Prompt Engineering vs RAG: Smarter Code Suggestions
TL;DR
- Prompt Engineering is fast and useful for generic, open-source-based coding tasks.
- It struggles with private APIs, modular enterprise code, or niche frameworks.
- RAG improves accuracy by injecting relevant code/docs at runtime, but demands infrastructure like vector stores and embedding pipelines.
- You’ll see real-world examples comparing both strategies (e.g., FastAPI auth, distributed locks).
- Based on latency, compute, and codebase complexity, the post breaks down when to use RAG vs prompt engineering.
- You’ll learn implementation tips, performance tradeoffs, and how tools like Qodo make RAG practical for enterprise dev workflows.
Since tools like ChatGPT, Claude, and Gemini became mainstream, developers have quickly found ways to bring generative AI into their daily work. One of the first things people learned was that better inputs often lead to better results. These inputs, known as prompts, have become a skill of their own, called prompt engineering.
But writing a good prompt doesn’t always guarantee accurate or reliable output. As a Senior AI Lead, I’ve spent the past few months experimenting with LLM-based developer tools across enterprise-scale projects. The results were mixed. In one case, we used prompt engineering to generate automation scripts for internal services. The model confidently suggested AWS SDK calls, but the problem was that those methods were deprecated. In another project, it hallucinated internal API endpoints that had never existed, even though they were described in the prompt. That alone set us back hours in debugging.
The root issue? Prompt Engineering depends entirely on the model’s internal weights. You’re out of luck if a feature or method wasn’t part of the training corpus. No grounding. No fallback. Just syntactically correct guesses.
That shift, from relying on static memory to injecting dynamic, real-time context, makes RAG so compelling for developers. Unlike prompt engineering, which tries to coax the right answer from a sealed box, RAG opens the door to context-aware reasoning. The model’s training data limits no longer constrain you. If your organization updates an internal API, you don’t need to wait for the next model release. You just index the new spec, and the model can reason over it immediately.
However, both techniques have tradeoffs, and in high-stakes environments like CI/CD pipelines or internal platform tooling, those tradeoffs become liabilities if they are not well understood.
In this blog, I will dissect both approaches, including rag prompt methods, compare where they fail or scale, and offer technical guidance on choosing the right fit depending on your system’s complexity and reliability needs.
Evaluating Code Suggestion Strategies: Prompt Engineering RAG
Prompt Engineering is about shaping inputs to extract useful completions from an LLM’s pre-trained knowledge. It’s fast, stateless, and works reasonably well for common or well-represented problems in the model’s training set. The core limitation? It can’t reach outside that dataset. If you’re working on something uncommon, like internal tools or company-specific code, you’re stuck with whatever the model “remembers.”
By contrast, Retrieval-Augmented Generation (RAG) uses external data in the generation pipeline. At query time, it searches a curated knowledge base, thinks code from private repositories, API docs, architectural wikis, and combines the retrieved documents with the user’s prompt. The model then generates a response using pre-trained knowledge and the injected context.
To grasp the difference more clearly, consider the following practical example. We’ll test how each method handles the same developer task using the same prompt.
Prompt:
“Create a Python rate limiter for distributed API”
We’ll try this using just Prompt Engineering, then compare it with RAG-enabled generation.
Prompt Engineering Output:
When I ran the above prompt through a vanilla GPT setup in ChatGPT, I got a basic token bucket implementation using in-memory state:

The output is syntactically clean and easy to follow, but it’s not built for distributed systems. This version stores all state in memory. There’s no Redis integration or shared coordination mechanism, which makes it unusable across multiple nodes. Deploy it in a real distributed setup and you’ll run into rate-limiting violations immediately.
RAG Output:
I used the same rag prompt this time, but ran it through an RAG pipeline. The system retrieved context from our internal documentation while using a Redis-based rate limiter in the production environment.
