How to Ship Production-Ready Code When AI Writes 30% of Your Codebase
TL;DR
- AI-generated code can pass unit tests and CI while silently skipping idempotency, retry bounds, and auth checks, the gaps that cause production incidents, not test failures
- Production-ready code defines behavior under failure: retries, 503s, duplicate requests, and dependency outages, not just the success path tests cover
- Pull request reviews show a single diff, not how a change behaves across services, missing rollback risks, broken API contracts, and retry storms that only flag under live traffic
- This post covers the 8 requirements every PR must meet before merge, 3 failure patterns that pass review and break in production, and how Qodo uses full codebase context to flag these risks before deployment
AI-generated code should not be shipped to production without additional checks, and in the reviews I handle as an SDE3, this comes up on almost every PR. A change passes tests and behaves correctly in isolation, but CI doesn’t tell you whether the function retries safely on a 503, enforces idempotency on duplicate requests, or avoids logging a sensitive identifier. Those gaps don’t appear in the unit test output. They get flagged in production when a 503 triggers a retry loop or a duplicate request charges the same card twice.
In review, I focus on how a change behaves when it interacts with other services and runs under conditions no test environment replicates, not just whether it returns the expected output.
The difference between working code and production-ready code is whether it defines behavior under failure. Working code produces the expected output in a test. Production-ready code defines what the system does when those conditions are no longer controlled.
What Makes Code Production-Ready? 8 Requirements Every PR Must Meet
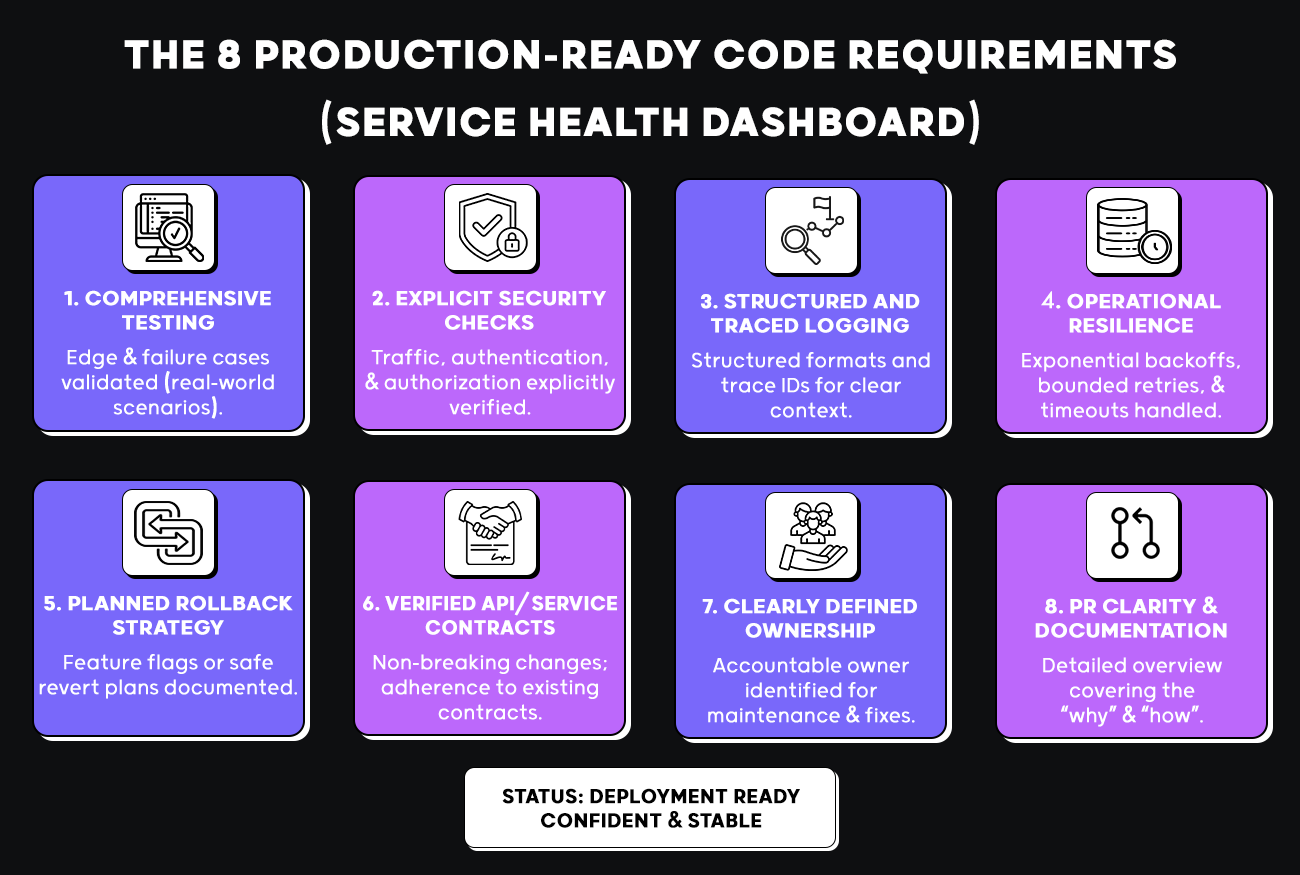
Code is production-ready when it can be deployed without breaking downstream consumers, handle expected request volume without exhausting memory or connections, recover from dependency failures without cascading failures, and be debugged by an engineer who didn’t write it.
