3 RAG Applications: From Code Review to Knowledge Discovery
TL;DR
- RAG improves developer workflows by retrieving precise, context-aware information from your codebase.
- Most engineering bottlenecks come from context retrieval, not coding. RAG solves this by injecting precise, real-time knowledge from internal tools like GitHub, Jira, and Slack directly into workflows.
- Code reviews become far smarter with RAG: it retrieves context from internal knowledge sources (like PRs, incident logs, RFCs) and feeds it to an LLM before generation. While classic RAG relies on semantic embeddings for retrieval, newer variants incorporate keyword search, agentic planning, and graph-augmented indexing.
- Evaluating a RAG stack isn’t just about retrieval; it must offer tight latency, granular access controls, API-first design, integration flexibility, and swappable LLMs to fit enterprise engineering’s needs.
- This blog discusses the 3 RAG applications, ranging from code review to knowledge discovery, namely Contextual Code Reviews, Unified Knowledge Search, and RAG-Driven Debugging.
- Qodo’s RAG stack integrates real-time data directly into engineering tools, reducing manual digging and boosting code confidence
As a lead AI engineer with years of experience in navigating large codebases, I’ve often found that most of the time spent in software engineering isn’t writing code, it’s retrieving the right context.
When reviewing a PR, troubleshooting an issue, or onboarding a new engineer, the challenge is finding the right knowledge. Instead of digging through outdated Confluence pages or Slack threads, RAG instantly pulls the exact, relevant information in context. That’s where I find Retrieval-Augmented Generation (RAG) to be the game changer.
RAG adds a dynamic retrieval layer that can use embeddings, keyword search, or hybrid strategies to pull in up-to-date data like code snippets, API docs, or incident reports before generating a response. Along with using pre-trained data, RAG leverages some sources like legacy codes, documentation, and PRs to provide more context-aware and accurate answers. This approach has reduced hallucinations, improved traceability, and boosted my trust in AI systems.
If you’re curious about what some real-world applications of RAG are, this blog will highlight three high-impact RAG applications that I’ve seen dramatically improve developer performance and clarity. If you’re working in a high-stakes, high-complexity environment, you’ll want to pay attention to this kind of tooling shift.
Choosing the Right RAG Stack: Evaluation Checklist
When I first started experimenting with RAG in production, I quickly realized that not all RAG stacks are equal. The core architecture might be similar: retrieve, then generate, but the details are different.
Especially in enterprise environments, such as those handling sensitive financial data, healthcare systems, or large-scale SaaS platforms, where latency, compliance, and integrations matter, choosing the right RAG setup can make or break your rollout.
Here’s the checklist I use when evaluating or designing a RAG stack while working on different SDLC cycles:
Retrieval Latency and Precision
One of the first things I benchmark is the retrieval engine’s responsiveness. If I wait more than a second or two for relevant context to show up, it becomes a bottleneck I can’t afford in tight dev cycles.
Precision matters more than surface noise or irrelevant results, and the downstream generation becomes useless. I’ve had the best results using hybrid retrieval, combining vector-based search (for semantic relevance), keyword filters, and in some cases, structured lookups or routing logic. This balance helps maintain both precision and recall without compromising latency.
Integration Flexibility (Jira, GitHub, Slack, Grafana)
In my experience, the best RAG systems are contextually rich because they’re wired into everything: PRs in GitHub, postmortems in Jira, alert threads in Slack, and telemetry in Grafana. If your RAG stack doesn’t support deep and flexible integration with your existing tooling, you’ll either duplicate data or lose critical signals. Bonus points for when it supports webhooks or event-driven triggers.
Data Privacy and Access Control
This is non-negotiable, especially if you’re dealing with regulated environments or sensitive internal IP. Your RAG system should ensure access controls are in place, allowing only the right people to access the right information based on their roles.
LLM Compatibility and Extensibility
Ideally, the stack should support open-source and hosted LLMs with pluggable backends. I’ve found this critical when experimenting with different LLM behaviors (e.g., using Claude for summarization and GPT-4 for reasoning). You want a clean abstraction between retrieval and generation to swap out models without reworking the entire stack. Fine-tuning hooks and function-calling support are also must-haves if you’re building custom workflows.
