Why Static AI Rule Files Like AGENTS.md Are Failing (and What Actually Works)

As AI coding agents become more common, many teams have adopted a simple strategy for guiding them: adding instruction files like AGENTS.md, CLAUDE.md, or similar rule files to their repositories.
The idea is straightforward. Document the rules of the codebase and give the AI agent access to them so it can produce better code.
But recent research from ETH Zurich suggests this approach may be doing more harm than good.
In a large evaluation across multiple coding agents and LLMs, researchers found that repository-level context files often reduced task success rates while increasing inference costs by more than 20 percent.
Other findings from the study were equally surprising:
- LLM-generated rule files reduced success rates by about 3 percent
- Inference costs increased by more than 20 percent
- Even human-written rule files improved success rates by only around 4 percent
In some cases, agents performed worse than when no rule file was provided at all.
At first glance this seems counterintuitive. More guidance should help an AI system produce better results. But the issue is not the rules themselves. The real problem is how those rules are delivered to the model.
At Qodo, we built a rules system specifically to address this problem. But first, it helps to understand the approach most teams use today.
Why Teams Started Using AGENTS.md
Before discussing the limitations, it is worth understanding why files like AGENTS.md became popular in the first place.
AI coding agents work best when they understand the conventions of a codebase. Teams quickly realized that a simple way to provide this context was to document rules directly in the repository.
A typical rule file might include things like:
- architectural patterns the project follows
- security or compliance requirements
- preferred libraries or frameworks
- conventions around testing or error handling
For early AI tooling, this approach worked surprisingly well. Adding a repository rule file gave agents more context about the project and often improved results.
But as these files grew larger and agents became more sophisticated, the limitations of static rule files started to appear.
Where Static Rule Files Break Down
Most teams implement AI rules using a single static file:
AGENTS.md
CLAUDE.md
AI_GUIDELINES.md
These files typically contain general guidance about how the codebase should evolve. Instructions might include architectural conventions, security requirements, or preferred implementation patterns.
When the agent runs, the entire file is injected into the prompt.
While this approach is simple, it creates several structural problems.
Too Much Context
Large instruction files force the model to process rules that may have nothing to do with the current task. If an agent is editing UI code, it may still receive rules related to database architecture, authentication logic, or backend services.
This increases token usage and adds unnecessary cognitive load for the model.
Models Follow Irrelevant Instructions
LLMs tend to treat all instructions as important. When irrelevant rules appear in the prompt, the model may attempt to satisfy them anyway. This can lead to unnecessary reasoning or exploration that has nothing to do with the task being performed.
Rule Files Grow Over Time
In practice, rule files rarely stay small. Teams continuously add new guidance as they discover edge cases or architectural constraints. Over time the document becomes longer, more redundant, and sometimes contradictory.
Because the file is simply unstructured text, there is no reliable way to determine which rules are actually useful.
No Feedback Loop
Perhaps the biggest limitation is the lack of feedback. Static rule files provide no visibility into how they affect agent behavior. Teams cannot easily determine which rules trigger frequently, which ones are ignored, or which ones introduce unnecessary noise.
Without feedback, rule files tend to grow indefinitely.
The Real Issue: Static Context Does Not Scale
The ETH Zurich research highlights a broader pattern in how LLMs behave.
AI systems do not always perform better when given more instructions. In fact, excessive context can degrade performance by increasing ambiguity and forcing the model to explore irrelevant possibilities.
This does not mean rules are a bad idea. It simply means that static rule delivery does not scale well for AI agents.
Instead of injecting an entire rules document into every prompt, agents need a way to receive only the rules that are relevant to the task at hand.
A Better Approach: Context-Aware Rules
A more effective strategy is to deliver rules dynamically based on the code being modified.
For example, if a developer changes files in:
/src/payments/
the agent should only evaluate rules related to payment logic. Rules related to authentication, UI components, or unrelated services should not appear in the prompt.
Reducing irrelevant context significantly improves signal quality and keeps the model focused on the task.
How Qodo’s Rule System Works Differently
At Qodo, the Rules System was designed to avoid the limitations of static rule files. Instead of storing all rules in a single document, rules are structured, contextual, and dynamically evaluated during code review.
Context-Aware Rule Retrieval
Rules can be scoped to specific areas of the repository. When a pull request modifies certain directories, only the rules relevant to those parts of the codebase are evaluated.
This keeps prompts smaller and prevents unrelated instructions from polluting the context.
Structured Rules Instead of Free-Form Text
Traditional rule files rely entirely on natural language. While convenient for humans, natural language instructions can be ambiguous for LLMs.