This doesn’t happen automatically. Writing code that works is only the first step. You also need to ensure the change won’t break a consumer that depends on an enum value you renamed, return sensitive fields in an API response that wasn’t filtered, exhaust a downstream queue under retry load, or require a database restore to undo.
Here are the checks that determine whether a change is actually ready to ship in production:
| # | Requirement | What breaks without it |
| 1 | Tests define behavior for failures | Retry loops run silently, duplicate requests charge customers twice |
| 2 | Access control and input validation enforced at runtime | Unauthenticated callers get responses, malformed input reaches the database |
| 3 | Failures logged with enough context to debug | On-call engineers can’t trace incidents, real alerts get dismissed as noise |
| 4 | Retries, timeouts, and resource usage bounded | Retry storms exhaust downstream connection pools, threads block indefinitely |
| 5 | Changes safe to roll out and easy to roll back | Broken logic can’t be disabled without shipping a fix or restoring backups |
| 6 | API and data contracts remain compatible | Consumers break silently on renamed enums, dropped fields, or changed types |
| 7 | Pull request establishes ownership | First production incident means reading unfamiliar code under pressure |
| 8 | Pull request clearly explains the change | Reviewers miss risks when intent has to be reverse-engineered from the diff |
1. Tests Must Define Behavior for Failures
Tests Must Define Return Values for Dependency Failures, Retries, and Duplicate Requests. Before merging, tests must define how the code behaves when inputs are missing, when a dependency returns an error, and when an operation is executed more than once. This means tests should verify:
- What the function returns when the required data is missing or invalid
- how it handles a failure from an external service (for example, an error response instead of success)
- whether retries stop after a defined limit instead of continuing indefinitely
- whether the same request can be executed multiple times without changing the result more than once
When the charge(orderId, amount) function was updated in a payment service PR, Qodo generated tests as shown in the snapshot below:
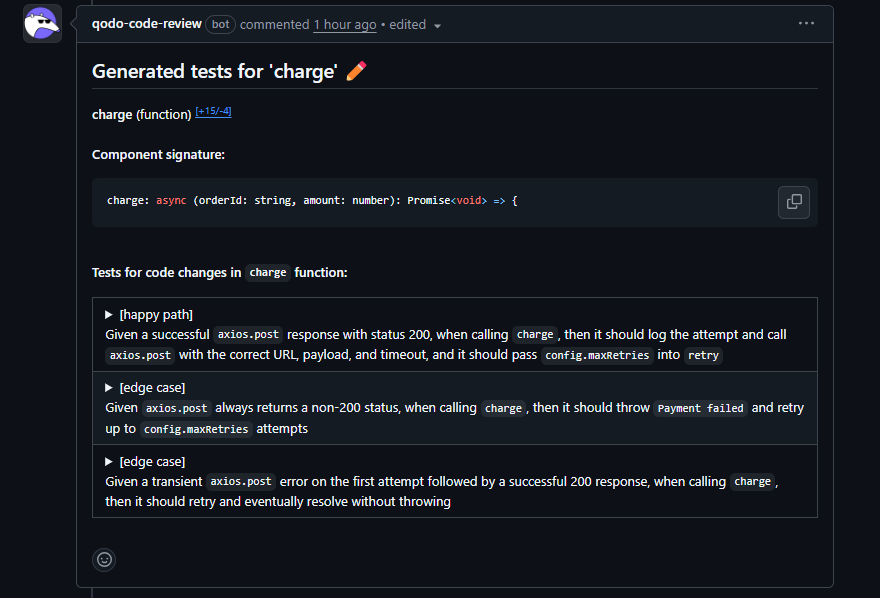
These tests covered all three of these conditions directly in the pull request:
- Happy path: confirms the function calls the correct endpoint with the right payload, timeout, and retry configuration
- Persistent failure: verifies that when axios.post keeps returning a non-200 status, the function retries up to config.maxRetries and then throws Payment failed instead of looping silently
- Transient failure: validates that a single failed attempt is retried and the operation resolves without throwing when the downstream service recovers
These tests do not just confirm the success path. They define the contract for how the function behaves under retry limits and partial failures, the conditions that determine whether it is safe to run in production.
Without these checks, a retry loop runs until it crashes a downstream queue, and a duplicate request charges a customer twice; neither failure appears in CI. Defining failure behavior in tests catches what code does under bad conditions. But tests can’t catch what’s missing from the runtime path, checks that only exist if someone put them there.
2. Access Control and Input Validation Must Be Enforced at Runtime
A change is not production-ready if access control and input validation are not enforced along the request-handling path. These checks must run in the request handler itself, not assume that a load balancer will block unauthenticated traffic, or that a trusted internal network means callers don’t need to be verified
This means the code must verify:
- that every endpoint checks the identity of the caller and enforces permissions before returning data
- that request inputs are validated for required fields, types, and allowed values before processing
- That response objects exclude sensitive fields by default, returning only what the caller is authorized to receive.
