What Is RAG and Why Does It Matter for Code Quality?
TL; DR
- Retrieval Augmented Generation (RAG) retrieves data to enhance AI-generated code, ensuring relevance and reliability.
- RAG lets AI access up-to-date information, avoiding outdated or inaccurate code suggestions.
- With Qodo, developers can leverage a built-in RAG pipeline to increase contextual awareness in AI of large codebases and improve code quality.
- Ensure you reindex your data for freshness and update and use clean data sources for optimal results.
Retrieval Augmented Generation (RAG) is a method that improves the output of a large language model (LLM) by adding information from an external, trusted knowledge base, such as internal databases, research papers, and product manuals, which is outside the model’s initial training data.
LLMs like ChatGPT, Gemini, or Claude have made remarkable progress in creating well-structured human-like output across various use cases. As an ML engineer, working with these tools has made me realize that speed isn’t the bottleneck; relevance and reliability are.
But while speed is important, it’s not the only thing that matters. LLMs aren’t that great for achieving real business outcomes, such as improving decision-making and automating customer interactions.
This is because traditional AI tools, like earlier versions of GPT, BERT, and even T5, are trained on publicly available static datasets. They don’t know your source code, documentation, or internal tooling.
For engineering teams and ML practitioners who care about accuracy, context awareness, and decision-grade output, Retrieval Augmented Generation (RAG) is a game-changer.
RAG is an approach that improves LLM’s performance with a retrieval system. Instead of relying solely on the data it was trained on, a RAG-based model can search external sources, like internal documents, databases, or knowledge bases (Confluence, Notion, etc) in real-time to fetch relevant information before generating a response.
According to GitHub’s 2023 developer report, developers using AI tools complete coding tasks up to 55% faster. More importantly, teams report fewer errors and faster reviews when AI systems are improved by adding relevant data from your project.
So, RAG LLM isn’t just an AI innovation; it’s becoming an essential component in modern development pipelines like CI/CD, automated documentation, and code intelligence systems that help teams maintain consistency and generate context-aware content that reflects current code and standards.
Understanding RAG and its components
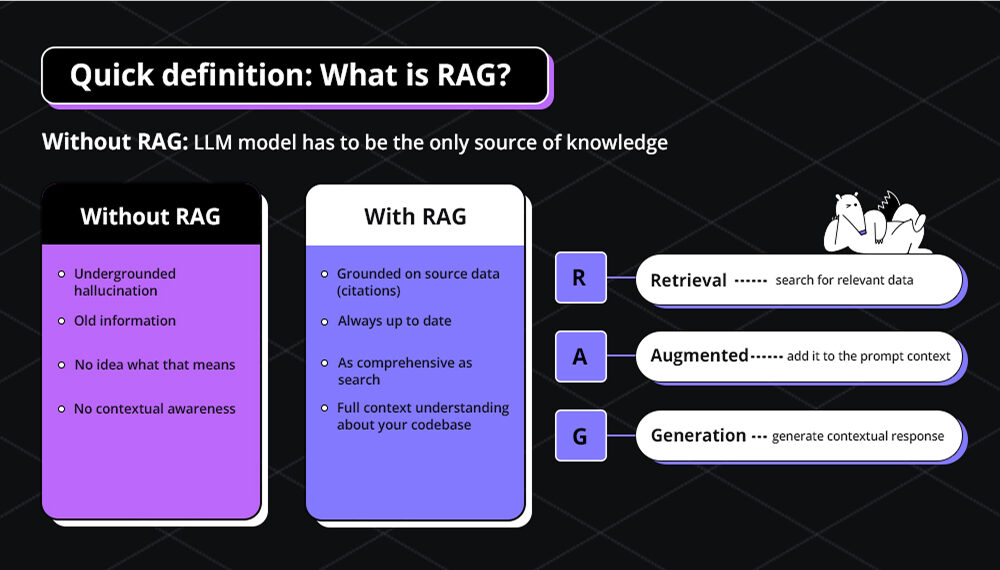
Here’s a simple way to understand how RAG works: when you ask a question, the system turns it into a numerical format called a vector. It then uses this vector to search through a knowledge base, such as documentation or code repos, to find the most relevant content. This context is passed to the language model, helping it give a more accurate and informed response.
When we talk about the architectural flow, retrieval augmented generation works in two stages:
- Retrieval: A query is used to search an external knowledge source (e.g., a vector database like FAISS or a document store like Elasticsearch) to fetch the most relevant context.
- Generation: The retrieved context is passed to a language model (e.g., GPT) to craft a response. This approach ensures the output is grounded in current, real-world data, making the response more accurate and relevant.