Here’s what using a model that implements RAG returns as an output:
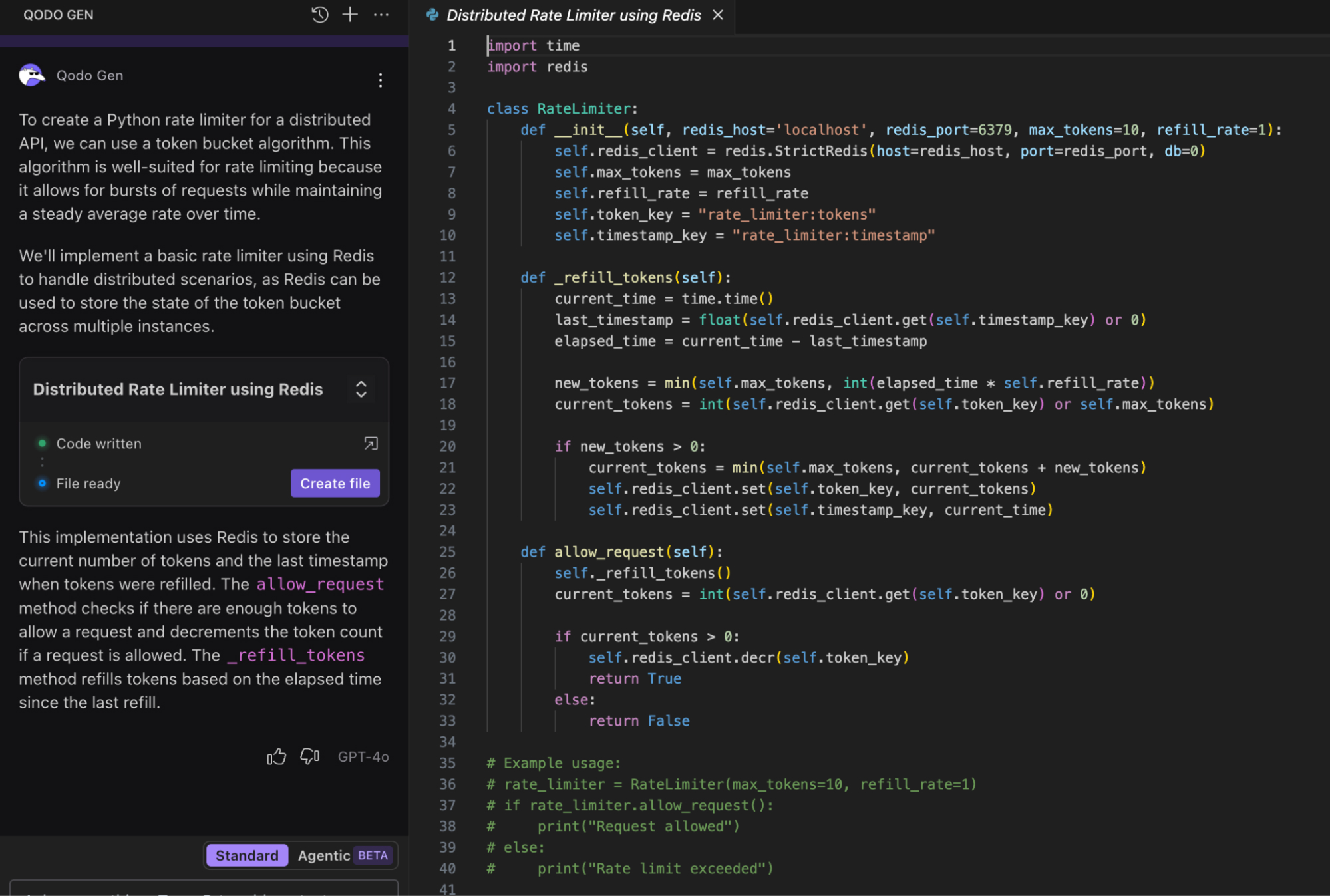
The class relies on a Redis backend to store and handle rate-limiting data. Redis is an in-memory data store that can be accessed by multiple servers or services concurrently. This means that no matter which instance of your application receives the request, they all share the same central view of request activity.
This approach works well in distributed systems because it correctly manages time windows across multiple instances. It uses Redis sorted sets to record each event’s timestamp, ensuring all nodes share the same state. The keys automatically expire, preventing stale data buildup and keeping the system efficient.