- Request handling does not depend on assumptions about infrastructure (for example, trusting client IPs without validating proxy headers)
Middleware ordering is one place where this breaks silently. In a PR that added rateLimit middleware to an API gateway, Qodo flagged that app.use(rateLimit) was registered after app.use(routes), meaning every request reached the route handlers before the rate limiter ran. Here’s how:
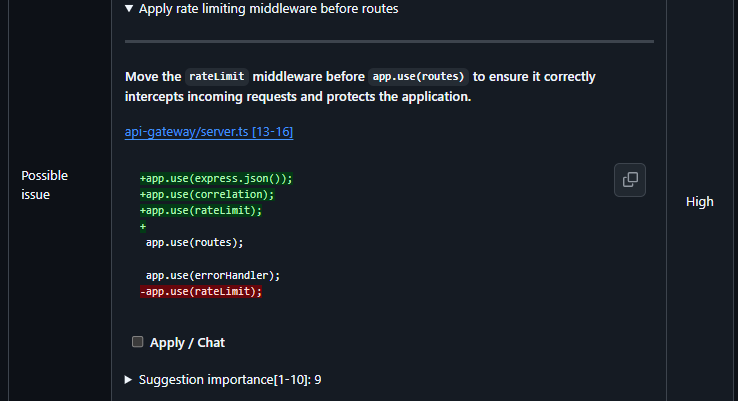
The fix was a single reorder, but without it, every request reached the route handlers first, rate limiting ran after the response was already being processed, so the check never blocked anything. Qodo rated this a 9 out of 10 severity, not because the code was syntactically wrong, but because the ordering meant the security check never executed in the path it was meant to protect.
When requireAuth runs after routes, or when rate limiting reads req.ip without accounting for X-Forwarded-For, a request from an unauthenticated caller gets a response, malformed input reaches the database, and every client behind a load balancer appears as the same IP, triggering rate limits for one user and allowing bypass for all others. The next requirement covers how failures on these paths must be reported when they occur.
3. Failures Must Be Logged with Enough Context to Debug in Production
Failures must log the Request ID, Error Reason, and Operation Name, so On-Call Engineers Can Trace Incidents Without Guessing. When code runs in production, the only way to understand what happened is through the data it records at runtime.
Production-ready code includes:
- log failures with identifiers such as request ID, user ID, or job ID so the event can be traced
- record the reason for failure (for example, error response, timeout, or validation failure) instead of a generic error message
- distinguish between success and failure correctly (for example, treating all 2xx responses as success instead of only 200)
- emit metrics for error rates, latency, or retries so abnormal behavior is visible
If failures are misclassified or reported incorrectly, on-call engineers dismiss real alerts as noise, retry logic fires on successful operations, and payment failures go undetected until a customer reports a missing charge.
For example, as shown in the comment below:
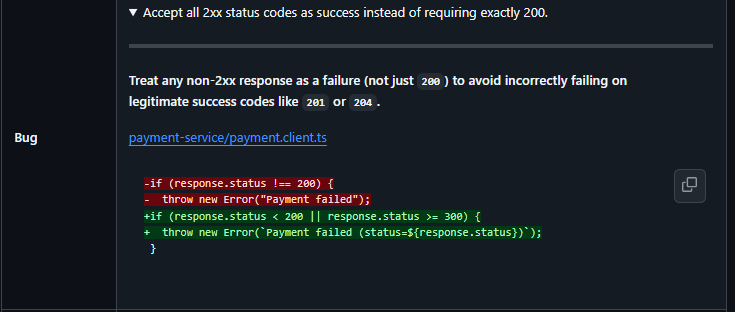
Qodo flagged that the payment client treated only a 200 response as a success, causing legitimate success responses such as 201 or 204 to be incorrectly treated as failures. This would trigger unnecessary retries and misleading error signals in production.
By recommending acceptance of all 2xx status codes and surfacing the exact failure condition, Qodo helps ensure that errors reflect failures, not incorrect assumptions, making logs, alerts, and retries far more reliable in production.
4. Retries, Timeouts, and Resource Usage Must Be Bounded
Any change that processes data, loops over a large dataset, or makes new network calls should be reviewed for:
- Timeouts, retries, and backoffs
- Bounded memory or queue usage
- Error handling when dependencies are slow or fail
Code that assumes everything will be fast and correct will spin a retry loop until it exhausts the downstream service’s connection pool, or block a thread pool waiting on a dependency that has already timed out.
For example, when retry logic was added to a payment client, Qodo flagged that the code retried every error the same way.
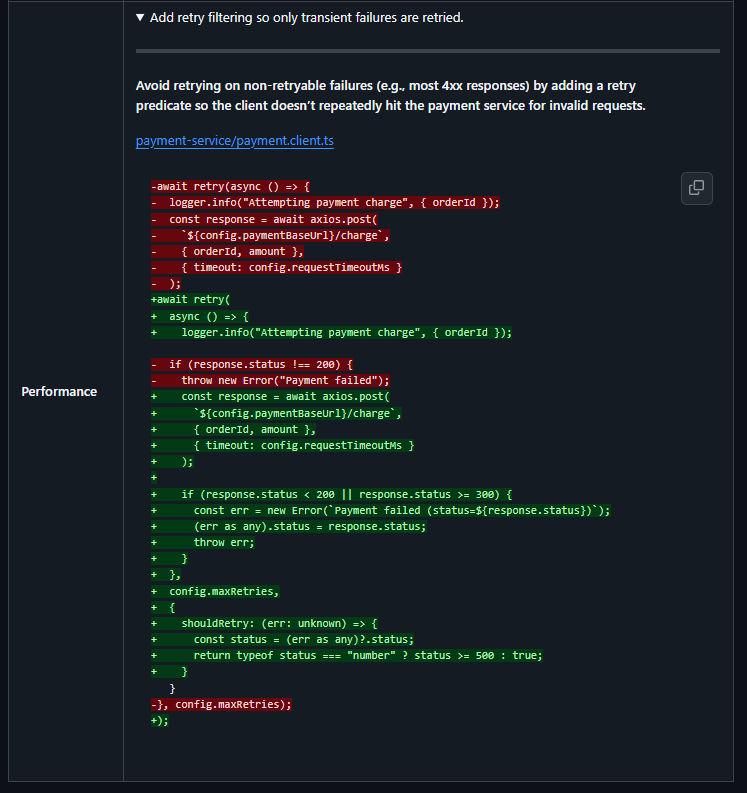
This meant the service would retry requests even when the error could never be corrected, such as invalid input or authorization failures.