The end-to-end RAG architecture typically follows this sequence:
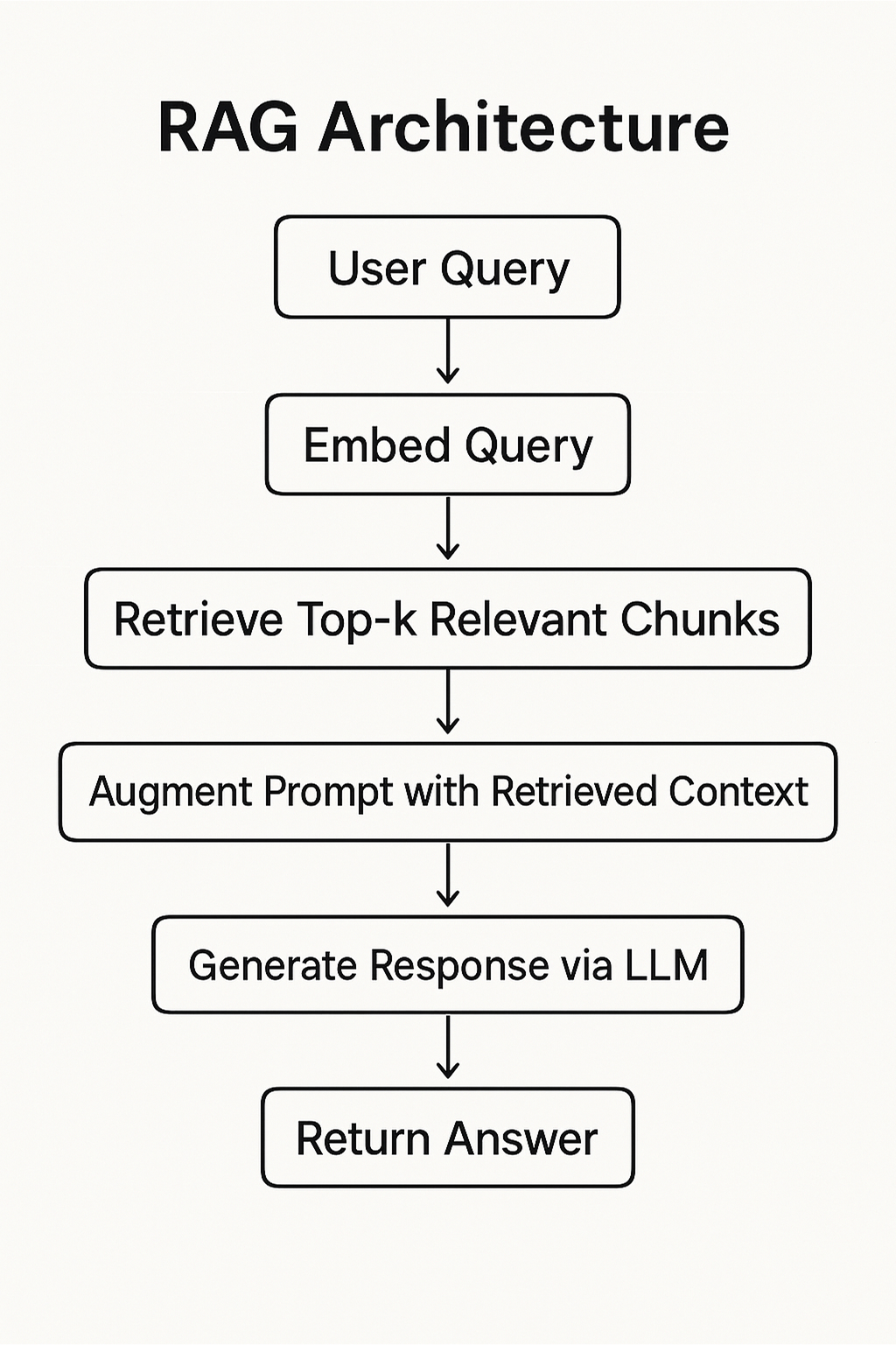
This RAG architecture diagram shows how a user query is processed through retrieval and generation processes. This makes it useful in dynamic domains, such as software engineering, where codebases, APIs, and best practices frequently change.
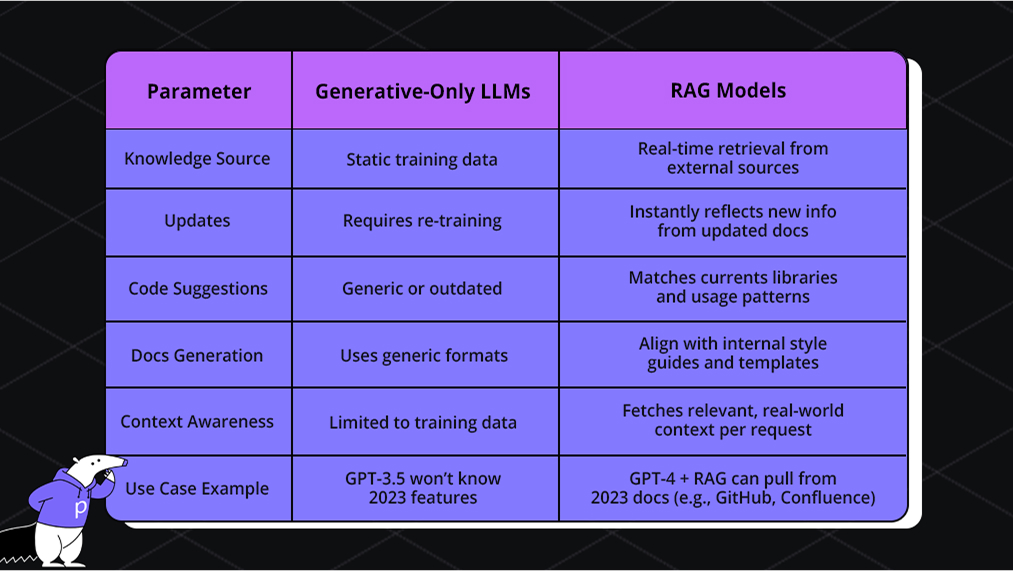
Difference Between Generative-Only LLMs and RAG Models
We have explained how RAG works. Now, let’s look into how it differs from generative-only LLMs. Traditional LLMs, like earlier versions of GPT, no matter how strong, are limited by their fixed training data, with knowledge that doesn’t update after a certain cutoff date.