Summary
Prompt Engineering gives you a guess based on training. If you’ve indexed the right sources, RAG gives you an answer grounded in your system’s actual tooling. For anything beyond toy problems, that grounding becomes the difference between shipping and debugging for hours.
Comparing RAG Prompting and Prompt Engineering: A Detailed Analysis
When integrating LLMs into dev workflows, you’re not just choosing a tooling style but committing to specific tradeoffs that shape developer velocity, infrastructure load, and output quality. I’ve had to make that call more than once, and here’s how I break it down.
Technical Factors
When deciding between Prompt Engineering and Retrieval-Augmented Generation, it helps to consider several practical technical factors. These include how fresh the data is, the computing resources required, how predictable the output can be, and the response time you can expect.
Each approach has its own strengths and limitations in these areas, which affect how well they fit different development scenarios. Let’s take a closer look at these important technical aspects:
Data Freshness
Prompt Engineering operates on frozen weights. I’ve hit this wall repeatedly, prompting for examples using the AWS SDK v3, only to get code that belongs to v2. RAG solves this by indexing live repositories. When I connected it to our internal SDK registry, the suggestions immediately aligned with the latest API signatures.
Compute Load
Prompt Engineering runs on any decent CPU. It’s what makes it viable in lightweight local dev tools. RAG, however, requires GPUs or high-spec CPUs for embedding generation and vector similarity search. We had to spin up a dedicated GPU node to support RAG pipelines at scale.
Output Control
Prompt Engineering is extremely sensitive to input phrasing. A slightly ambiguous prompt produced inconsistent results across sessions. With RAG, injecting structured docs and code snippets helped us lock down stable, repeatable outputs, even for domain-heavy logic like multi-region failovers.
Latency
Prompt Engineering shines in IDE plugins. You get sub-second feedback. RAG introduces a 1–2 second retrieval step. That delay isn’t ideal for inline suggestions, but it works fine for tasks like validating CI/CD YAMLs or reviewing PRs against coding guidelines.