Qodo suggested changing the retry logic so that:
- Retries happen only for temporary failures (like network issues or server errors)
- Invalid requests fail immediately instead of being retried
- Downstream services aren’t hit repeatedly with requests that are guaranteed to fail
Skipping retries for 400 and 401 errors stops the payment service from hitting the charge endpoint repeatedly with requests the server will always reject, avoiding a thundering herd when input validation fails at scale.
5. Changes Must Be Safe to Roll Out and Easy to Roll Back
A production-ready change includes a plan for rollout and a way to reverse it:
- Feature flags or config toggles for new logic so behavior can be disabled without redeployment
- Schema changes that remain backward-compatible, new columns nullable by default, no removed fields without a deprecation window
- A rollback plan that doesn’t involve restoring backups manually or coordinating emergency deploys across multiple services
- Database migrations that can be reversed, if a migration drops a column or changes a type, the previous version of the code must still run against the new schema
If a change can’t be disabled quickly when something goes wrong, it’s not safe to release.
The most common rollback failures come from two patterns. The first is a migration that is not reversible, a column is dropped, an enum value is removed, or a NOT NULL constraint is added before all consumers stop sending null. The second is a feature that writes to a new schema without a flag, meaning the only way to stop the behavior is a full revert and redeploy.
A safe rollout separates the deploy from the activation. The code ships first, the flag allows the behavior, and the migration runs only after both old and new versions can coexist on the new schema. This is the pattern that makes rollback a one-step flag flip instead of a coordinated incident response.
6. API and Data Contracts Must Remain Compatible with Existing Consumers
When a change touches a shared API, schema, or contract, it must remain compatible with existing consumers or be rolled out in coordination. This includes:
- Not adding required fields that older clients don’t send
- Not changing enum values or response types unexpectedly
- Versioning the API if compatibility can’t be guaranteed
Renaming an enum value or making a previously optional field required breaks any consumer that hasn’t deployed the corresponding update, causing deserialization failures, dropped requests, or silent data corruption in services that haven’t been redeployed yet.
For example, Qodo flagged problems where the API itself didn’t change, but how it was used did. In the payment client, the code treated only a 200 response as success. Many APIs return other valid success responses, such as 201 or 204. Treating those as failures causes the client to behave incorrectly, even though the server did nothing wrong. As visible in the PR comment below:

Qodo also flagged that retrying a payment request without enforcing idempotency changes the behavior of the /charge endpoint. A retry can result in the same charge being processed multiple times, breaking assumptions made by downstream systems.
In both cases, the API shape stays the same, but the behavior changes. Double charges and misclassified success responses are easy to miss in review because nothing in the diff shows the downstream effect, they get flagged in production when a retry fires on a completed charge.
7. The Pull Request Must Establish Ownership
Production-ready code can be debugged by an engineer who didn’t write it. That means following the team’s module structure, naming functions after what they do (charge_with_idempotency_key, not process), and placing new jobs or workers where the alerting and ownership config already exists.
If nobody understands it after the merge, the first production incident means reading unfamiliar code under pressure, without context on why decisions were made or which edge cases were also tested.
8. The Pull Request Clearly Explains the Change
The pull request should explain:
- What changed
- Why it changed
- Any impact on other systems
- How the change was tested
If reviewers have to reverse-engineer intent from the code, the risk of missing something important increases. For example, when asked to summarize the changes in this pull request, Qodo generated a clear, structured overview that covered:
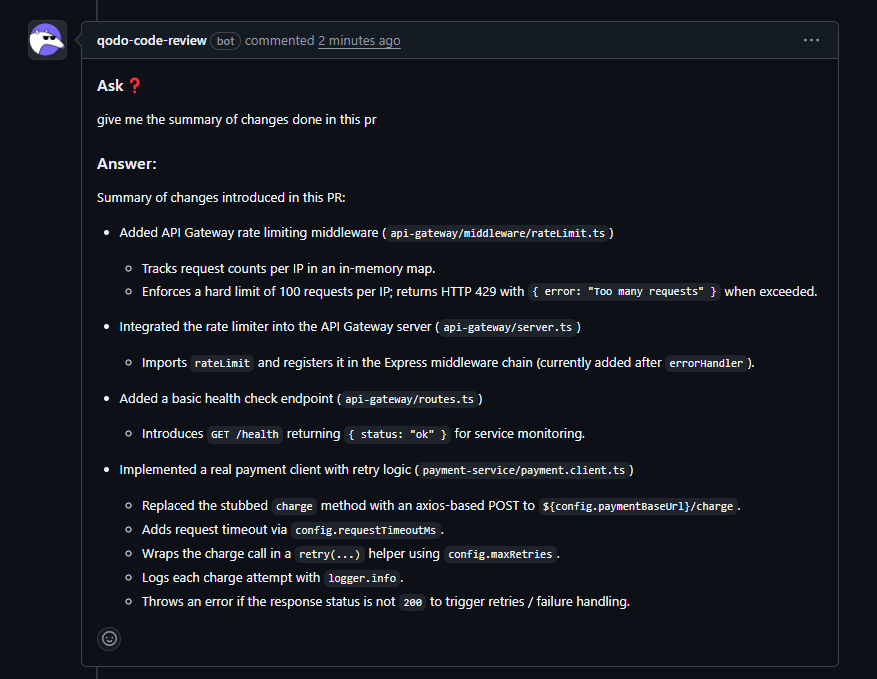
The above summary clearly highlights the changes introduced in the PR, helping reviewers quickly understand the scope and intent before going into further implementation details.
