When Your System Is an Agent, You Need a Different Benchmark
At some point during the evolution of Qodo’s code review system, we ran into a problem that snuck up on us: the benchmarks we’d built to measure quality no longer measured what we cared about.
We hadn’t changed the benchmark. The system had changed. We’d gone from a single LLM call that returned a YAML list of code suggestions to a multi-agent pipeline with specialized agents, tool calls, compliance checking, and deduplication. But we were still evaluating it like a prompt.
This post is about what that journey looked like: how our architecture evolved, why our benchmarks had to evolve with it, and what the benchmarking infrastructure looks like today.
From Prompt to System
Qodo’s code review capability didn’t start as a multi-agent system. It started as a single command, /review, that called an LLM and returned a structured YAML list of CodeSuggestion objects. Simple. Fast. Measurable.
As we added more clients, expanded to more surfaces (IDE, Git, CLI), and deepened our code review capabilities to compete on quality, the single-agent model stopped scaling. Better quality meant understanding more context, catching different types of problems, and doing so with fewer false positives. You can’t do that with one monolithic prompt.
So we moved to what we call a Mixture of Agents (MoA) architecture. Multiple specialized models work together with a routing mechanism that selects which agent(s) handle each specific task. This isn’t React. It isn’t LangGraph. It’s our own deep agent framework where each agent operates with its own prompt, has access to specific tools, and evaluates its own progress toward defined goals.
The first three major tasks we separated into specialized agents:
Context Collection: gathering full-codebase context, PR history, and repository-specific rules before any review begins. Without deep context, every agent downstream is flying blind.
Issue Finding: detecting bugs, logic errors, breaking changes, and security problems in the diff, grounded in real codebase understanding.
Compliance Enforcement: checking the PR against the organization’s defined coding standards and rules, identifying violations with precise localization.
Each agent has its own prompt, its own toolset, and evaluates its own intermediate progress. They share state, but they’re specialized. This design gives us higher tool call accuracy, lower latency, reduced hallucinations, and, critically, easier debugging when something goes wrong.
That last one matters more than people expect. When a monolithic agent produces a bad output, you don’t know where it went wrong. With specialized agents, you can trace the failure to a specific stage.
The Problem with the Old Benchmark
When the system was a single prompt, measuring quality was straightforward. We ran /review on 400 real open-source PRs (polyglot: Python, C++, Go, TypeScript, Rust) across over 100 repos. We used +10 model code suggestions per PR as the reference answers, o3 as the judge, and scored each candidate model on a normalized 0-100 scalar.
Clean setup. One command in, one number out. You could put models on a leaderboard.
But once the system became an agent pipeline, that benchmark broke in several ways:
Determinism collapsed. A prompt can return the same output for the same input when constructed correctly and at temperature=0. An agent pipeline doesn’t. It makes tool calls, follows branching logic, and may collect different contexts on different runs. String-level matching for evaluation becomes meaningless.
The output structure changed. We’re no longer comparing YAML lists. We’re looking for findings with provenance: which agent surfaced this issue, which rule triggered it, which file and line number it points to. Matching these semantically against ground truth requires a different evaluation approach.
Multiple findings per PR. A compliance agent might surface 3 violations. An issues agent might catch 2 bugs. You need precision and recall separately, not a single aggregated score. A model that catches 1 of 5 issues with 100% precision looks great on a leaderboard and terrible in production.
Ground truth got fuzzy. With injected bugs, “did the model catch the right bug?” requires semantic reasoning, not string comparison. A finding that says “this null check is missing in the error handler” may be a hit even if the exact phrasing differs from the ground truth.
Evaluation itself became expensive. One LLM judge call per PR is cheap. When you’re running ensemble judges across 400 PRs, parallelizing across multiple providers, and doing it repeatedly across ablation experiments, the cost adds up fast.
The old scalar benchmark wasn’t wrong. It was just optimized for a system that no longer existed.
The New Benchmark Architecture
We rebuilt around two core ideas: synthetic PRs and LLM-as-Judge with ensemble voting.
Synthetic PRs
The ground truth problem in code review evaluation is fundamental: you can’t get a reliable signal from real PRs alone, because you don’t control what issues exist or how severe they are. So we generate controlled corruption.
For each benchmark case, we start with a real, merged upstream PR. We cherry-pick those commits onto a fresh base branch, then inject a known rule violation or bug. This gives us a CLEAN/CORRUPTED sibling pair: two versions of the same PR, one with no injected issue and one with a precisely defined defect the agent should catch.
For the Compliance Benchmark, the injected violation is a rule violation: something that breaks a standard captured in the repository’s codebase. We evaluate on three criteria simultaneously: did the agent identify the correct rule category, the correct file location, and a correct issue description? All three must match for a hit. This prevents gaming by vague, high-recall complaints.
For the Issues Benchmark, we inject functional bugs (logic errors, edge case failures, race conditions, resource leaks, improper error handling) with multiple bugs per PR case. The full pipeline, including issues detection, compliance, deduplication, and more. We track two metric pairs: precision and recall.