These technical factors highlight the key differences between Prompt Engineering and RAG in real-world use. Given these points, it’s natural that people have different takes on how distinct these approaches are.
That said, I read a thread on Reddit where users debated whether RAG is simply a more elaborate form of prompt engineering.
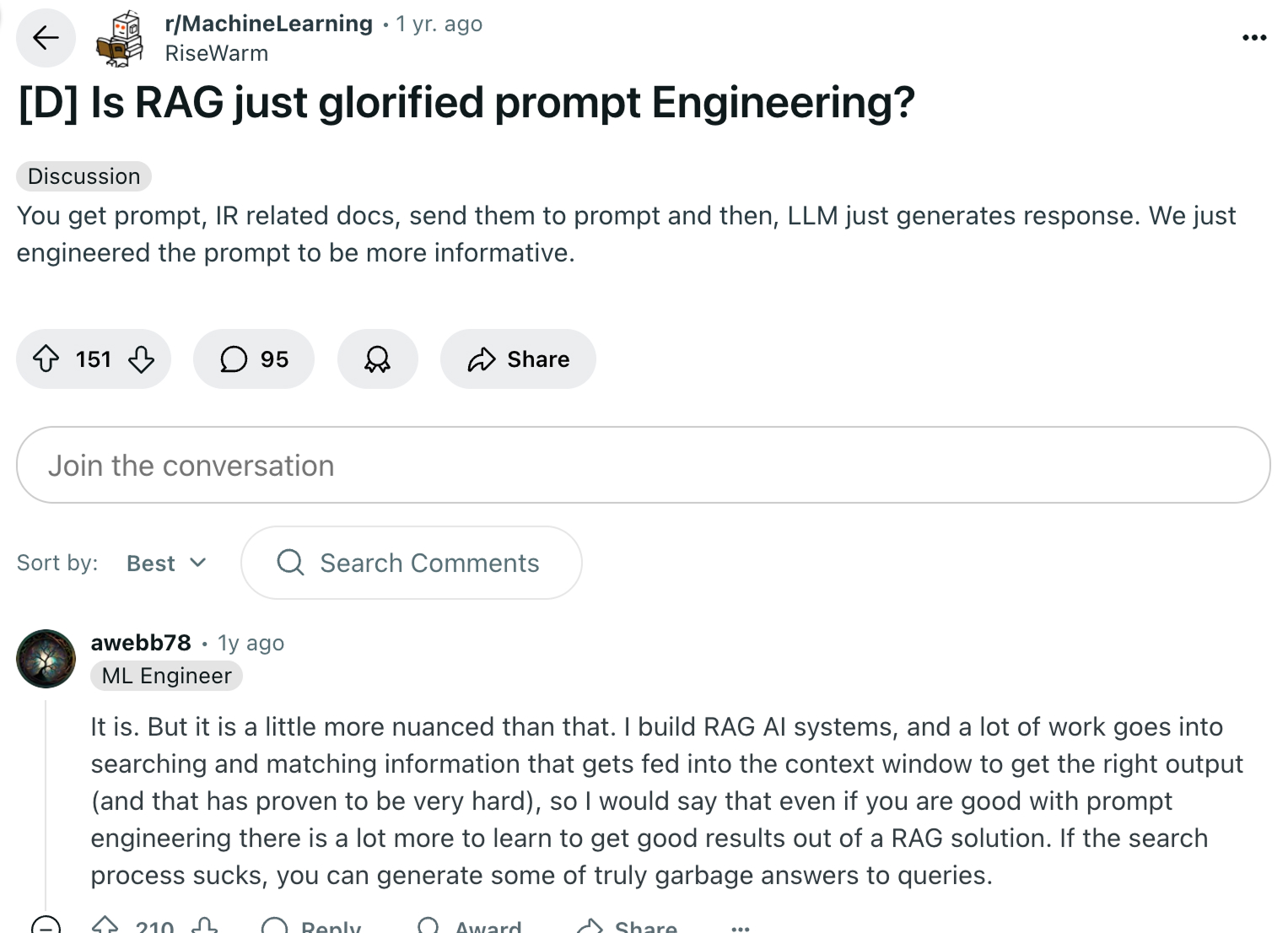
Some argued it’s just about making prompts richer with extra context, while others highlighted the additional complexity involved in searching and selecting the right information to feed the model. This conversation reflects how the AI community is still exploring what differentiates RAG.
Strengths and Weaknesses
To understand where each approach works better and struggles, I’ll break down the main strengths and weaknesses of Prompt Engineering and RAG prompt based on my hands-on experience. This comparison will help clarify when to choose one over the other.
Prompt Engineering: Strengths
- I use instant responses daily for one-off helpers like jq filters or Bash pipes.
- Zero infra setup; it’s prompt-in, result-out.
- Easily test pattern variations by tweaking phrasing in rapid iterations.
Prompt Engineering: Weaknesses
- Fails when dealing with private APIs or internal abstractions.
- Highly fragile; vague prompts return pseudo-correct answers that don’t compile or deploy cleanly.
RAG: Strengths
- Yields accurate suggestions for our domain-specific systems (Kafka wrappers, internal logging layers).
- Drastically reduces hallucinations by grounding generation in real code.
- Adapts quickly to changes if your retrieval source is continuously updated.
RAG: Weaknesses
- Operational overhead: vector stores, embedding jobs, periodic re-indexing.
- Slower response time limits usage to non-interactive tasks.
- If data isn’t refreshed, you’ll get outdated suggestions that look correct but aren’t deployable.
Use Cases
Understanding where each method fits best is critical for practical application. Here’s how I see the two approaches being used effectively in different contexts:
Prompt Engineering
- Best suited for rapid prototyping: quick CLI parsers, basic Flask apps, small shell scripts.
- Also great for standalone devs without access to full infra or private codebases.
RAG
- Ideal for complex systems with layered architecture: Kubernetes controllers, custom operators, and multi-tenant services.