Why Code Review Is Not Enough for Production Readiness
Code review is valuable. Engineers use it to check logic, spot edge cases, and ensure a change makes sense. But with the way software is built today (especially with AI writing more of the code), reviews aren’t enough to guarantee production-readiness.
| What code review catches | What code review misses |
| Logic errors and incorrect output | Whether retries are safe under real failure conditions |
| Missing edge cases in the diff | How a change behaves across dependent services |
| Style and naming inconsistencies | Whether the same request can run twice without side effects |
| Obvious security issues in the changed file | Middleware ordering that silently bypasses auth |
| Incorrect function signatures | Whether an enum rename breaks a consumer in another repo |
| Missing tests for the happy path | Whether retry logic will exhaust a downstream queue under load |
“The problem is context. A reviewer sees one diff in one repo, not which services call that function, not whether the change reintroduces a pattern that caused a prior incident, and not whether a flag flip in production will trigger a retry storm.”
AI Ships Code That Passes Tests and Skips the Checks That Matter in Production
AI-generated code produces functions that look syntactically clean and pass tests, but the model has no awareness of your service’s idempotency requirements, your logging standards, or which endpoints require auth, so those checks are silently absent. The code might look clean and even pass basic tests, but it can silently skip critical behavior:
- No auth checks in exposed endpoints
- No fallback or retries in background jobs
- Logs with missing context or leaked identifiers
- Data flowing across services without validation
These gaps don’t trigger CI failures. They get flagged when a retry fires on a completed payment, when a background job runs without the caller’s identity and skips an auth check, or when an endpoint returns a token in an error log that ends up in Splunk. These are the kinds of changes that don’t break anything right away, but fail later (during a real deployment, in an edge case, or under real traffic).
Reviewers See One Diff, Not the Services That Depend on It
The problem is context. A reviewer sees a pull request in isolation, just one diff, in one repo. They usually can’t see which other services call that function, what happens if a flag is flipped in production, or whether the change reintroduces a pattern that caused problems before.
Production readiness depends on a lot more:
- Do retries have backoff?
- Can this feature be rolled back?
- Are downstream consumers aware of the schema change?
- Is this endpoint exposing sensitive data in logs?
Without a system that answers these questions automatically, the check depends on whether the assigned reviewer happens to know the service’s retry contract, has seen the downstream consumer list, and is not under deadline pressure, none of which is guaranteed on any given PR.
Qodo’s Context Engine Connects Every PR to the Codebase It Lives In
Qodo’s Context Engine solves the reviewer context gap, connecting every PR to the repos, service contracts, and call chains it affects, rather than analyzing the diff in isolation. It indexes your full codebase, maps which services call which functions, and checks each PR against that dependency graph, flagging when a change in one repo breaks a contract in another.
When a PR is opened, it doesn’t just run lint and tests. It also checks whether a migration has rollback risk, whether a helper skips validation, or whether an API change affects 12 downstream services. It can tell if your AI-generated function silently introduces a broken access pattern or skips a logging guardrail your org requires.
That analysis runs on every PR across around 10 repositories, or 1,000, without requiring a senior engineer to manually trace the dependency graph before approval.
3 Code Patterns That Pass CI and Break in Production
The following three patterns are short, readable, and pass all tests. Each one causes a production incident, not because the code is syntactically wrong, but because it was not built for the conditions it runs under: retries, downstream failures, rollback requirements, and access control.
Pattern 1: Payment Handler That Works, But Fails in Production
Before: Looks Fine, But Fails
def charge_order(order_id, payment_info):
order = db.get_order(order_id)
if order.status != "PENDING":
return {"error": "invalid_state"}, 400
result = payment_gateway.charge(payment_info, order.total)
if not result.success:
return {"error": "payment_failed"}, 402
order.status = "PAID"
db.save(order)
notify_warehouse(order.id)
return {"status": "ok"}, 200
This code breaks because:
- No idempotency: If this endpoint is retried (user refreshes during payment), the card might be charged twice
- No recovery plan: If db.save() fails after charging, the customer pays, but the order stays PENDING
- Synchronous side effect: notify_warehouse() runs in-process; if that service is down, the whole order silently breaks
- No observability: There’s no trace or logging to debug what happened
After: Production-Ready Version
def charge_order(order_id, payment_info, idempotency_key):
if is_duplicate(idempotency_key):
return {"status": "already_processed"}, 200
order = db.get_order(order_id)
if order.status != "PENDING":
log_event("invalid_state", order_id=order.id)
return {"error": "invalid_state"}, 400
try:
result = payment_gateway.charge(payment_info, order.total)
if not result.success:
log_event("payment_failed", order_id=order.id)
return {"error": "payment_failed"}, 402
order.status = "PAID"
db.save(order)
outbox.enqueue("warehouse.notify", {"order_id": order.id})
log_event("payment_successful", order_id=order.id)
mark_idempotent(idempotency_key)
return {"status": "ok"}, 200
except Exception as e:
log_event("payment_exception", order_id=order.id, error=str(e))
return {"error": "server_error"}, 500
Why this version is production-ready:
- Uses an idempotency key to avoid double charges if retried
- Logs each important step so issues can be traced
- Moves notify_warehouse to an outbox pattern, so downstream failures don’t block the order
- Wraps the whole process in a try-except block to catch unexpected errors
This pattern directly violates Requirement 1, without tests that define behavior for retries and duplicate requests, a double charge ships to production undetected.