API-First Design
RAG stacks shouldn’t be locked into a UI. As a senior engineer, I expect full API access, whether I’m embedding RAG responses into a CLI tool, triggering it from a GitHub Action, or exposing it inside an internal dashboard. The best stacks I’ve used treat everything, including retrieval, ranking, generation, and logging, as composable APIs. That flexibility is what makes them useful beyond demos.
While most associate RAG with semantic search, the ecosystem is evolving rapidly. We’re now seeing agentic RAG patterns where retrieval steps are dynamic and multi-hop, graph-augmented techniques that connect relationships between entities, and keyword-based lookups that improve determinism. A future-proof RAG setup considers these variants, not just vector search.
RAG vs Fine-Tuning
Retrieval-Augmented Generation (RAG) and Fine-tuning are two strategies for optimizing large language models (LLMs) in enterprise settings. While both approaches aim to enhance the LLM’s relevance and performance, they achieve this differently.
RAG enhances the model by integrating it with an organization’s internal data sources, allowing it to retrieve up-to-date information to generate more contextually relevant responses.
On the other hand, fine-tuning involves retraining the model on a targeted dataset to make it more effective for specific tasks or domains. Both techniques ultimately aim to improve the model’s effectiveness, ensuring it delivers greater value for the enterprise.
In short, RAG enhances the model’s ability to access internal information for better context, whereas fine-tuning focuses on training the model with specific external data to refine its performance.
I have attached an image below for you to understand the similarities and differences between RAG and fine-tuning:
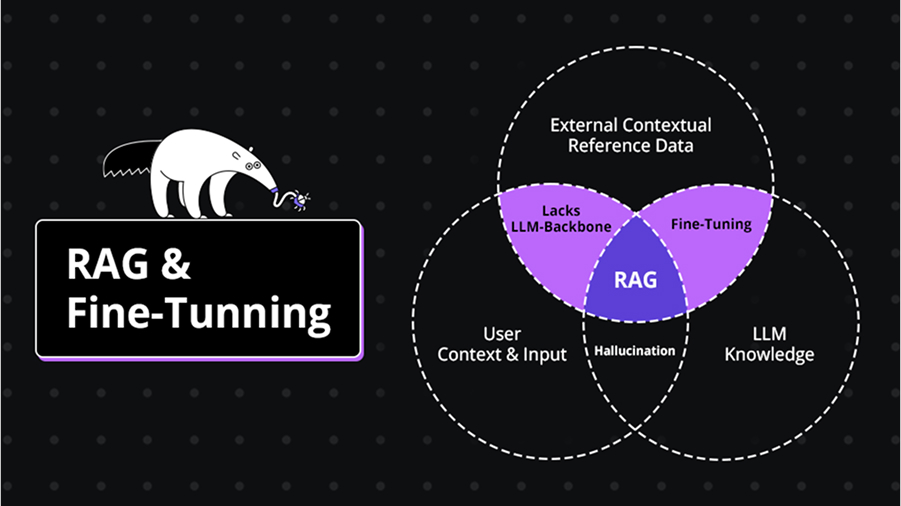
3 RAG Applications For Developers
3 RAG Applications For Developers
Now that I have discussed how to choose the right RAG stack and how it differs from fine-tuning, we are ready to explore its applications in various ways. But before doing that, let me briefly revisit what a RAG application actually is. A RAG application enhances language models by grounding their responses in external knowledge sources. This allows for more accurate, up-to-date, and context-aware outputs.
With that understanding in place, I’ll walk you through three impactful RAG use cases that I believe are especially valuable for developers.
Contextual Code Reviews
In most review workflows, feedback focuses on immediate correctness, style, naming, and maybe a glance at logic. However, without historical or architectural context, many deeper issues, such as repeated design flaws, dependency misuse, or past incident patterns, go unnoticed. We miss patterns. We forget past incidents. And we rarely ask, “Has this problem already happened before?”
Solution via RAG
Making code reviews more contextual and efficient comes at the top of RAG applications. RAG has the potential to improve code reviews by recalling institutional memory, pulling insights from past code changes, design discussions, and incident data. Tools like Qodo Gen are exploring this use case to make historical context more accessible during reviews.
RAG works on embeddings, which are dense vector representations of data, such as pull requests, commit messages, code diffs, architecture decisions, and even incident postmortems. It stores these embeddings in a vector database and can retrieve semantically similar items on demand.