For example, OpenAI’s GPT-3.5 model trained in 2022 won’t know about libraries, security patches, or architecture patterns introduced in 2023 unless it’s fine-tuned again, which is a time-consuming and resource-heavy task. Here, RAG proves to be helpful by fetching information in real-time and keeping up-to-date.
Some might ask: LLMs now have very large context windows, so why not just feed the entire codebase into the model and retrieve answers from that? Why use RAG at all? The answer lies in three key areas:
- Pre-processing: RAG systems can transform code into more digestible representations before feeding it into the model. This helps improve reasoning, as the model doesn’t need to parse everything from scratch.
- Order Matters: RAG doesn’t just retrieve relevant snippets; it also structures them meaningfully. For example, it can place related functions, definitions, and comments next to each other so that the model understands the flow better. This is better than raw code being dumped into a huge window with no prioritization.
- Solving the Relevance Overload Issue: Even if an LLM can process up to 100,000 tokens, only a fraction may truly matter to your query. It’s like trying to find a needle in a haystack, possible but time-consuming and inefficient. RAG filters out the noise by retrieving only what matters, helping the model focus on precise, relevant information.
Here’s an illustration for ease:
Why Does RAG Matter to Developers?
As an ML engineer, I have addressed a major drawback of using LLMs. They’re stuck with whatever information they were trained with, also known as the ‘knowledge cut off’ problem.
LLMs can’t access anything new after that point. This results in the AI delivering confident answers that are outdated or factually incorrect. Moreover, when AI-focused developers solely depend on LLMs, they might rely on these answers, which can seriously affect code quality and even introduce security risks.
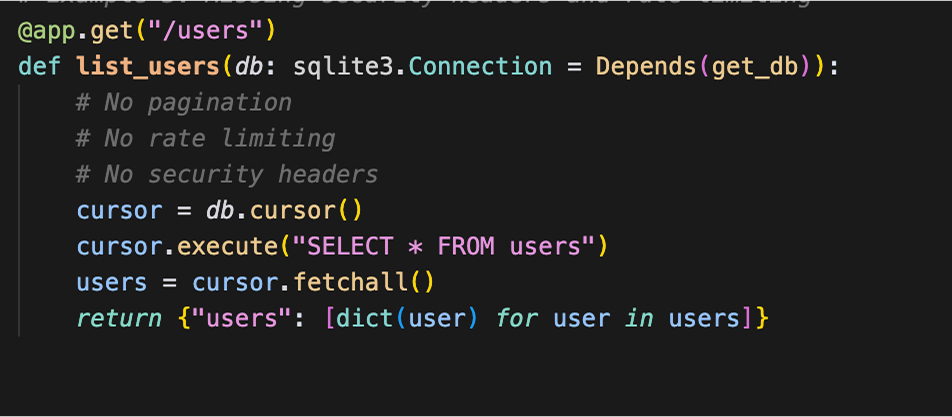
For example, I created a FastAPI endpoint in the above code that creates a new user and generates a new user ID. It then stores the user data and returns a success message with the new user details.
I have intentionally missed rate limiting and security headers. The code may be working fine for small-scale projects. However, this mistake opens it up to several vulnerabilities. An attacker could easily:
- Make thousands of requests per second to
/usersendpoint - Exhaust server resources
- Cross-Site Scripting (XSS)
- MIME-type sniffing
- Cross-Origin Resource Sharing (CORS) issues
How does RAG Improve Code Quality?
We are now well aware of what is RAG in AI. But how does it help with code quality? What difference does it make, unlike LLMs? Let me list down a few points to make you understand how RAG models make code quality better:
1. Contextual Access to Source-Controlled Code and Docs
Retrieval augmented generation combines real-time retrieval with generation to provide context-aware outputs. It can pull updated data from tools like GitHub, Swagger, and Notion, and then rank or filter that information before using it to generate responses. It uses these tools to provide recommended actions based on the current source code to maintain reliability.