The per-repo isolation is strict. Rules are keyed by org/repo, injections are validated against repository-specific standards before being committed, and we keep clean and corrupted PRs on separate branches in a dedicated benchmark organization.
LLM-as-Judge with Ensemble Voting
We support two judge modes:
Holistic: the judge sees raw findings and ground truth, evaluates whether each finding maps to a known bug. Best for internal ground truth with file paths and code snippets.
Pairwise: the judge compares findings from two systems side by side. Best for apples-to-apples comparison when you’re evaluating a model change.
In all modes, we use an ensemble of three providers (OpenAI, Anthropic, Gemini) running in parallel, producing structured outputs, and then averaging scores with their standard deviations. The ensemble reduces provider-specific bias. The structured output makes post-processing reliable. The standard deviation tells you when the judges disagree, which is itself a signal.
We short-circuit evaluation for edge cases (both empty, tool empty, ground truth empty) and handle them deterministically. This saves roughly 30% of LLM calls across a typical benchmark run, which matters at scale.

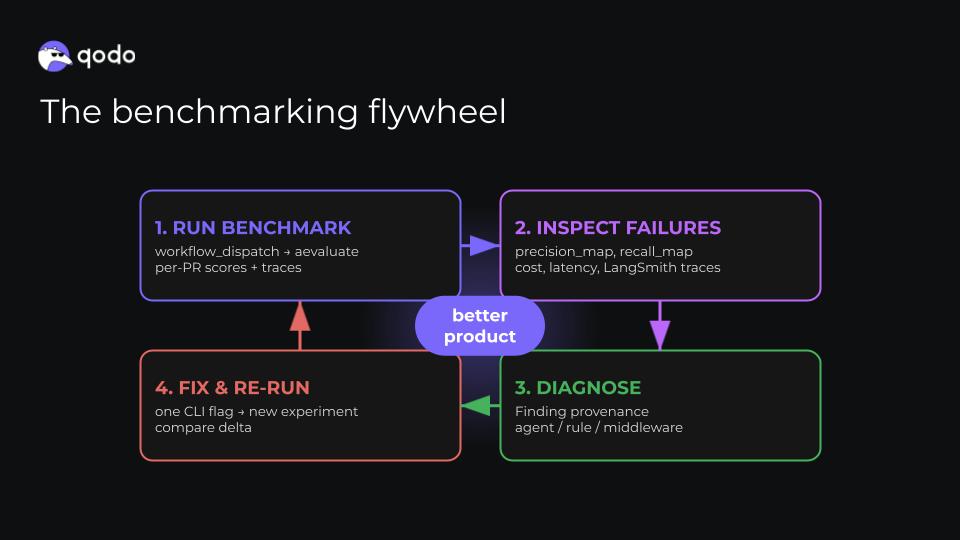
The Benchmarking Flywheel
The benchmark infrastructure isn’t just for measuring absolute performance. The real value is the feedback loop it enables: run, inspect, diagnose, fix, re-run.
We expose the full system through a single workflow_dispatch CI trigger with configurable knobs:
- Toggle agents on and off for ablation
- Swap the underlying model for any agent
- Change the evaluation mode (holistic | pairwise)
- Run multiple times to account for non-determinism
Every run produces per-PR traces, cost, and latency in LangSmith. When precision drops on a specific PR, we can inspect exactly which agent produced the finding, which tool call triggered it, and where in the pipeline the failure happened. That provenance, knowing which component caused a bad output, is what makes the system debuggable at scale.
The flywheel in practice: run the benchmark, look at precision map and recall broken out by agent, find the PRs where we’re missing issues or producing false positives, trace to the responsible component (issues agent? compliance enforcement?), make a targeted change, re-run with a single flag. We went from opaque outputs on a static leaderboard to fully interpretable metrics with full trace visibility.
From “Is Our Prompt Good?” to a System You Can Trust
The full picture of where we landed:
Prompt Era: One scalar. Static. Single LLM call. Opaque output. Leaderboard position.
Agent Era: Precision, recall, F1 across agents. Synthetic PR pairs with injected violations. Multi-agent pipeline with full middleware. LangSmith traces per PR. Ensemble judge with mean and standard deviation across three providers. CI with ablation knobs.
The jump from one scalar to full metrics isn’t complexity for its own sake. It’s because the system is more complex, and the evaluation needs to reflect that. A single score that aggregates across issue types, agent stages, and judge modes would hide exactly the failures you need to find.
The other shift is conceptual: you can’t improve what you can’t measure, but you also can’t trust measurements that don’t match your system’s architecture. The old benchmark was measuring a prompt. We were iterating on an agent. Those are different things.
What we’ve built here isn’t just Qodo’s internal eval infrastructure. It’s a repeatable methodology for any team building multi-agent systems that need to demonstrate and improve quality in a principled way. The specific tools matter less than the loop: control your ground truth, build ensemble judges that don’t favor any single provider, expose ablation surfaces, and close the feedback loop between metric and component.
Agents aren’t prompts. Don’t benchmark them like they are.