- We use it in build pipelines to validate Terraform configs and ensure consistency with internal deployment standards.
Decision Criteria
Finally, choosing between Prompt Engineering and RAG depends on the project requirements and resources available. I use these criteria to decide the best fit:
Use Prompt Engineering when:
- You’re working on isolated modules with public dependencies.
- You’re constrained by compute or infrastructure (e.g., remote devboxes or solo projects).
- Speed matters more than completeness.
Use RAG when:
- You build on internal APIs or maintain large-scale systems.
- Context lives outside the model and changes frequently (e.g., monorepos, SDK registries).
- You can afford the latency and infra complexity to get accurate, grounded code.
Practical Examples
Now that we have understood all the basics of prompt engineering and RAG, we can shift to experimenting with real-world examples. Here’s what it looks like when you run these prompts through both Prompt Engineering and RAG-powered systems.
Example 1: REST API Endpoint
I encountered this while working on a lightweight internal service that exposed user profile data. I wanted to scaffold a basic GET endpoint using FastAPI, so I prompted the model directly.
Prompt:
"Write a FastAPI endpoint to fetch user data."
Prompt Engineering Output (Vanilla LLM)

Issue: This looks fine at first glance; it compiles and runs. But that’s where the usefulness ends. There’s no trace of how we handle authentication internally. There’s no validation, error handling, or context about how user data is retrieved in our stack. It’s a solid demo, but far from production-ready.
RAG Output (with internal auth patterns)
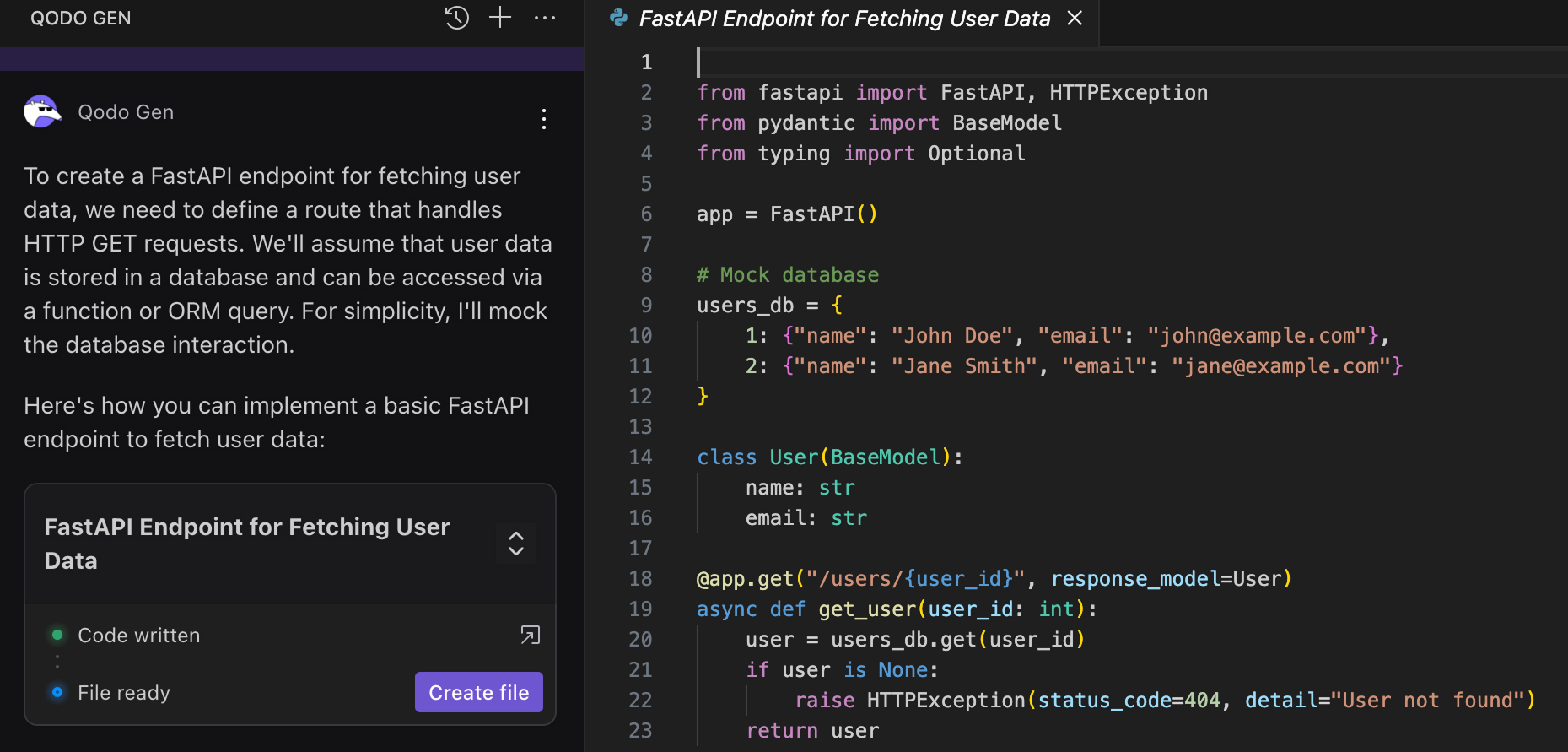