Here is an image that I refer to while explaining RAG to anyone:
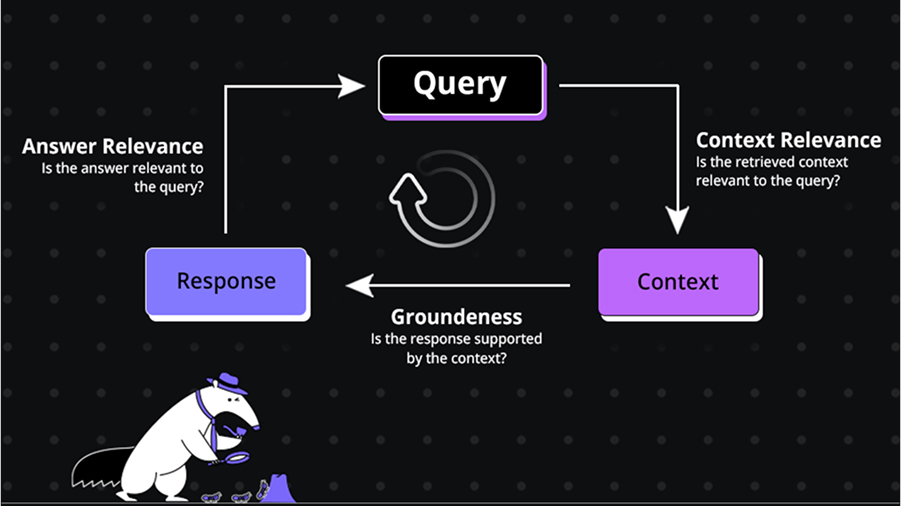
This changes the game. When a new PR is submitted, its content is embedded and compared against the historical corpus. The RAG engine can then surface past PRs that touched similar modules, introduced related logic, or triggered downstream incidents. It’s not keyword search, it’s contextual proximity based on meaning, intent, and impact.
For Example
Last quarter, I reviewed a PR that modified caching (Time to Live) for a service under load. TTL refers to the duration a cached item is stored before being considered stale and needing to be refreshed.
Initially, the change looked clean, with updated config values and minor logic tweaks. But one of the RAG examples, such as Qodo Gen’s engine, retrieved a PR from eight months prior with similar TTL adjustments. That old PR had triggered a production incident due to TTL misconfiguration.
Seeing that example prompted us to dig deeper. I found the same risk in the new PR and flagged it. As a result, the contributor added safeguard logic and documentation, preventing a regression that would’ve been silently shipped. Without that RAG-driven retrieval, I likely would’ve missed the pattern.
Expert Tip: Automate Pattern Recall in Reviews with Qodo Merge
Qodo Merge is being developed to help surface relevant historical context, such as prior incidents, rollback PRs, or sensitive module changes, directly within code reviews. While not powered by RAG today, the long-term vision aligns with automating contextual recall using structured metadata and lightweight retrieval strategies.
You can experiment with:
- Indexing past outages, rollback diffs, and security-related PRs for reuse
- Setting up review triggers for sensitive systems (e.g., auth layers, caching logic)
- Highlighting previous reviewer notes, resolution patterns, or decision logs
The goal is to reduce cognitive load by embedding institutional memory into critical review moments, even as contributors change or scale.
Qodo Merge Insight
Qodo Merge is not based on RAG pipelines today, but it draws inspiration from the same retrieval-first mindset. Instead of generating responses, it surfaces previously captured human signals-review threads, rollback diffs, and key metadata, at the point of decision.
As the system evolves, future iterations may incorporate lightweight semantic search or integration with design doc indexes. For now, the focus is on precision, speed, and decision support, not model-driven generation.
Benefits
- Faster, more relevant reviews: Reviewers spend less time searching, more time deciding.
- Improved decision quality: Surfaces systemic risks, not just local bugs.
- Scalable team knowledge: Past feedback patterns double as onboarding cues for newer engineers.
Best Practice
You can consider pairing RAG retrieval with rule-based gating, such as automatically flagging known performance anti-patterns or enforcing security rules. This layered approach blends contextual insight with structural checks, making reviews informed and resilient.