Pattern 2: Feature That Works, But You Can’t Roll It Back
Before: Hardcoded Launch Logic
export function calculateDiscount(user: User): number {
if (user.segment === 'enterprise') {
return user.contractValue * 0.15;
}
return user.contractValue * 0.10;
}
What’s missing:
- No runtime flag; once deployed, this logic is live for all enterprise users
- No rollback path if the math is wrong or business rules change
- No tracking or metrics to see how the new logic is behaving
After: Safe Rollout With Runtime Control
export function calculateDiscount(user: User): number {
if (isFeatureEnabled('new_enterprise_discount') && user.segment === 'enterprise') {
logMetric('discount.new_enterprise_applied', { userId: user.id });
return user.contractValue * 0.15;
}
return user.contractValue * 0.10;
}
Why this version is production-ready:
- The logic is behind a feature flag, so it can be turned off without shipping a fix
- Metrics log when the new logic is used; if something goes wrong, you know where to look
- The change is now safe to roll out gradually, test in real conditions, and turn off if needed
This pattern directly violates Requirement 5, hardcoded logic with no flag means the only rollback path is an emergency redeploy, not a one-step flag flip.
Pattern 3: AI-Generated Utility That Skips Auth
Before: AI-Generated Helper That Works, But Leaks
export function calculateDiscount(user: User): number {
if (user.segment === 'enterprise') {
return user.contractValue * 0.15;
}
return user.contractValue * 0.10;
}
What’s missing:
- No authentication check; any user could call this and fetch someone else’s data
- No authorization; admin vs. regular users aren’t distinguished
- No field-level filtering; sensitive fields (email, phone, tokens) are returned by default
- No audit logging; you don’t know who accessed what, or when
After: Locked Down and Traceable
export function calculateDiscount(user: User): number {
if (isFeatureEnabled('new_enterprise_discount') && user.segment === 'enterprise') {
logMetric('discount.new_enterprise_applied', { userId: user.id });
return user.contractValue * 0.15;
}
return user.contractValue * 0.10;
}
Why this version is production-ready:
- Checks who’s allowed to access what, and avoids open data exposure
- Limits returned fields to only what’s necessary
- Adds an audit trail to track access in case of incidents or reviews
This pattern directly violates Requirement 2: access control and field-level filtering must be enforced in the request handler itself, not assumed from infrastructure or caller trust.
How to Enforce Production Standards Across Every PR Without Relying on Manual Review
By this point, it’s clear that individual pull requests (no matter how carefully written or reviewed) can’t guarantee production safety. The assurance comes from how the entire system is configured to catch issues before they reach production.
This means readiness can’t be a checklist inside someone’s head or buried in a Notion doc. It has to be built into your tooling and enforced across every change.
CI Gates Must Reject the PR When Auth Checks, Tests, or Secret Scanning Don’t Pass
Every pull request should be checked for basics automatically:
- Are there tests for this change?
- Are secrets or credentials leaking into source code?
- Are permissions, auth checks, and validation present?
These aren’t review tasks; they’re preconditions. Your CI should fail if these aren’t met.
A Change That Looks Small Locally Can Break a Consumer in a Separate Repo
A change might look small locally, but affect shared modules, types, or APIs used across services. You need systems that trace those connections across the whole codebase and flag risk early.
Example: A renamed enum in one repo silently breaks another service’s integration test, but no one knows until after deployment.
Risk Scoring Routes the Right Reviewer to the Right Change
Not all changes need the same level of scrutiny. A typo fix in comments? Low risk. A change to how auth tokens are issued? High risk.
Good systems assign risk scores based on change type, affected areas, and system impact, and route reviews accordingly.
Every PR Must Record Who Owns It, What It Changes, and Who Approved It
Every PR should answer:
- What ticket is this tied to?
- What behavior is changing?
- Who signed off on it?
And once approved, you should be able to trace: Who approved it, what was flagged, what got overridden, and why.
Audit Trails Make the Next Incident Cheaper Than the Last One
If something fails in production, you should be able to trace the decision path:
- Was this warning ignored?
- Was a risky area modified without the right reviewer?
- Was a policy skipped or overridden?
These aren’t just useful for postmortems; they’re how you build systems that don’t repeat the same mistakes.
How Qodo Flags Production Risks During Code Review
Qodo is an AI code review platform that analyzes each PR against the full codebase it lives in, not just the diff. When a PR touches a shared function, a public API, or a database schema, Qodo maps which other services depend on that change and flags risks before merge. A renamed enum, a changed response type, or a removed field gets caught at the PR stage, not after the consumer service starts throwing deserialization errors in production.
Qodo Gives a Direct Answer on Whether a PR Is Ready to Ship
For each pull request, Qodo analyzes the diff in the context of the wider codebase and applies production-readiness checks across security, reliability, deployment safety, and operability.