2. Enforcing Internal Standards Automatically
RAG lets you define project rules against style guides, linting tools, and architectural standards to give teams real-time standard suggestions during code development. Developers get real-time suggestions that follow team conventions, reducing the risk of non-compliant code and easing the code review process.
Use Case: Code Generation With and Without RAG
So far, we have seen how RAG can improve code quality. To understand even better, I want you to go through an example I recently implemented while working on one of my codebases.
Here, I will be comparing the same code creation with a usual LLM like ChatGPT and then Qodo Merge, which has an inbuilt RAG pipeline that gets customized to our domain, data, and preferences, and can deliver significantly more accurate and context-aware results.
I started with a mock codebase that mimics common practices within our internal projects. These utility files are part of the core backend functionality and are designed to ensure that logging and validation are consistent across all requests and responses in the system.
The task I was aiming to accomplish was to generate a FastAPI middleware that:
- Logs each incoming HTTP request using our internal logging mechanism
(log_request()). - Validates the JSON body of
POSTrequests using the existing validation logic(validate_request()).
This is a common use case in our codebase. I wanted to automate the generation of this middleware code while ensuring it used the already established functions from the codebase. This would save time and keep the code consistent.
To generate the code, I used the following prompt, which I fed into both a standard LLM (like ChatGPT) and Qodo:
“Generate a FastAPI middleware that logs each incoming request and validates the JSON body using internal utilities.”
This prompt clearly outlined the high-level requirements for the code, including:
- Logging: The middleware should log the incoming request.
- Validation: The middleware should validate the incoming JSON body against predefined models.
Code Generation Without RAG (Standard LLM)
To generate the code, I initially turned to ChatGPT, a popular LLM. I used the same prompt as mentioned above.
I got the following output:
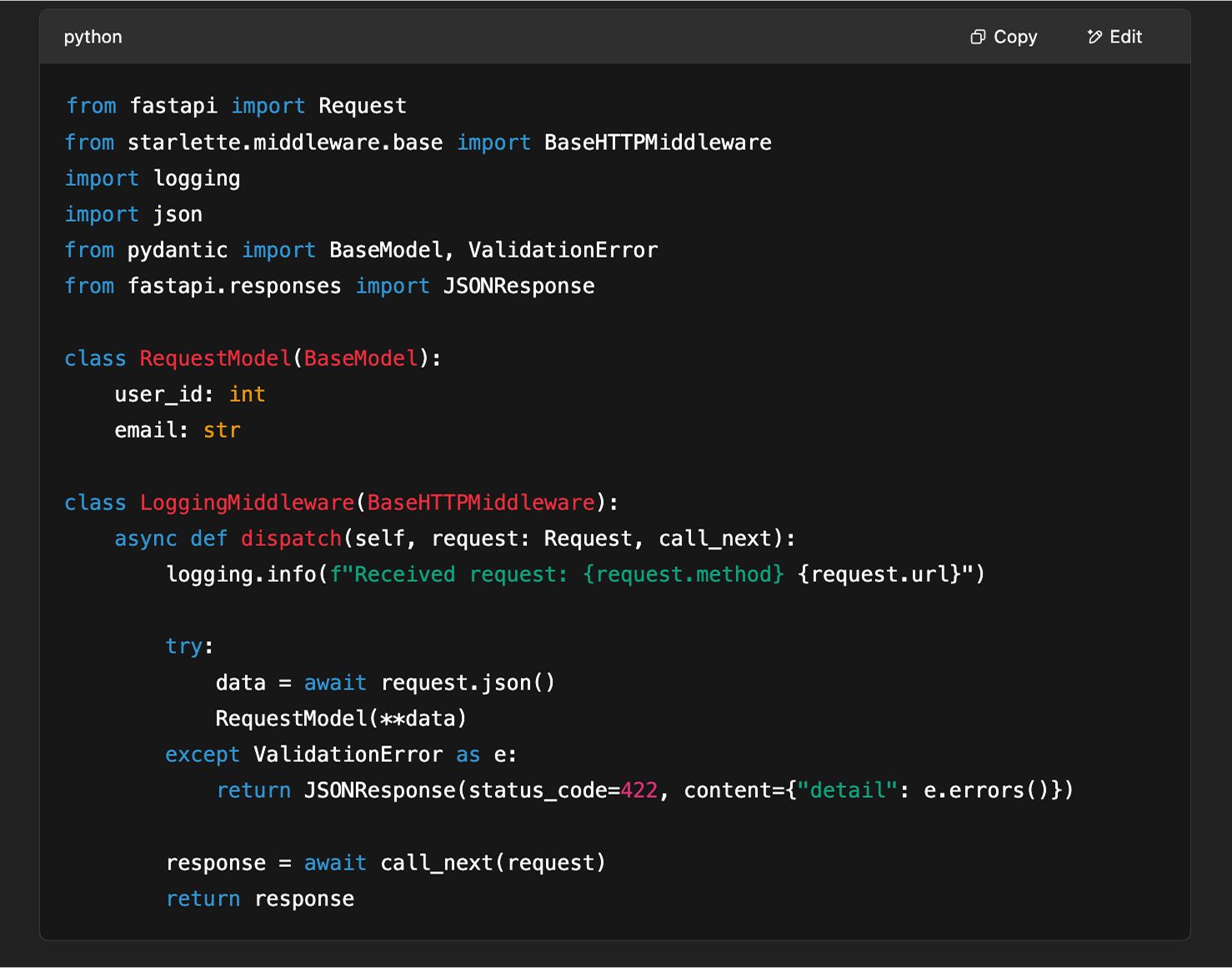
While the code generated by ChatGPT was functional, it had several issues:
- It did not use our internal
log_request()andvalidate_request()functions that are part of our established utilities. - Instead of using the pre-built utilities, ChatGPT re-implemented the logic for logging and validation from scratch.