Why this works: What made the difference here was the retrieval layer. RAG prompt engineering helped me pull examples from our actual codebase, including how we wrap auth with Depends(), use UserResponse schemas, and standardize exceptions. This wasn’t just a better response; it reflected how our endpoints look in production.
Example 2: Distributed Lock
We needed to coordinate a background job across several containers in another project. I wanted a simple distributed lock in Python to prevent overlapping executions.
Prompt:
"Implement a distributed lock in Python for microservices."
Prompt Engineering Output

Issue: This technically counts as a lock, but only in the narrowest sense. It works fine if everything is happening in a single Python process. However, once deployed across multiple ECS tasks, this implementation falls apart. Jobs skipped the lock and ran in parallel, breaking idempotency.
RAG Output (with Redis-based locking from the team’s repo)
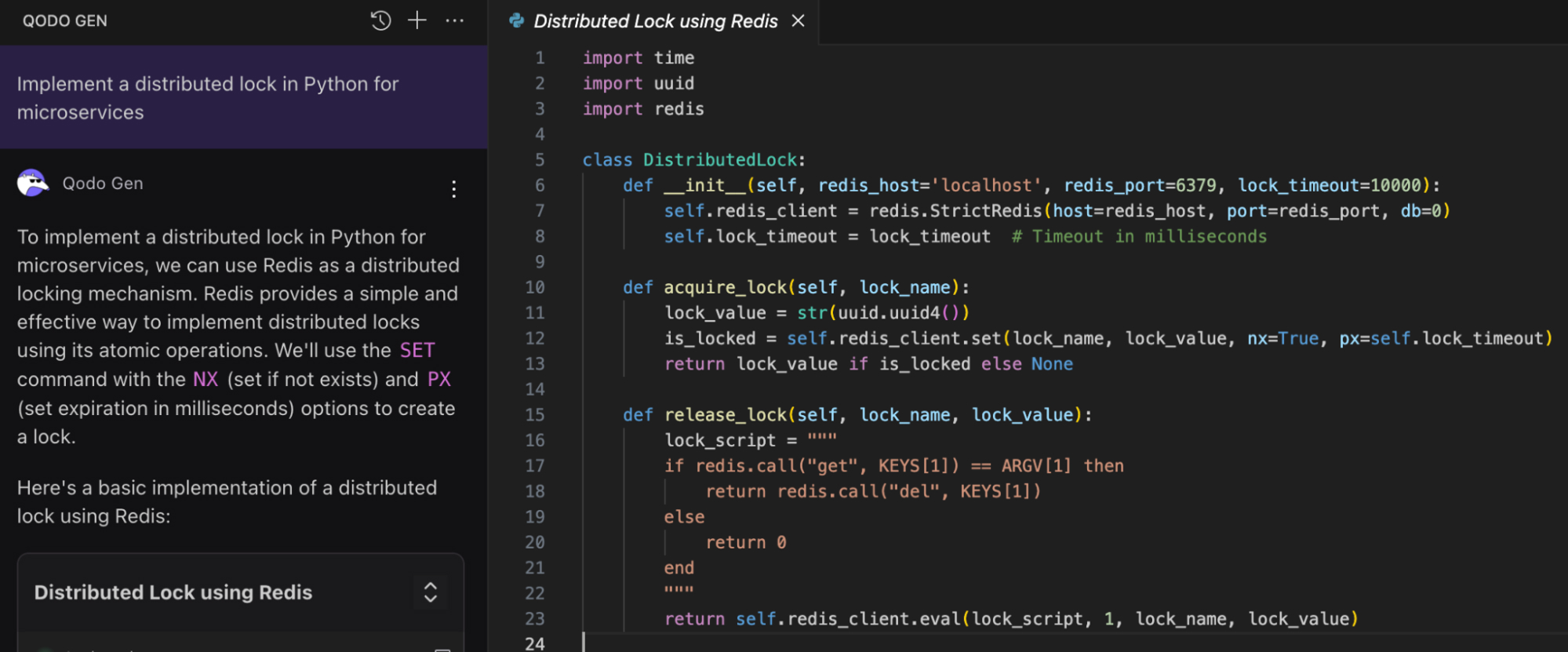
Why it works: RAG correctly uses Redis’ atomic SET NX for lock acquisition, and Lua scripting ensures only the owner can release the lock. It respects TTLs and safely coordinates distributed tasks, a pattern that would have taken hours to recreate manually.
Final Thoughts on Testing These
Set up a test bed, run Prompt Engineering and RAG against real prompts, and log the delta. This makes strengths/limitations obvious and helps guide integration decisions.
When you can see both side-by-side, one hallucinating or underbuilding, the other grounded in code your team wrote last week, you stop theorizing and start planning real adoption paths.
Context-Aware Code Suggestions That Don’t Miss the Mark
Prompt Engineering gets you quick wins, fast completions, no infra, no setup. But if you’ve spent hours tuning a single prompt only to get boilerplate or hallucinated results, you already know where it falls short.