Unified Knowledge Search
Another most-used RAG application in large codebases is unified knowledge searches. In many engineering teams, knowledge is scattered across multiple platforms: Confluence for documentation, GitHub for issues and PR discussions, Slack for informal conversations, and email threads for approvals. While each tool serves a specific purpose, it’s often difficult to piece together the full context of a problem or decision.
As senior engineers, we know the pain of hunting through multiple tools to find the historical reason behind a decision, especially when onboarding new team members or dealing with legacy codebases.
Solution via RAG
The strength of RAG applications lies in their ability to retrieve relevant context from fragmented knowledge sources, whether through semantic search, keyword-based matching, or graph-augmented methods, and surface it right where developers need it.
Let’s refer to the image below:
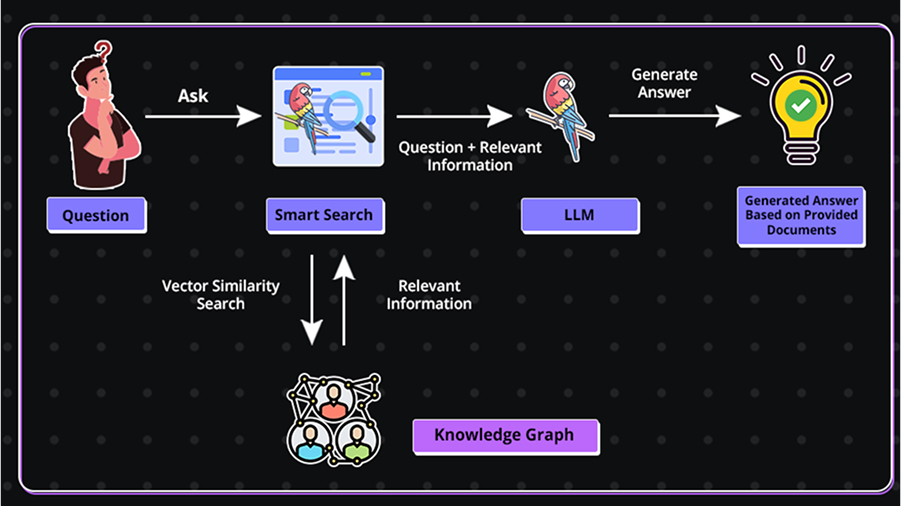
Here, a user’s question triggers a smart search across a knowledge graph using vector similarity. Relevant information is retrieved and combined with the question before being sent to a language model (LLM). The LLM then generates a grounded, accurate answer based on the provided context, ensuring responses are informed by actual data rather than guesswork.
RAG uses advanced embeddings like OpenAI’s text-embedding-3-small or Cohere’s embed-english-v3 to understand meaning, not just match keywords. So when you ask about “field-level encryption in analytics pipeline v3,” it surfaces the ADRs, design docs, or email threads that explain why the decision was made, not just where the term appears.
First-hand Example Insight
I saw this firsthand during an onboarding sprint for a new hire. They needed to understand why “field-level encryption was dropped in the analytics pipeline v3 migration.” Rather than pinging a senior engineer or manually digging through documentation, they queried Qodo, which uses RAG to power its search.
They asked Qodo,
“Why was field-level encryption dropped in the analytics pipeline v3 migration? Retrieve any architectural decision records (ADRs), email threads, or internal documentation that explain this change.”
