traditional LLM workflows to Retrieval-Augmented Generation (RAG) and, more importantly, RAG as a Service (RAGaaS).
We walked through how RAGaaS can impact engineering teams and why they should start using these services in their development cycles. These services can help teams to ensure faster prototyping, reduced hallucinations, and better alignment with evolving enterprise knowledge.
Ultimately, RAG as a Service allows engineers to stop reinventing infrastructure and focus on delivering real value. It decouples complex system design from domain-specific problem solving, making building grounded, explainable, and scalable LLM-powered applications easier.
FAQs
What is the difference between RAG and LLM?
An LLM (Large Language Model) generates responses solely based on the data it was trained on, which may become outdated or limited. In contrast, a RAG (Retrieval-Augmented Generation) improves this by retrieving relevant data from external sources and feeding it into the LLM before response generation. This results in more accurate, grounded, and context-aware outputs.
What is the structure of RAG?
In AI, a typical RAG pipeline includes three core components:
- Retriever: Finds relevant documents from a knowledge base.
- Reader/Generator (LLM): Generates responses using the retrieved documents.
- Pipeline Controller: Manages the flow of inputs, retrieval, and generation.
This structure enables dynamic, grounded responses with real-time context.
Is RAG an AI agent?
No, RAG is not an AI agent. It is a method or architecture that enhances LLMs with retrieval capabilities. However, RAG can be integrated into an AI agent’s system, helping it deliver more reliable, knowledge-backed responses.