RAG flips the model: it’s infra-heavy, requiring vector stores, chunking, GPU embedding pipelines, and repo sync logic. We built this internally once. It worked, but maintaining the retrieval logic and keeping embeddings fresh became its sprint backlog.
What Qodo Changes
Qodo Gen’s RAG engine doesn’t just retrieve context, it learns from edits. Instead of relying solely on embedding similarity or keyword hits, Qodo Gen scores retrieved chunks by how much the developer’s post-insertion edits the LLM-generated suggestion. That feedback loop closes the gap between what was retrieved and what was useful. We saw a measurable drop in hallucinated outputs, especially around internal APIs. In fact, Qodo can also be used as an automated code review that can help improve the reliability of pull request checks.
First-Hand Gains:
- Suggested FastAPI handlers matched our auth decorators and DB wrappers without manual tweaking.
- Kafka consumer templates included our internal observability setup, which is out of the box.
- Migration scripts for PostgreSQL used our team’s Flyway conventions with zero prompt engineering.
Ready to Try It?
Install Qodo Gen’s IDE plugin for VSCode or JetBrains, connect it to your internal GitHub/GitLab repos, and start generating code grounded in what your team ships. Let your codebase teach the model, not your prompt engineering skills.
And if you want to push accuracy even further, explore how Qodo integrates code review best practices into its RAG workflows. By combining the strengths of code review tools and retrieval-augmented suggestions, you get smarter, faster, and more reliable developer support.
Best Practices for Smarter Code Suggestions
There’s no single right way to get high-quality code completions, but there are consistent patterns that separate noisy suggestions from useful ones. These are the practices I’ve adopted (and seen teams adopt) to get consistently reliable output from both Prompt Engineering and RAG-based systems.