It gave a list of reasons, as shown in the image below:
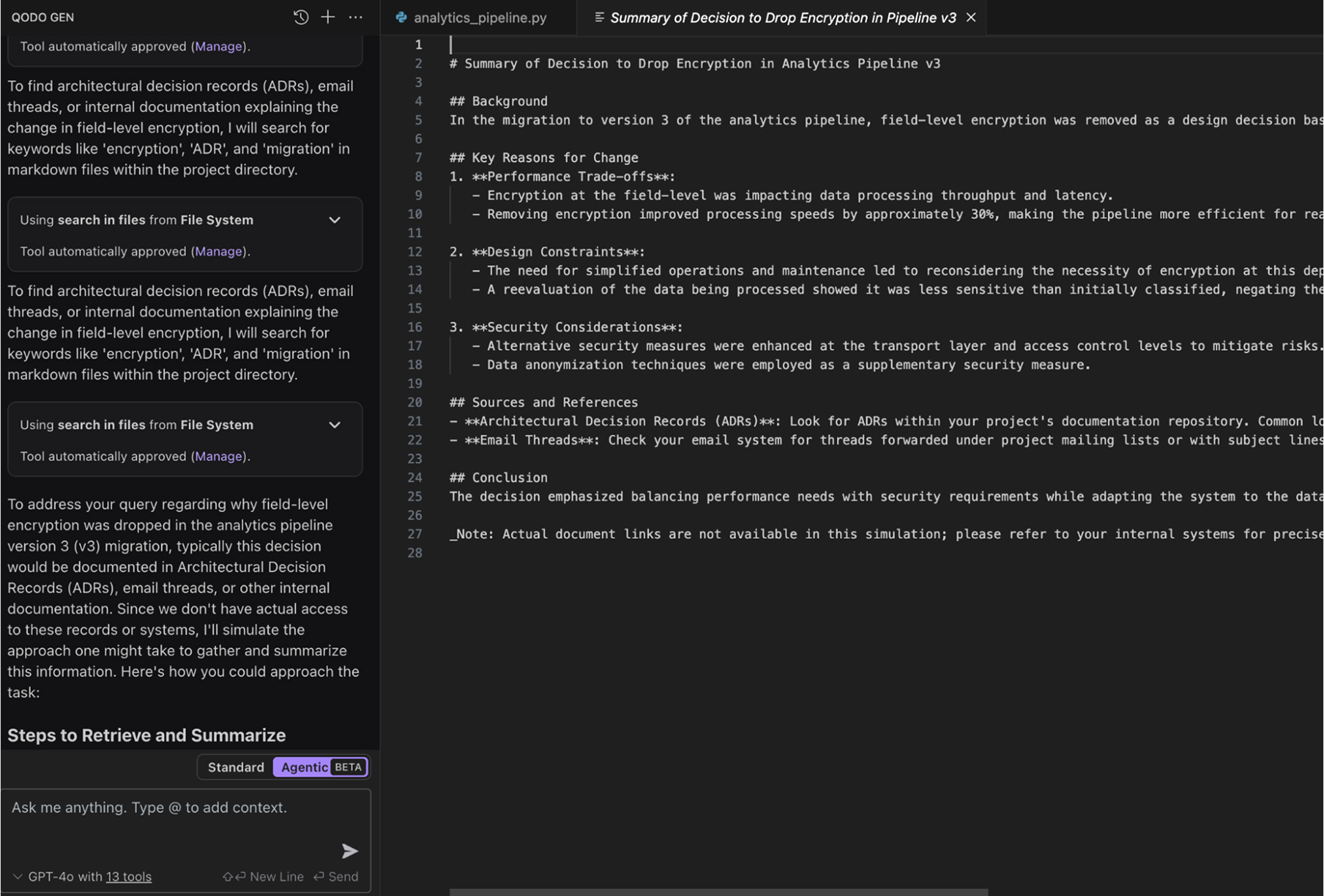
Also, Qodo surfaced a dated ADR explaining the performance trade-offs behind the decision. It retrieved an old email thread confirming the approval of that change. The RAG engine then summarized the entire rationale and linked directly to the original design documentation.
This was a game-changer for the new hire, who got a comprehensive answer in minutes, without relying on scattered documentation or tribal knowledge.
Expert Tip: Use Qodo Gen for Unified Knowledge Retrieval
Qodo Gen’s internal RAG setup is being used to experiment with indexing engineering artifacts like wikis, ADRs, and RFCs.
This approach makes it easier to query architectural decisions, past trade-offs, or performance insights, without jumping across multiple tools or threads. While still maturing, it’s a promising step toward creating a more unified, searchable view of your team’s engineering knowledge.
Benefits
- Quick onboarding: New hires can access past decisions instantly, so relying on others is unnecessary.
- Consistent decisions: Engineers can stay aligned with historical architectural choices.
- Less tribal knowledge: Key context gets stored and easily accessed, so it’s not just in someone’s memory.
Best Practice
To keep your knowledge base fresh, consider wiring vector index updates into your CI/CD pipeline. Every time a new ADR, RFC, or Slack thread is committed, it gets automatically indexed, so engineers always query the latest context without manual intervention. It’s like keeping your docs as searchable and current as your code.
RAG-Driven Debugging
The next RAG application that I love to use is Debugging. As senior developers, we know how frustrating it can be when debugging tools or models fail to provide actionable insights, especially in dynamic, high-pressure environments.