When asked directly whether a change is production-ready, Qodo provides a clear answer and explains the rationale. As shown in the comment below:
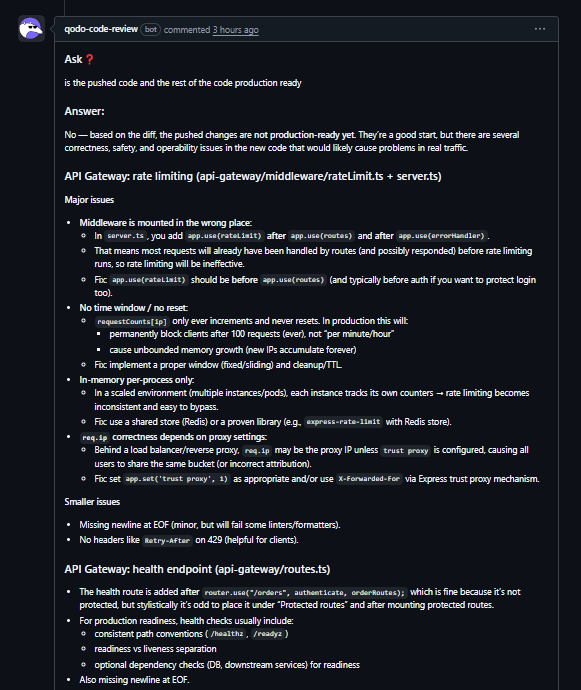
In the above comment, Qodo clearly stated after analyzing the changes that the code was not yet production-ready, pointing out issues that would likely break under production load.
This explicit “ready vs not ready” signal is critical: it removes ambiguity and stops unsafe changes from being assumed safe simply because they pass tests.
Qodo Flags Production Gaps with Actionable Explanations
In the same PR, as visible in the PR Compliance Check below:
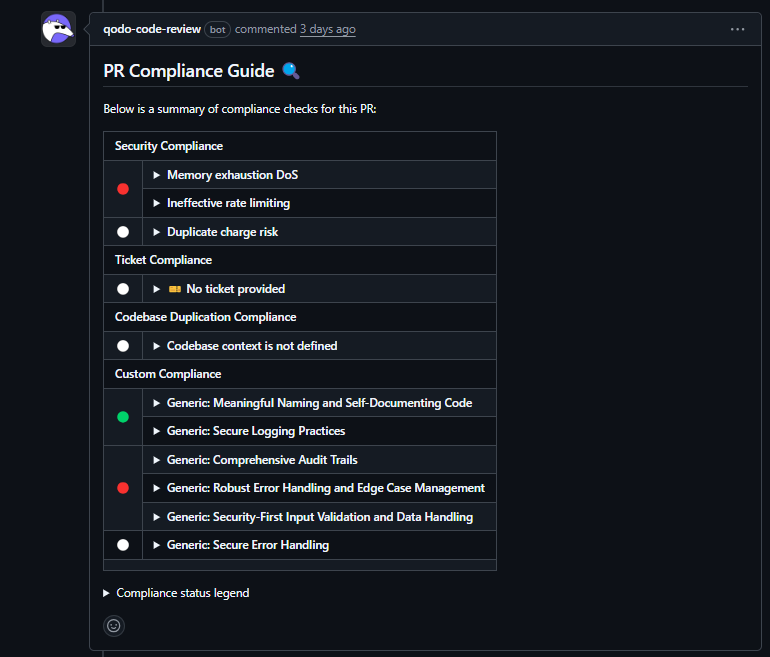
Beyond individual PRs, Qodo tracks patterns across the codebase. If a retry-without-idempotency pattern was flagged and fixed in one service, Qodo recognizes the same pattern when it appears in another, avoiding teams from solving the same problem twice:
API gateway (rate limiting)
- Detected unbounded in-memory request counters that could lead to memory exhaustion
- Identified missing time windows that would permanently block clients after a threshold
- Flagged incorrect middleware ordering that made rate limiting ineffective
- Highlighted risks in multi-instance deployments where counters aren’t shared
- Called out proxy-related IP attribution issues that affect correctness in production
Payment service (retry logic)
- Flagged retry behavior that could result in duplicate charges
- Identified missing idempotency guarantees for non-idempotent POST requests
- Highlighted retry policies that would retry non-recoverable errors
- Surfaced observability gaps that would make payment failures hard to debug in production
These weren’t lint warnings or stylistic suggestions; they were production correctness and operability risks.
Qodo Suggests Production-Ready Code Fixes
Beyond identifying gaps, Qodo provided code suggestions to help make the PR production-ready. Here is how the suggestions look:
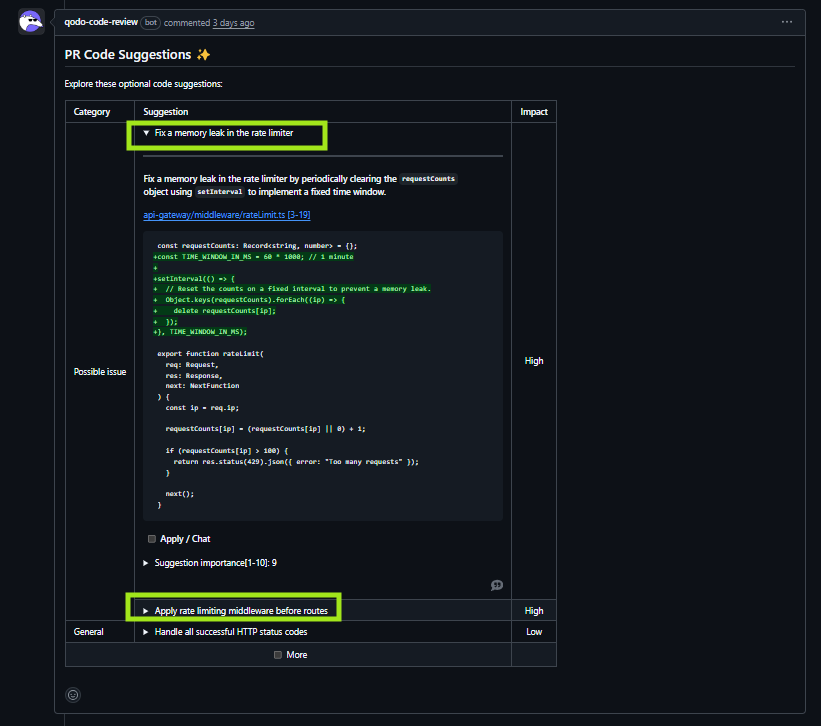
The suggestions listed above include:
- Fixing a memory leak in the rate limiter: Suggesting a fixed time window and periodic cleanup to avoid unbounded memory growth
- Correcting middleware ordering: Recommending that rate-limiting middleware be applied before routes, so it actually protects endpoints.