Qodo rules use structured fields such as:
- objective
- success criteria
- failure criteria
- examples
- severity
This structure reduces interpretation errors and makes rule evaluation more consistent.
Bounded Context Through Rule Batching
Another lesson from the research is that model performance declines as prompt context grows.
To address this, Qodo evaluates rules in smaller batches rather than loading an entire ruleset into a single prompt. Each model call sees only a limited set of rules, which helps maintain clarity and focus.
Automatic Conflict Detection
As rule sets grow, contradictions and duplicates can emerge. Qodo automatically detects relationships between rules, including identical, overlapping, or conflicting rules. This keeps the ruleset cleaner and reduces noise.
Continuous Feedback
Unlike static rule files, Qodo tracks how rules perform in practice. For each pull request the system records whether a rule was checked, passed, violated, or skipped.
Over time this makes it possible to identify rules that are ineffective, redundant, or overly noisy.
Rules Should Verify Code, Not Just Guide It
There is another important distinction between traditional rule files and modern rule systems.
Most rule files attempt to guide how code is generated. However, LLMs do not always follow instructions reliably.
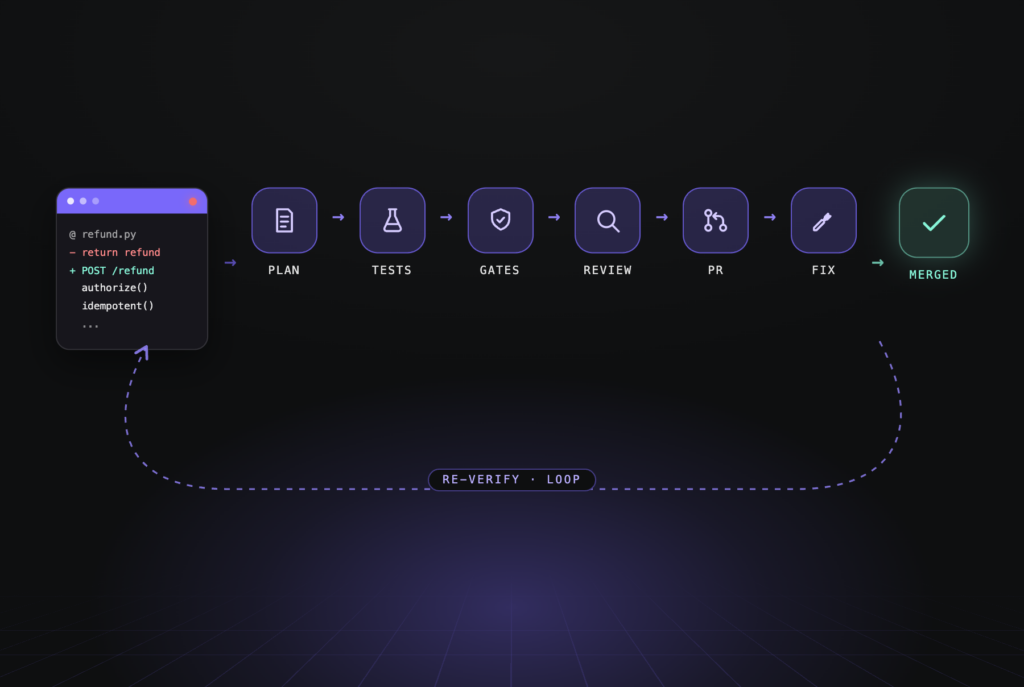
Instead of relying only on guidance during generation, Qodo focuses on validating the final code. Even if an AI agent ignores a rule while writing code, Qodo can still verify that the resulting implementation satisfies the required standards before it is merged.
To make rule validation reliable, Qodo uses a dedicated rules-enforcement agent separate from the agents responsible for reviewing or reasoning about the code. This agent is optimized specifically to detect rule violations rather than generate suggestions. In internal benchmarks, it achieves high recall and precision when identifying violations, ensuring that rules act as enforceable guardrails rather than passive guidance.
This shifts rules from being suggestions to becoming enforceable guardrails.
The Future of AI Coding Rules
Instruction files like AGENTS.md were an early attempt to encode team knowledge for AI coding agents. They provided a simple way to share guidelines with emerging AI tools.
But as the ETH Zurich research shows, static context files quickly become too blunt an instrument.
Effective AI rule systems need to be contextual, structured, feedback-driven, and enforceable. In other words, they need to be designed specifically for AI systems.
Static rule files were a useful starting point. The next generation of developer tooling is moving beyond them.