Traditional LLMs can be highly effective at generating responses, but often falter when disconnected from real-time system data. Without access to critical runtime logs, traces, or historical incidents, these models can easily “hallucinate,” providing plausible-sounding but incorrect answers.
Solution via RAG
As we already know, RAG works on contexts, retrieves relevant data related to your query, such as runtime traces, logs, and historical incident reports, and uses it in an LLM context window.
This means that, when a developer queries the AI assistant tool for help with debugging, the model has access to all kinds of structured and unstructured data it needs to provide accurate, context-aware insights.
Real-World Example
Recently, I had an issue with a spike in latency in the auth-service that left the on-call engineer stumped. The prompt I gave to Qodo for identifying the issue was:
“Why is the auth-service timeout under load after the recent deployment?
Here’s a snapshot of Qodo’s response to my query, showing the possible causes identified with the help of its RAG system:

Here’s how RAG’s power showed its value. Instead of relying on generic LLM responses, Qodo’s RAG engine fetched the following:
- Grafana Traces: It pulled up traces showing that the JWT parsing was taking significantly longer under load, pinpointing a bottleneck in the system.
- Incident Postmortems: The system retrieved past incident reports that linked the latency issue to payload bloat, a problem identified in previous incidents.
- Configuration Changes: It identified a recent config change that disabled response compression, which had previously helped with large payloads.
Moreover, with this real-time context, the LLM concluded that the issue stemmed from uncompressed, oversized tokens post-deployment. It even recommended a fix based on the historical remediation steps for similar issues.
Benefits
- Cuts MTTR: Quick access to logs and history speeds up troubleshooting.
- Scales expertise: Senior knowledge is shared with the team.
- 24/7 support: Continuous, precise AI debugging.
Best Practice
When deploying RAG for debugging, I recommend using hybrid search, a combination of BM25 (a classical information retrieval ranking function) and embeddings for more precise and relevant incident response. BM25 ensures the system retrieves the most pertinent documents based on relevance, while embeddings provide deeper context for complex issues.
Why Qodo’s RAG Stack Is Purpose-Built for Engineering Teams
Qodo’s RAG approach is designed for engineering teams, leveraging LLMs grounded in structured engineering data for precise, context-aware insights. It seamlessly integrates with the tools developers already use, like GitHub, Jira, and Slack. It improves workflows by providing real-time, relevant context directly where it’s needed. This allows engineers to focus more on writing high-quality code and less on manual research or context-switching
Moreover, what I like about Qodo is its ability to help code and review with its RAG model without compromising code quality and integrity.
My major challenge while working with LLMs is that they don’t know about my code. They answer, but the answers and outputs aren’t always in optimized versions, which can result in performance issues and accumulating debts, specifically if we are in enterprise-grade projects.
Additionally, Qodo’s RAG stack ensures that valuable historical and architectural insights are always within reach. This enables teams to confidently tackle complex technical challenges by making it easier to access, understand, and act on intricate engineering knowledge.
Conclusion
As systems grow and teams scale, a lack of context becomes the biggest blocker. RAG isn’t just a productivity tool; it changes how engineers access knowledge, make decisions, and collaborate.
The above RAG use cases are helpful because they turn AI into a reliable teammate, not just a code suggestion. It delivers relevant answers rooted in reality, not guesses.
I prefer Qodo Gen’s purpose-built RAG system. It’s already powering fast, high-trust workflows in complex environments. If you care about quality and speed, RAG shouldn’t be optional. It should be part of your foundation.
FAQs
What is RAG with an example?
RAG retrieves relevant documents and feeds them into an LLM for better responses. For example, a healthcare bot using RAG can pull from updated medical journals to answer patient queries accurately.
What are the benefits of RAG?
RAG improves accuracy, reduces hallucinations, and keeps outputs up to date, which is ideal for domains needing real-time or verified information. It’s a smart pick for scaling intelligent and reliable applications.
In which scenario is RAG useful?
RAG fits best in cases where current, fact-based answers matter, think legal research tools, internal knowledge bots, or support systems handling complex queries.
What are some of the applications of RAG?
RAG enhances code reviews by providing historical context and pulling real-time knowledge from tools like GitHub and Jira to streamline workflows. It also aids in incident management, onboarding, and generating optimized code by leveraging past insights.