- Hardening HTTP success handling: Updating brittle status checks to correctly handle all successful 2xx responses
These were actionable fixes that improved production reliability. Qodo flags risks and provides clear code changes to resolve them.
How Qodo Helps Catch Production Risks Early
As an AI code review platform, Qodo adds a production-readiness layer to code review by:
- Making readiness explicit: Each PR is checked against production-grade expectations, not just correctness
- Highlighting real-world risks early: Issues are surfaced before merge, when fixes are cheapest
- Providing actionable fixes: Suggested code changes help teams move faster toward safe, deployable implementations
- Keeping humans focused on design: Reviewers spend less time enforcing safety checklists and more time on architecture and intent.
The result is higher confidence that the merged code is ready to run in real systems, under traffic.
Production Readiness Is Already a Standard for High-Quality Code in Teams That Ship Reliably
In 2026, production readiness is no longer a code quality aspiration documented in runbooks. It is enforced infrastructure, integrated directly into CI/CD pipelines and pull request workflows.
The shift is already happening. Teams that treat readiness as optional see it fail under pressure. Teams that treat it as a gate see it scale with code velocity.
Qodo fits into this by making production readiness visible and actionable at the point where code enters the system, the pull request. It handles the systematic checks a reviewer could catch but routinely misses under time pressure: middleware ordering, retry bounds, idempotency coverage, field-level exposure in API responses. Human reviewers stay focused on architecture and intent. Qodo handles the rest.
Teams that get this right ship faster and see fewer incidents, because they built systems that catch problems before deployment, not after.
FAQs
1. What does “production-ready code” actually mean?
Production-ready code is code that won’t cause an incident when it runs under real conditions. It handles failures, retries safely, enforces access control, logs enough context to debug, and can be rolled back without a restore. Code that only works in tests is not production-ready, it just hasn’t failed yet.
2. How does Qodo determine if code is production-ready?
Qodo analyzes each pull request in the context of your wider codebase and applies production-readiness checks across security, reliability, deployment safety, and operability. It flags concrete risks (like missing idempotency, unbounded retries, or broken auth patterns) and gives a clear “ready vs not ready” signal with explanations. This removes ambiguity and stops unsafe changes from being assumed safe just because they pass tests.
3. Can AI-generated code be production-ready without manual review?
No. AI-generated code can be syntactically correct and pass all tests while silently skipping auth checks, retry bounds, and idempotency, none of which trigger CI failures. Production readiness requires system-level context that an AI assistant working in isolation doesn’t have: which services call this function, whether the retry is safe, whether the API change breaks a consumer in another repo. That’s why Qodo analyzes PRs with full codebase context alongside human review.
4. What are the most common production-readiness gaps that slip through code review?
The most common gaps are: missing idempotency (leading to duplicate charges or actions on retry), unsafe retry logic (retrying non-recoverable errors or causing retry storms), broken or missing authentication checks, incorrect error handling (treating success responses as failures), lack of observability (no logging or metrics to debug issues), and missing rollback mechanisms (no feature flags or safe deployment patterns). These don’t cause test failures but break in production under real traffic.
5. How does Qodo integrate with existing CI/CD pipelines?
Qodo runs as part of your pull request workflow, integrating with GitHub, GitLab, Bitbucket, and CI systems like Jenkins, GitHub Actions, or GitLab CI. It analyzes code when a PR is opened or updated, checks it against your organization’s production-readiness policies, and reports results as standard status checks that can block merges. It works within your existing tools without requiring developers to change their workflow.
6. Does using Qodo mean you don’t need human code reviewers?
No. Qodo handles the systematic, repeatable checks that humans miss or find tedious (retry logic correctness, idempotency, security patterns, API compatibility, observability). Human reviewers stay focused on what they do best: architectural decisions, business logic correctness, design tradeoffs, and context that requires judgment. Qodo makes human review more effective by catching mechanical issues before reviewers see the PR.
7. Does Qodo work across multiple repositories?
Yes. Qodo indexes across repos and maps cross-service dependencies, so a change in one repo can be checked against the contracts and consumers it affects in others. This is how it catches issues like a renamed enum in a shared library breaking a consumer service that hasn’t been redeployed.
8. What happens if Qodo flags a risk but the team decides to merge anyway?
The decision stays with the team. Qodo flags the risk, explains the reasoning, and records the override in the audit trail. If that change causes a production incident, the trail shows what was flagged, who approved it, and what was overridden, making postmortems faster and avoiding the same decision from being made twice.