Also, the generated code re-implemented the logging and validation logic, which I already had in place. And it’s obvious that an LLM won’t be aware of my internal practices or standards, as it didn’t use our existing, standardized functions. This made it harder to integrate into my existing codebase and added unnecessary complexity.
Code Generation With RAG (Using Qodo)
After facing the issues with generating code without utilizing our internal utilities, I turned to Qodo’s RAG (Retrieval-Augmented Generation) pipeline.
When I used Qodo, I simply uploaded our mock codebase, which included the log_request() function from logging.py and the validate_request() function from validation.py. Qodo’s RAG-powered system was able to retrieve the relevant context from my codebase and integrate those functions into the generated middleware automatically.
I used the same prompt as before, as seen in the image below:
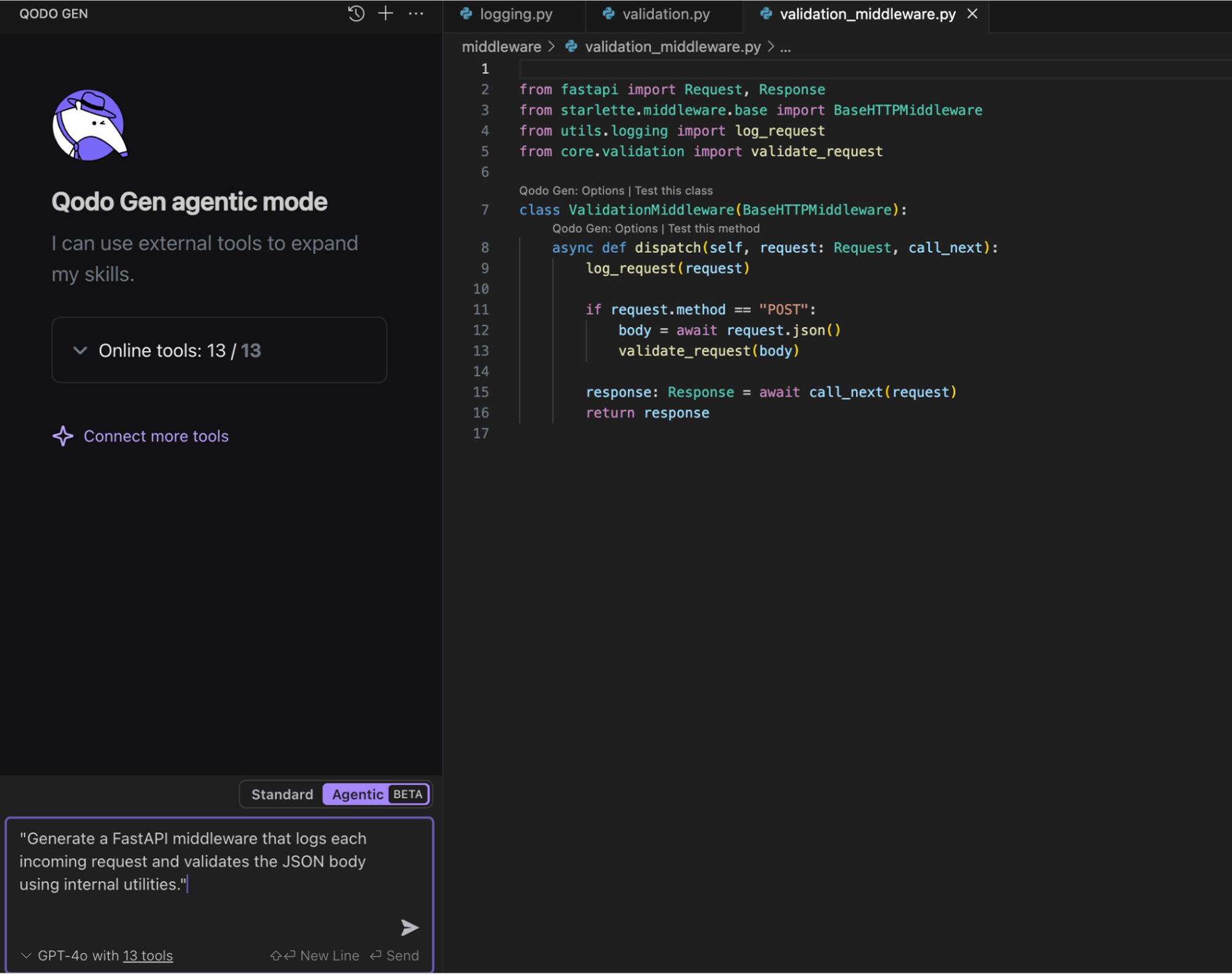
But this time, I was quite impressed as Qodo intelligently pulled in the functions from my codebase, ensuring the generated code was perfectly aligned with my existing structure and standards.