For Prompt Engineering
- Use task-specific phrasing
Generic prompts like “write a Python function” tend to surface whatever’s common across Stack Overflow. When I specify “Create a FastAPI endpoint with JWT validation and pagination over MongoDB”, the output is significantly closer to what we’d accept in code review. Add domain-specific terms early in the prompt to steer the model before it makes assumptions. - Include concrete examples
LLMs work best when they have something to anchor their understanding. So, instead of asking for a JSON schema validator, I include a small sample payload in the prompt. This helps the model infer the structure and data types more accurately. It also makes the prompt easier for teammates to read and reuse. - Keep prompts deterministic
To make outputs predictable and reliable, use a fixed randomness setting: low values like 0.2 or 0.3 work well. I’ve even committed JSON-formatted prompt templates to our repo for repeatable fine-tuned testing. Don’t rely on “trial and error”; treat prompts like reusable test cases.
For RAG
- Keep your retrieval index clean and up-to-date
Outdated embeddings are worse than none, they surface stale patterns. I’ve seen RAG pull pre-refactor service contracts, suggest deprecated arguments, and automate indexing with CI hooks (e.g., post-merge updates or nightly builds) to avoid drift. - Embed useful metadata
We tag every indexed file with the team owner, tech stack, and last commit timestamp. This isn’t just for filtering; it helps weight retrieval. Our retriever prioritizes files touched in the last 90 days over long-forgotten utils, which improves relevancy in fast-moving codebases. - Use hybrid search (BM25 + dense vectors)
Semantic search alone misses the mark when you need exact matches (e.g., config keys, method names). We’ve had better results using a two-phase search: BM25 to filter candidates fast, then dense vector similarity to rank suggestions. It’s especially helpful when naming conventions matter (e.g., fetchUserWithRoles vs. getUser).
Smarter suggestions don’t happen by chance. They happen when you give the model structure to work with and treat retrieval as a versioned, testable layer in your stack.
Conclusion
Prompt Engineering and Retrieval-Augmented Generation (RAG) aren’t interchangeable; they solve different problems in modern code suggestion workflows. Prompt Engineering is fast and accessible, ideal for generating common patterns when precision isn’t make-or-break. But it buckles under the weight of enterprise codebases, internal APIs, and modular architectures.
RAG introduces structure by grounding the model with indexed knowledge, internal repos, specs, design docs, improving accuracy and alignment with real-world systems. That structure comes with operational cost: embedding pipelines, vector stores, and higher latency.
In practice, I use both: Prompt Engineering for scaffolding quick prototypes, and RAG when quality, maintainability, and system fidelity matter. Tools like Qodo make RAG viable in production environments by closing feedback loops, reducing hallucinations, and aligning suggestions with code quality standards.
Smarter suggestions aren’t just about better models but better inputs, data, and tooling.
FAQs
What is the best way to think of prompt engineering?
It’s like writing a test case for an LLM: the more precise, scoped, and deterministic your prompt, the more reliable your output. Think in terms of constraints, edge cases, and intent, just like you would in code.
Does RAG require training?
No, RAG does not require training. RAG fetches relevant data at runtime (e.g., from private code repos or documentation) and feeds it to the LLM as context. You need good retrieval infrastructure: vector stores, chunking logic, metadata tagging, and indexing automation.
What is prompt engineering used for?
Primarily for steering general-purpose LLMs toward useful, context-specific output without additional training. In engineering, it generates boilerplate code, CLI scaffolds, config files, or API wrappers, especially when accuracy isn’t deeply coupled to internal logic.
What are the alternatives to RAG?
The different RAG alternatives are fine-tuning, custom plugins, or hybrid toolchains. When deciding between RAG vs fine-tuning, the key difference lies in flexibility and infrastructure needs. RAG injects fresh, real-time context at query time without retraining the model, making it more adaptable to changing data. Fine-tuning requires retraining the model on specific datasets, which can be expensive and slow to update but may yield more specialized outputs when data and use cases are stable.
How to improve prompt engineering?
To improve prompt engineering, you can start versioning your prompts. Test them like code and add structured examples. You can also isolate prompt variables and collect output differences to measure success. Over time, you’ll build a prompt corpus as valuable as your test suite.