Here is a snapshot of what Qodo created with its built-in RAG pipeline:
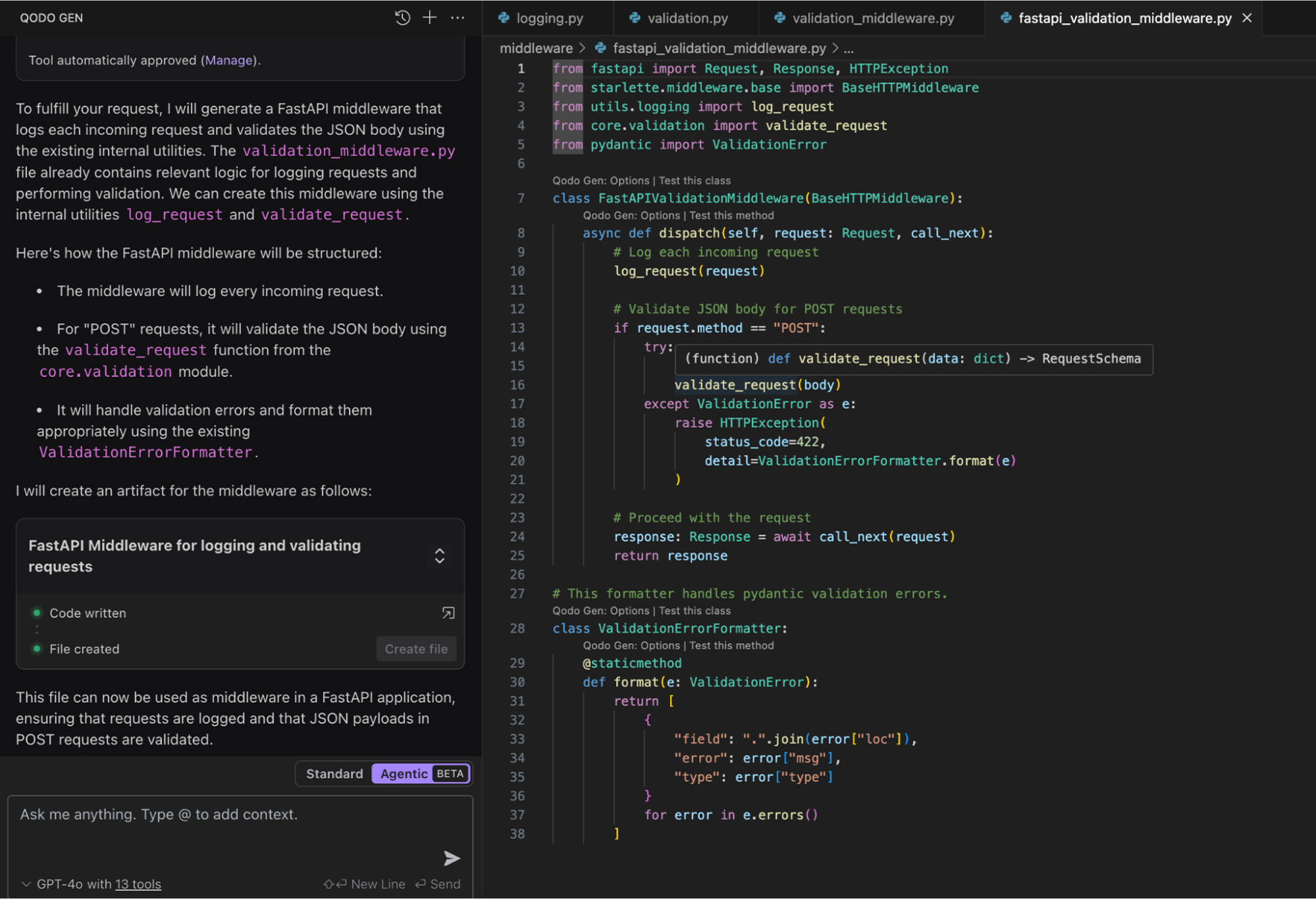
First of all, unlike the standard LLM (ChatGPT), which re-implemented the logic, Qodo’s RAG retrieved and reused my existing functions (log_request() and validate_request()). This meant that there was no need for me to rewrite or replace code, and the result was consistent with our internal standards.
Plus, with RAG, the generated code was simpler and avoided duplication, making it much easier to maintain.
Qodo operates by searching the existing codebase and using context from your project to inform code generation. So, using Qodo helped me get the functionality I needed, but in a way that was much more efficient, accurate, and consistent with our internal standards.
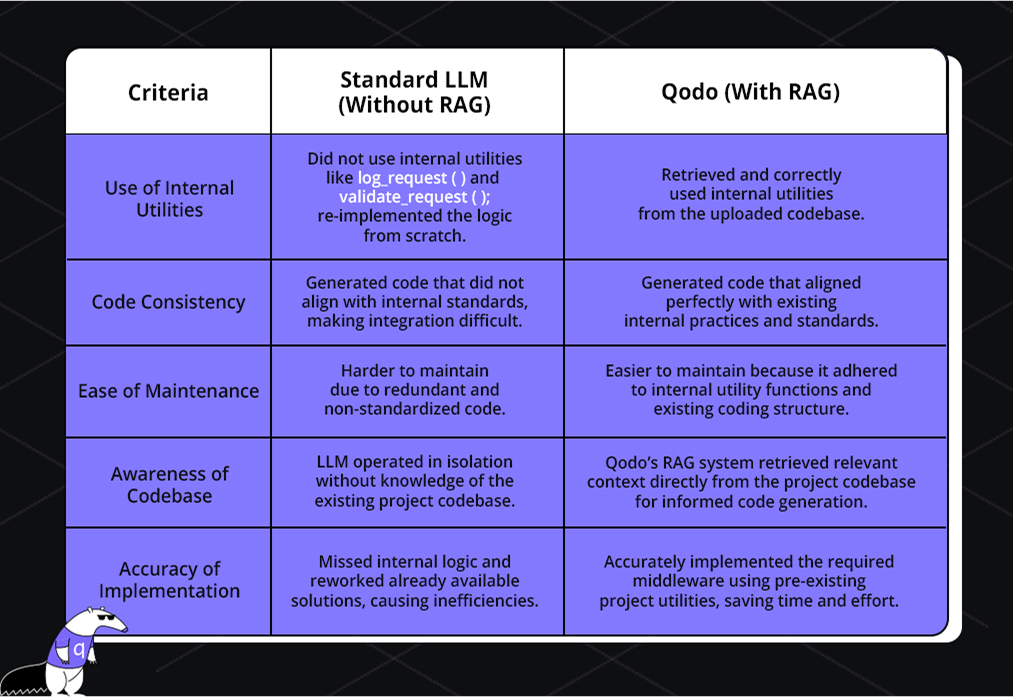
Here’s a comparison to go through what was missing in an LLM and how RAG helped it to improve:
How To Use RAG in Qodo Merge?
By now, you would have understood how RAG benefits your code quality and reduces that extra load. But for some reason, if your RAG is not enabled in Qodo Merge, let me give you a small brief on how you can do that.
Suppose I am using the same prompt that generates a FastAPI middleware. Now, to enable RAG within the Qodo Merge workflow, I introduced two parameters:
- enable_rag=true: This enables RAG functionality.
- rag_repo_list=[“my-org/my-repo”, …]: This parameter defines which repositories should be included in the search scope for code references.
Once configured, the AI could analyze pull requests (PRs) with a deep awareness of the repository’s architecture, coding standards, and patterns. This made the review process more efficient and accurate, ensuring that suggestions were syntactically correct and aligned with the project’s established practices.
Additionally, with RAG, I could retrieve relevant code examples directly from the codebase, enhancing the quality of the review process and reducing the manual effort involved in identifying patterns across large codebases.
Challenges with RAG: What to Watch Out For
There are a few challenges that you need to look out for. RAG can significantly boost the performance of LLMs, but it’s not a silver bullet. Like any system, it comes with its own challenges that are mostly tied to the quality and accessibility of the data it relies on. Here are a few of them that I have encountered in my experience:
1. Data Quality Matters Most
The result from RAG depends on the reliability of the initial data it receives. Our results depend on the quality of updated, reliable data we input.
2. Chunking Strategic Hell
Poor chunking can often lead to fragmented context and garbage answers. Moreover, there’s never a universal solution – legal docs need chunking that differs from API docs. You often end up reinventing chunking logic tailored to each dataset. This way, you’ll spend hours tweaking chunk size and overlap to improve semantic recall by a few percent.
3. Embedding Drift
Changing your embedding model (e.g., from text-embedding-ada-002 to text-embedding-3-large) can mess up your entire retrieval pipeline. Your old vectors become meaningless, and you have to re-embed everything, which can be costly and time-consuming.
4. Query → Garbage → Retrieval → Garbage
LLMs are only as good as the documents retrieved. If your search is weak (bad embeddings, poor chunking, irrelevant vector hits), your LLM ends up hallucinating or making up answers based on unrelated context.
5. No Feedback Loop
How do I know my RAG is actually helping? There’s rarely built-in observability for RAG quality. You’re often left manually diffing LLM answers with and without retrieval. There’s no easy metric that says, “retrieval improved this answer” or “your context is irrelevant.” You’ll want some kind of retrieval score, but you’ll likely write custom eval scripts.
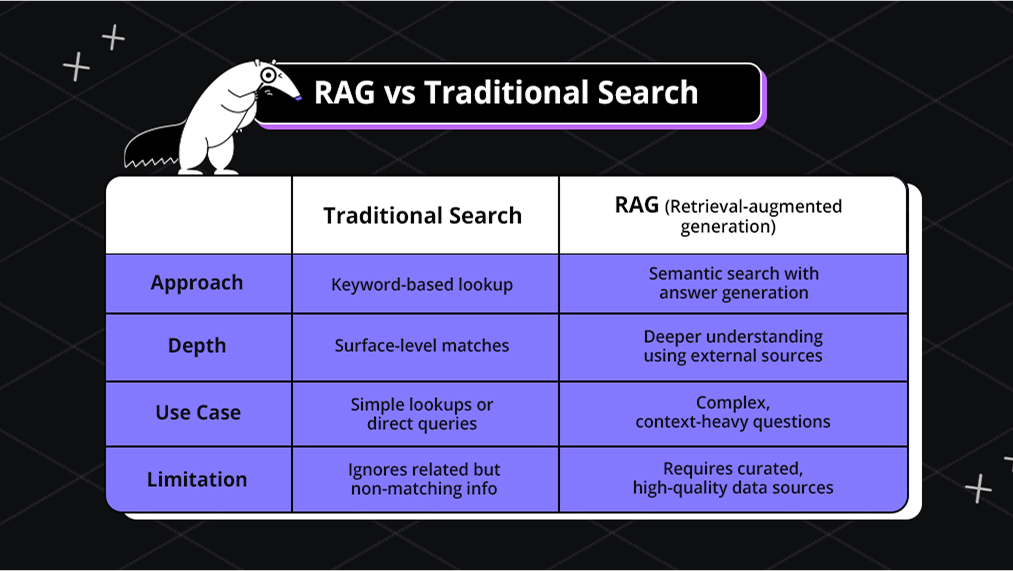
RAG vs Semantic Search
RAG framework and semantic search aim to improve how AI finds and uses information, but they work differently.
Traditional search relies on exact keywords. For example, if we search for “foods native to France,” the model may miss relevant data (like trees in Montpellier) if the exact keywords aren’t used.
Semantic search, however, understands the intent behind a query, analyzing context to return more accurate results, even without matching exact words. This makes it better for nuanced questions.
In RAG, semantic search helps the system pull the most relevant context before generating a response, ensuring the output is more accurate and grounded.
Let’s look at a brief difference between these two:
Why RAG + Qodo Matters for Modern Engineering Teams
When you align RAG with the right agentic flows, it becomes more than just a technical upgrade; it becomes a game-changer for your workflow.
For engineering leads and ML engineers, this means less time spent searching for solutions or debugging and more time focused on building effective, reliable code. RAG pulls in the right resources when needed, helping developers avoid errors and make smarter, real-time decisions.
From my own experience using Qodo, the combination of RAG and a custom development workflow made a noticeable difference. It brought relevant documentation, internal APIs, and real code examples directly into my IDE, no extra searching, no tool-switching, just better decisions faster.
But Qodo’s value goes beyond speed; it’s built to elevate code quality throughout the entire development lifecycle. From code generation and testing to reviews, Qodo ensures continuous quality at every stage.
At the heart of it is this focus on code integrity. Every line benefits from:
- The right context, pulled from sources that matter
- Built-in best practices, so you’re not reinventing standards
- Ongoing analysis that helps you catch issues early and keep improving
I found this quite helpful as it leads to not just better individual contributions but also a more robust and consistent codebase overall. For teams aiming to scale confidently, Qodo helps make quality the default, not an afterthought.
Conclusion
Simply generating code isn’t enough; generating the right code based on relevant context is the game changer. Throughout this guide, we explored how traditional LLMs, though powerful, often fall short when faced with fast-moving codebases, evolving documentation, and project-specific standards.
We reviewed how RAG machine learning models overcome these challenges, delivering real-time, context-aware responses that developers can trust. You can now know when you need a custom RAG pipeline and how to implement it. So, the key takeaway is that RAG isn’t just theory but also practical. It’s time to move beyond generic AI and build with context.
FAQs
What is RAG in AI?
RAG (Retrieval Augmented Generation) combines large language models (LLMs) with external data retrieval to generate context-aware responses in AI systems.
What is a RAG application?
RAG applications use AI models to fetch relevant information from databases and combine it with generated content, improving accuracy and relevance.
What is RAG retrieval?
RAG retrieval refers to fetching relevant data from external sources or databases to improve the quality and accuracy of AI-generated responses.
What are the principles of RAG?
RAG combines retrieval and generation: it retrieves relevant data and uses it to generate more accurate and context-specific content.
What are the advantages of RAG?
RAG reduces hallucinations, keeps answers up to date, and tailors responses to your codebase, tools, and standards, leading to more accurate, secure, and context-aware outputs.


